本文主要是介绍Mplus—潜在剖面分析(Latent Profile Analysis, LPA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
潜类别模型
简介
分类
潜在剖面分析
简介
分析步骤
Mplus语句
结果报告
1. 信息评价指标(AIC, BIC, aBIC)
2. Entropy分类指标
3. 似然比指标
4. 图
5. txt文件
6. 可以以表格的方式呈现多个模型的上述信息
潜在剖面的后续分析
协变量为预测变量
协变量为结果变量
Mplus语句及结果
协变量为预测变量
结果
协变量为结果变量
结果
参考文献
潜类别模型
简介
根据个体在观测指标上的反应模式进行参数估计,是一种以个体为中心(Person-Centered)的分析方法。
换句话说,
-
LCM可以用来干什么?/达成什么目的?——LCM可以将人群分为不同的类别。
-
那根据什么来分类?/分类依据?——LCM依据个体在观测指标上的反应模式,将每个个体分到不同的类别中。
分类
根据观测指标/外显变量的特征,LCM可以分为潜在类别分析(Latent Class Analysis, LCA)和潜在剖面分析(Latent Profile Analysis, LPA)。前者处理分类观测指标,后者处理连续观测指标。
潜在剖面分析
简介
潜在剖面分析(Latent Profile Analysis, LPA)可以简单理解为:根据个体对连续观测指标的反应特征,将其划分到不同的类别中。
那么,想要进行LPA,则需要解决以下几个问题:
-
分类依据是个体对连续观测指标的反应特征,那么连续观测指标怎么确定?
-
将人群分类,那么分几类?怎么知道分几类是最恰当的呢?
当我们不清楚该怎么做的时候,其中一个方法便是:看别人怎么做。
- 连续观测指标可以是题目得分、维度得分、量表总得分,只要“连续”即可。

- 分几类最恰当?——可以最初假设只存在一个分类,然后逐步增加类别个数,通过模型比较,确定最佳分类个数。
- 模型比较标准?
- 信息评价指标(AIC, BIC, aBIC):越小越好。
- Entropy指数:表示分类精确程度,取值范围为0到1,越接近1表明分类越精确。 0.6以下表明有超过20%的个体在分类错误; 0.8以上表示分类准确性超过90%;
- 似然比指标(LMR, BLRT):显著的LMR、BLRT值表明K个类别的模型优于K-1个类别的模型。

分析步骤
-
确定观测指标/外显变量
-
假设只存在一个分类,逐步增加潜在类别的个数
-
进行模型比较,确定最佳类别个数
-
对类别命名
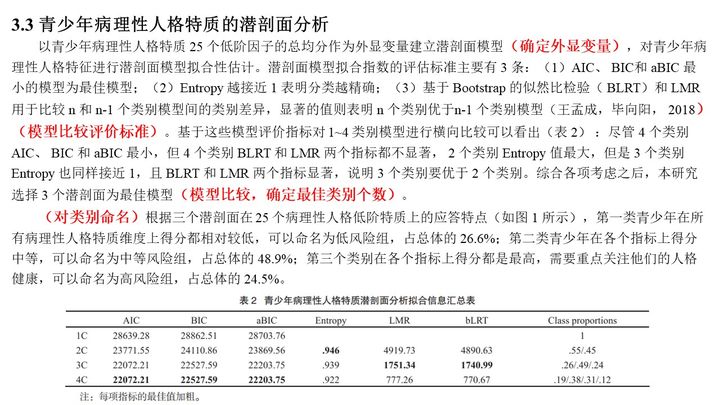
(张文娟, 商士杰, 2023)
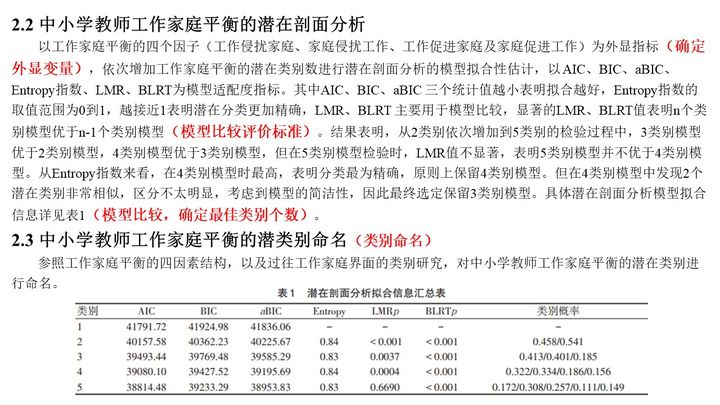
(曾练平, 曾冬平等, 2021)
Mplus语句
TITLE: This is an example of LPA;
DATA: FILE IS dataLPA.dat; ! 数据文件名为dataLPA.dat
VARIABLE: NAME ARE A1-A5; ! 数据文件中包含的变量
USEVARIABLES ARE A1-A5; ! 本次分析中使用的变量
MISSING ARE ALL (99); ! 定义缺失值为99
CLASSES = C(3); ! 设置类别个数,从1个类别开始,依次增加
ANALYSIS: TYPE = MIXTURE; ! 使用MIXTURE算法
STARTS = 200 50; ! 避免局部最大化解,增加随机起始值数
PROCESSOR = 4; ! 调用的处理器
OUTPUT: TECH11 TECH14; ! TECH11输出LMRT的结果,TECH14输出BLRT的结果
SAVEDATA: FILE = dataLPA1.TXT; ! 保存个体分类结果到dataLPA1.txt中
SAVE = CPROB; !保存后验分类概率
PLOT: TYPE IS PLOT3; ! 通过绘图命令,可以获得描述性统计图和条件概率示意图
SERIES = A1-A5 (*); ! 绘图中所使用的变量名
结果报告
1. 信息评价指标(AIC, BIC, aBIC)
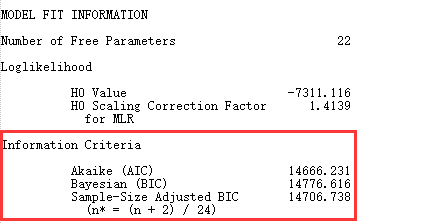
2. Entropy分类指标

