本文主要是介绍强化学习深入学习(一):价值函数和贝尔曼方程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 引言
- 1. 回报(Return)
- 2. 价值函数(Value Function)
- 3. 贝尔曼期望方程(Bellman Expectation Equation)
- 4. 贝尔曼最优方程(Bellman Optimality Equation)
- 总结
0. 引言
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过与环境的交互来学习如何采取行动,以最大化累积的回报。智能体的目标是找到最优策略 π ∗ \pi^* π∗,使得从任意状态 s s s 开始行动时,累积的期望回报最大。这个问题通常通过优化策略的方式来解决。
强化学习的基本概念
-
智能体(Agent): 强化学习的核心参与者,它通过与环境交互,选择行动并从中学习。智能体的目标是找到一个策略,使得在长期内获得的累积回报最大化。
-
环境(Environment): 智能体所处的外部世界。智能体与环境交互,通过执行动作改变环境状态,并接收来自环境的反馈(奖励和新状态)。
-
状态(State, s s s): 环境在某一时刻的具体情况或描述。状态可以是环境的完整描述,也可以是部分信息的表示。
-
动作(Action, a a a): 智能体在每个状态下可以采取的操作。动作会影响环境的状态,并引发反馈。
-
奖励(Reward, r r r): 环境对智能体采取某一动作的反馈。奖励是一个标量值,用于指示该动作的好坏。智能体的目标是最大化累积奖励。
-
策略(Policy, π \pi π): 智能体在每个状态下选择动作的规则或分布。策略可以是确定性的(在某状态下总是选择同一动作)或随机的(在某状态下根据概率选择动作)。
-
回报(Return, G G G): 从某一时刻开始,智能体获得的累积奖励。通常使用折扣因子 γ \gamma γ 来对未来的奖励进行折扣计算。
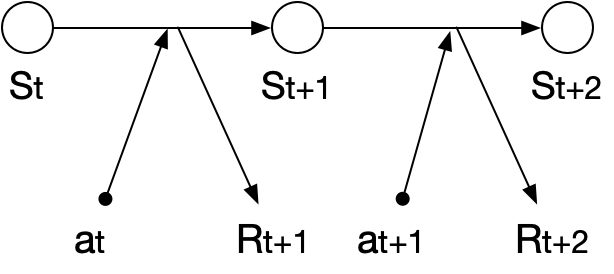
强化学习的工作流程
-
初始状态: 智能体从环境中感知当前的状态 s t s_t st。
-
动作选择: 基于当前策略 π \pi π,智能体选择一个动作 a t a_t at。
-
执行动作: 智能体执行动作 a t a_t at,该动作影响环境并导致状态转移。
-
反馈接收: 环境反馈给智能体一个奖励 r t + 1 r_{t+1} rt+1 以及新的状态 s t + 1 s_{t+1} st+1。
-
更新策略: 智能体利用获得的反馈更新策略,使得将来在类似情形下能做出更好的选择。
-
重复: 过程重复,直到智能体达到目标或学习结束。
1. 回报(Return)
回报是指在某个状态下开始,经过一系列行动后获得的累积奖励(Reward)。在时间步 t t t 时的回报通常表示为 G t G_t Gt。
对于无折扣的情况,总回报为:
G t = R t + 1 + R t + 2 + R t + 3 + ⋯ = ∑ k = 0 ∞ R t + k + 1 G_t = R_{t+1} + R_{t+2} + R_{t+3} + \cdots = \sum_{k=0}^{\infty} R_{t+k+1} Gt=Rt+1+Rt+2+Rt+3+⋯=k=0∑∞Rt+k+1
如果使用折扣因子 γ \gamma γ(其中 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1)来表示未来奖励的重要性,回报可以表示为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1
这里, γ \gamma γ 控制了未来奖励对当前回报的影响程度。当 γ \gamma γ 越接近 1,越更加重视长期奖励;当 γ \gamma γ 越接近 0,则更加关注短期奖励。
2. 价值函数(Value Function)
价值函数用来评估一个状态或状态-动作对的好坏。价值函数有两种主要形式:
(1)状态价值函数(State Value Function, V ( s ) V(s) V(s)):表示在状态 s s s 下,按照某一策略 π \pi π 行动时,未来回报的期望值。
V π ( s ) = E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] V_{\pi}(s) = \mathbb{E}_{\pi} \left[ G_t \mid S_t = s \right] = \mathbb{E}_{\pi} \left[ \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \mid S_t = s \right] Vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣St=s]
