本文主要是介绍Zephyr-7B-β :类GPT的高速推理LLM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Zephyr 是一系列语言模型,经过训练可以充当有用的助手。 Zephyr-7B-β 是该系列中的第二个模型,是 Mistralai/Mistral-7B-v0.1 的微调版本,使用直接偏好优化 (DPO) 在公开可用的合成数据集上进行训练 。 我们发现,删除这些数据集的内置对齐可以提高 MT Bench 的性能,并使模型更加有用。 然而,这意味着该模型在提示时可能会生成有问题的文本,并且只能用于教育和研究目的。 你可以在技术报告中找到更多详细信息。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D场景编辑器
1、Zephyr-7B-β 模型说明
- 模型类型:7B 参数类似 GPT 的模型,在公开可用的合成数据集上进行微调。
- 语言 (NLP):主要是英语
- 许可证:MIT
- 微调原模型:mistralai/Mistral-7B-v0.1
模型源码如下:
- 存储库:github
- 演示:zephyr-chat
- Chatbot竞赛:在 LMSYS 竞技场中针对 10 多个 LLM 评估 Zephyr 7B
2、Zephyr-7B-β 性能
在发布时,Zephyr-7B-β 是 MT-Bench 和 AlpacaEval 基准上排名最高的 7B 聊天模型
| 模型 | 大小 | 对齐 | MT-Bench(分数) | AlpacaEval(胜率 %) |
|---|---|---|---|---|
| StableLM-Tuned-α | 7B | dSFT | 2.75 | - |
| MPT-Chat | 7B | dSFT | 5.42 | - |
| Xwin-LMv0.1 | 7B | dPPO | 6.19 | 87.83 |
| Mistra-Instructv0.1 | 7B | - | 6.84 | - |
| Zephyr-7b-α | 7B | dDPO | 6.88 | - |
| Zephyr-7b-β 🪁 | 7B | dDPO | 7.34 | 90.60 |
| Falcon-Instruct | 40B | dSFT | 5.17 | 45.71 |
| Guanaco | 65B | SFT | 6.41 | 71.80 |
| Llama2-Chat | 70B | RLHF | 6.86 | 92.66 |
| Vicuna v1.3 | 33B | dSFT | 7.12 | 88.99 |
| WizardLM v1.0 | 70B | dSFT | 7.71 | - |
| Xwin-LM v0.1 | 70B | dPPO | - | 95.57 |
| GPT-3.5-turbo | - | RLHF | 7.94 | 89.37 |
