本文主要是介绍知识注入以对抗大型语言模型(LLM)的幻觉11.6,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
知识注入以对抗大型语言模型(LLM)的幻觉
- 摘要
- 1 引言
- 2 问题设置和实验
- 2.1 幻觉
- 2.2 生成响应质量
- 3 结果和讨论
- 3.1 幻觉
- 3.2 生成响应质量
- 4 结论和未来工作

摘要
大型语言模型(LLM)内容生成的一个缺点是产生幻觉,即在输出中包含错误信息。对于需要可靠、基于事实的、可控的大规模文本生成的企业应用案例,这尤为危险。为了减轻这一问题,本文利用一种称为知识注入(KI)的技术,将与文本生成任务相关的实体的上下文数据从知识图谱映射到文本空间中,以便在LLM提示中包含这些数据。以回应在线客户对零售店铺的评论为例,我们发现KI可以增加生成文本中包含的正确断言的数量。在定性评估中,具有KI的经过微调的bloom560m模型表现优于OpenAI的未经微调的text-davinci-003模型,尽管text-davinci-003模型的参数数量是后者的300倍。因此,KI方法可以增加企业用户对利用LLM替代繁琐的手动文本生成的信心,并使较小、更便宜的模型表现更好。
1 引言
大型语言模型(LLM)内容生成的一个限制是幻觉,即在生成的文本中存在虚假断言。企业使用案例需要可靠、以事实为基础的大规模文本生成,因此对LLM生成的文本进行投资具有风险。为了减轻幻觉问题,我们利用一种称为知识注入(KI)的技术,将与任务相关的实体的上下文数据从知识图谱映射到文本空间中,以便在LLM提示中包含这些数据。在我们回应在线零售店铺客户评论的用例中,KI增加了正确断言的比例,同时提高了整体文本质量。
尽管LLM的参数包含了知识,但它们仍然容易产生幻觉,因为:
(1)并非所有当前数据都可以在模型训练期间提供(例如,训练后对业务信息进行的更新),以及
(2)将所有知识编码到模型参数中是困难的。KI从包含与任务相关的实体以及与其他实体的连接相关的知识图谱开始。KI旨在生成带有业务信息的可控文本,该信息不是通用知识(例如,商家的电话号码可能不是LLM从基础训练中获知的常识)。可控文本生成(CTG)受控制约束的影响,例如情感或者在我们的用例中,与真实业务信息的对齐。
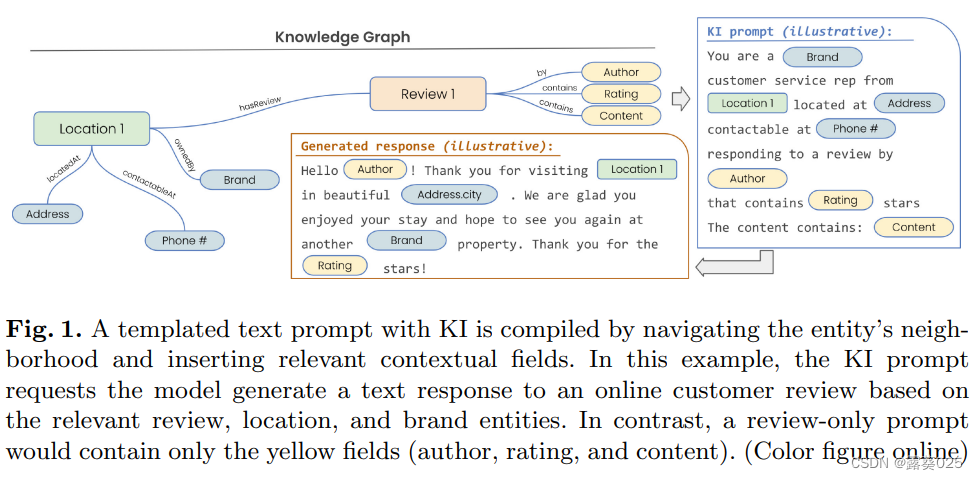
从知识图谱中提取的文本字段被插入到一个模板化的提示中,以将基于图谱的上下文映射到文本空间,形成LLM的输入。这在图1中进行了演示,其中请求了LLM对在线客户评论的生成响应。相关实体Review 1及其邻居,例如Location 1,在知识图谱中被映射到一个模板化的提示中。
