本文主要是介绍Text2Video-Zero:Text-to-Image Diffusion Models are Zero-Shot Video Generators,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【AIGC-AI视频生成系列-文章1】Text2Video-Zero - 知乎一句话亮点:当文本-视频生成也不需要额外数据训练,只需要基于现有的diffusion-model 如Stable Diffusion能力调整即可实现,解决生成视频帧间不一致问题,是不是很心动。 文章链接:Text-to-Image Diffusion Mode…![]() https://zhuanlan.zhihu.com/p/626777733
https://zhuanlan.zhihu.com/p/626777733
0.abstract
本文不需要额外数据训练,利用现有的文本到图像合成能力,例如stable diffusion,可以解决帧间不一致的问题。调整包括两方面:1.使用motion dynamics丰富真的latent code,以保持全局场景和背景的一致性。2.重新编程帧间self-attention,使用每个帧对第一个帧的cross-frame attention来保留前景对象的content、appearance和identity。方法不局限于文生视频,还适用于条件和内容专用的视频生成,以及pix2pix,引导引导的视频编辑。

1.introduction
一些工作试图在视频领域重新利用文本到图像扩散模型来扩展文本到视频生成和编辑,但是需要大量标注数据,VideoFusion就属于要用视频数据训练的,tune a video属于one-shot的,zero-shot方法利用图文生成模型,但是要解决一致性问题,三个贡献:
1.zero-shot
2.在latent code中编码motion dynamics和使用跨帧注意力来重新编码帧级别self-attention。
3.条件和内容专用视频生成,video instruct pix2pix,视频编辑。
2.related works
NUMA->Phenaki->Cogvideo(Cogview2)->VDM->Imagen Video->Make a video->Gen-1->Tune a Video->Text2Video-Zero
3.methods
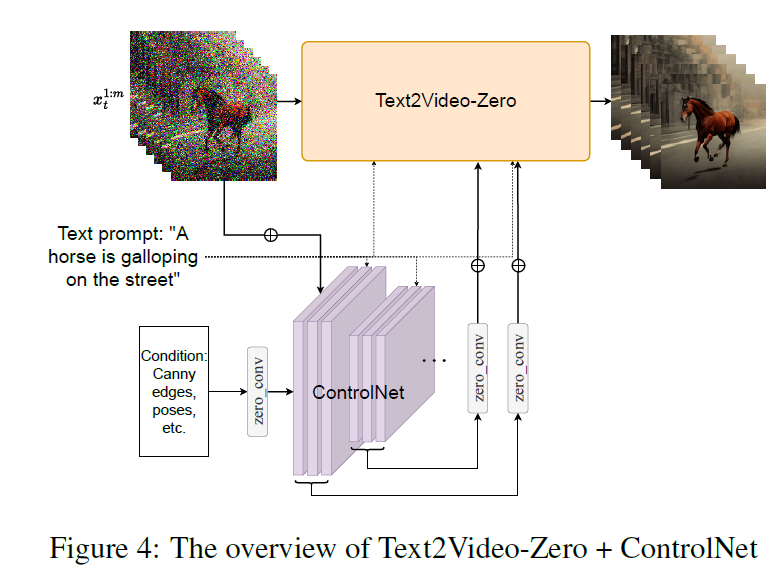
Text2video-zero和controlnet,dreambooth结合,以及Video Instruct-pix2pix。由于需要生成视频,stable diffusion应当在latent code的序列上操作,朴素的方法是从标准高斯中独立采样m个latent code,并对每个latent code应用DDIM采样以获得相应的张量,然后解码以获得生成的视频序列,但是如下图:
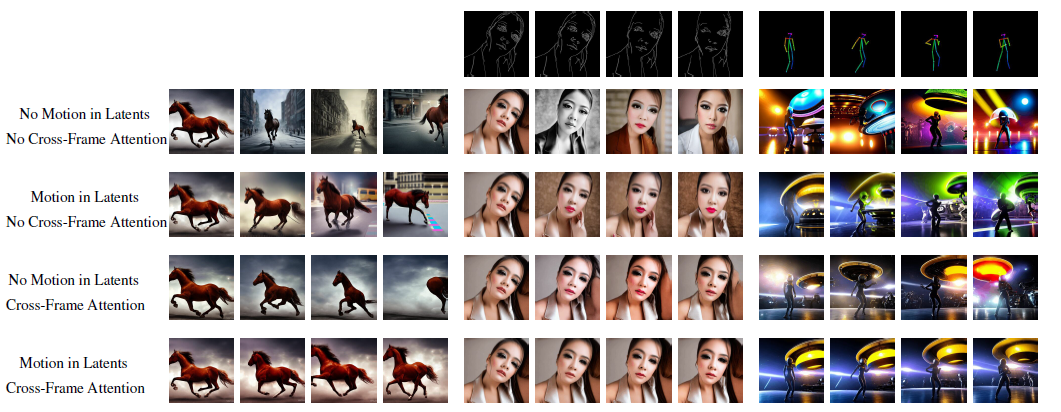
上图中第一行是没有motion和cross-frame attention的,导致了完全随机的图像生成,仅有文本描述的语义,没有物体运动的连贯性,为了解决这个问题:
1.在latent code中引入了motion dynamics,使得生成视频序列具有连贯性和一致性。
2.引入跨帧注意力机制保证前景对象的外观一致性。
3.1 motion dynamics in latent codes

