本文主要是介绍迁移学习「求解」偏微分方程,条件偏移下PDE的深度迁移算子学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文约3200字,建议阅读5分钟
迁移学习框架能够快速高效地学习异构任务。
传统的机器学习算法旨在孤立地学习,即解决单个任务。在许多实际应用中,收集所需的训练数据和重建模型要么成本高得令人望而却步,要么根本不可能。
迁移学习(TL)能够将在学习执行一个任务(源)时获得的知识迁移到一个相关但不同的任务(目标),从而解决数据采集和标记的费用、潜在的计算能力限制和数据集分布不匹配的问题。
来自美国布朗大学和约翰斯·霍普金斯大学(JHU)的研究人员提出了一种新的迁移学习框架,用于基于深度算子网络 (DeepONet) 的条件转移下的任务特定学习(偏微分方程中的函数回归)。
由于几何域和模型动力学的变化,研究人员展示了该方法在不同条件下涉及非线性偏微分方程的各种迁移学习场景的优势。尽管源域和目标域之间存在相当大的差异,但提出的迁移学习框架能够快速高效地学习异构任务。
该研究以「Deep transfer operator learning for partial differential equations under conditional shift」为题,发布在《Nature Machine Intelligence》上。

论文链接:
https://www.nature.com/articles/s42256-022-00569-2
深度学习已经成功地应用于模拟偏微分方程(PDE)描述的计算成本很高的复杂物理过程,并实现了卓越的性能,从而加速了不确定性量化、风险建模和设计优化等众多任务。但此类模型的预测性能通常受到用于训练的标记数据的可用性的限制。
然而,在许多情况下,收集大量且足够的标记数据集在计算上可能很棘手。此外,孤立学习(即为独特但相关的任务训练单个预测模型)可能非常昂贵。
为了解决这个瓶颈,可以在称为迁移学习的框架中利用相关领域之间的知识。在这种情况下,来自在具有足够标记数据的特定域(源)上训练的模型的信息可以转移到只有少量训练数据可用的不同但密切相关的域(目标)。
