本文主要是介绍Unity DOTS 学习笔记3 - 面向数据设计的基本概念(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Unity中的面向数据设计
Unity的ECS(Entity-Component-System)是面向数据编程的设计方法,这种模式的主要思想是将数据与逻辑分开。除此之外,它遵循“组合优于继承”的原则,以避免通常通过继承遇到的问题。我将简要描述 Unity 中如何定义实体、组件和系统,然后我计划更深入地了解内存管理。
Unity中的内存布局
实体(Entity)
实体只是一个ID,这使您可以更自由地以您想要的方式对数据进行建模。
// Class is provided by Unity
public struct Entity
{public uint Id;
}
组件(Componnent)
一个组件包含一组数据。您可以将组件附加到实体,并使实体具有所需的任何组件组合。这就是 ECS 的本质:实体只是组件的集合。这些组件中的任何一个都没有承担任何功能,它们只是数据包。
// Version 1
public struct WorldObjectData: IComponentData
{public float3 Position;public float3 Velocitiy;
}// Or ...
// Version 2
public struct PositionData: IComponentData
{public float3 Position;
}
public struct VelocityData: IComponentData
{public float3 Velocity;
}
如果您总是必须一起访问它们,您可以将多个值放入一个组件中。如果您有时只需要一个值而没有另一个值,则应该将它们分开。这里没有正确或错误的决定,您对数据建模的方式应取决于您的数据访问模式。
必须遵循的主要规则:
-
组件必须是结构。
-
组件必须实现 IComponentData。它是一个空接口,用作标记,仅用作通用约束。
-
只能包含可复制类型( blittable types)。这意味着原始类型、其他结构或枚举。也就是结构就是全部数据,没有指针指向其他地方。
-
您可以使用固定数组(fixed arrays)。因此,您必须将结构标记为不安全。字段声明如下所示:public fixed int Foo[6]。编译器在编译时就知道它的大小,并且可以内联数组而不是将其存储在堆上。
-
类不被允许!为什么?记住一个类是如何存储在内存中的。它位于堆上的某个地方,他的结构只包含一个指向它的指针。如果您访问它,您将创建一个缓存未命中,因为它在您的缓存行之外。
系统(System)
系统包含有关游戏一个方面的功能,每个系统都定义了它需要读写的组件。例如,一个移动系统需要一个 PositionComponent 和一个 VelocitiyComponent。
public class VelocitiySystem: ComponentSystem
{protected override void OnCreateManager(){// Init the system here }protected override void OnUpdate(){// Do your work here}
}
// The actual implementation is shown later
必须遵循的主要规则:
- 该类必须继承自 ComponentSystem
- 在 OnCreateManager 中,您可以在 ComponentGroup 的帮助下定义您的依赖关系。
- 每帧都会调用 OnUpdate。您可以从 ComponentGroup 中查询数据并对其进行操作
- 一个 ComponentSystem 在主线程中同步运行
如果你想异步运行你的代码,你可以使用 JobComponentSystem 作为基类。