2 问题设置和实验
2.1 幻觉
我们旨在确定KI是否减少LLM生成的对在线客户评论的响应中的幻觉。使用bloom-560m 的LLM经过微调,使用人工客户服务代理撰写的评论和回复进行训练。对比评估了仅使用评论信息(作者、评分和内容)进行微调的仅评论模型生成的响应与使用添加的实体上下文进行KI提示的模型生成的响应。这些模型在约35,000个评论-回复对的数据集上进行了微调。
领域专家统计了每个生成的响应中的正确和错误断言。断言包括指定位置名称,可通过电话号码或网址联系,由品牌名称所有,并位于位置地址。不正确(即幻觉)的断言包含与知识图谱相矛盾的不真实信息,例如指示客户拨打虚构的电话号码。事实性断言是指其他没有标记为不正确的断言。
2.2 生成响应质量
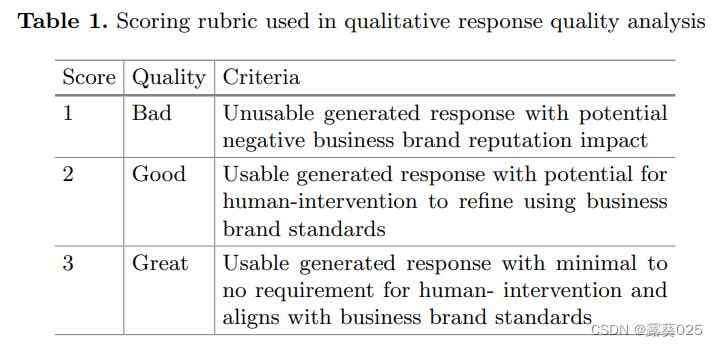
除了测试KI对幻觉的影响外,我们还测试了其对生成的评论响应整体质量的影响。主题专家根据3级评分标准(表1)对非KI提示的OpenAI的text-davinci-003文本生成模型(即GPT-3 )和KI提示的bloom-560m生成的响应进行了评分。
3 结果和讨论
3.1 幻觉
KI增加了正确断言的数量,同时减少了错误断言的数量(表2),这表明在像评论回复这样的企业任务中,KI是有用的。这些任务在人工完成时既费时又昂贵,但需要关于业务的事实背景才能生成可信赖的文本。

3.2 生成响应质量
KI模型在生成的响应质量上获得了更高的评分,这表明KI对于帮助模型与业务品牌标准保持一致是有用的(表3)。尽管text-davinci-003的参数数量是bloom-560m的约300倍,但经过KI微调的较小模型表现优于较大的OpenAI模型。因此,通过使用KI进行微调,企业可以在训练和托管较小模型的同时产生更高质量的生成响应,从而节省成本。此外,使用较小的模型还可以提高推理速度。
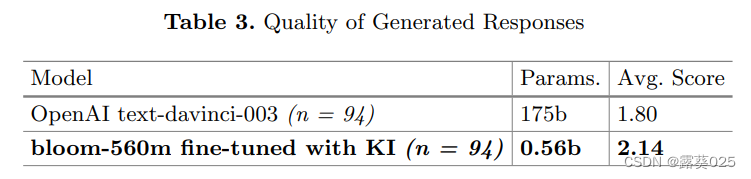
4 结论和未来工作
在幻觉和生成响应质量方面的实验表明,KI可以帮助企业从LLM中生成更可靠、基于事实且质量更高的文本。为了充分利用这一点,企业需要具有与其业务相关的实体的事实和健壮的知识图谱,如位置、评论、产品、文件等。
为了减轻这一限制,在未来的实验中,我们打算继续研究通过利用LLM进行实体和边缘提取来建立业务的健壮知识图谱的方法。
这篇关于知识注入以对抗大型语言模型(LLM)的幻觉11.6的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









