本文主要是介绍R语言信用风险回归模型中交互作用的分析及可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全文链接:http://tecdat.cn/?p=21892
相关视频
引言
多元统计分析中,交互作用是指某因素作用随其他因素水平的不同而不同,两因素同时存在是的作用不等于两因素单独作用之和(相加交互作用)或之积(相乘交互作用)。通俗来讲就是,当两个或多个因素同时作用于一个结局时,就可能产生交互作用,又称为效应修饰作用(effect modification)。当两个因素同时存在时,所导致的效应(A)不等于它们单独效应相加(B+C)时,则称因素之间存在交互作用。当A=B+C时称不存在交互效应;当A>B+C时称存在正交互作用,又称协同作用(Synergy)。
在一个回归模型中,我们想写的是
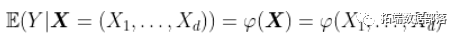
当我们限制为线性模型时,我们写
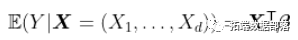
或者
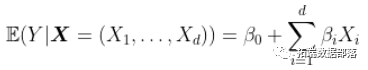
但是我们怀疑是否缺少某些因素……比如,我们错过所有可能的交互影响。我们可以交互变量,并假设
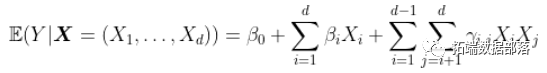
可以进一步扩展,达到3阶
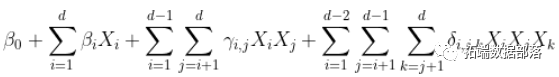
甚至更多。
假设我们的变量 Xi 在这里是定性的,更确切地说是二元的。
信贷数据
让我们举一个简单的例子,使用信贷数据集。
Credit数据是根据个人的银行贷款信息和申请客户贷款逾期发生情况来预测贷款违约倾向的数据集,数据集包含24个维度的,1000条数据。
该数据集将通过一组属性描述的人员分类为良好或不良信用风险。
数据集将通过一组属性描述的人员分类为良好或不良信用风险。
建立模型
我们读取数据
db=Credit我们从三个解释变量开始,
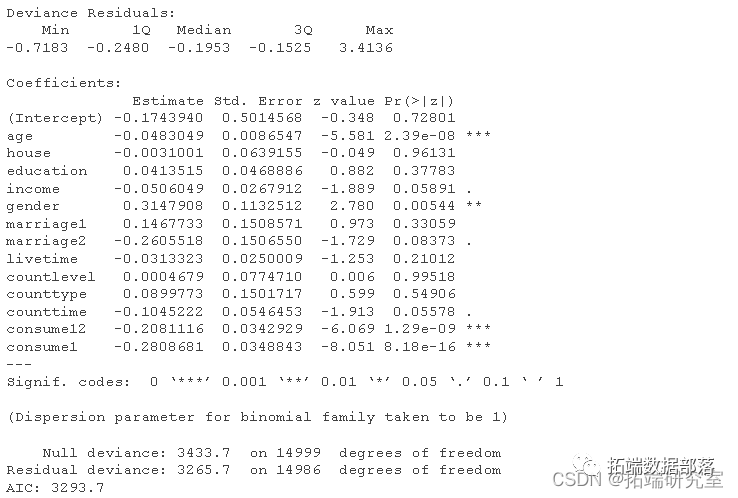
reg=glm(Y~X1+X2+X3,data=db,family=binomial)
summary(reg)没有交互的回归长这样
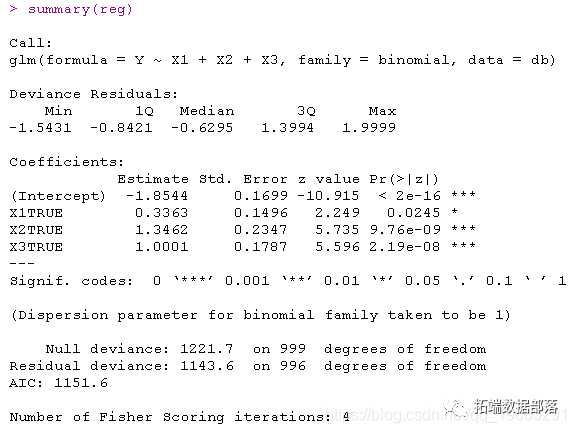
这里有几种可能的交互作用(限制为成对的)。进行回归时观察到:

