本文主要是介绍在一个循环链队中只有尾指针(记为rear,结点结构为数据域data,指针域next),请给出这种队列的入队和出队操作实现过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在一个循环链队中只有尾指针(记为rear,结点结构为数据域data,指针域next),请给出这种队列的入队和出队操作实现过程
入队过程如下图:
先创一个结点,用于存储要插入的结点数据
然后就是老套路了:先连后断
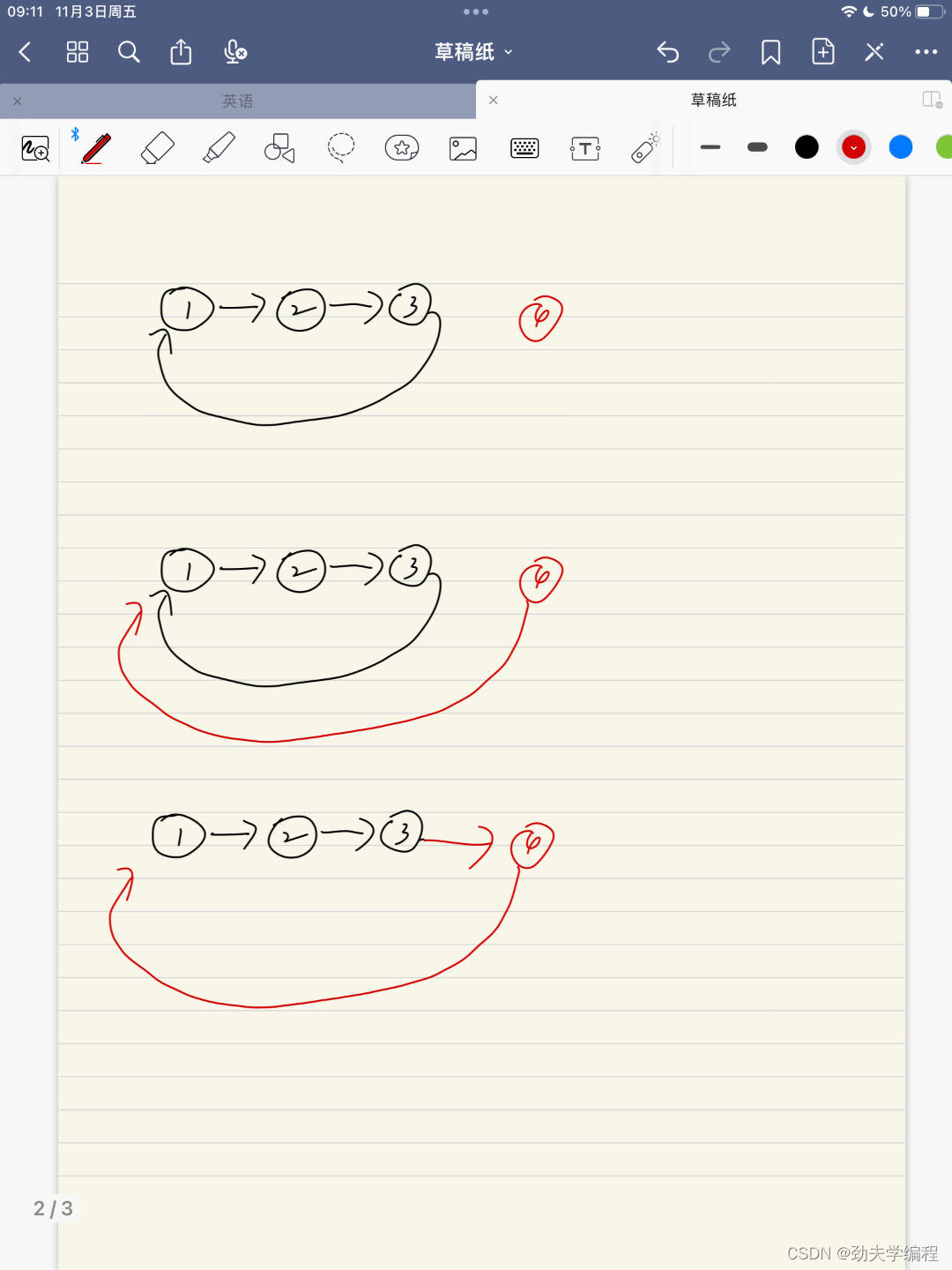
void EnQueue(LinkQueue* Q,int x){QueuePtr s=(QueuePtr)malloc(sizeof(QNode));//malloc申请一个QNode结点大小的空间,然后用指针s指向它s->data=x;//把x值赋到结点里面if(Q->rear==NULL){//队列为空,新加入的s结点成为唯一结点Q->rear=s;Q->rear->rear=Q->rear;//唯一一个结点就自己指向自己形成一个环}else{s->next=Q->rear->next;//先连:s的next指向rear的next(也就是头结点)Q->rear->next=s;//后断,当前rear的next指向sQ->rear=s;//s成为新的rear}}