SystemBase将是以后Runtime下System的唯一基类,这里的ComponentSystem和后面的JobComponentSystem将会在各种Package中逐步被替换掉,因为SystemBase包含了他们两个的功能。
这只是对 ECS 的基本模式以及 Unity 如何实现这些模式的非常简短的描述。
ECS内存布局(ECS Memory Layout)
ECS在组件和系统之间添加了一个抽象层。该层的工作方式有点像一个数据库,它抽象了实际的内存布局,并提供了独立于数据存储方式访问和迭代数据的能力。
实体管理器(Entity Manager)
EntityManager 为您提供创建、销毁和组合实体以及有效访问数据的功能。以下代码显示了如何创建新实体。
// An Archetype defines the components an entity has. This one defines
// and object in the game world that can move
EntityArchetype movingObjectArchetype = EntityManager.CreateArchetype(ComponentType.Create<PositionComponent>(),ComponentType.Create<MoveComponent>());// An entity in the game world that is static
EntityArchetype staticObjectArchetype = EntityManager.CreateArchetype(ComponentType.Create<PositionComponent>());// Those arrays will store the Id´s (not the data) of the created entities
NativeArray<Entity> movingEntities = new NativeArray<Entity>(10, Allocator.Persistent);
NativeArray<Entity> staticEntities = new NativeArray<Entity>(10, Allocator.Persistent);// Create 10 new moving entities
EntityManager.CreateEntity(movingObjectArchetype, movingEntities);
// Create 10 new static entities
EntityManager.CreateEntity(staticObjectArchetype, staticEntities);
该代码创建了二十个实体。它们都有一个 PostionComponent,但只有 10 个可以移动并且有一个 MoveComponent。让我们看看它们是如何存储在内存中的。
块(Chunks)和 IComponentData
Unity 以块的形式存储数据。每个块只包含一个原型的数据!在块内部,一个组件的数据是按顺序存储的。一个块的容量约为 16 KB。如果块已满并且创建了相同原型的新实体,则创建具有相同原型的新块。
运行上述示例时,Unity 将创建两个块,如下所示:
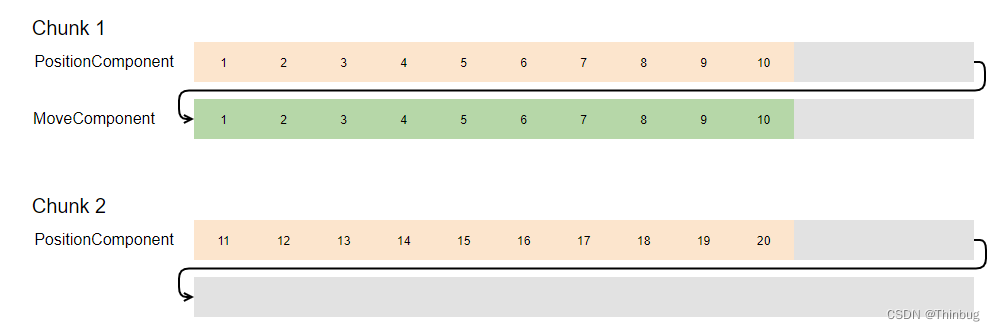
让我们想象每个块的容量为 26 个 float3 值。带颜色的框表示组件使用的插槽,而灰色的框为空。第二行框将直接跟随内存中的第一行。
Chunk1 可容纳 13 个实体。MoveComponent 和 PositionComponent 之间的可用空间相等,因为它们都需要相同的大小。每个组件的数据按顺序排列,以便快速迭代,最后为缺失的三个实体留出缓冲空间。Chunk2 可容纳 26 个实体。
让我们想象我们的一个Chunk2静态对象是一辆破车。如果玩家可以修复它并且让它开始移动会发生什么?
// This is the id of our car