交互关系可视化
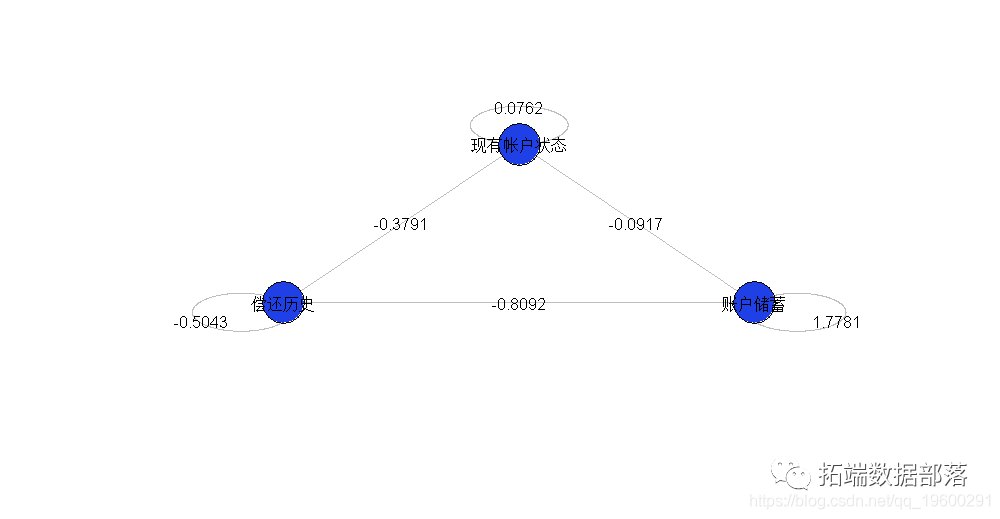
我们可以画一幅图来可视化交互:我们有三个顶点(我们的三个变量),并且可视化了交互关系
plot(sommetX,sommetY,cex=1,axes=FALSE,xlab="",ylab="",for(i in 1:nrow(indices)){
segments(sommetX[indices[i,2]],sommetY[indices[i,2]],
text(mean(sommetX[indices[i,2:3]]),mean(sommetY[indices[i,2:3]]),
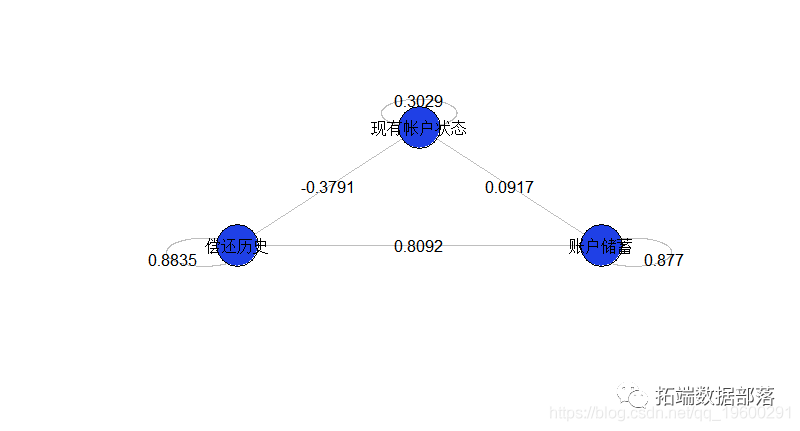
}text(sommetX,sommetY,1:k)这给出了我们的三个变量
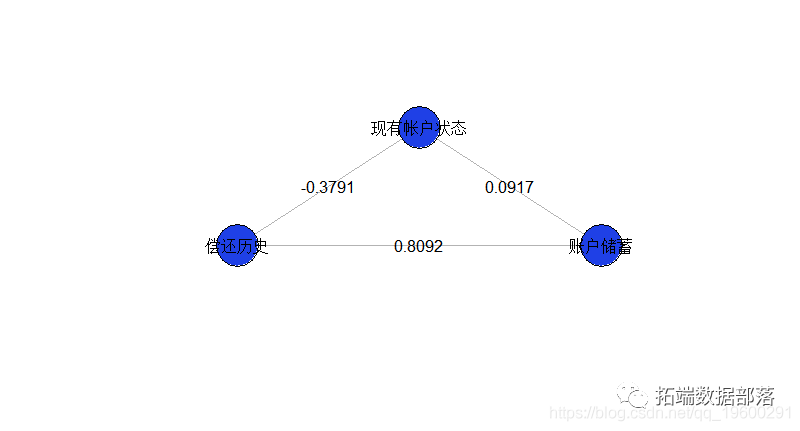
这个模型似乎是不完整的,因为我们仅成对地看待变量之间的相互作用。实际上,这是因为(在视觉上)缺少未交互的变量。我们可以根据需要添加它们
点击标题查阅往期内容

