本文主要是介绍语音合成论文优选:Fre-GAN: Adversarial Frequency-consistent Audio Synthesis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要对文章简略概括。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
低调奋进迎来新的伙伴加入,本文由迎风飞扬进行文章的分享,欢迎更多伙伴的加入。
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
此篇文章是Department of Artificial Intelligence, Korea University, Seoul, Korea在2021.6.6日发表的文章,主要是在HifiGAN的基础上,改进了生成器和判别器,可以提高生成语音的MOS值。具体文章链接 https://arxiv.org/abs/2106.02297
1、研究背景
尽管最近的声码器已经极大的提升了合成语音的音质,但是与GT相比在频谱上仍然存在gap。这样的一种差别就会导致 spectral artifacts 比如说hissing noise or robotic sound, 从而会导致音质的下降.
为此,提出了FreGAN,它可以输出高质量的音频,与GT相比在MOS上只有0.03的差别。
2、详细设计
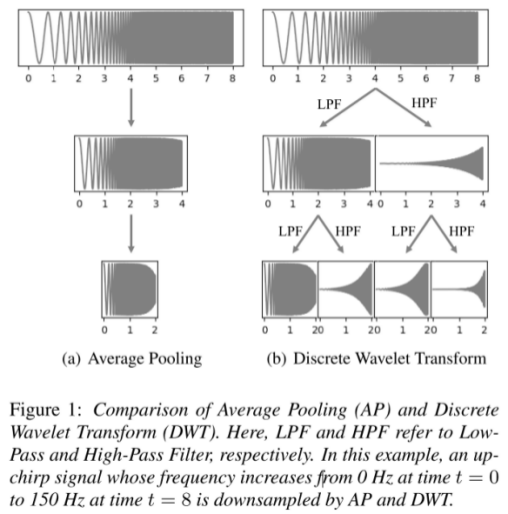
FreGAN采用了 RCG(resolution-connected generator) 和 resolution-wise discriminators 来学习频谱上的不同频段。由于传统的下采样方法(比如average pool)忽略了高频部分,为此作者采用了DWT(离散小波变换)保留了所有的信息并且保持了正交性。
生成器
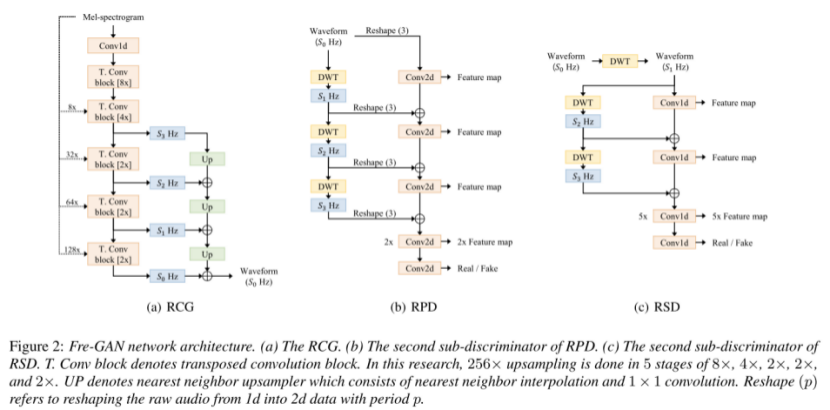
与HiFiGAN不同的是,作者采用了RCG,如下图所示,Up模块采用了Nearest Neighbor (NN) upsampler ,NN已经被证明了可以有效的缓解由于transpose conv引起的artifacts.
