本文主要是介绍基于bert预训练高中知识点的单轮对话机器人,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码和数据集下载链接:
基于bert预训练的高中知识点单轮对话机器人-自然语言处理文档类资源-CSDN下载
代码主要流程

对话机器人工作流程
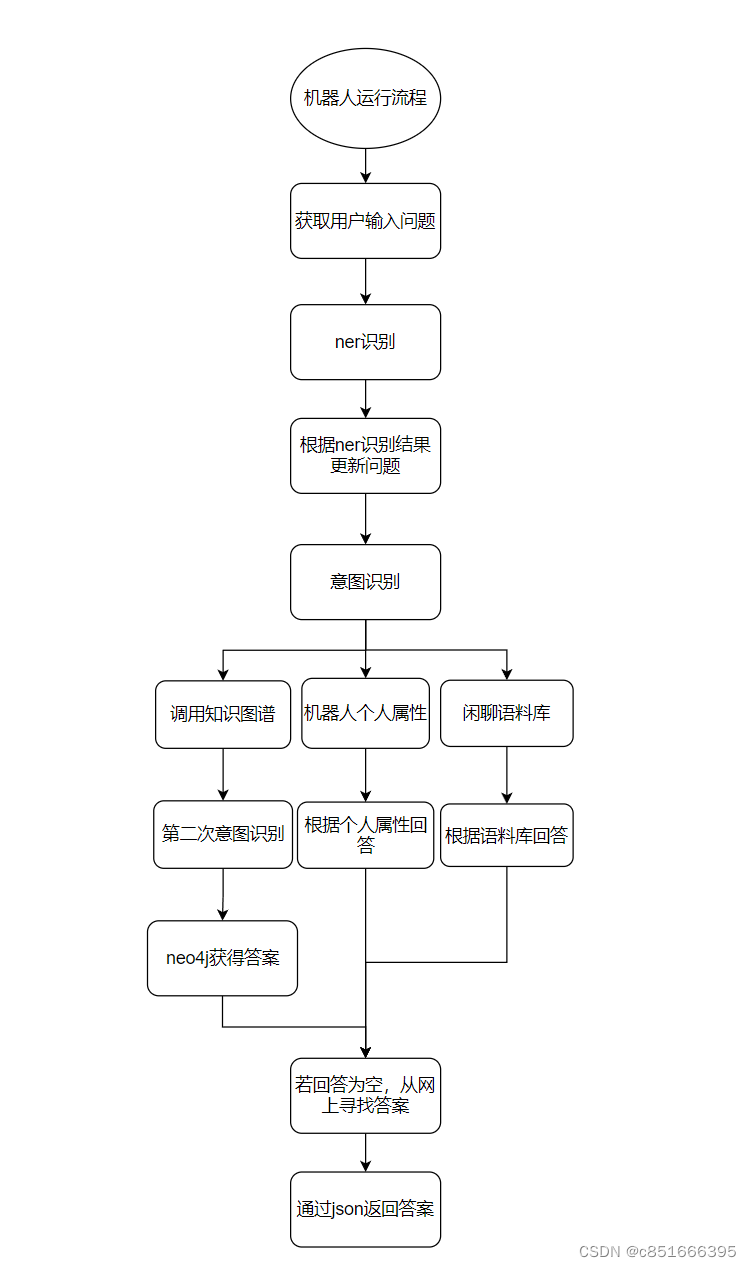
1 清洗数据
import os
import numpy as np
import pandas as pddicts = {}
error_num = 0
uppath = "原始数据\\"
outpath = "数据生成\\"
subjects = ["高中地理", "高中历史", "高中生物", "高中政治"]
error = []for subject in subjects:dicts[subject] = {}for i in os.listdir(os.path.join(uppath, subject, "origin\\")): # 查看子目录dicts[subject][i.split(".")[0]] = []data = pd.read_csv(os.path.join(uppath, subject, "origin\\", i)).item # 读取item列for j in data:j = j.split("\n")if len(j) == 4: # 题目,题目内容,知识点,知识点内容questions = j[1].replace("知识点:", "") # 问题内容清洗kg = j[3].split(",") # 多个知识点 以逗号分开dicts[subject][i.split(".")[0]].append([questions, kg])elif len(j) > 4:questions = []questions_key = Falsekg = []kg_key = Falsefor tmp in j:if "[题目]" == tmp:questions_key = True # 说明后面跟着就是题目内容continueif "[知识点:]" == tmp:questions_key = Falsekg_key = Truecontinueif questions_key:questions.append(tmp)if kg_key:kg.append(tmp)if len(kg) > 0:questions = ''.join(questions).replace("知识点:", "")kg = "".join(kg).split(",") # 多个知识点dicts[subject][i.split(".")[0]].append([questions, kg])else:error_num += 1error.append([subject, i, j])else:error_num += 1error.append([subject, i, j])os.mkdir(outpath) if not os.path.exists(outpath) else 1# 也可在数据清理中完成
data_new = []
for km1 in dicts: # 主课程for km2 in dicts[km1]: # 子课程for data in dicts[km1][km2]: # 知识点for kg in data[1]: # 一个知识点给一个题目data_new.append([km1, km2, kg, data[0]]) #[主课程, 子课程, 知识点, 题目]data_new = pd.DataFrame(data_new)
data_new.columns = ["km1", "km2", "kg", "question"]
data_new.to_csv(outpath+"km.csv", index=False)2 构建实体表和关系表
2.1 构建知识点实体表和关系表
import pandas as pd
import numpy as np
import os
import random# 设置随机数种子
random.seed(2)def long_num_str(data): # 把数字转为strdata = str(data) + "\t"return dataoutpath = "数据生成\\"
data = pd.read_csv(outpath+"km.csv")# 实体表
entity = None
for i in data: # 列名names = list(set(eval("data."+i))) # 每一列去重复ids = [hash(j) for j in names] # hash值labels = [i for j in names] # 标签都是列名if entity is None:entity = pd.DataFrame(np.array([ids, names, labels]).transpose())else:entity = entity.append(pd.DataFrame(np.array([ids, names, labels]).transpose())) # 添加 不是在原有数据集上添加 有返回值entity.columns = [":ID", "name", ":LABEL"]
entity[":ID"] = entity[":ID"].map(long_num_str) # 数字转为str# 保存
os.mkdir(outpath) if not os.path.exists(outpath) else 1
entity.to_csv(outpath+'entity_km.csv', index = False)# 关系表relation = Nonefor i in [[data.keys()[tmp], data.keys()[tmp+1]] for tmp in range(len(data.keys())-1)]:# i ['km1', 'km2'] ['km2', 'kg'] ['kg', 'question']tmp = data[i]tmp = tmp.drop_duplicates(subset=i[1], keep="first", inplace=False) # 在i[1]上去重start = [hash(j) for j in eval("tmp."+i[0])] # i[0] 一样时 hash值也一样end = [hash(j) for j in eval("tmp."+i[1])]# 列名1 -> 列名2name = [i[0] + '->' + i[1] for j in range(len(tmp))]if relation is None:relation = pd.DataFrame(np.array([start, name, end, name]).transpose())else:relation = relation.append(pd.DataFrame(np.array([start, name, end, name]).transpose()))relation.columns = [":START_ID", "name", ":END_ID", ":TYPE"]
relation[':START_ID'] = relation[':START_ID'].map(long_num_str)
relation[':END_ID'] = relation[':END_ID'].map(long_num_str)#保存relation.to_csv(outpath + "relation_km.csv", index=False)2.2 构建古诗词实体表和关系表
import pandas as pd
import numpy as np
import os
import random# 设置随机数种子
random.seed(2)def long_num_str(data): # 把数字转为strdata = str(data) + "\t"return data# 生成实体表
poems = pd.read_csv('原始数据/古诗/诗句.csv')
poets = pd.read_csv('爬虫清洗后数据/poets.csv')
poets = dict(zip(poets.poet, poets.introduce))
introduce = []
outpath = "数据生成\\"for i in poems.author:if i in poets: # poets清洗了一部分数据introduce.append(poets[i])else:introduce.append(np.nan)
poems["introduce"] = introduce # 增加列# eval 转为list
max_len = max([len(eval(i)) for i in poems['tag'] if type(i) == type('')])tag = []
for i in poems["tag"]:if type(i) == type(''): # 不为空i = eval(i)i += [np.nan]*(max_len - len(i))else:i = [np.nan]*max_lentag.append(i)# 添加列
poems[["tag-" + str(i) for i in range(max_len)]] = pd.DataFrame(tag)
# 去掉原来的tag列
poems = poems[['author', 'introduce', 'title', 'content', 'type', 'translate', 'class'] + ['tag-' + str(i) for i in range(max_len)]]entity = None
for i in poems:names = list(set(eval(f"poems['{i}']")))ids = [hash(j) for j in names]if 'tag-' in i:i = 'tag'labels = [i for j in names] # labelif entity is None:entity = pd.DataFrame(np.array([ids, names, labels]).transpose())else:entity = entity.append(pd.DataFrame(np.array([ids, names, labels]).transpose()))entity.columns = [':ID', 'name', ':LABEL']
entity[':ID'] = entity[':ID'].map(long_num_str)#保存
os.mkdir(outpath) if not os.path.exists(outpath) else 1
poems.to_csv(outpath+'poems.csv', index=False) # 保存这里的poem表
entity.to_csv(outpath+'entity_poems.csv', index=False)# 生成关系表relation = Nonepoems = pd.read_csv(outpath+'poems.csv')for i in [['author','title'],['author','introduce'],['title','content'],['title','translate'],['type','title'],['class','title']]+[['tag-'+str(i),'title'] for i in range(7)]: # 关系表tmp = poems[i]tmp = tmp.dropna() # 只要有一个为空就去除# 去重tmp = tmp.drop_duplicates(subset=[i[0], i[1]] , keep='first',inplace=False)start = [hash(j) for j in eval(f'tmp["{i[0]}"]')]end = [hash(j) for j in eval(f'tmp["{i[1]}"]')]if 'tag-' in i[0]:i[0] = 'tag'name = [i[0] + "->" + i[1] for j in range(len(tmp))]if relation is None:relation = pd.DataFrame(np.array([start, name, end, name]).transpose())else:relation = relation.append(pd.DataFrame(np.array([start, name, end, name]).transpose()))relation.columns = [':START_ID', 'name', ':END_ID', ':TYPE']
relation[':START_ID'] = relation[':START_ID'].map(long_num_str) # id从数字转为str
relation[':END_ID'] = relation[':END_ID'].map(long_num_str)#保存
relation.to_csv(outpath+'relation_poems.csv', index = False)2.3 分别整合实体表和关系表
import pandas as pd
import numpy as np
import os
path = "数据生成\\"
file_list = ["km", "poems"]
entity_list = None
relation_list = None
for i in file_list:if entity_list is None:entity_list = pd.read_csv(path + "entity_" + i +".csv", dtype=str)relation_list = pd.read_csv(path + "relation_" + i +".csv", dtype=str)else:entity_list = entity_list.append(pd.read_csv(path + "entity_" + i +".csv", dtype=str)) # 对pandas append 是要返回接收的relation_list = relation_list.append(pd.read_csv(path + "relation_" + i +".csv", dtype=str))# 统一去重
entity_com = entity_list.drop_duplicates(subset=":ID", keep="first", inplace=False)
relation_com = relation_list.drop_duplicates(subset=[':START_ID', 'name', ':END_ID', ':TYPE'], keep="first", inplace=False) # 得用单引号# 保存
os.mkdir(path + "实体表和关系表\\") if not os.path.exists(path + "实体表和关系表\\") else 1