R语言VaR市场风险计算方法与回测、用LOGIT逻辑回归、PROBIT模型信用风险与分类模型

左右滑动查看更多
01
02
03
04
reg=glm(Y~X1+X2+X3+X1:X2+X1:X3+X2:X3,data=db,family=binomial)
k=3
theta=pi/2+2*pi*(0:(k-1))/k
plot(X,Y
for(i in 1:nrow(indices)){
segments(X[indices[i,2]],Y[indices[i,2]],
for(i in 1:k){
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18),.18)
text(cos(theta)[i]*1.35,sin(theta)[i]*1.35,
points(X,Y,cex=6,pch=1)这里得到
如果我们更改变量的“_含义_”(通过重新编码,通过排列真值和假值),将获得下图
glm(Y~X1+X2+X3+X1:X2+X1:X3+X2:X3,data=dbinv,family=binomial)
plot(sommetX,sommetY,cex=1
for(i in 1:nrow(indices)){
segments(sommetX[indices[i,2]]
for(i in 1:k){
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18)points(sommetX,sommetY,cex=6,pch=19)然后可以将其与上一张图进行比较
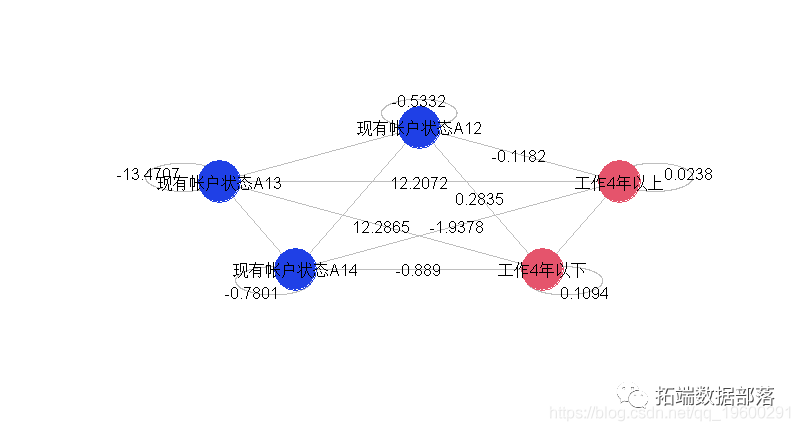
使用5个变量,我们增加了可能的交互作用。
然后,我们修改前面的代码
formule="Y~1"
for(i in 1:k) formule=paste(formule,"+X",i,sep="")
for(i in 1:nrow(indices)) formule=paste(formule,"+X",indices[i,2],":X",indices[i,3],sep="")
reg=glm(formule,data=db,family=binomial)
plot(sommetX,sommetY,cex=1
for(i in 1:nrow(indices)){
segments(sommetX[indices[i,2]],sommetY[indices[i,2]],
for(i in 1:k){
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18)
points(sommetX,sommetY,cex=6给出了更复杂的图,
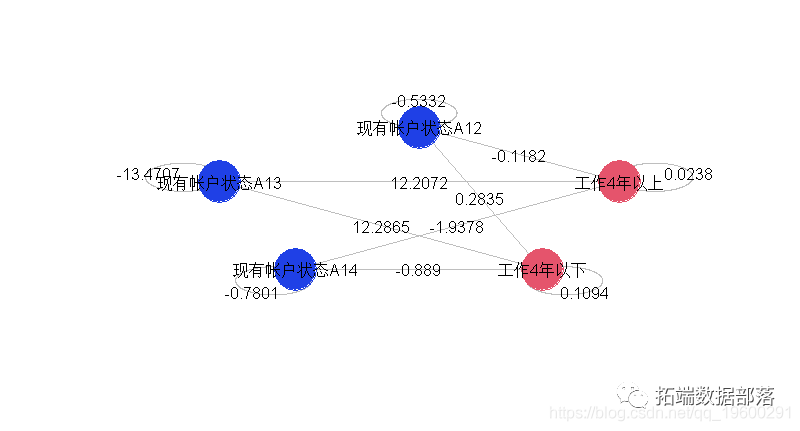
我们也可以只采用2个变量,分别取3和4种指标。为第一个提取两个指标变量(其余形式为参考形式),为第二个提取三个指标变量
formule="Y~1"
for(i in 1:k) formule=paste(formule,"+X",i,sep="")
for(i in 1:nrow(indices)formule=paste(formule,"+X",indices[i,2],":X",indices[i,3],sep="")
reg=glm(formule,data=db,family=binomial)
for(i in 1:nrow(indices){
if(!is.na(coefficients(reg)[1+k+i])){
segments(X[indices[i,2]],Y[indices[i,2]],
}
for(i in 1:k){
cercle(c(cos(theta)[i]*1.18,sin(theta)[i]*1.18),.18)
text(cos(theta)[i]*1.35,sin(theta)[i]*1.35,
}我们看到,在左边的部分(相同变量的三种指标)和右边的部分不再有可能发生交互作用。
我们还可以通过仅可视化显著交互来简化图形。
for(i in 1:nrow(indices)){
if(!is.na(coefficients(reg)[1+k+i])){
if(summary(reg)$coefficients[1+k+i,4]<.1){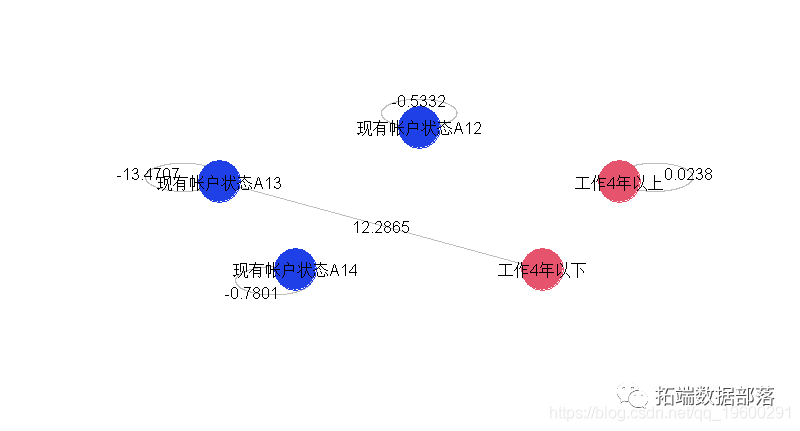
在这里,只有一个交互作用是显著的,几乎所有的变量都是显著的。如果我们用5个因子重新建立模型,
for(i in 1:nrow(indices))
formule=paste(formule,"+X",indices[i,2],":X",indices[i,3],sep="")
reg=glm(formule,data=db,family=binomial)for(i in 1:nrow(indices){
if(!is.na(coefficients(reg)[1+k+i])){
if(summary(reg)$coefficients[1+k+i,4]<.1){我们得到
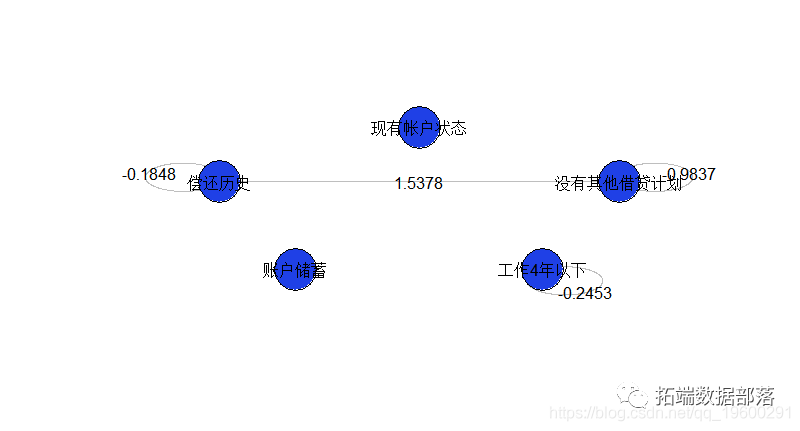