Entity carEntity;
// Add the component to the car
EntityManager.AddComponentData(carEntity, new MoveComponent());
已经拥有 PositionComponent 的汽车会另外获得一个 MoveComponent。ECS 使用的“组合模式”非常适合这种变化。想想这对于面向对象的设计会有多复杂。
但是现在我们的内存布局会发生什么。一个块只允许包含一个原型,但我们的汽车现在改变了它的原型。因此,汽车实体现在被移动到具有movingObject的原型类型的块(Chunk 1)中。为简单起见,汽车实体的 ID 为 20。内存现在看起来像这样:
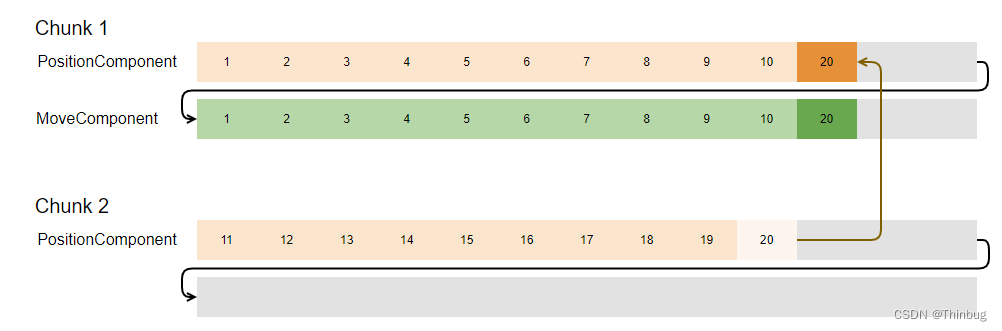
PositionComponent 被复制到另一个块中,并添加了 MoveComponent。
现在玩家用汽车撞到一棵树,树实体(id 为 13)需要被摧毁。现在数据内部存在差距。这是通过复制那里的最后一个元素来填充的。内存现在看起来像这样:
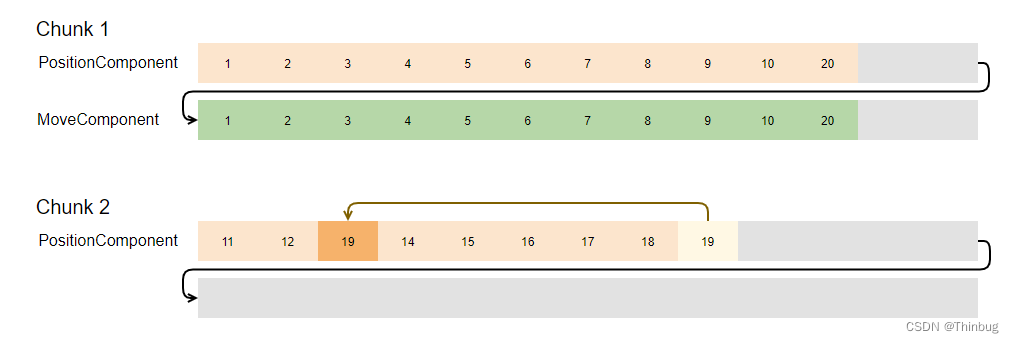
在实体之间共享数据
有时几个实体共享相同的数据。您可以使用 ISharedComponentData 代替向每个实体添加组件并复制它,而不是。
// Shared data need to implement the ISharedComponentData interface
// instead of IComponentData
public struct SharedData : ISharedComponentData
{public float SharedValue;
}SharedData sharedData1 = new SharedData { SharedValue = 2};
SharedData sharedData2 = new SharedData { SharedValue = 5};
// Lets imaging this array contains 6 of our moving objects
Entity[] entities;
for (int i=0; i<entities.Length; i++)
{// You can assign shared data to an entity like you do with normal// IComponentData. In this example every second entity gets// different data than the rest.EntityManager.AddSharedComponentData(entities[i], i % 2 == 1 ? sharedData1 : sharedData2 );
}
共享数据每个块只存储一次。这意味着具有不同共享数据的实体不能存储在同一个块中。分离是通过比较基于值的结构来完成的。我们示例中的第一个实体的“SharedValue”为 2,而第二个实体的“SharedValue”为 5。因此它们需要存储在不同的块中。但请记住,我们总共有 11 个移动元素,其中 5 个没有分配共享数据。这5个需要与其他人分开。块现在看起来像这样:
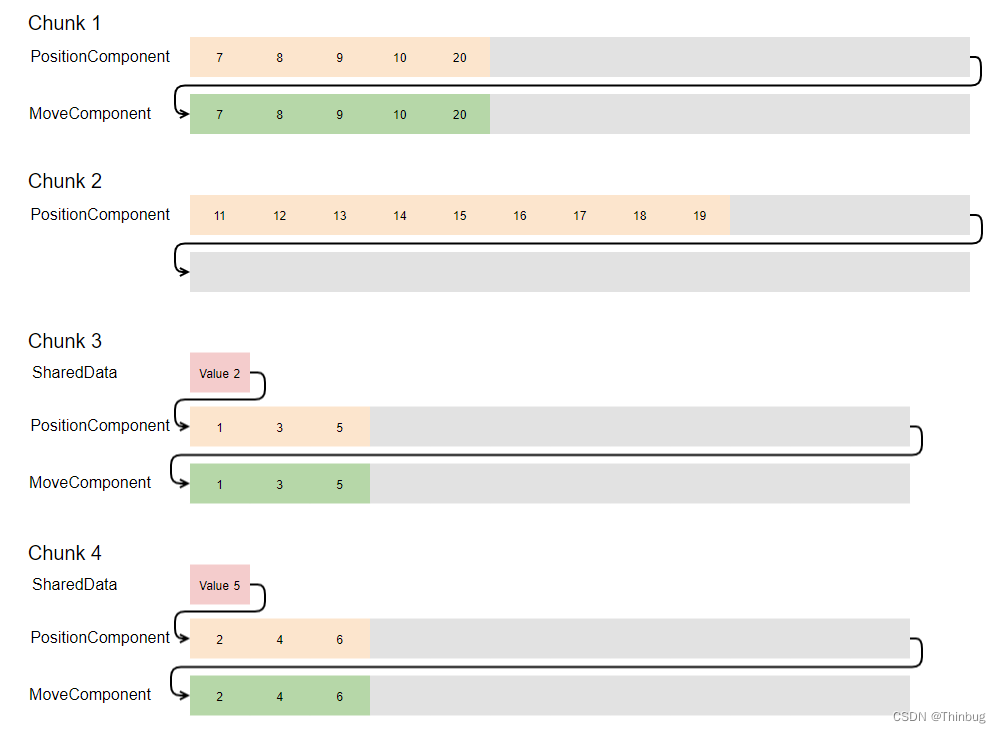
创建了两个新块,一个用于共享数据值 2,一个用于 5。根据它们是奇数还是偶数,分别将 3 个实体复制到新块中。在块的开头存储共享组件数据。因为这需要额外的空间,所以该块现在可以少容纳一个实体。
迭代数据(Iterating over data)
在上一章中,我们演示了数据布局如何影响迭代速度,但是如果系统必须迭代所有 PositionComponents 会发生什么。它们现在被分成四个块。因此,Unity 提供了一个迭代器来轻松访问拆分为多个块的数据。下面的代码展示了一个系统的实现。