# entity[":ID"] = entity[":ID"].map(long_num_str) # 数字转为str
entity_com.to_csv(path + "实体表和关系表\\entity.csv", index=False)
relation_com.to_csv(path + "实体表和关系表\\relation.csv", index=False)3 准备训练数据
3.1 ner训练数据和第二次意图识别训练数据
# 构建ner实体数据集
import pandas as pd
import os
path = "数据生成/实体表和关系表/"
outpath = "数据生成/命名实体识别和意图识别数据/"data = pd.read_csv(path + "entity.csv")index = data[":LABEL"].isin(["km1", "km2", "kg", "author", "title", "tag", "type", "class"])
data = data[index]
ner_data = data[["name", ":LABEL"]]
ner_data.columns = ['name', 'label']
#保存
os.mkdir(outpath) if not os.path.exists(outpath) else 1
# ner_data.to_csv(outpath + "ner_entity.csv", index= False)import pandas as pd
path = "数据生成/命名实体识别和意图识别数据/"
data = pd.read_csv(path + "ner_entity.csv")
data_new = {}
for i in range(len(data)):i = data.loc[i]# 对name进行简单的数据清洗name = i['name'].replace('(','').replace(')','').replace('【','').replace('】','').replace('“','').replace('”','').replace('《','').replace('》','').replace('(','').replace(')','').replace('_','')# 按标签再分割实体name_list = [m for j in name.split('·') for k in j.split('、') for q in k.split('、') for p in q.split(',') for m in p.split('・') for n in m.split('/')]label = i.labelfor name in name_list:if len(name) > 10: # 过滤太长的实体continueif label not in data_new:data_new[label] = [name]else:data_new[label].append(name) # 一个标签key 对应多个实体实名from random import choice
import pickle as pk# 输入实体前句和实体后句 返回 (x_intent, y_intent, x_ner, y_ner)
def build_seq(data, label, seq1, seq2, intent, model=1, num=0, output=None):'''data 实体列表, label 实体标签, seq1 实体前句子, seq2 实体后句子, intent 生成语料的意图'''seqs_intent, labels_intent, seqs_ner, labels_ner = [], [], [], []seqs_intent.append(list(seq1) + [label] + list(seq2)) # 部分意图识别数据 ['老', '师', 'km1', '有', '哪', '些', '重', '要', '的', '课', '程']labels_intent.append(intent)# 命名实体识别数据if model == 1: # 全遍历for i in data[label]: # 'km1': ['高中地理', '高中生物', '高中政治', '高中历史'],'km2': ['地球与地图','经济学常识',seqs_ner.append(list((seq1 + '%s' + seq2)%(i))) # 原句子 ['老', '师', '高', '中', '历', '史', '有', '哪', '些', '重', '要', '的', '课', '程']if len(i) >= 2: # 转成 ['O', 'O', 'B-km1', 'I-km1', 'I-km1', 'E-km1', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']labels_ner.append(['O']*len(seq1) + ['B-' + label] + ['I-' + label]*(len(i)-2) + ['E-' + label] + ['O']*len(seq2))if len(i) < 2:labels_ner.append(['O']*len(seq1) + ['S-' + label] + ['O']*len(seq2))if model == 2: # 随机生成num个for i in range(num):i = choice(data[label])seqs_ner.append(list((seq1 + '%s' +seq2)%(i)))if len(i) >= 2:labels_ner.append(['O']*len(seq1) + ['B-' + label] + ['I-' + label]*(len(i)-2) + ['E-' + label] + ['O']*len(seq2))if len(i) < 2:labels_ner.append(['O']*len(seq1) + ['S-' + label] + ['O']*len(seq2))if output is None:return seqs_intent, labels_intent, seqs_ner, labels_nerelse: # output(x_intent, y_intent, x_ner, y_ner)output[0] += seqs_intentoutput[1] += labels_intentoutput[2] += seqs_neroutput[3] += labels_ner# 通过 seq1_list, seq2_list 遍历调用 build_seq
def create_dataset(seqs, output, label, intent, keys=1, num=100):seq1_list, seq2_list = seqsif keys == 1:for seq1 in seq1_list:for seq2 in seq2_list:build_seq(data=data_new, label=label,seq1=seq1, seq2=seq2, intent=intent, model=1, num=10, output=output)else:iffirst = Truemodel = 1for seq1 in seq1_list:for seq2 in seq2_list:# 第一次是全遍历 第二次就是model 2 了if not iffirst:model = 2iffirst = Falsebuild_seq(data=data_new, label=label, seq1=seq1, seq2=seq2, intent=intent, model=model, num=num, output=output)# 手动生成 x_intent, y_intent, x_ner, y_ner
x_intent, y_intent, x_ner, y_ner = [], [], [], []
output = [x_intent, y_intent, x_ner, y_ner]# 包括了ner数据集和17个intent1意图数据集
# km1
label = 'km1'
seq1_list = ['老师','','请问','你好']
seq2_list = ['有哪些重要的课程','有哪些重要的课','什么课比较重要','需要学什么课','有哪些课']
create_dataset([seq1_list,seq2_list],output,label,0)seq1_list = ['老师','','请问','你好']
seq2_list = ['有哪些重要的知识点','有哪些知识点需要注意','什么知识点比较重要','需要学什么那些知识点', '有哪些知识点','涉及到哪些知识点','包含哪些知识点']
create_dataset([seq1_list,seq2_list],output,label,1)seq1_list = ['老师','','请问','你好']
seq2_list = ['有哪些重要的例题需要掌握','有哪些例题需要注意','什么例题需要掌握','有哪些例题']
create_dataset([seq1_list,seq2_list],output,label,2)# km2
label = 'km2'
seq1_list = ['老师','','请问','你好']
seq2_list = ['是哪个学科的课程','是什么学科的']
create_dataset([seq1_list,seq2_list],output,label,3)seq1_list = ['老师','','请问','你好']
seq2_list = ['有哪些重要的知识点','有哪些知识点需要注意','什么知识点比较重要','需要学什么那些知识点', '有哪些知识点','涉及到哪些知识点','包含哪些知识点']
create_dataset([seq1_list,seq2_list],output,label,4)seq1_list = ['老师','','请问','你好']
seq2_list = ['有哪些重要的例题需要掌握','有哪些例题需要注意','什么例题需要掌握','有哪些例题']
create_dataset([seq1_list,seq2_list],output,label,5)label = 'kg'
seq1_list = ['老师','','请问','你好']
seq2_list = ['是什么学科的','是哪个学科的知识点']
create_dataset([seq1_list,seq2_list],output,label,6,keys = 2)seq1_list = ['老师','','请问','你好']
seq2_list = ['是什么课程的','是哪个课程需要学习的知识点','是哪门课的']
create_dataset([seq1_list,seq2_list],output,label,7,keys = 2)seq1_list = ['老师','','请问','你好']
seq2_list = ['有哪些重要的例题需要掌握','有哪些例题需要注意','什么例题需要掌握','有哪些例题']
create_dataset([seq1_list,seq2_list],output,label,8,keys = 2)# 针对古诗的处理
# author
label = 'author'
seq1_list = ['老师','','请问','你好']
seq2_list = ['写过哪些诗句啊','有哪些诗','有哪些有名的诗句',]
create_dataset([seq1_list,seq2_list],output,label,9,keys = 2,num = 500)seq1_list = ['老师','','请问','你好']
seq2_list = ['是谁啊','这个的生平怎么样','有哪些经历',]
create_dataset([seq1_list,seq2_list],output,label,10,keys = 2,num = 500)# title
label = 'title'
seq1_list = ['老师','','请问','你好']
seq2_list = ['是谁写的啊']
create_dataset([seq1_list,seq2_list],output,label,11,keys = 2,num = 500)seq1_list = ['老师','','请问','你好']
seq2_list = ['的诗句有哪些']
create_dataset([seq1_list,seq2_list],output,label,12,keys = 2,num = 500)seq1_list = ['老师','','请问','你好']
seq2_list = ['的翻译是']
create_dataset([seq1_list,seq2_list],output,label,13,keys = 2,num = 500)seq1_list = ['老师','','请问','你好']
seq2_list = ['是什么类型的古诗']
create_dataset([seq1_list,seq2_list],output,label,14,keys = 2,num = 500)seq1_list = ['老师','','请问','你好']
seq2_list = ['出现在几年级的课程']
create_dataset([seq1_list,seq2_list],output,label,15,keys = 2,num = 500)# tag
label = 'tag'
seq1_list = ['老师','','请问','你好']
seq2_list = ['的古诗有哪些']
create_dataset([seq1_list,seq2_list],output,label,16,keys = 2,num = 100)# class
label = 'class'
seq1_list = ['我们','','请问我们']
seq2_list = ['学习的古诗有哪些']
create_dataset([seq1_list,seq2_list],output,label,17,keys = 1,num = 100)len(x_intent),len(y_intent),len(x_ner),len(y_ner)# 保存
# pk.dump([x_intent, y_intent, x_ner, y_ner], open("数据生成/命名实体识别和意图识别数据/data_intent1_ner.pkl", 'wb'))3.2 构建第一次意图识别数据
# 语料库
corpus = [list(i.strip()) for i in open("corpus/conversation_test.txt", "r", encoding="utf-8").readlines()][::2] # 步长为2 只取问题
corpus_new = {}