| Claude 2 | - | RLHF | 8.06 | 91.36 |
| GPT-4 | - | RLHF | 8.99 | 95.28 |
特别是,在 MT-Bench 的多个类别上,与 Llama2-Chat-70B 等较大的开放模型相比,Zephyr-7B-β 具有较强的性能:
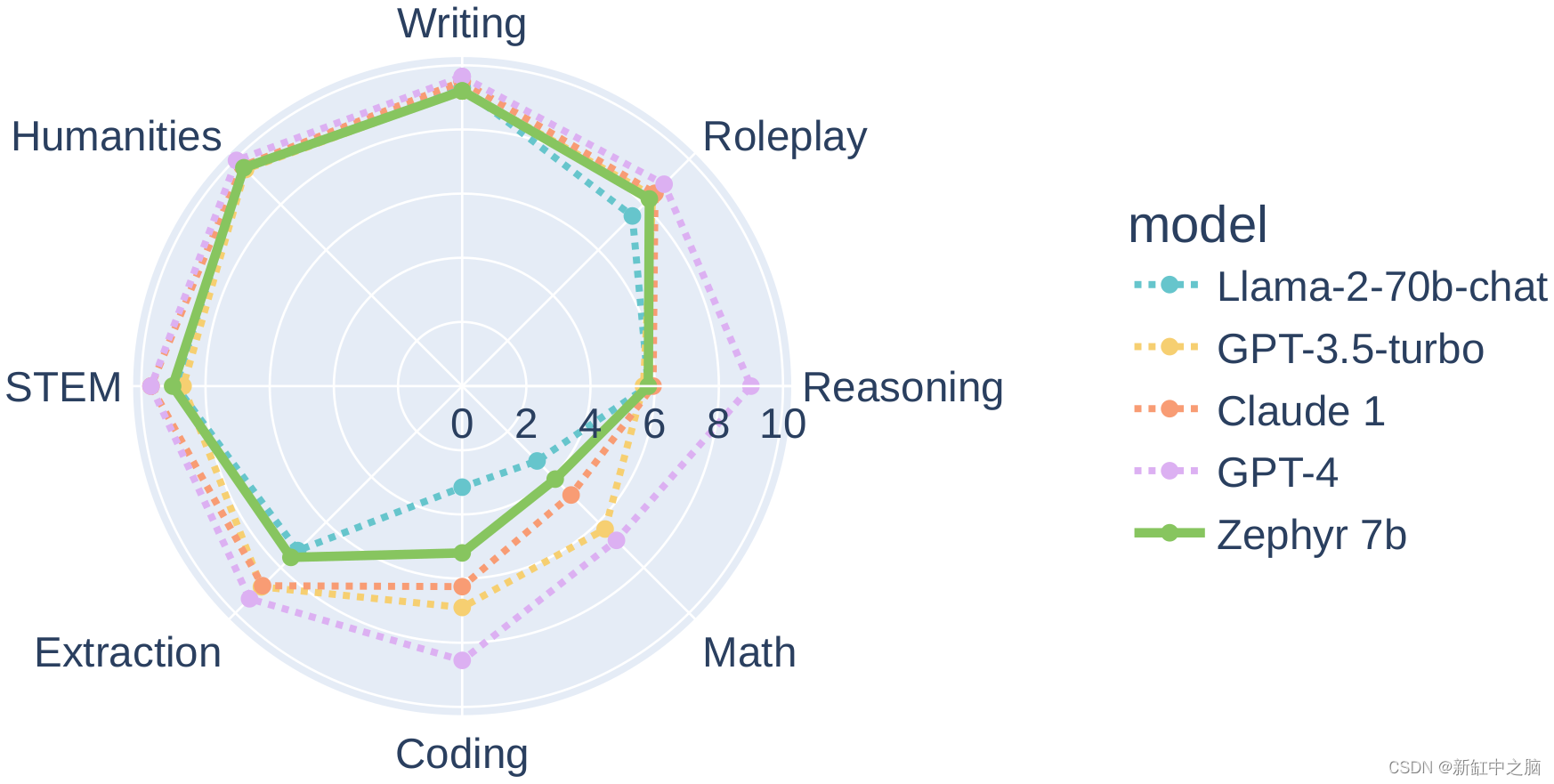
然而,在编码和数学等更复杂的任务上,Zephyr-7B-β 落后于专有模型,需要更多的研究来缩小差距。
3、Zephyr-7B-β 预期用途和限制
该模型最初是在经过过滤和预处理的 UltraChat 数据集上进行微调的,该数据集包含 ChatGPT 生成的各种合成对话。 然后,我们在 openbmb/UltraFeedback 数据集上进一步将模型与 🤗 TRL 的 DPOTrainer 对齐,该数据集包含按 GPT-4 排名的 64k 提示和模型完成情况。 因此,该模型可以用于聊天,你可以查看我们的演示来测试其功能。
可以在此处找到用于训练 Zephyr-7B-β 的数据集
以下是使用 🤗 Transformers 中的 pipeline() 函数运行模型的方法:
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerateimport torch
from transformers import pipelinepipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-beta", torch_dtype=torch.bfloat16, device_map="auto")# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [{"role": "system","content": "You are a friendly chatbot who always responds in the style of a pirate",},{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
4、Zephry-7B-β 的偏见、风险和局限性
Zephyr-7B-β 尚未通过 RLHF 等技术与人类偏好保持一致,也未通过 ChatGPT 等响应的循环过滤进行部署,因此该模型可能会产生有问题的输出(尤其是在提示时)。 目前还不清楚用于训练基本模型 (mistralai/Mistral-7B-v0.1) 的语料库的大小和组成,但它很可能包含 Web 数据和书籍和代码等技术资源的组合 。 有关示例,请参阅 Falcon 180B 模型卡。
原文链接:Zephyr-7B-β — BimAnt
这篇关于Zephyr-7B-β :类GPT的高速推理LLM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)