出队过程如下图:
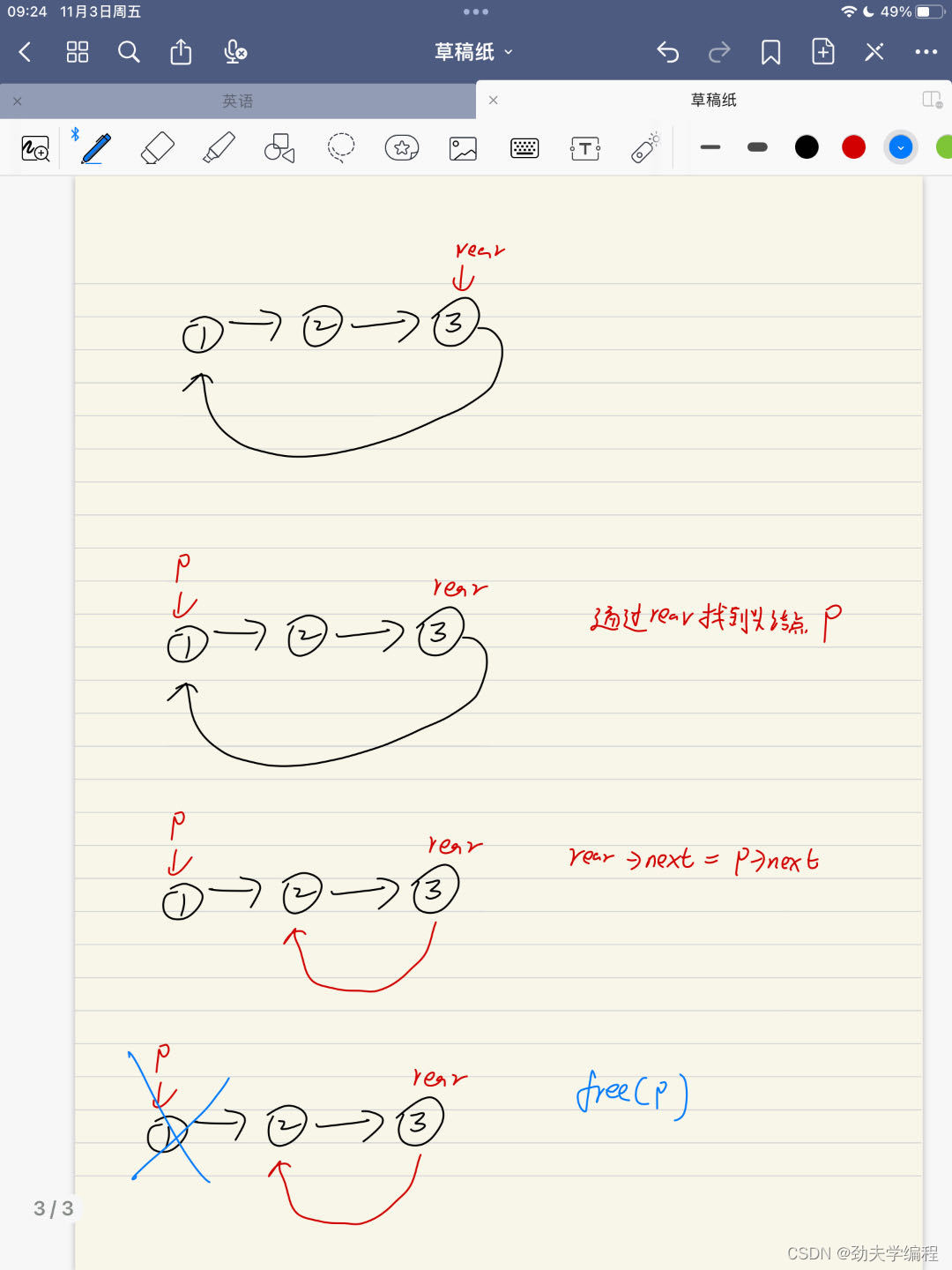
void DeQueue(LinkQueue* Q){QueuePtr p;if(Q->rear==NULL){//空队列,没办法出队printf("队列为空,无法出队");return;}if(Q->rear->next==Q->rear){//队列中只有一个元素p=Q->rear;//用p记录rear位置,再free掉free(p);Q->rear=NULL;//最后rear置空}else{//队列还有一些元素p=Q->rear->next;//通过rear找到头结点赋给pQ->rear->next=p->next;//rear连上头结点下一个结点free(p);//把p释放掉}
}
这篇关于在一个循环链队中只有尾指针(记为rear,结点结构为数据域data,指针域next),请给出这种队列的入队和出队操作实现过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