for i in corpus: # i为列表if str(i) not in corpus_new: # str(i) 是因为列表不能hashcorpus_new[str(i)] = 1corpus = [eval(i) for i in corpus_new.keys()]# 处理机器人个人属性数据
import xml.etree.ElementTree as etrobot_data = et.parse("robot_template/robot_template.xml").findall("temp")# findall'q' 后做简单的数据清理
robot_data = [j.text.replace('(.*)', '').replace('.*', '') for i in robot_data for j in i.find('question').findall('q')]
# 不用处理的数据
data_new = [i for i in robot_data if '[' not in i]
# 需要进一步处理的数据
data_need_deal = [i.replace('+', '').replace('*', '') for i in robot_data if '[' in i]data_need_deal_new = []for i in data_need_deal:# i = i.strip(']')tmp = []for j in i.split(']'):# print(j)if '[' not in j:if len(j) != 0:tmp.append(j)else:for k in j.split('['):if len(k) != 0:tmp.append(k)data_need_deal_new.append(tmp)def build(seq, m=0, tmp='', res=[]):if m < len(seq): # 判断indexif "|" in seq[m]:for i in seq[m].split('|'): # 有'|' 就分割build(seq, m+1, tmp+i, res) # 递归先形成一句话else:build(seq, m+1, tmp+seq[m], res) # 没有'|' 就直接拼接else:res.append(tmp)for i in data_need_deal_new:res = []build(seq=i, res=res)data_new += res
data_new = [list(i) for i in data_new]
# 把图数据库 机器人个人属性 语料库的问题合并 作为第一次意图识别数据
data_x = x_intent + data_new + corpus
data_y = [0] * len(x_intent) + [1] * len(data_new) + [2] * len(corpus)# 保存
pk.dump([data_x, data_y], open("数据生成\命名实体识别和意图识别数据\data_intent0.pkl", "wb"))4 ner模型
4.1 ner模型训练
import torch
import pickle as pk
import numpy as np
import random
from torch import nn
from torchcrf import CRF
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, AdamW, BertTokenizer, get_linear_schedule_with_warmupconfig_class, tokenizer_class = BertConfig, BertTokenizer
config = config_class.from_pretrained('../prev_trained_model') # bert的config
tokenizer = tokenizer_class.from_pretrained('../prev_trained_model')device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
[x_intent, y_intent, x_ner, y_ner] = pk.load(open("../../../data/数据生成/命名实体识别和意图识别数据/data_intent1_ner.pkl", 'rb'))
# x_ner:['老', '师', '高', '中', '历', '史', '有', '哪', '些', '重', '要', '的', '课', '程']
# y_ner:['O', 'O', 'B-km1', 'I-km1', 'I-km1', 'E-km1', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']X_train, X_test, y_train, y_test = train_test_split(x_ner, y_ner)
train_data = [(X_train[i], y_train[i]) for i in range(len(X_train))]
test_data = [(X_test[i], y_test[i]) for i in range(len(X_test))]tag2label = ['O'] + list(set([j for i in y_ner for j in i]) - set('O')) # 需要把'O'放在0位置
tag2label = dict(zip(tag2label, range(len(tag2label)))) # 'B-km1', 'I-km1', 'I-km1', 'E-km1'parameter = { 'batch_size': 32,'epoch': 10,'dropout': 0.5,'lr': 0.001,'tag2label': tag2label,'num_tag': len(tag2label),'d_model': 768,'shuffle': True,'device': device,'train_data': train_data,'test_data': test_data,}# pk.dump(parameter, open('ner_parameter.pkl','wb'))print(train_data[:5])def list2torch(ins):return torch.from_numpy(np.array(ins))def batch_yield(parameter, shuffle=True, isTrain=True):if isTrain:epochs = parameter['epoch']data = parameter['train_data']else:epochs = 1data = parameter['test_data']for train_epoch in range(epochs):if shuffle:random.shuffle(data)max_len = 0seqs, labels = [], []for seq, label in tqdm(data):# seq = seq2id(seq, parameter['vocab'])# 使用bert自带字典seq = tokenizer.convert_tokens_to_ids(seq)label = [parameter['tag2label'][label_] for label_ in label]seqs.append(seq)labels.append(label)if len(seqs) == parameter["batch_size"]:seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)# 这里都用0 填充不不太好 在seqs中0表示pad 在labels中0表示'O'seqs = [i + [0]*(max_len - len(i)) for i in seqs]labels = [i + [-1]*(max_len - len(i)) for i in labels] # label也要对齐 seqs对labels是一对一输出的yield list2torch(seqs), list2torch(labels), False, Noneseqs, labels = [], []seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]labels = [i + [-1]*(max_len - len(i)) for i in labels]yield list2torch(seqs), list2torch(labels), False, train_epochseqs, label = [], []yield None, None, True, Noneclass bert_crf(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_crf, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['num_tag']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()self.crf = CRF(output_size, batch_first=True)def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[0] # (batch_size, sequence_length, hidden_size)out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return res# 微调训练
from torch import optim
model = bert_crf.from_pretrained("../prev_trained_model",config=config,parameter = parameter).to(parameter['device'])full_finetuning = True
if full_finetuning:param_optimizer = list(model.named_parameters())no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight'] # 不更新optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01}, # 更新{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}] # 不更新else:param_optimizer = list(model.fc.named_parameters())optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer]}]# 优化器
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5, correct_bias=False)# 学习率策略
train_steps_per_epoch = len(train_data) // parameter['batch_size']
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=train_steps_per_epoch, num_training_steps=parameter['epoch']*train_steps_per_epoch)# 训练
model.train()
loss_cal = []
min_loss = float('inf') # 无穷大
train_yield = batch_yield(parameter)while 1:seqs, labels, keys, epoch = next(train_yield)if keys:breakout = model(seqs.long().to(parameter['device']))loss = -model.crf(out, labels.long().to(parameter['device']))optimizer.zero_grad()loss.backward()# 梯度裁剪nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=5)optimizer.step()scheduler.step()loss_cal.append(loss.item())if epoch is not None:loss_cal = sum(loss_cal) / len(loss_cal)if loss_cal < min_loss:min_loss = loss_cal# torch.save(model.state_dict(), "ner_model.h5")print(f'epoch[{epoch+1}/{parameter["epoch"]}, loss:{loss_cal:.4f}')loss_cal = [loss.item()]4.2 ner模型评估
import torch
from torch import nn
from torchcrf import CRF
import pickle as pk
import numpy as np
from operator import itemgetter
import random
from tqdm import tqdm
import pandas as pd
from transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, AdamW, BertTokenizer, get_linear_schedule_with_warmupconfig_class, tokenizer_class = BertConfig, BertTokenizer
config = config_class.from_pretrained('../prev_trained_model') # bert的config
