
相关文章

7. 深度强化学习:智能体的学习与决策
引言 深度强化学习结合了强化学习与深度学习的优势,通过智能体与环境的交互,使得智能体能够学习最优的决策策略。深度强化学习在自动驾驶、游戏AI、机器人控制等领域表现出色,推动了人工智能的快速发展。本篇博文将深入探讨深度强化学习的基本框架、经典算法(如DQN、策略梯度法),以及其在实际应用中的成功案例。 1. 强化学习的基本框架 强化学习是机器学习的一个分支,专注于智能体在与环境的交互过程中,学

强化网络安全:通过802.1X协议保障远程接入设备安全认证
随着远程办公和移动设备的普及,企业网络面临着前所未有的安全挑战。为了确保网络的安全性,同时提供无缝的用户体验,我们的 ASP 身份认证平台引入了先进的 802.1X 认证协议,确保只有经过认证的设备才能接入您的网络。本文档将详细介绍我们的平台如何通过 802.1X 协议实现高效、安全的远程接入认证。 产品亮点 1. 无缝集成 我们的 ASP 身份认证平台支持无缝集成到现有的网络基础设施中

强化学习和监督学习的一些区别
强化学习要求agent去探索环境,然后对状态进行evaluate,在每一个状态下agent可以选择多种action,每次选择的依据可以是贪婪或者softmax等,但是得到的reward是无法表明当前的选择是正确的还是错误的,得到的只是一个score,监督学习的labels可以给agent简洁明了的correct or wrong,并且在agent 在对环境充分的探索前即在每一种状态下选择的每个ac

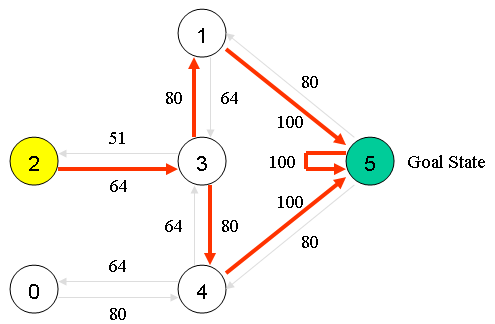
强化学习深入学习(一):价值函数和贝尔曼方程
文章目录 0. 引言1. 回报(Return)2. 价值函数(Value Function)3. 贝尔曼期望方程(Bellman Expectation Equation)4. 贝尔曼最优方程(Bellman Optimality Equation)总结 0. 引言 强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过与环境的交互来学习如何

数学建模强化宝典(10)多元线性回归模型
一、介绍 多元线性回归模型(Multiple Linear Regression Model)是一种用于分析多个自变量(解释变量、预测变量)与单个因变量(响应变量、被预测变量)之间线性关系的统计模型。这种模型假设因变量的变化可以通过自变量的线性组合来近似地表示,同时考虑了一个误差项来捕捉模型未能解释的变异性。 二、模型形式 多元线性回归模型的一般形式可以表示为: Y=β

如何通过Kimi强化论文写作中的数据分析?
在学术研究领域,数据分析是验证假设、发现新知识和撰写高质量论文的关键环节。Kimi,作为一款先进的人工智能助手,能够在整个论文写作过程中提供支持,从文献综述到数据分析,再到最终的论文修订。本文将详细介绍如何将Kimi的数据分析功能融入论文写作的各个阶段,以提高研究的准确性和论文的学术质量。 Kimi在论文写作中的作用 1. Kimi能够快速扫描和分析大量文献,提取关键信息,帮助研究者构建全面且
擅长领域python ,深度强化学习,人工智能,计算机等,可咨询
Python 深度学习 机器学,计算机视觉,自然语言处理,模型创新,算法改进,代码跑通,配置环境,可提供项目答疑和指导等服务,可做英文项目. 人工智能本硕接python代做,强化学习,深度学习,机器学习程序代写,环境调试,代码调通,模型优化,模型修改,数据处理等,项目主攻:Pytorch, Tensorflow, Yolo, Unet, DNN,CNN, GAN, Transformer,训练模

强化学习实践(二):Dynamic Programming(Value \ Policy Iteration)
强化学习实践(二):Dynamic Programming(Value \ Policy Iteration) 伪代码Value IterationPolicy IterationTruncated Policy Iteration 代码项目地址 伪代码 具体的理解可以看理论学习篇,以及代码中的注释,以及赵老师原著 Value Iteration Policy Itera
强化学习实践(一):Model Based 环境准备
强化学习实践(一):Model Based 环境准备 代码项目地址 代码 这里是Model Based的环境构建,原型是赵老师课上的Grid World import numpy as npfrom typing import Tuplefrom environment.utils import Utilsfrom environment.enums import Rewa