(2)动作价值函数(Action Value Function, Q ( s , a ) Q(s, a) Q(s,a)):表示在状态 s s s 下采取动作 a a a 并且随后按照某一策略 π \pi π 行动时,未来回报的期望值。
Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q_{\pi}(s, a) = \mathbb{E}_{\pi} \left[ G_t \mid S_t = s, A_t = a \right] Qπ(s,a)=Eπ[Gt∣St=s,At=a]
下面说明状态价值函数 V π ( s ) V_{\pi}(s) Vπ(s) 和动作价值函数 Q π ( s , a ) Q_{\pi}(s, a) Qπ(s,a) 之间通过策略 π \pi π 联系在一起。 V π ( s ) V_{\pi}(s) Vπ(s) 可以被视为在当前状态下所有可能动作的 Q π ( s , a ) Q_{\pi}(s, a) Qπ(s,a) 的加权平均。
3. 贝尔曼期望方程(Bellman Expectation Equation)
贝尔曼期望方程将价值函数表示为当前奖励与未来状态的价值之间的关系。
(1)状态价值函数的贝尔曼期望方程:
V π ( s ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] V_{\pi}(s) = \mathbb{E}_{\pi} \left[ R_{t+1} + \gamma V_{\pi}(S_{t+1}) \mid S_t = s \right] Vπ(s)=Eπ[Rt+1+γVπ(St+1)∣St=s]
这表示在状态 s s s 下的价值等于当前行动得到的即时奖励与未来状态的折扣价值的期望值。
(2)动作价值函数的贝尔曼期望方程:
Q π ( s , a ) = E [ R t + 1 + γ E π [ Q π ( S t + 1 , A t + 1 ) ∣ S t + 1 ] ∣ S t = s , A t = a ] Q_{\pi}(s, a) = \mathbb{E} \left[ R_{t+1} + \gamma \mathbb{E}_{\pi} \left[ Q_{\pi}(S_{t+1}, A_{t+1}) \mid S_{t+1} \right] \mid S_t = s, A_t = a \right] Qπ(s,a)=E[Rt+1+γEπ[Qπ(St+1,At+1)∣St+1]∣St=s,At=a]
这里, Q π ( s , a ) Q_{\pi}(s, a) Qπ(s,a) 表示在状态 s s s 下采取动作 a a a 后,立即获得的奖励加上下一状态的期望价值。
4. 贝尔曼最优方程(Bellman Optimality Equation)
贝尔曼最优方程用于描述最优策略下的状态或动作的价值。
(1)最优状态价值函数的贝尔曼方程:
V ∗ ( s ) = max a E [ R t + 1 + γ V ∗ ( S t + 1 ) ∣ S t = s , A t = a ] V_*(s) = \max_a \mathbb{E} \left[ R_{t+1} + \gamma V^*(S_{t+1}) \mid S_t = s, A_t = a \right] V∗(s)=amaxE[Rt+1+γV∗(St+1)∣St=s,At=a]
这意味着在最优策略下,状态 s s s 的价值是通过选择在该状态下的最佳行动所获得的即时奖励和后续状态的最优价值来决定的。
(2)最优动作价值函数的贝尔曼方程:
Q ∗ ( s , a ) = E [ R t + 1 + γ max a ′ Q ∗ ( S t + 1 , a ′ ) ∣ S t = s , A t = a ] Q_*(s, a) = \mathbb{E} \left[ R_{t+1} + \gamma \max_{a'} Q^*(S_{t+1}, a') \mid S_t = s, A_t = a \right] Q∗(s,a)=E[Rt+1+γa′maxQ∗(St+1,a′)∣St=s,At=a]
这里, Q ∗ ( s , a ) Q_*(s, a) Q∗(s,a) 表示在状态 s s s 下采取动作 a a a 后,立即获得的奖励加上后续状态的最优行动价值。
总结
(1)回报 G t G_t Gt 是从某个时间步开始所能获得的累积奖励。
(2)价值函数 V ( s ) V(s) V(s) 和 Q ( s , a ) Q(s, a) Q(s,a) 用于评估状态或动作的长期好坏。
(3)贝尔曼期望方程 将价值函数与未来的期望回报联系起来,表达策略下的期望价值。
(4)贝尔曼最优方程 则用于找到最优策略下的最大期望回报。
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤

这篇关于强化学习深入学习(一):价值函数和贝尔曼方程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