tokenizer = tokenizer_class.from_pretrained('../prev_trained_model')class bert_crf(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_crf, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['num_tag']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()self.crf = CRF(output_size, batch_first=True)def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[0] # (batch_size, sequence_length, hidden_size)out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return resdef load_model(config, isEval=False):parameter = pk.load(open('ner_parameter.pkl', 'rb'))if isEval:parameter['device'] = torch.device('cuda' if torch.cuda.is_available() else 'cpu')else:parameter['device'] = torch.device('cpu') # 预测在cpu上完成就行model = bert_crf(config, parameter).to(parameter['device'])# 加载模型参数model.load_state_dict(torch.load('ner_model.h5', map_location=parameter['device']))model.eval()return model, parameterdef list2torch(ins):return torch.from_numpy(np.array(ins))def batch_yield(parameter, shuffle=True, isTrain=True):if isTrain:epochs = parameter['epoch']data = parameter['train_data']else:epochs = 1data = parameter['test_data']for train_epoch in range(epochs):if shuffle:random.shuffle(data)print(data[:5])max_len = 0seqs, labels = [], []for seq, label in tqdm(data):# seq = seq2id(seq, parameter['vocab'])# 使用bert自带字典seq = tokenizer.convert_tokens_to_ids(seq)label = [parameter['tag2label'][label_] for label_ in label]seqs.append(seq)labels.append(label)if len(seqs) == parameter["batch_size"]:seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)# 这里都用0 填充不不太好 在seqs中0表示pad 在labels中0表示'O'seqs = [i + [0]*(max_len - len(i)) for i in seqs]labels = [i + [-1]*(max_len - len(i)) for i in labels] # label也要对齐 seqs对labels是一对一输出的yield list2torch(seqs), list2torch(labels), False, Noneseqs, labels = [], []seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]labels = [i + [-1]*(max_len - len(i)) for i in labels]yield list2torch(seqs), list2torch(labels), False, train_epochseqs, label = [], []yield None, None, True, Nonedef eval_model():count_table = {}test_yield = batch_yield(parameter=parameter, isTrain=False)while 1:seqs, labels, keys, _ = next(test_yield)if keys:breakpredict = model(seqs.long().to(parameter['device']))predict = np.array(model.crf.decode(predict))labels = np.array(labels)right = (labels == predict)for i in range(1, parameter['num_tag']):if i not in count_table:count_table[i] = {'pred': len(predict[(predict == i) & (labels != -1)]), # tp+fp'real': len(labels[labels == i]), # tp+fn'common': len(labels[right & (labels == i)]) # tp}else:count_table[i]['pred'] += len(predict[(predict == i) & (labels != -1)])count_table[i]['real'] += len(labels[labels == i])count_table[i]['common'] += len(labels[right & (labels == i)])count_pandas = {}name = list(parameter['tag2label'].keys())[1:] # 统计时 不算padfor ind, i in enumerate(name):i = i.split('-')[1]ind += 1if i in count_pandas:count_pandas[i][0] += count_table[ind]['pred']count_pandas[i][1] += count_table[ind]['real']count_pandas[i][2] += count_table[ind]['common']else:count_pandas[i] = [0, 0, 0]count_pandas[i][0] = count_table[ind]['pred']count_pandas[i][1] = count_table[ind]['real']count_pandas[i][2] = count_table[ind]['common']count_pandas['all'] = [ sum([count_pandas[i][0] for i in count_pandas]),sum([count_pandas[i][1] for i in count_pandas]),sum([count_pandas[i][2] for i in count_pandas]) ]# 转pandasname = count_pandas.keys()count_pandas = pd.DataFrame(count_pandas.values())count_pandas.columns = ['pred', 'real', 'common']# 增加列count_pandas['p'] = count_pandas['common'] / count_pandas['pred']count_pandas['r'] = count_pandas['common'] / count_pandas['real']count_pandas['f1'] = 2*count_pandas['p']*count_pandas['r'] / (count_pandas['p'] + count_pandas['r'])# 设置indexcount_pandas.index = list(name)# 保存# count_pandas.to_csv('eval_ner_model.csv')return count_pandas4.3 ner调用接口
import torch
from torch import nn
from torchcrf import CRF
import pickle as pk
import numpy as np
from operator import itemgetterfrom transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, BertTokenizer, get_linear_schedule_with_warmup
import os
import syspath = os.path.abspath(os.path.dirname(__file__))config_class, tokenizer_class = BertConfig, BertTokenizer# config = config_class.from_pretrained('../prev_trained_model') # bert的config
config = config_class.from_pretrained(os.path.abspath(os.path.join(path, '..', 'prev_trained_model'))) # bert的config# tokenizer = tokenizer_class.from_pretrained('../prev_trained_model')
tokenizer = tokenizer_class.from_pretrained(os.path.abspath(os.path.join(path, '..', 'prev_trained_model')))class bert_crf(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_crf, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['num_tag']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()self.crf = CRF(output_size, batch_first=True)def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[0] # (batch_size, sequence_length, hidden_size)out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return resdef load_model(config, isEval=False):# parameter = pk.load(open('ner_parameter.pkl', 'rb'))parameter = pk.load(open(os.path.join(path, 'ner_parameter.pkl'), 'rb'))if isEval:parameter['device'] = torch.device('cuda' if torch.cuda.is_available() else 'cpu')else:parameter['device'] = torch.device('cpu') # 预测在cpu上完成就行model = bert_crf(config, parameter).to(parameter['device'])# 加载模型参数model.load_state_dict(torch.load(os.path.join(path, 'ner_model.h5'), map_location=parameter['device']))model.eval()return model, parameterdef list2torch(ins):return torch.from_numpy(np.array(ins))def keyword_predict(input): input = list(input)ind2key = dict(zip(parameter['tag2label'].values(), parameter['tag2label'].keys()))# input_id = seq2id(input, parameter['vocab'])input_id = tokenizer.convert_tokens_to_ids(input)print("input_id", input_id)# predict = model.crf.decode(model(list2torch([input_id]).long().to(parameter['device'])))[0]predict = model(list2torch([input_id]).long().to(parameter['device']))predict = model.crf.decode(predict)[0]predict = itemgetter(*predict)(ind2key) # 把index转成label标签# 后处理keys_list = []for ind, i in enumerate(predict):if i == 'O':continueif i[0] == 'S':if not (len(keys_list) == 0 or keys_list[-1][-1]):del keys_list[-1]keys_list.append([input[ind], [i], [ind], True])continueif i[0] == 'B':if not (len(keys_list) == 0 or keys_list[-1][-1]):del keys_list[-1]keys_list.append([input[ind], [i], [ind], False])continueif i[0] == 'I':if len(keys_list) > 0 and not keys_list[-1][-1] and keys_list[-1][1][0].split('-')[1] == i.split('-')[1]:keys_list[-1][0] += input[ind]keys_list[-1][1] += [i]keys_list[-1][2] += [ind]else:if len(keys_list) > 0:del keys_list[-1]continueif i[0] == 'E':if len(keys_list) > 0 and not keys_list[-1][-1] and keys_list[-1][1][0].split('-')[1] == i.split('-')[1]:keys_list[-1][0] += input[ind]keys_list[-1][1] += [i]keys_list[-1][2] += [ind]keys_list[-1][3] = Trueelse:if len(keys_list) > 0:del keys_list[-1]keys_list = [[i[0], i[1][0].split('-')[1], i[2]] for i in keys_list]return keys_listdef keyword_predict_long_text(input):max_len = 512if len(input) < max_len:return keyword_predict(input)else:keys_list = []pad = 25max_len -= padfor i in range((len(input) // max_len) + 1):if i == 0:input_slice = input[i*max_len: (i+1)*max_len]else:input_slice = input[i*max_len - pad: (i+1)*max_len] # pad滑动效果 避免实体被分开keys_list += keyword_predict(input_slice)return keys_listmodel, parameter = load_model(config, isEval=False)# res = keyword_predict_long_text('你好,请问高中历史有哪些重要的知识点') # '老', '师', '高', '中', '历', '史', '有', '哪', '些', '重', '要', '的', '课', '程']