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言信用风险回归模型中交互作用的分析及可视化》。

本文中的信贷数据分享到会员群,扫描下面二维码即可加群!

点击标题查阅往期内容
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
使用贝叶斯层次模型进行空间数据分析
MCMC的rstan贝叶斯回归模型和标准线性回归模型比较
python贝叶斯随机过程:马尔可夫链Markov-Chain,MC和Metropolis-Hastings,MH采样算法可视化
Python贝叶斯推断Metropolis-Hastings(M-H)MCMC采样算法的实现
matlab贝叶斯隐马尔可夫hmm模型实现
贝叶斯线性回归和多元线性回归构建工资预测模型
Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
R语言STAN贝叶斯线性回归模型分析气候变化影响北半球海冰范围和可视化检查模型收敛性
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言JAGS贝叶斯回归模型分析博士生延期毕业完成论文时间
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
随机森林优化贝叶斯预测分析汽车燃油经济性
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
Python贝叶斯回归分析住房负担能力数据集
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python用PyMC3实现贝叶斯线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言Gibbs抽样的贝叶斯简单线性回归仿真分析
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言贝叶斯线性回归和多元线性回归构建工资预测模型
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言stan进行基于贝叶斯推断的回归模型
R语言中RStan贝叶斯层次模型分析示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
视频:R语言中的Stan概率编程MCMC采样的贝叶斯模型
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计

![]()

这篇关于R语言信用风险回归模型中交互作用的分析及可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