3.2 reprogramming cross-frame attention
为了保留前景对象的外形、形状和身份等信息,使用cross-frame attention并在生成的过程贯穿整个序列。为了利用cross-frame attention也不重新训练sd,将sd中的每个self-attention替换成cross-frame attention,其中每帧的注意力都放在第一帧上。在原始的sd unet架构中,每一层都能得到一个feature map,对其进行线性投影获得query,key,value,计算如下:
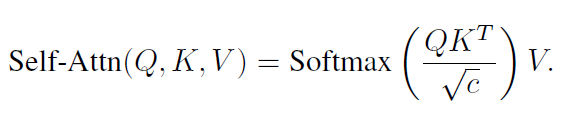
在text2video-zero中每个attention层都接收m个输入,线性投影后残生m个queries,keys和values,因此cross-frame attention:

通过cross-frame attention,对象和背景的外观,结构和身份都从第一帧传到了后续帧,大大提高了生成帧的时间一致性。


模型结构:
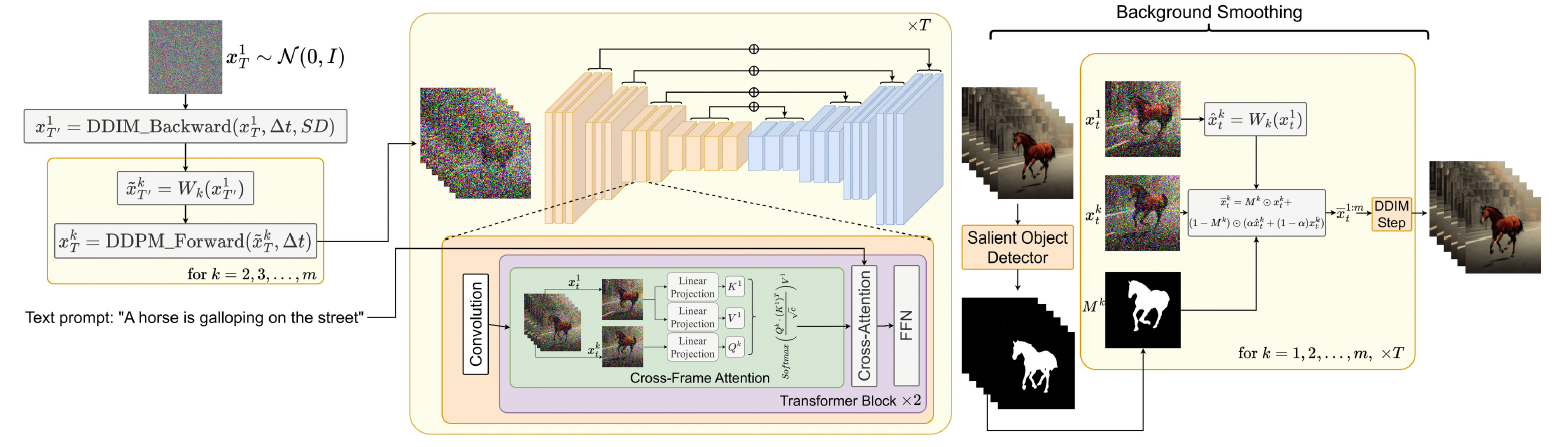
上面这个图是本文的核心,首先从latent code开始,使用进过预训练好的sd中的DDIM反向传播得x,此处得到就是一帧一帧的图像,为每一帧指定一个运动场,这个运动场就是所谓的motion dynamics,通过变形函数W来完成,然后再通过DDPM前向将其编码到latent code中,此时的latent code就具备了全局运动一致性,通过DDPM是因为可以在对象的运动方面获得更大的自由度,最后,将latent code传递给修改后的sd产生一帧一帧的视频。
4.结合controlnet
这篇关于Text2Video-Zero:Text-to-Image Diffusion Models are Zero-Shot Video Generators的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