# print(res)5 intent模型
5.1 intent_0模型训练
import torch
import os
import random
import numpy as np
import pandas as pd
import pickle as pk
from collections import defaultdict
from tqdm import tqdmfrom sklearn.model_selection import train_test_split
from transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, AdamW, BertTokenizer, get_linear_schedule_with_warmup
config_class, tokenizer_class = BertConfig, BertTokenizer
config = config_class.from_pretrained('../prev_trained_model') # bert的config
tokenizer = tokenizer_class.from_pretrained('../prev_trained_model')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')[x_intent, y_intent] = pk.load(open("../../../data/数据生成/命名实体识别和意图识别数据/data_intent0.pkl", 'rb'))
X_train, X_test, y_train, y_test = train_test_split(x_intent, y_intent)output_size = len(set(i for i in y_intent))train_data = [(X_train[i], y_train[i]) for i in range(len(X_train))]
test_data = [(X_test[i], y_test[i]) for i in range(len(X_test))]parameter = {'epoch': 300,'batch_size': 32,'d_model': 768,'dropout': 0.5,'device': device,'lr': 0.001,'output_size': output_size,'train_data': train_data,'test_data': test_data,
}# pk.dump(parameter, open('bert_intent0_parameter.pkl','wb'))
print(train_data[:5])def list2torch(ins):return torch.from_numpy(np.array(ins))def batch_yield(parameter, shuffle=True, isTrain=True):if isTrain:epochs = parameter['epoch']data = parameter['train_data']else:epochs = 1data = parameter['test_data']for train_epoch in range(epochs):if shuffle:random.shuffle(data)max_len = 0seqs, labels = [], []for seq, label in tqdm(data):# bert自带字典seq = tokenizer.convert_tokens_to_ids(seq)seqs.append(seq)labels.append(label)if len(seqs) == parameter['batch_size']:seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]yield list2torch(seqs), list2torch(labels), False, Noneseqs, labels = [], []seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]yield list2torch(seqs), list2torch(labels), False, train_epochseqs, labels = [], []yield None, None, True, Nonefrom torch import nnclass bert_intent(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_intent, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['output_size']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[1] # 没弄明白 为什么CLS能代表整句话# bert_out[0] (batch_size, sequence_length, hidden_size)# bert_out[1] (batch_size, hidden_size) CLS BERT希望最后的输出代表的是整个序列的信息out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return res
# 微调训练
from torch import optim
model = bert_intent.from_pretrained("../prev_trained_model",config=config,parameter = parameter).to(parameter['device'])full_finetuning = True
if full_finetuning:param_optimizer = list(model.named_parameters())no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight'] # 不更新optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01}, # 更新{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}] # 不更新else:param_optimizer = list(model.fc.named_parameters())optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer]}]# 交叉熵损失
criterion = nn.CrossEntropyLoss()# 优化器
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5, correct_bias=False)# 学习率策略
train_steps_per_epoch = len(train_data) // parameter['batch_size']
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=train_steps_per_epoch, num_training_steps=parameter['epoch']*train_steps_per_epoch)# 训练
model.train()
loss_cal = []
min_loss = float('inf') # 无穷大train_yield = batch_yield(parameter)while 1:seqs, labels, keys, epoch = next(train_yield)if keys:breakout = model(seqs.long().to(parameter['device']))labels = labels.long().to(parameter['device'])# print(out.shape)# print(labels.shape)loss = criterion(out, labels)optimizer.zero_grad()loss.backward()# 梯度裁剪nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=5)optimizer.step()scheduler.step()loss_cal.append(loss.item())if epoch is not None:loss_cal = sum(loss_cal) / len(loss_cal)if loss_cal < min_loss:min_loss = loss_cal# torch.save(model.state_dict(), "bert_intent0_model.h5")print(f'epoch[{epoch+1}/{parameter["epoch"]}, loss:{loss_cal:.4f}')loss_cal = [loss.item()]
5.2 intent_1模型训练
import torch
import os
import random
import numpy as np
import pandas as pd
import pickle as pk
from collections import defaultdict
from tqdm import tqdm
from sklearn.model_selection import train_test_splitfrom transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, AdamW, BertTokenizer, get_linear_schedule_with_warmup
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')[x_intent, y_intent, x_ner, y_ner] = pk.load(open("../../../data/数据生成/命名实体识别和意图识别数据/data_intent1_ner.pkl", 'rb'))
X_train, X_test, y_train, y_test = train_test_split(x_intent, y_intent)output_size = len(set(i for i in y_intent))train_data = [(X_train[i], y_train[i]) for i in range(len(X_train))]
test_data = [(X_test[i], y_test[i]) for i in range(len(X_test))]parameter = {'epoch': 300,'batch_size': 32,'d_model': 768,'dropout': 0.5,'device': device,'lr': 0.001,'output_size': output_size,'train_data': train_data,'test_data': test_data,
}# pk.dump(parameter, open('bert_intent1_parameter.pkl','wb'))
print(train_data[:5])def list2torch(ins):return torch.from_numpy(np.array(ins))def batch_yield(parameter, shuffle=True, isTrain=True):if isTrain:epochs = parameter['epoch']data = parameter['train_data']else:epochs = 1data = parameter['test_data']for train_epoch in range(epochs):if shuffle:random.shuffle(data)max_len = 0seqs, labels = [], []for seq, label in tqdm(data):# bert自带字典seq = tokenizer.convert_tokens_to_ids(seq)seqs.append(seq)labels.append(label)if len(seqs) == parameter['batch_size']:seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]yield list2torch(seqs), list2torch(labels), False, Noneseqs, labels = [], []seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]yield list2torch(seqs), list2torch(labels), False, train_epochseqs, labels = [], []yield None, None, True, Noneconfig_class, tokenizer_class = BertConfig, BertTokenizer
config = config_class.from_pretrained('../prev_trained_model') # bert的config