由于缺乏针对特定任务的算子(operator)学习和不确定性量化的 TL 方法,在这项工作中,研究人员提出了一个使用神经算子在条件转换下高效 TL 的新框架。
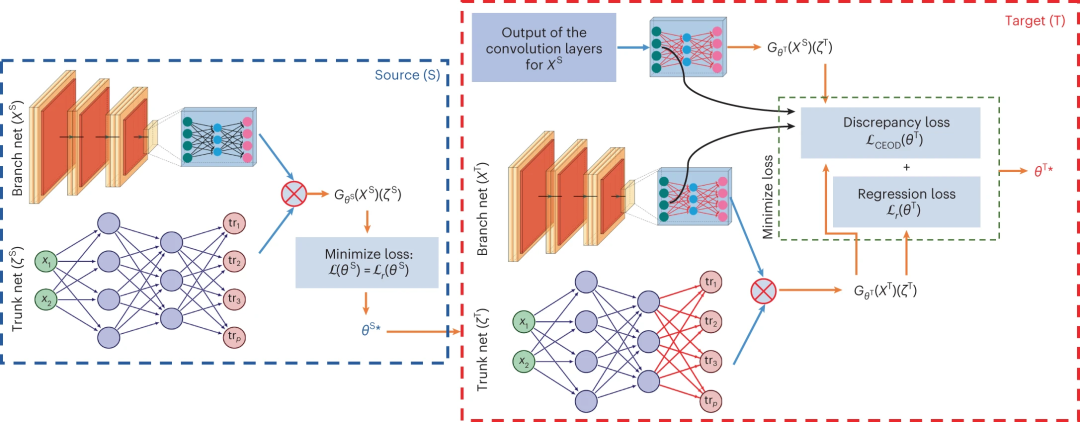
图 1:利用 DeepONet 提出的近似 PDE 解的迁移学习框架。(来源:论文)
研究人员将目标神经算子称为迁移学习深度算子网络 (TL-DeepONet)。这项工作背后的主要思想是在标准回归损失下从源域训练具有足够标记数据(即模型评估)的源模型,并将学习的变量迁移到第二个目标模型,该目标模型在混合损失函数下用来自目标域的非常有限的标记数据训练。混合损失包括回归损失和条件嵌入算子差异 (CEOD) 损失,用于衡量再现核希尔伯特空间 (RKHS) 中条件分布之间的差异。所提出框架的关键要素是利用源模型提取的域不变特征,从而有效地初始化目标模型变量。
在这项工作中,研究人员采用了更通用的深度神经算子 (DeepONet),它使我们能够充分学习算子,从而对任意新输入和复杂域执行实时预测。重要的是,所提出的迁移学习框架能够在标记数据非常有限的领域中识别 PDE 算子。这项工作的主要贡献可归纳如下:
提出了一种新的框架,用于在深度神经算子的条件转移下迁移学习问题。
所提出的框架可用于快速高效的特定于任务的 PDE 学习和不确定性量化。
利用 RKHS 和条件嵌入算子理论的原理来构建新的混合损失函数并对目标模型进行微调。
所提出框架的优点和局限性通过各种迁移学习问题得到证明,包括由于域几何、模型动力学、材料特性、非线性等变化引起的分布变化。
研究人员提出了参数 PDE 的迁移学习问题的综合集合,以评估所提出方法的有效性。图 2 给出了所考虑的不同基准的直观描述。首先介绍基准问题以及所考虑的迁移学习场景,然后提供实验结果。
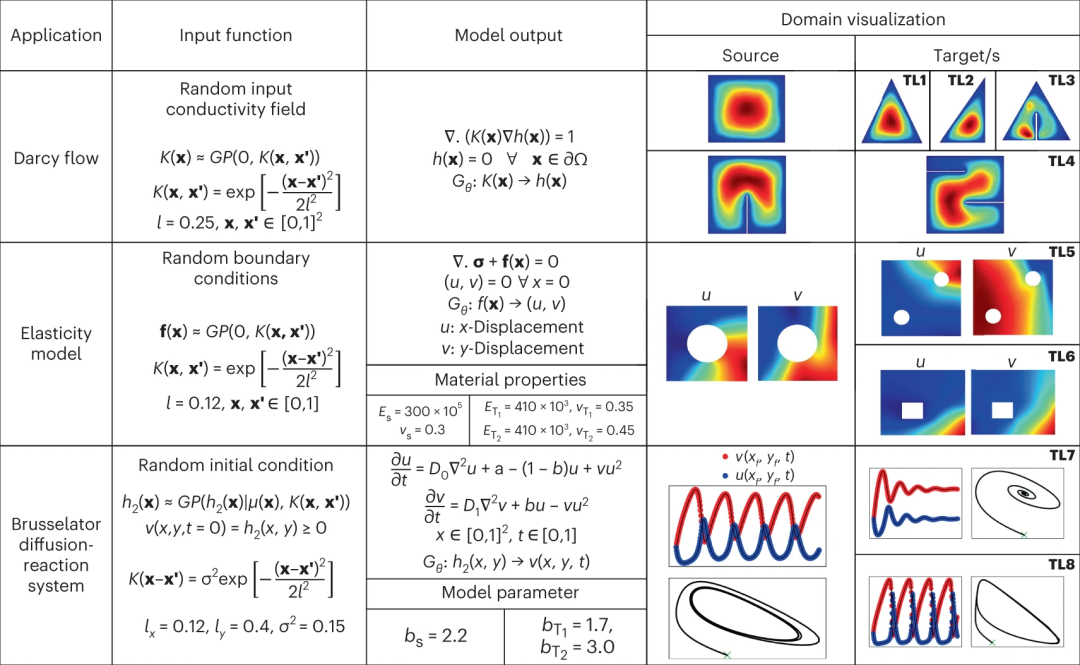
图 2:本工作中考虑的算子学习基准和 TL 场景的示意图。(来源:论文)
