本文主要是介绍金豺算法优化VMD参数,六种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵、包络谱峰值因子...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:对于作者的原创代码,禁止转售倒卖,违者必究!
本期采用金豺优化算法(Golden Jackal optimization, GJO)优化VMD参数。选取六种适应度函数进行优化,以此确定VMD的最佳k和α参数。6种适应度函数分别是:最小包络熵,最小样本熵,最小信息熵,最小排列熵,排列熵/互信息熵,包络谱峰值因子,代码中可以一键切换。
关于优化VMD参数的更多详细内容还可以参考这一篇:运行速度终于变快了!优化VMD参数,五种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵
金豺优化算法于2022年发表在中科院1区top SCI期刊《Expert Systems with Applications》上,属于高被引论文,深受欢迎。谷歌学术被引次数为167次。


对于前面五种适应度函数,之前的文章介绍过很多了。本文新增一个包络谱峰值因子作为适应度函数,关于包络谱峰值因子的介绍如下:

参考文献:张龙,熊国良,黄文艺.复小波共振解调频带优化方法和新指标[J].机械工程学报,2015,51(03):129-138.
至于应该选择哪种作为自己的适应度函数,大家可以看这篇文章。VMD为什么需要进行参数优化,最小包络熵/样本熵/排列熵/信息熵,适应度函数到底该选哪个
同样以西储大学数据集为例,选用105.mat中的X105_BA_time.mat数据中1000个数据点。没有数据的看这篇文章。西储大学轴承诊断数据处理,matlab免费代码获取
1.最小包络熵作为适应度函数


2.最小样本熵作为适应度函数
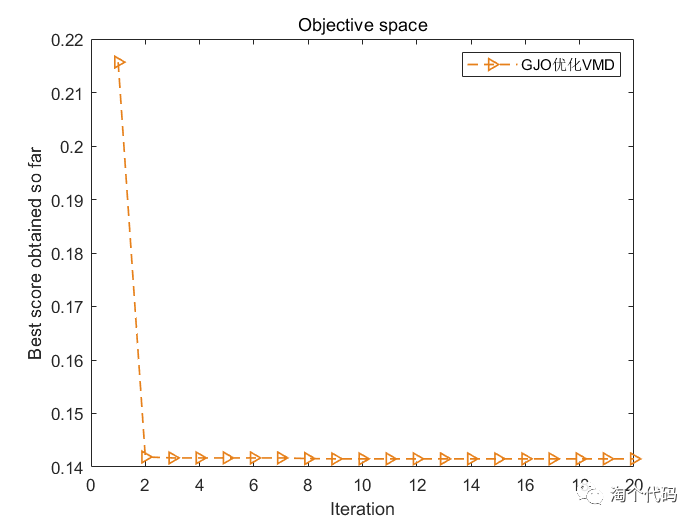
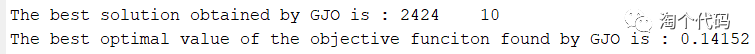
3.最小信息熵作为适应度函数
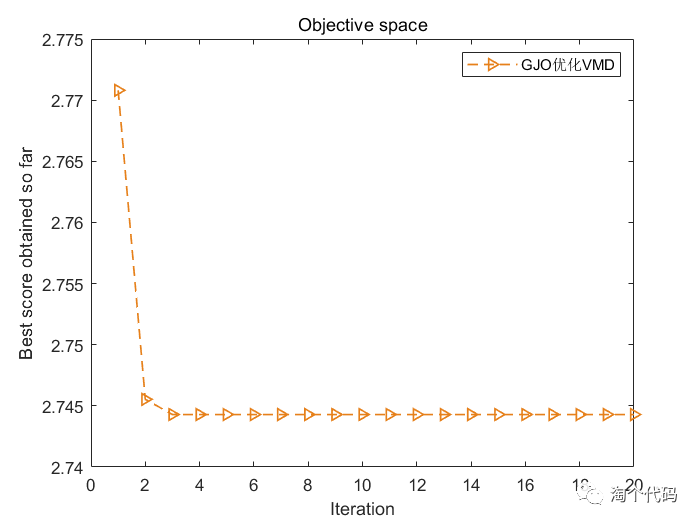
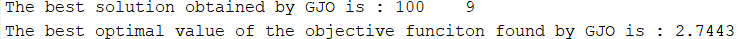
4.最小排列熵作为适应度函数
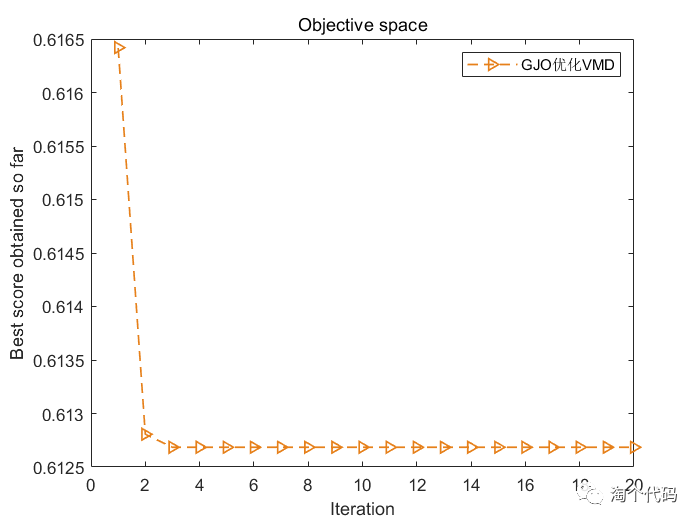
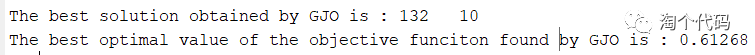
5.复合指标作为适应度函数
有关复合指标的介绍如下:

