本文主要是介绍Revisiting the Negative Data of Distantly Supervised Relation Extraction文章阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
刚刚准备定下开题技术路线,刚好也接触了一下MarkDown,所以先写一篇博客练练手,同时记录一下这篇文章。
文章信息:
- 会议: ACL2021
- 任务:联合抽取
- 学习方式:远程监督
1.Motivation:

众所周知,利用远程监督对文本进行标注会出现许多问题。其中最明显的就是FP(False Positive)和FN(False Negetive)问题。
FP问题指的是“本来应为负例的样本被判断为正例”。例如上图中S2,原句中描述的是shakespeare 在Stratford-upon-Avon这个地方度过余生,但是由于知识库中存在(William shakespeare,Brithplace,Stratford-upon-Avon)这样的三元组,所以对这句打上了错误标签
FN本意是“本来为负例的样本被判断为负例”,这本来是没问题的,但是在远程监督的场景下,标签为负例的样本可能仅仅是因为知识库中不存在这样的三元组,并不是真正的负例。如上图S3所示。
虽然存在上述两个问题,但是这篇文章真正着手解决的是FN问题,主要方式是通过对损失函数的改造来实现的。此外,文章开头还对传统的联合抽取pipeline进行了重构,但是和远程监督中的FN和FP问题并无太大关联。
所以总的来说,我认为这篇文章的主要贡献如下:
- 提出“关系-实体”的抽取框架,并建模为句级分类-阅读理解的任务
- 针对数据集中的FN问题,对Positive Unlabeled学习中的损失函数进行了重构,进行学习
- 模型的构建简单且有效,有较大提升空间
2.Framwork
(1)为何要先关系后实体?
作者对此的观点是,抽取出m个实体后,其实大部分实体间是无法形成有效关系的,但是以往的技术路线却要在所有关系上,对m个实体两两间计算关系得分,因此带来决策空间的裁剪不够。但是其实并没有很说服我,因为决策空间尽管很大,但是模型其实也可以通过类别间的先验学习到实体类型和每个关系的概率,只要数据量足够。
不过在我看来,从实体抽取任务和关系抽取的任务上出发其实是make sense的。因为首先,实体抽取无论建模为基于序列标注还是跨度的分类,其实都是相当复杂的,将实体抽取作为pipeline的第一步,有可能对后续的关系抽取引入更多噪声。其次,实体确定了,并不一定可以确定关系。例如在NYT10中,如果确定是三元组是(people,,location),中间的关系可以是place_of_death,place_of_birth,place_lived等。
| NYT10-HRL | NYT11-HRL | |
|---|---|---|
| TPLinker | 71.93 | 55.28 |
| RERE | 73.4 | 55.47 |
| 提升 | 1.47 | 0.19 |
从实验的角度来看,本模型更适用于关系较多的数据集。因为从实验效果来看,相较有监督SOTA模型TPlinker,在NYT10上,本文模型有1.47的F1值提升。但是在NYT11上仅有0.19的提升。NYT11的F1值偏低,按照常识来说,应该是可以带来更多提升的。所以我们基本上可以得出推论,本文模型其实更适合于NYT10这个数据集,即关系较多的数据集(NYT10-HRL有29个关系,NYT11-HRL有12个关系)
(2)关系分类 -->句子级分类:
对于关系分类,首先进行一个句子级分类的任务。对于输入句子,输出一个R维one-hot向量,R为数据集关系数量。如果模型判定出现了某个关系,则在对应位置标为1,否则标为0。
(3)实体抽取 -->阅读理解:
实体抽取如何利用第一步抽取出的关系是整个框架的关键。因为实体数量没有确定,如何把第一步抽取出的关系分配到两个实体间仍需解决。
本文通过阅读理解的方法在二者间建立起了关系。作者观察到(关系,句子,头尾实体)和阅读理解中的(query,context,answer)非常像,所以可以通过将第一问中得出的关系,作为query,从而预测出所有包含关系的头尾实体,从而实现关系的分配。
设输入句长为N,关系数为R,则最后预测的时候,预测R个4*N的向量,每个N维向量用于指示(头实体开始,头实体结束,尾实体开始,尾实体结束)的位置,如果为边界为1,否则为0。
3.Detail