RCG的优势在于:
1)可以有效的捕捉到不同频带的信息
2)在训练过程中,刚开始主要是建模低分辨率部分,训练过程中逐渐将注意力转移到高分辨率部分
判别器
与HiFiGAN类似,采用了两个判别器,Resolution-wise MPD (RPD) and Resolution-wise MSD (RSD),不同的是采用了DWT做了分解,不损失任何信息。
DWT
为了不损失高频部分,用DWT替换了AP,如下图所示,可以清楚的看到DWT并没有损失任何信息,而AP每次下采样后都损失了高频部分。在DWT过程中,信号会经过两个滤波器low-pass filter (g) 和high-pass filter (h)
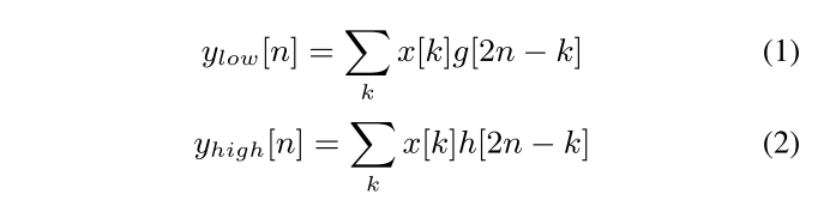
训练
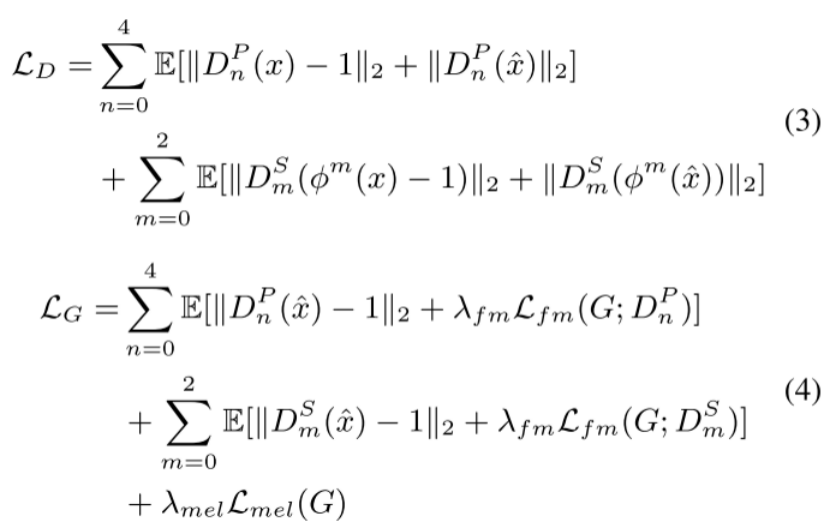
3、实验结果
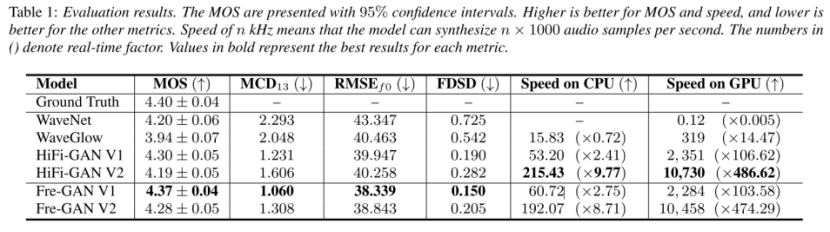
从Table1可以看出,FreGAN要的效果要优于其他模型,在推理速度上比HiFiGAN略微有些降低。
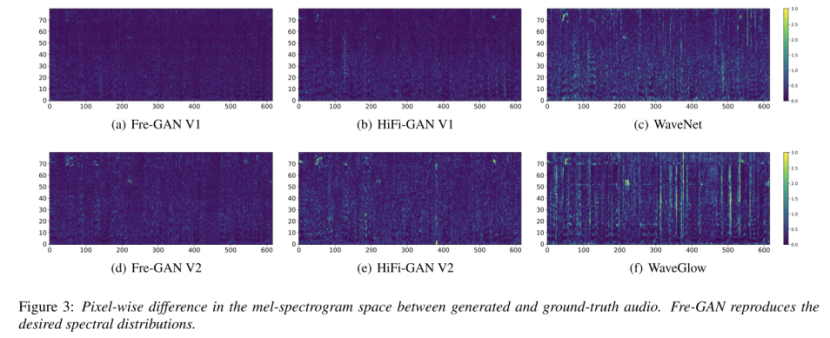