场景一——达西流:达西定律描述了流体在给定渗透率下流过多孔介质的压力,可以用以下方程组进行数学表示:
∇⋅(K(x)∇h(x))=g(x),x=(x,y) (1)
受以下边界条件约束:
h(x)=0,∀x∈∂Ω,
其中 K(x) 是异质多孔介质随空间变化的导水率,h(x) 是相应的水头。
本研究的目标是学习等式(1)中系统的算子,它将输入随机电导率场映射到输出水头(hydraulic head);即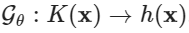 。
。
为了生成多个电导率场来训练 DeepONet,将 K(x) 描述为一个随机过程,其实现是通过截断的 Karhunen–Loéve 展开生成的。源模拟框是一个方形域 Ω = [0,1] ×[0,1],离散化 d = 1541 个网格点。考虑以下四种迁移学习场景:
TL1:将学习从正方形域迁移到等边三角形。
TL2:将学习从正方形域转移到直角三角形。
TL3:将学习从正方形域迁移到具有垂直缺口的等边三角形。
TL4:将学习从具有一个垂直缺口的方形域迁移到具有两个水平缺口的方形域。
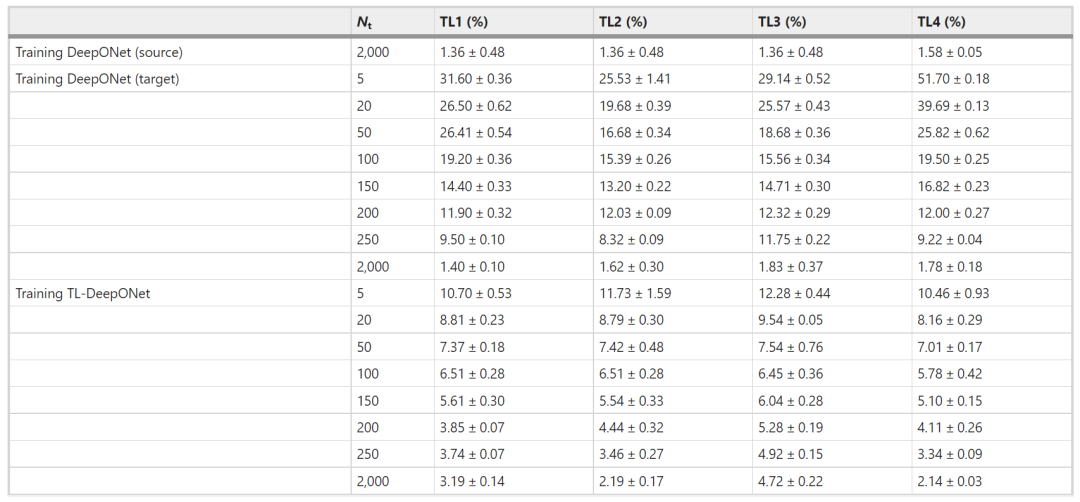
研究发现,任务 TL1 和 TL2 展示了该方法能够以高精度将知识从方形域转移到三角形域,即使在使用小型数据集进行训练时也是如此(见表 1)。为了测试该方法在具有挑战性的情况下的性能,考虑具有不连续性和缺口的域(任务 TL3 和 TL4)。观察到 TL-DeepONet 精度损失小于 5%,这表明即使考虑了非常不同的外部边界域,也可以用很少的标记数据预测液压头。
表 1:所有达西流问题的相对 L2 误差 (TL1–TL4)。(来源:论文)
场景二——弹性模型:考虑承受平面内载荷作用的薄矩形板,将其建模为平面应力弹性的二维问题。相关方程如下:
∇⋅σ+f(x)=0,x=(x,y) (2)
(u,v)=0,∀x=0,
其中 σ 为柯西应力张量;f 是力;u(x) 和 v(x) 分别表示 x 和 y 位移;E 和 ν 分别代表材料的杨氏模量和泊松比。在平面应力条件下,应力与位移的关系定义为:
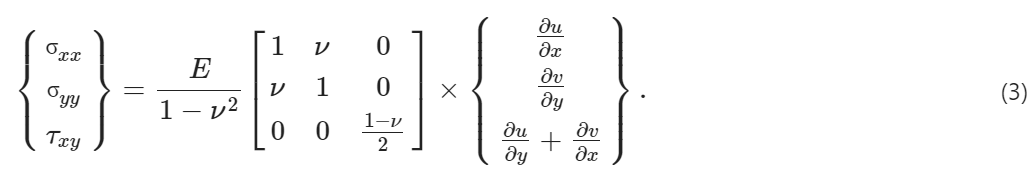
将施加到板右边缘的加载条件 f(x) 建模为高斯随机场。这里的目标是学习从随机边界载荷到位移场的映射(u:x-位移和 v:y-位移),使得 。
。
因此,研究人员训练 DeepONet 代理来预测两个不同的模型输出。在这个例子中,考虑以下两个 TL 场景:
TL5:将学习从具有中心圆形内部边界和材料特性(ES = 300 × 10^5, νS = 0.3)的域转移到右上角和左下角具有两个较小圆形内部边界和不同材料特性(ET = 410 × 10^3, νT = 0.35)。
TL6:将学习从具有中心圆形内部边界和材料特性的域 (ES = 300 × 10^5, νS = 0.3) 迁移到具有方形内部边界和不同材料特性的域(ET = 410 × 10^3, νT = 0.45) 。
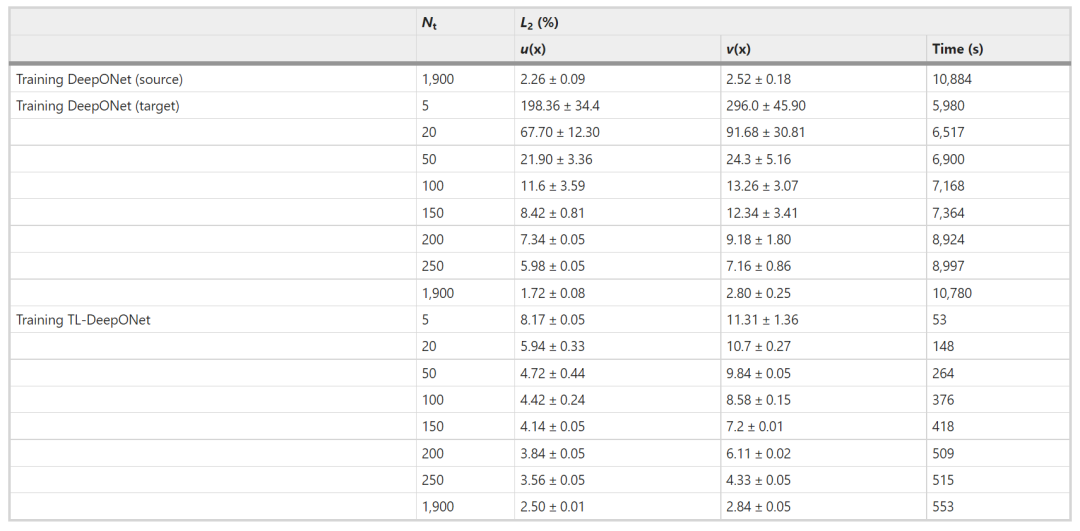
研究发现,所提出的 TL 框架允许多任务学习,即使源域和目标域存在不止一个方面的差异。在弹性模型中,这两个域具有不同的内部边界和不同的材料特性。对目标数据集大小的研究表明,大约 200 个样本足以模拟 TL5 中从源域到目标域的条件转移。
表 2:弹性迁移学习问题 (TL5) 的相对 L2 误差和训练成本。(来源:论文)
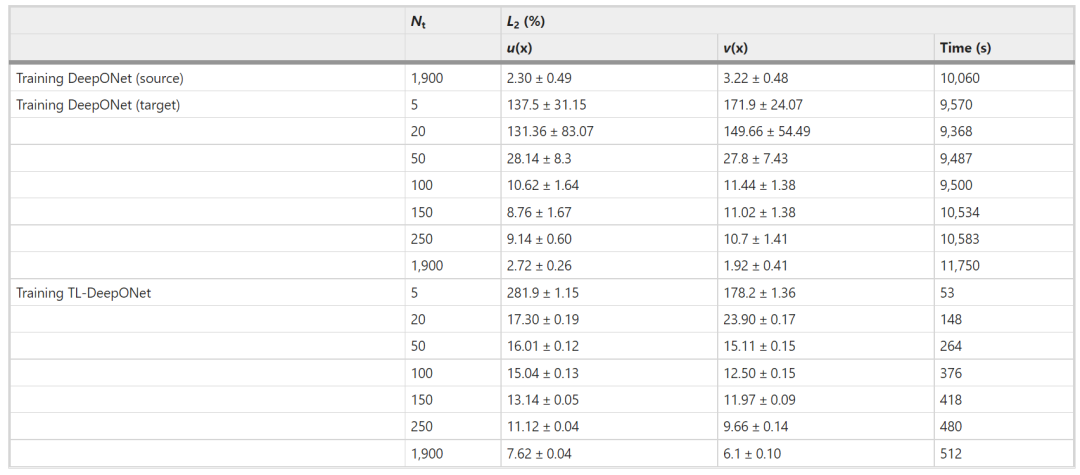
然而,在 TL6 中,内部边界和模型参数发生了很大程度的变化(从平滑边界到非平滑边界),TL-DeepONet 由于源模型无法捕获较低层次网络中的目标特征,导致了相对较高的误差。
表 3:弹性迁移学习问题 (TL6) 的相对 L2 误差和训练成本。(来源:论文)
场景三——Brusselator 扩散反应系统:最后,以 Brusselator 扩散反应系统为例,它描述了一种自催化化学反应,在该反应中,反应物质与另一种物质相互作用以提高其生产率。Brusselator 体系的特点是:

其中ki, (i =1,2,3,4) 是代表反应速率常数的正参数。在等式 (4) 中,反应物 A 在四种额外的物质 X、B、Y 和 D 的帮助下分四步转化为最终产物 E。物质 A 和 B 大量过量,因此可以在恒定浓度下建模。二维速率方程如下:
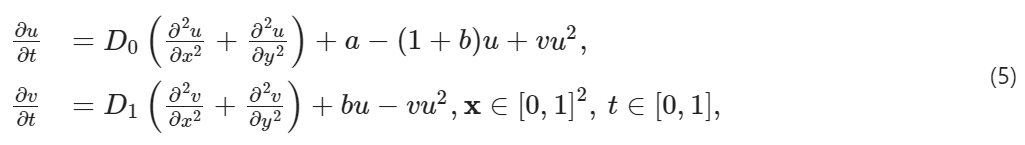
受限于以下初始条件:

其中 x =(x, y) 是空间坐标;D0,D1 表示扩散系数;a={A},b = B 为常数浓度;和 u = {X}, v ={Y} 表示反应物种类 X, Y 的浓度。
在过程系统工程中——目标是设计、控制和优化动力系统描述的化学物理和生物过程——迁移学习可以为学习不同场景下的系统动力学(例如,不同数量的物种、热力学性质等)提供有用的手段。
在这个问题中,研究人员训练 DeepONet 来学习初始场和物种 v 的进化浓度之间的映射,即 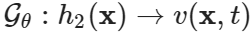 。
。
初始场 h2(x, y) 被建模为高斯随机场。考虑以下两个迁移学习问题:
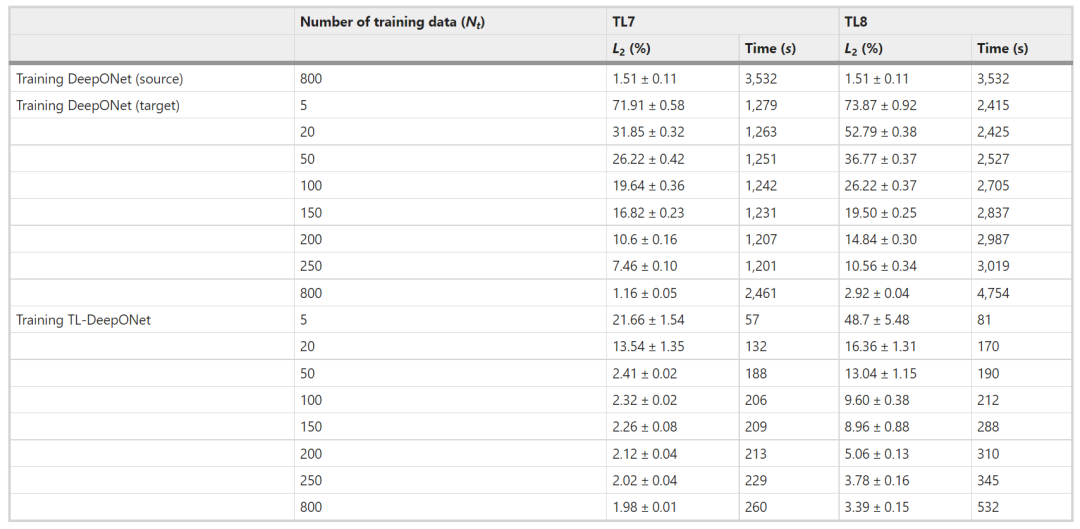
TL7:将学习从阻尼振荡转移到过阻尼振荡(快速接近稳态响应)。
TL8:将学习从阻尼振荡转移到周期性振荡(相空间中的极限循环)。
在 TL7 中,部署了在平滑动力学上训练的源模型,用于近似高度非平滑动力学。结果表明,即使对于这种具有挑战性的动态,该框架也表现良好。对于TL7,使用自适应权重对目标域进行微调,并用于目标域的回归损失。
表 4:Brusselator 迁移学习问题(TL7 和 TL8)的相对 L2 误差和训练成本。(来源:论文)
总的来说,研究发现在解决条件分布不匹配的 PDE 问题时,转移先前获得的知识(即从模型的较低级别学习的域不变特征)和对网络的较高级别层进行优化,可以实现高效的多任务算子学习。
编辑:于腾凯
校对:林亦霖

这篇关于迁移学习「求解」偏微分方程,条件偏移下PDE的深度迁移算子学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