tokenizer = tokenizer_class.from_pretrained('../prev_trained_model')from torch import nnclass bert_intent(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_intent, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['output_size']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[1] # bert_out[0] (batch_size, sequence_length, hidden_size)# bert_out[1] (batch_size, hidden_size) CLS BERT希望最后的输出代表的是整个序列的信息out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return res
# 微调训练
from torch import optim
model = bert_intent.from_pretrained("../prev_trained_model",config=config,parameter = parameter).to(parameter['device'])full_finetuning = True
if full_finetuning:param_optimizer = list(model.named_parameters())no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight'] # 不更新optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01}, # 更新{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}] # 不更新else:param_optimizer = list(model.fc.named_parameters())optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer]}]# 交叉熵损失
criterion = nn.CrossEntropyLoss()# 优化器
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5, correct_bias=False)# 学习率策略
train_steps_per_epoch = len(train_data) // parameter['batch_size']
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=train_steps_per_epoch, num_training_steps=parameter['epoch']*train_steps_per_epoch)# 训练
model.train()
loss_cal = []
min_loss = float('inf') # 无穷大train_yield = batch_yield(parameter)while 1:seqs, labels, keys, epoch = next(train_yield)if keys:breakout = model(seqs.long().to(parameter['device']))labels = labels.long().to(parameter['device'])# print(out.shape)# print(labels.shape)loss = criterion(out, labels)optimizer.zero_grad()loss.backward()# 梯度裁剪nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=5)optimizer.step()scheduler.step()loss_cal.append(loss.item())if epoch is not None:loss_cal = sum(loss_cal) / len(loss_cal)if loss_cal < min_loss:min_loss = loss_cal# torch.save(model.state_dict(), "bert_intent1_model.h5")print(f'epoch[{epoch+1}/{parameter["epoch"]}, loss:{loss_cal:.4f}')loss_cal = [loss.item()]5.3 intent 模型评估
import torch
import os
import random
import numpy as np
import pandas as pd
import pickle as pk
from collections import defaultdict
from tqdm import tqdm
from torch import nn
from transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, AdamW, BertTokenizer, get_linear_schedule_with_warmupconfig_class, tokenizer_class = BertConfig, BertTokenizer
config = config_class.from_pretrained('../prev_trained_model') # bert的config
tokenizer = tokenizer_class.from_pretrained('../prev_trained_model')class bert_intent(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_intent, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['output_size']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[1] # 没弄明白 为什么CLS能代表整句话# bert_out[0] (batch_size, sequence_length, hidden_size)# bert_out[1] (batch_size, hidden_size) CLS BERT希望最后的输出代表的是整个序列的信息out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return resdef load_model(config, intent, isEval=False):parameter = pk.load(open(f'bert_intent{intent}_parameter.pkl', 'rb'))if isEval:parameter['device'] = torch.device('cuda' if torch.cuda.is_available() else 'cpu')else:parameter['device'] = torch.device('cpu') # 预测在cpu上完成就行model = bert_intent(config, parameter).to(parameter['device'])# 加载模型参数model.load_state_dict(torch.load(f'bert_intent{intent}_model.h5', map_location=parameter['device']))model.eval()return model, parameterdef list2torch(ins):return torch.from_numpy(np.array(ins))def batch_yield(parameter, shuffle=True, isTrain=True):if isTrain:epochs = parameter['epoch']data = parameter['train_data']else:epochs = 1data = parameter['test_data']for train_epoch in range(epochs):if shuffle:random.shuffle(data)max_len = 0seqs, labels = [], []for seq, label in tqdm(data):# bert自带字典seq = tokenizer.convert_tokens_to_ids(seq)seqs.append(seq)labels.append(label)if len(seqs) == parameter['batch_size']:seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]yield list2torch(seqs), list2torch(labels), False, Noneseqs, labels = [], []seq_len_list = [len(i) for i in seqs]max_len = max(seq_len_list)seqs = [i + [0]*(max_len - len(i)) for i in seqs]yield list2torch(seqs), list2torch(labels), False, train_epochseqs, labels = [], []yield None, None, True, Nonedef eval_model(intent): # 0 第一次意图识别 1 第二次意图识别try:model, parameter = load_model(config, intent=intent, isEval=True)except:print('intent输入错误')count_table = {}test_yield = batch_yield(parameter=parameter, isTrain=False)while 1:seqs, labels, keys, _ = next(test_yield)if keys:breakpredict = model(seqs.long().to(parameter['device']))# print(predict.shape) [32,18]# maxpredicted_prob, predict = torch.max(predict, dim=1) # [32,]labels = labels.long().to(parameter['device']) # [32,]right = (labels == predict)for i in range(parameter['output_size']):if i not in count_table:count_table[i] = {'pred': len(predict[predict == i]), # tp+fp'real': len(labels[labels == i]), # tp+fn'common': len(labels[right & (labels == i)]) # tp}else:count_table[i]['pred'] += len(predict[predict == i])count_table[i]['real'] += len(labels[labels == i])count_table[i]['common'] += len(labels[right & (labels == i)])count_pandas = {}# name = list(parameter['tag2label'].keys())[1:] # 统计时 不算pad# 标签只是0-17数字for i in range(parameter['output_size']):if i in count_pandas:count_pandas[i][0] += count_table[i]['pred']count_pandas[i][1] += count_table[i]['real']count_pandas[i][2] += count_table[i]['common']else:count_pandas[i] = [0, 0, 0]count_pandas[i][0] = count_table[i]['pred']count_pandas[i][1] = count_table[i]['real']count_pandas[i][2] = count_table[i]['common']count_pandas['all'] = [ sum([count_pandas[i][0] for i in count_pandas]),sum([count_pandas[i][1] for i in count_pandas]),sum([count_pandas[i][2] for i in count_pandas]) ]# 转pandasname = count_pandas.keys()count_pandas = pd.DataFrame(count_pandas.values())count_pandas.columns = ['pred', 'real', 'common']# 增加列count_pandas['p'] = count_pandas['common'] / count_pandas['pred']count_pandas['r'] = count_pandas['common'] / count_pandas['real']count_pandas['f1'] = 2*count_pandas['p']*count_pandas['r'] / (count_pandas['p'] + count_pandas['r'])# 设置indexcount_pandas.index = list(name)count_pandas.fillna(0, inplace=True)# 保存# count_pandas.to_csv(f'eval_intent{intent}_model.csv')return count_pandas
5.4 intent接口调用
import torch
import os
import random
import numpy as np
import pandas as pd
import pickle as pk
from collections import defaultdict
from tqdm import tqdm
from torch import nn
from transformers import BertModel, BertPreTrainedModel, WEIGHTS_NAME, BertConfig, AdamW, BertTokenizer, \get_linear_schedule_with_warmuppath = os.path.abspath(os.path.dirname(__file__))config_class, tokenizer_class = BertConfig, BertTokenizer