3. 似然比指标

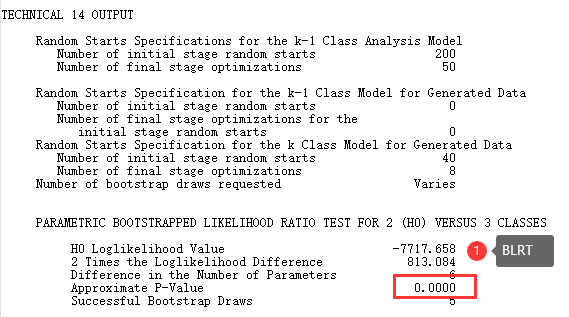
4. 图
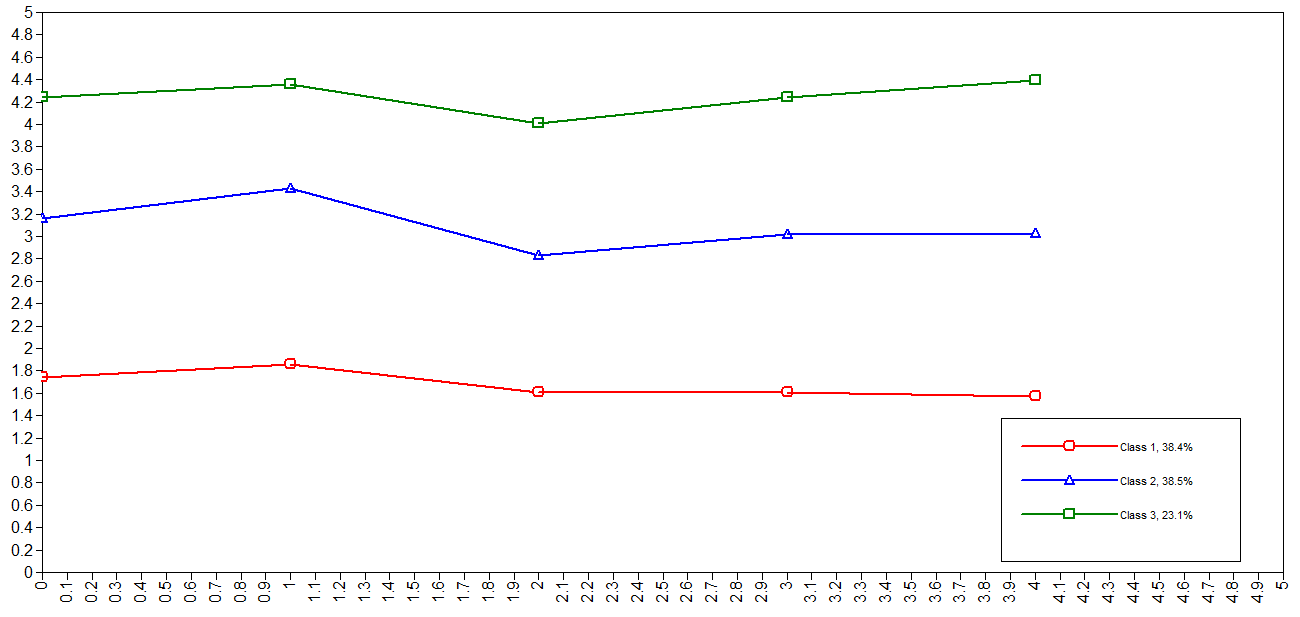
5. txt文件
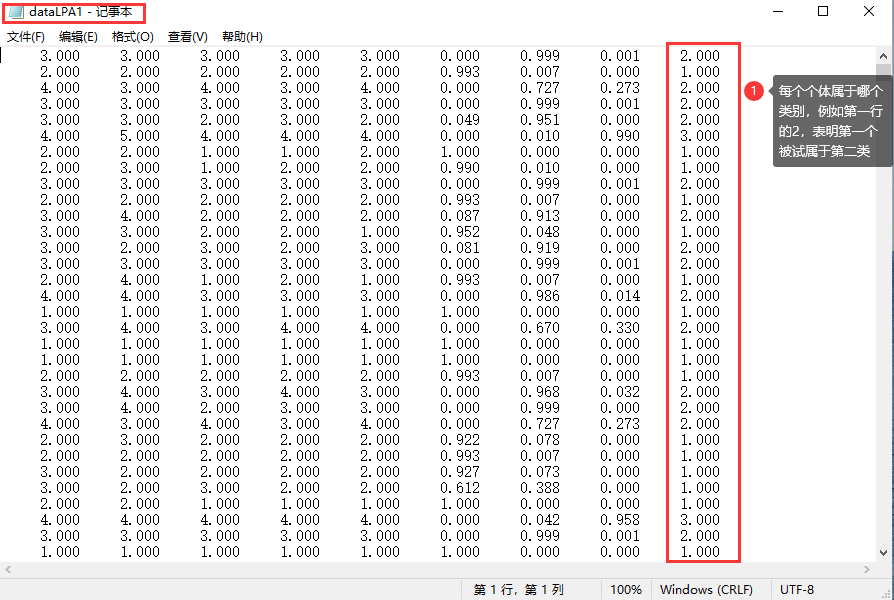
在Mplus语句中,我们通过“SAVEDATA: FILE = dataLPA1.TXT;”这一命令,将个体分类结果保存在了名为dataLPA1的txt文件中,在这一文件中,最后一列会标明每个个体属于哪个类别。
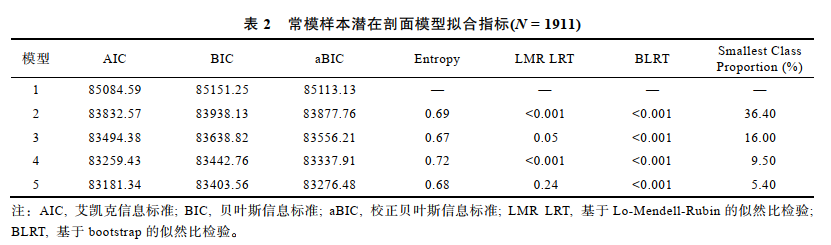
6. 可以以表格的方式呈现多个模型的上述信息
(周明洁等, 2023)

(曾练平, 田丹丹等, 2021)
潜在剖面的后续分析
当我们通过LPA确定最佳分类数,并且对每个类别命名后,通常还会进行后续分析,即纳入协变量(Auxiliary Variable,也称为辅助变量),分析协变量与潜在类别变量之间的关系。协变量可以充当潜在类别变量的预测变量(Predictor),也可以充当潜在类别变量的结果变量(Distal Outcome)。
协变量为预测变量
当协变量为预测变量,潜在类别变量为因变量时,可以进行Logistic回归分析。

(郑天鹏等, 2023)
协变量为结果变量
当协变量为结果变量,潜在类别变量为自变量时,可以采用方差分析检验潜在类别之间的差异,或者通过列联表分析协变量与潜在类别的关系。