结果图:


6.包络谱峰值因子作为适应度函数
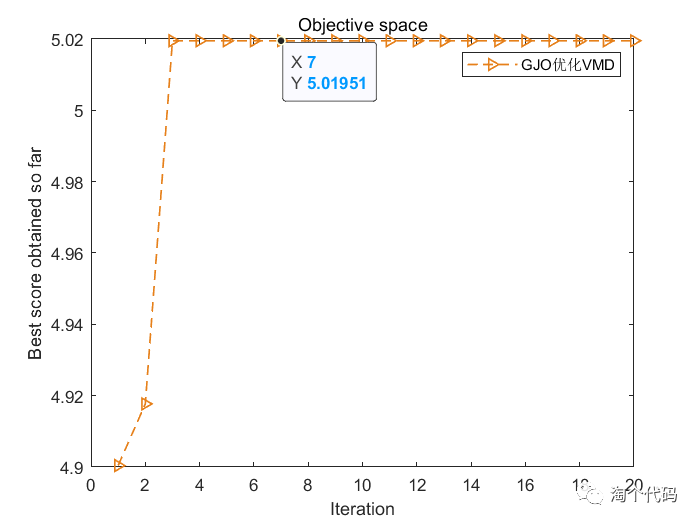
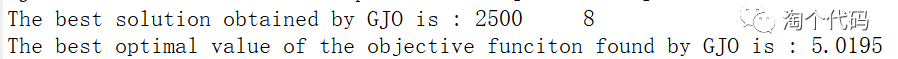
本文的部分代码
%% 以最小包络熵、最小样本熵、最小信息熵、最小排列熵,排列熵/互信息熵,包络谱峰值因子,为目标函数(任选其一),采用金豺算法优化VMD,求取VMD最佳的两个参数
clear
clc
close all
%选取数据
load 105.mat
data = X105_DE_time(6001:7000); %这里选取105的DEtime数据,注意这里替换为自己的数据即可,数据形式为n行*1列,列数必须为1。
%% 选取适应度函数类型
xz = 1;
% 选择1,以最小包络熵为适应度函数,
% 选择2,以最小样本熵为适应度函数,
% 选择3,以最小信息熵为适应度函数,
% 选择4,以最小排列熵为适应度函数,
% 选择5,以复合指标:排列熵/互信息熵为适应度函数。
% 选择6,以包络谱峰值因子为适应度函数。
if xz == 1 fobj=@(x)EnvelopeEntropyCost(x,data); %最小包络熵
elseif xz == 2fobj=@(x)SampleEntropyCost(x,data); %最小样本熵
elseif xz == 3 fobj=@(x)infoEntropyCost(x,data); %最小信息熵
elseif xz == 4fobj=@(x)PermutationEntropyCost(x,data); %最小排列熵
elseif xz == 5fobj=@(x)compositeEntropyCost(x,data); %复合指标:排列熵/互信息熵
elsefobj=@(x)Envelopepeakfactor(x,data); %复合指标:排列熵/互信息熵
end%% 设置参数
lb = [100 3]; %惩罚因子和K的下限
ub = [2500 10]; %惩罚因子和K的上限
dim = 2; % 优化变量数目
Max_iter=20; % 最大迭代数目
SearchAgents_no=30; %种群规模
%% 调用GJO函数
[GTO_bestfit, GJO_bestX, GJO_Convergence_curve] = GJO(SearchAgents_no,Max_iter,lb,ub,dim,fobj);
%% 画适应度函数曲线图,并输出最佳参数
if xz == 6GJO_Convergence_curve = -GJO_Convergence_curve;GTO_bestfit = -GTO_bestfit;
end
figure
plot(GJO_Convergence_curve,'Color',[0.9 0.5 0.1],'Marker','>','LineStyle','--','linewidth',1);title('Objective space')
xlabel('Iteration');
ylabel('Best score obtained so far');
legend('GJO优化VMD')
display(['The best solution obtained by GJO is : ', num2str(fix(GJO_bestX))]); %输出最佳位置
display(['The best optimal value of the objective funciton found by GJO is : ', num2str(GTO_bestfit)]); %输出最佳适应度值大家注意看到xz这个变量,当选择1,以最小包络熵为适应度函数,选择2,以最小样本熵为适应度函数,选择3,以最小信息熵为适应度函数,选择4,以最小排列熵为适应度函数,选择5,以复合指标:排列熵/互信息熵为适应度函数。,选择6,以包络谱峰值因子为适应度函数。这样大家切换起来就很方便了。
代码获取方式:支付后会显示网盘链接!

这篇关于金豺算法优化VMD参数,六种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵、包络谱峰值因子...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