config = config_class.from_pretrained(os.path.abspath(os.path.join(path, '..', 'prev_trained_model'))) # bert的config
tokenizer = tokenizer_class.from_pretrained(os.path.abspath(os.path.join(path, '..', 'prev_trained_model')))class bert_intent(BertPreTrainedModel):def __init__(self, config, parameter):super(bert_intent, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)embedding_dim = parameter['d_model']output_size = parameter['output_size']self.fc = nn.Linear(embedding_dim, output_size)self.init_weights()def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):bert_out = self.bert(input_ids, attention_mask, token_type_ids)out = bert_out[1]# CLS代表整句话# bert_out[0] (batch_size, sequence_length, hidden_size)# bert_out[1] (batch_size, hidden_size) CLS BERT希望最后的输出代表的是整个序列的信息out = self.dropout(out)res = self.fc(out) # embedding_dim和hidden_size 都是用768return resdef load_model(config, intent, isEval=False):parameter_path = f'bert_intent{intent}_parameter.pkl'state_dict_path = f'bert_intent{intent}_model.h5'parameter = pk.load(open(os.path.join(path, parameter_path), 'rb'))if isEval:parameter['device'] = torch.device('cuda' if torch.cuda.is_available() else 'cpu')else:parameter['device'] = torch.device('cpu') # 预测在cpu上完成就行model = bert_intent(config, parameter).to(parameter['device'])# 加载模型参数model.load_state_dict(torch.load(os.path.join(path, state_dict_path), map_location=parameter['device']))model.eval()return model, parameterdef list2torch(ins):return torch.from_numpy(np.array(ins))def intent_predict(input, model, parameter):max_len = 512# 处理过长文本if len(input) > 512:input = input[:512]input = list(input)input_id = tokenizer.convert_tokens_to_ids(input)# print(list2torch([input_id])) 二维 [[6435, 7309, 7770,]]# print(list2torch(input_id)) 一维 [6435, 7309, 7770,]predict = model(list2torch([input_id]).long().to(parameter['device']))# 取最大值predicted_prob, predict = torch.max(predict, dim=1)return predict# 0 第一次意图识别
intent0_model, parameter0 = load_model(config, intent=0, isEval=False)
# 1 第二次意图识别
intent1_model, parameter1 = load_model(config, intent=1, isEval=False)6 基于机器人个人属性、闲聊语料库、网络搜索回答api
import logging
import ospath = os.path.abspath(os.path.dirname(__file__))# 日志类
class BaseLayer:def __init__(self, log=True):self.logger = logging.getLogger() # 初始化日志 参数可以填个nameif not log:self.close_log()def close_log(self):self.logger.setLevel(logging.ERROR) # 设置日志的等级def print_log(self, msg):self.logger.warning(msg)def search_answer(self, question): # 抽象方法pass# 基于机器人个人属性的问答import xml.etree.ElementTree as et
from random import choice
import reclass template(BaseLayer):def __init__(self):super(template, self).__init__()self.template = self.load_template_file()self.robot_info = self.load_robot_info()self.temps = self.template.findall("temp") # <temp id="name"># 暂时用不到# self.default_answer = self.template.find("default")# self.exceed_answer = self.template.find("exceed")def load_template_file(self):data = et.parse(os.path.abspath(os.path.join(path, '../data/robot_template/robot_template.xml')))return datadef load_robot_info(self):robot_info = self.template.find("robot_info") # <name>Ash,中文名:小智</name>robot_info_dict = {}for info in robot_info:robot_info_dict[info.tag] = info.textreturn robot_info_dictdef search_answer(self, question):match_temp = Noneflag = Nonefor temp in self.temps:qs = temp.find("question").findall("q") # 问题列表for q in qs:res = re.search(q.text, question) # 匹配问题if res:match_temp = tempflag = Truebreakif flag:breakif flag:a_s = choice([i.text for i in match_temp.find("answer").findall("a")]) # 随机选个答案answer = a_s.format(**self.robot_info) # 填充{}return answerelse:return None# 预处理语料库import jieba
import redef load_seq_qa(): # 加载语料库q_list, a_list = [], []with open(os.path.abspath(os.path.join(path, "../data/corpus/conversation_test.txt")), "r", encoding="utf-8") as f:for i, line in enumerate(f):line = re.sub('[0-9]*', '', line.strip())line = jieba.lcut(line)if i % 2 == 0: # 偶数为问题q_list.append(line)else: # 奇数为答案a_list.append(line)return q_list, a_listdef build_vocab(): # 问题列表 词->index 字典q_list, _ = load_seq_qa()word_dict = set([j for i in q_list for j in i])word_dict = dict(zip(word_dict, range(3, len(word_dict) + 3)))word_dict['<pad>'] = 0word_dict['<start>'] = 1word_dict['<end>'] = 2return word_dictdef build_words_in_question(): # 统计词在问题中的分布word_dict = build_vocab()q_list, _ = load_seq_qa()inverse_index_dict = {}for i in word_dict.keys():inverse_index_dict[i] = []for i, qw in enumerate(q_list):for w in qw:inverse_index_dict[w].append(i) # 统计 词 在问题index中的分布return inverse_index_dict # {词:[问题1, 问题2 , 问题3...]}from collections import Counter
import numpy as np
import jiebaclass CorpusSearch(BaseLayer):def __init__(self):super(CorpusSearch, self).__init__()self.question_list, self.answer_list = load_seq_qa()self.words_in_question = build_words_in_question()self.THRESHOLD = 0.7 # 阈值def cosin_sim(self, a, b): # 计算余弦相似度(通过看词和问题列表的词统计)# a 和 b 都是分词后的结果a_words = Counter(a) # Counter({'你': 1, '是': 1, '什么': 1})b_words = Counter(b) # Counter({'你': 1, '的': 1, '爱好': 1, '是': 1, '什么': 1})all_words = b_words.copy()all_words.update(a_words - b_words)# print(all_words) # Counter({'你': 1, '的': 1, '爱好': 1, '是': 1, '什么': 1})all_words = set(all_words) # 两个句子的全部分词a_vec, b_vec = list(), list()for w in all_words:a_vec.append(a_words.get(w, 0))b_vec.append(b_words.get(w, 0))a_vec = np.array(a_vec) # [0 1 0 1 1]b_vec = np.array(b_vec) # [1 1 1 1 1]# 取模 为了正规化a_ = np.sqrt(np.sum(np.square(a_vec)))b_ = np.sqrt(np.sum(np.square(b_vec)))# 内积 看多大长度指向同一方向cos_sim = np.dot(a_vec, b_vec) / (a_ * b_)return round(cos_sim, 4) # 保留4为小数def search_answer(self, question):search_list = list()q_words = jieba.lcut(question)for q_word in q_words:index = self.words_in_question.get(q_word, list()) # 查找哪些文档出现了这些词search_list += indexif not search_list: # 都没出现过的词return Nonecount_list = Counter(search_list) # 计数count_list = count_list.most_common(3) # 找出现最多的前3个文档result_sim = list()for i, _ in count_list:q = self.question_list[i] # 取文档中问题sim = self.cosin_sim(q_words, q)result_sim.append((i, sim)) # 文档index, 相似度result = max(result_sim, key=lambda x: x[1]) # 相似度在1位置if result[1] > self.THRESHOLD:answewr = "".join(self.answer_list[result[0]]) # 与问题相似度最高的模板问题对应的答案return answewrreturn None# 基于网络回答import requestsclass InterNet(BaseLayer):def __init__(self):super(InterNet, self).__init__()self.print_log("Interner layer is ready")def search_answer(self, question):url = 'https://api.ownthink.com/bot?appid=xiaosi&userid=user&spoken='try:text = requests.post(url + question).json() # 发送请求 接收返回并处理jsonif 'message' in text and text['message'] == 'success':return text['data']['info']['text']else:return Noneexcept:return None7 neo4j搜索回答
from py2neo import Graph# 设置路径
import os
import sys