(肖雨蒙等, 2022)
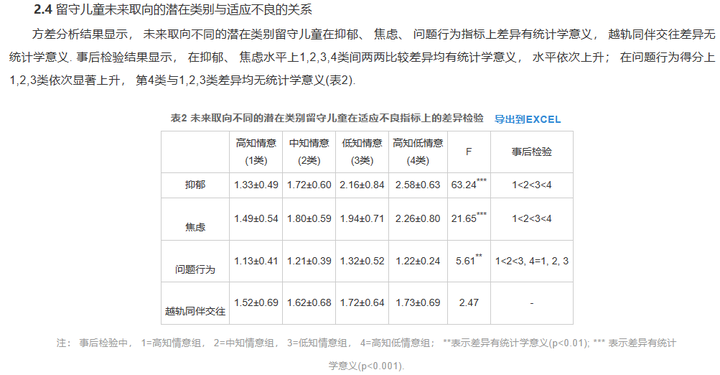
(肖雨蒙等, 2022)

(邹维兴等, 2022)

(赵雪艳等, 2023)
上述分析通常需要先使用Mplus得到潜在类别变量,之后通过统计分析软件,例如SPSS,完成后续分析。
除此之外,还可以在LPA语句的基础上添加一些语句,在Mplus中直接完成后续分析。
Mplus语句及结果
协变量为预测变量
如果协变量是预测变量X,由命令“AUXILIARY = X (R3STEP)”来设定。
TITLE: This is an example of LPA;
DATA: FILE IS dataLPA.dat; ! 数据文件名为dataLPA.dat
VARIABLE: NAME ARE A1-A5 X; ! 数据文件中包含的变量
USEVARIABLES ARE A1-A5 X; ! 本次分析中使用的变量
MISSING ARE ALL (99); ! 定义缺失值为99
CLASSES = C(3); ! 设置类别个数,从1个类别开始,依次增加
AUXILIARY = X (R3STEP); ! 使用稳健三步法设定协变量
ANALYSIS: TYPE = MIXTURE; ! 使用MIXTURE算法
STARTS = 200 50; ! 避免局部最大化解,增加随机起始值数
PROCESSOR = 4; ! 调用的处理器
OUTPUT: TECH11 TECH14; ! TECH11输出LMRT的结果,TECH14输出BLRT的结果
SAVEDATA: FILE = dataLPA.TXT; ! 保存个体分类结果到dataLPA.txt中
SAVE = CPROB; !保存后验分类概率
PLOT: TYPE IS PLOT3; ! 通过绘图命令,可以获得描述性统计图和条件概率示意图
SERIES = A1-A5 (*); ! 绘图中所使用的变量名
结果
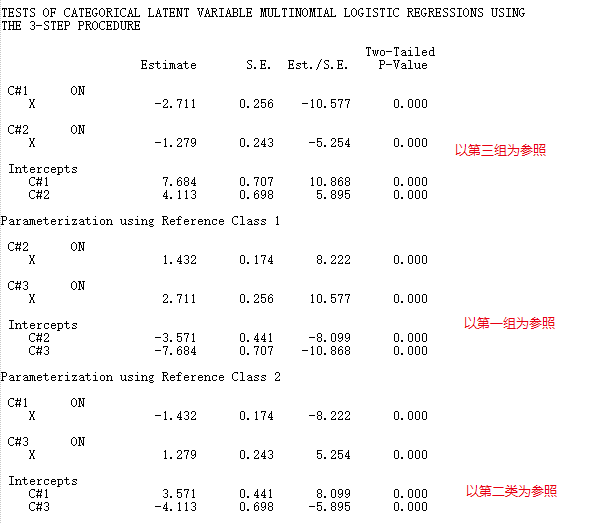