从Figure3可以看出,FreGAN生成的音频相比较于其他模型,在高频上与GT的差别比较小
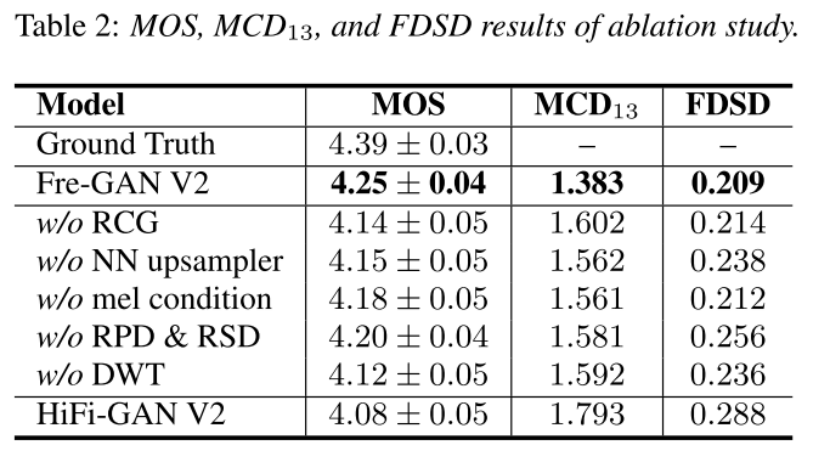
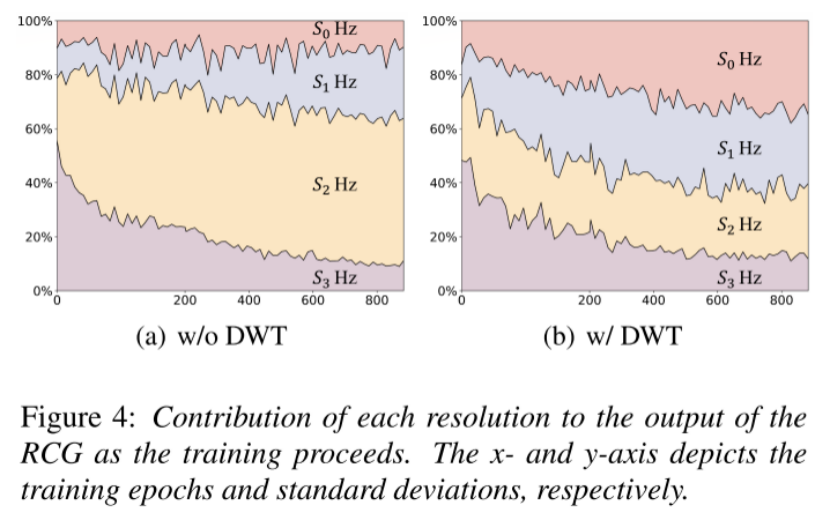
从Table2可以看出,采用DWT对音频的MOS影响最大。从Figure4可以看出,随着训练时间的推移,模型更专注于高频部分。
4、总结
作者提出了一种新的生成器和判别器结构,可以提升合成音频的MOS值,最核心思想就是采用了DWT(当然,其他模块比如NN,RCG等都对模型效果都有提升),它可以将信号分解成高频和低频部分,分别送入判别器中,与传统的Average Pool相比,没有任何信息损失,可以更好的重建高频部分。论文不足的地方,就是采用的GT谱进行MOS评测,并没有给出采用声学模型预测谱的MOS比对。
这篇关于语音合成论文优选:Fre-GAN: Adversarial Frequency-consistent Audio Synthesis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