path = os.path.abspath(os.path.dirname(__file__))
sys.path.append(path)from neo4j_config import neo4j_ip, username, passwordfrom pyhanlp import *class GraphSearch():def __init__(self):self.graph = Graph(neo4j_ip, auth=(username, password))# 基于km1(科目)寻求课程(km2)def forintent0(self, entity):sql = 'match p = (n:km1)-[]->(m:km2) where n.name = "%s" return m.name' % (entity[0])print(sql)res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于km1(科目)寻求知识点def forintent1(self, entity):if entity[1] == 'km1': # 基于km1sql = "match p = (n:%s)-[]->()-[]->(m:kg) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])else: # 避免识别错误 使用km2sql = "match p = (n:%s)-[]->(m:kg) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于km1(科目)寻求问题(question)def forintent2(self, entity):if entity[1] == 'km1':sql = "match p = (n:%s)-[]->()-[]->()-[]->(m:question) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])elif entity[1] == 'km2':sql = "match p = (n:%s)-[]->()-[]->(m:question) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])else:sql = "match p = (n:%s)-[]->(m:question) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于km2寻求km1(科目)def forintent3(self, entity):sql = "match p = (n:km1)-[]->(m:%s) where m.name = '%s' return n.name" % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['n.name'] for i in res]# 基于km2寻求知识点def forintent4(self, entity):res = self.forintent1(entity)return res# 基于km2寻求问题def forintent5(self, entity):res = self.forintent2(entity)return res# 基于kg(知识点)寻求km1def forintent6(self, entity):sql = "match p = (n:km1)-[]->()-[]->(m:%s) where m.name = '%s' return n.name " % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['n.name'] for i in res]# 基于kg(知识点)寻求km2def forintent7(self, entity):sql = "match p = (n:km2)-[]->(m:%s) where m.name = '%s' return n.name " % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['n.name'] for i in res]# 基于kg(知识点)寻求questiondef forintent8(self, entity):sql = "match p = (n:%s)-[]->(m:question) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于作者,寻求诗句名def forintent9(self, entity):sql = "match p = (n:%s)-[]->(m:title) where n.name = '%s' return m.name limit 10" % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于作者名,寻求简介def forintent10(self, entity):sql = "match p = (n:%s)-[]->(m:introduce) where n.name = '%s' return m.name" % (entity[1], entity[0])res = self.graph.run(sql).data()return res[0]['m.name']# 基于诗句名,寻求作者def forintent11(self, entity):sql = "match p = (n:author)-[]->(m:%s) where m.name = '%s' return n.name" % (entity[1], entity[0])res = self.graph.run(sql).data()return [i['n.name'] for i in res]# 基于诗名,寻求诗文def forintent12(self, entity):sql = "match p = (n:title)-[]->(m:content) where n.name = '%s' return m.name" % (entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于诗名,寻求翻译def forintent13(self, entity):sql = "match p = (n:title)-[]->(m:translate) where n.name = '%s' return m.name" % (entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于诗名,寻求类型def forintent14(self, entity):sql = "match p = (n:title)<-[]-(m:tag) where n.name = '%s' return m.name" % (entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]# 基于诗名,寻求classdef forintent15(self, entity):sql = "match p = (n:class)-[]->(m:title) where m.name= '%s' return n.name" % (entity[0])res = self.graph.run(sql).data()return [i['n.name'] for i in res]# 基于类型,寻求诗名def forintent16(self, entity):sql = "match p = (n:title)<-[]-(m:tag) where m.name = '%s' return n.name limit 10" % (entity[0])res = self.graph.run(sql).data()return [i['n.name'] for i in res]# 基于class,寻求诗名def forintent17(self, entity):sql = "match p = (n:class)-[]->(m:title) where n.name= '%s' return m.name limit 10" % (entity[0])res = self.graph.run(sql).data()return [i['m.name'] for i in res]
8 flask部署
import json
import os
import sys
from operator import itemgetter# ner识别
from utils.model.ner_model.ner_predict import keyword_predict_long_text
# 意图识别
from utils.model.intent_model.intent_predict import intent0_model, intent1_model, parameter0, parameter1, intent_predict
# neo4j
from utils.neo4j_graph import GraphSearchfrom flask_cors import cross_origin
from flask import Flask, request, redirect, url_for
# 个人属性,闲聊预料库,基于网络
from utils.template_corpus_internet import template, CorpusSearch, InterNetintent0_tag = {'0': '基于知识图谱问答','1': '基于机器人个人属性回答','2': '基于语料库回答'}intent1_tag = {'0': '询问科目有哪些课程','1': '询问科目有哪些知识点','2': '询问科目有哪些例题','3': '询问课程是什么学科的','4': '询问课程有哪些知识点','5': '询问课程有哪些例题','6': '询问是哪个学科的知识点','7': '询问是哪个课程的知识点','8': '询问这个知识点有哪些例题需要掌握','9': '询问作者有哪些诗句','10': '询问作者个人简介','11': '询问诗是谁写的','12': '询问诗的诗句','13': '询问诗的翻译','14': '询问诗的类型','15': '询问诗来自那篇课文','16': '询问这种类型的古诗有哪些','17': '询问这个年级学过哪些诗',
}app = Flask(__name__)
template_model = template()
corpus_search_model = CorpusSearch()
InterNet_model = InterNet()
graphSearch_model = GraphSearch()def takelong(ins):return len(ins[0])def rebuildins(ins, entity_list): # 用实体类别替换实体名new_ins = {}left_ind = set(range(len(ins)))for i in entity_list:left_ind -= set(range(i[-1][0], i[-1][-1] + 1)) # 实体起始位置到实体结束位置new_ins[i[-1][0]] = i[1] # 替换为实体类别for i in left_ind:new_ins[i] = ins[i] # 添加剩余非实体new_id = list(new_ins.keys())new_id.sort() # 排序return itemgetter(*new_id)(new_ins) # id转文字@app.route('/test', methods=['GET', 'POST'])
@cross_origin() # 跨域
def my_service():if request.method == 'POST':data = request.get_data().decode()data = json.loads(data)question = data['question']print('question:', question)entity_list = keyword_predict_long_text(question)entity_list.sort(key=takelong, reverse=True) # 实体列名名称从大到小排序print('entity_list', entity_list)# 更新问题new_question = rebuildins(question, entity_list)print('new_question:', new_question)intent0 = intent_predict(new_question, intent0_model, parameter0)[0]print('第一次意图识别:', intent0)answer = Noneif intent0 == 0:intent1 = intent_predict(new_question, intent1_model, parameter1)[0]print('第二次意图识别:', intent1)try:print(f'graphSearch_model.forintent{intent1}({entity_list[0]})')answer = eval(f'graphSearch_model.forintent{intent1}(entity_list[0])')# print(answer)except:answer = Noneif intent0 == 1:answer = template_model.search_answer(question)if intent0 == 2:answer = corpus_search_model.search_answer(question)if answer is None or len(answer) == 0:answer = InterNet_model.search_answer(question)return json.dumps(answer, ensure_ascii=False)if __name__ == '__main__':app.run(host='0.0.0.0', port=8081, threaded=True)9 用户输入问题模块
import requests
import jsonwhile 1:question = input('请输入:')if len(question) > 0:data = {'question': question,}url = 'http://127.0.0.1:8081/test'answer = requests.post(url, data=json.dumps(data)).json()print(answer)else:print('退出')break这篇关于基于bert预训练高中知识点的单轮对话机器人的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