(王泓懿 & 张珊珊, 2023)
协变量为结果变量
如果协变量是连续结果变量Y,推荐使用BCH法,由命令“AUXILIARY = Y (BCH)”来设定。
TITLE: This is an example of LPA;
DATA: FILE IS dataLPA.dat; ! 数据文件名为dataLPA.dat
VARIABLE: NAME ARE A1-A5 Y; ! 数据文件中包含的变量
USEVARIABLES ARE A1-A5 Y; ! 本次分析中使用的变量
MISSING ARE ALL (99); ! 定义缺失值为99
CLASSES = C(3); ! 设置类别个数,从1个类别开始,依次增加
AUXILIARY = Y (BCH); ! 使用稳健三步法设定协变量
ANALYSIS: TYPE = MIXTURE; ! 使用MIXTURE算法
STARTS = 200 50; ! 避免局部最大化解,增加随机起始值数
PROCESSOR = 4; ! 调用的处理器
OUTPUT: TECH11 TECH14; ! TECH11输出LMRT的结果,TECH14输出BLRT的结果
SAVEDATA: FILE = dataLPA.TXT; ! 保存个体分类结果到dataLPA.txt中
SAVE = CPROB; !保存后验分类概率
PLOT: TYPE IS PLOT3; ! 通过绘图命令,可以获得描述性统计图和条件概率示意图
SERIES = A1-A5 (*); ! 绘图中所使用的变量名
结果
由下图可知,Y在三个类别/剖面中存在显著差异(χ2 = 260.826, p < 0.001)。具体而言,第一类的Y显著低于第二类的Y(χ2 = 92.653, p < 0.001)和第三类的Y(χ2 = 255.706, p < 0.001),第二类的Y显著低于第三类的Y(χ2 = 42.555, p < 0.001)。
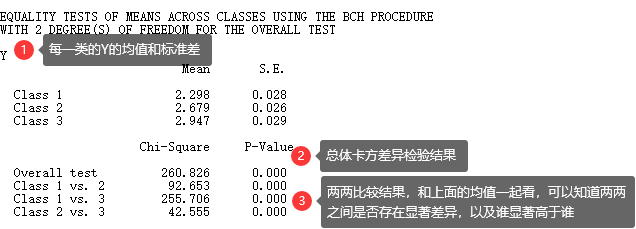

(刘豆豆等, 2020)
参考文献
- 曾练平, 曾冬平, 屈家宁, 佘爱, 燕良轼. (2021). 中小学教师工作家庭平衡的异质性:基于潜在剖面分析. 中国临床心理学杂志, 29(01), 161-164
- 曾练平, 田丹丹, 黄亚夫, 赵守盈. (2021). 中小学教师人格类型及其对工作家庭平衡与工作绩效关系的调节作用. 心理与行为研究, 19(02), 280-286
- 侯晴晴, 郭明宇, 王玲晓, 吕辉, 常淑敏. (2022). 学校资源与早期青少年心理社会适应的关系:一项潜在转变分析. 心理学报, 54(08), 917-930
- 刘豆豆, 陈宇帅, 杨安, 叶茂林, & 吴丽君. (2020). 中学教师工作狂类型与工作绩效的关系研究:基于潜在剖面分析. 心理科学, 43(01), 193-199
- 肖雨蒙, 杨莹, 冯宁宁, 刘蓓颖, 甘钱会, 崔丽娟. (2022). 留守儿童未来取向类型与适应不良的关系:基于潜在剖面分析. 西南大学学报(自然科学版), 44(08), 13-19
- 邹维兴, 谢玲平, 王洪礼. (2022). 亲子依恋与留守儿童攻击性行为的关系:基于潜在剖面的分析. 中国健康心理学杂志, 30(05), 703-708
- 王泓懿, & 张珊珊. (2023). 问题性社交网络使用对抑郁情绪的影响:基于潜在剖面分析. 中国健康心理学杂志, 1-13
- 赵雪艳, 游旭群, 秦伟. (2023). 中学教师情绪劳动策略与职业幸福感的关系:基于潜在剖面分析. 华东师范大学学报(教育科学版), 41(01), 16-24
- 张文娟, 商士杰. (2023). 父母回应消极情绪的方式与青少年病理性人格特质的关系. 心理科学, 46(03), 586-593
- 郑天鹏, 沈梦智, 周欣然, 梁丽婵, & 边玉芳. (2023). 温暖教养亲子感知差异与儿童情绪适应:基于潜在剖面分析的证据. 心理技术与应用, 11(08), 449-459
- 周明洁, 李府桂, 穆蔚琦, 范为桥, 张建新, 张妙清. (2023). 外圆内方:中国人人际关系性的潜在剖面结构及其适应性. 心理学报, 55(3), 390-405
希望上述介绍可以帮助到你!也欢迎大家在评论区多多交流分享。
你的关注/点赞 /收藏★/分享,是最大的支持!
这篇关于Mplus—潜在剖面分析(Latent Profile Analysis, LPA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