(1)Relation Classifier
具体实现上,本文的方法十分简单,首先,对于输入句子,通过BERT编码为矩阵,然后利用矩阵第一各位置CLS用于句子级的关系分类。在关系分类这里就是使用了一个简单的sigmoid全连接层。
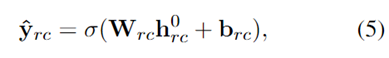
其中 h0rc即编码后的 [CLS] token。
(2)Entity Extractor
对于实体抽取,首先将第一步抽取出的关系转化为query。具体方法是直接将关系标签通过BERT编码后,作为query,如Nationality则为"[CLS] / people / person / nationality [SEP]"。每个关系独立形成query。所以如果一句话中第一步分类出3个关系,则这个样本转化为3个前面拼接的query不同的样本(当然最后预测的标签也不同)。最后,也是一个sigmoid全连接层进行分类。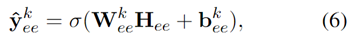
4.Loss function
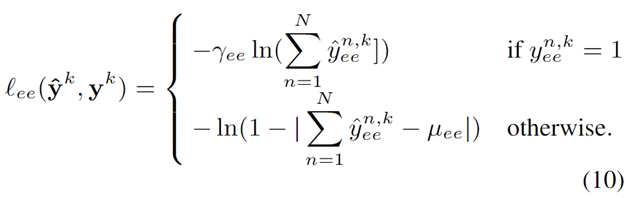
损失函数是本文的一个亮点,不过似乎还是存在部分错误。我对实体抽取部分的进行分析,关系分类原理也相同。
(1)对于正例
对于正例来说,损失函数部分ln中为预测的yhat,这部分较为简单,意思是如果原标签为正例,则预测标签尽量接近1,则ln1,损失接近0。但是式子似乎存在错误,N加和的符号似乎应该放在外面。因为如果按照原式子,如果句子中存在两个实体,模型给出的预测yhat=1,则式子变成了ln2>0,加上前面的负号,loss变为了一个负数,这是不正常的。而如果把ln (yhat)<0进行累加,则不会出现这种情况。
(2)对于负例
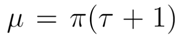

对于负例来说,首先看损失函数的绝对值部分,绝对值部分为0则损失最小,所以这个损失函数旨在使yhat尽量接近μ。上式给出了μ的定义。首先π是数据集中的类别先验,用通俗的说法来说,就是把数据集中的实体数了一遍,看一个token是实体的概率是多少。τ则为FN率,是一个估算的值,利用τ可以衡量有多少实体没有被标记。
所以背后的核心思想是这样的:既然有一些实体是没有被标记的,那么显然对数据集中的非实体,我们不能简单得认为他的yhat就应该是0。那么应该是多少呢?应该接近它的先验。比如实体中先验为0.1,说明大概10个token中就存在1个实体,那么面对10个未标记的实体,也大概应该有1个实体应该存在,但是没被标记出来,而且FN率越高,这个比例应该越高,例如FN率为0.5,那么这10个token中大概应该有1.5个。此外,我们必须避免模型的预测过于平均,这样就没有意义了。 所以,我们应该把这10个token的预测的yhat加起来,另他们的加和为1.5,而不是关注每个token的yhat。
因此,我感觉式子其实也列错了。因为前面yhat如果进行了累加,那么先验μ也应该相应的累加,否则就无法和yhat对应上了,就会导致N(即句长)越大的,损失越大,这样显然是不公平的。
5.Experiments

实验部分我感觉还是有缺陷的,首先就是没有远程监督模型进行对比,虽然TPLinker牛皮,但是你这么比不是欺负老师傅呢么。然后也没有消融实验,最起码你用了不一样的loss,和经典的交叉熵比一下不过分吧。
唯一能说服我follow这个工作的原因也许就是可以直接在句内多关系的场景下应用吧,也懒得再找其他路线了。5篇远程监督2021ACL,就这篇可以直接食用
这篇关于Revisiting the Negative Data of Distantly Supervised Relation Extraction文章阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!