public class PositionInitSystem: ComponentSystem
{private ComponentGroup _componentGroup;protected override void OnCreateManager(){// An entity query defines which components are needed by your // systemvar query = new EntityArchetypeQuery{All = new ComponentType[]{ typeof(PositionComponent) }};// You can query from the ComponentGroup the data_componentGroup = GetComponentGroup(query);}protected override void OnUpdate(){// ComponentDataArray is an iterator that automatically// calculates the correct memory offsets between chunks when you// use the [] operatorComponentDataArray<PositionComponent> positionData = componentGroup.GetComponentDataArray<PositionComponent>();// Use the ComponentDataArray like a normal array. The length// will be 20for (int i = 0; i < positionData.Length; i++){// The [] operator calculates correct memory location even// if the data is divided between chunkspositionData[i] = new PositionComponent(new float3(0, 1, 0));}}
}
上面的代码完美地展示了您的系统和数据之间的抽象层。您实际上不知道内存是如何组织的,以及您的哪些组件存储在哪个块中。
结论
在本章中,我们看到了实体-组件-系统如何在内部存储数据。ECS 尝试将相同类型的组件按顺序存储在内存中。如果您有许多由不同组件组合组成的实体,则将相同类型的组件隔离到许多不同的内存位置。这将产生大量缓存未命中并降低性能。因此,重要的是要知道一个块如何在内部工作以检测这种情况。在某些用例中,借助 NativeArrays 将数据存储在 ECS 之外可能会更好。
到目前ECS的一些缺点:
- ECS 仍处于预览阶段
- 学习曲线非常陡峭,你经常会遇到一些问题,如果你不去论坛上寻找解决方案或做一些蹩脚的变通方法,你就无法解决这些问题。
- 很多文档都丢失了,甚至更糟——已经过时了。在谷歌上也很难找到详细而深入的信息。您经常需要在 Unity 论坛上发帖或自己查看源代码。
- API 仍在不断变化。注入等功能已被弃用,您必须迁移代码。
- 有些问题仍然没有解决,比如使用String。
- 值得一提的是,绝对不建议使用基于网格的数据。ECS不会关心你相邻的单元是否在内存中,这让您像疯子一样跳过您的内存。
并行化
如果没有作业(jobs),在 Unity 中就不可能多线程运行您的代码。您当然可以创建自己的 C# 线程并使用 Unity 的主线程管理同步点,但您不能在主线程之外使用 Unity API 的任何方法。
工作系统(Job-System)
作业系统为您提供了一个界面,可以轻松地并行化您的代码并将您的数据与主线程同步。Unity 的 Job 系统从开发人员那里抽象出直接的线程处理,就像普通的 C# Tasks 或 Java Runnables 一样。该作业不是直接使用线程,而是在中央调度程序中排队并在线程可用时执行。
Job-System 已准备好用于生产,Unity 内部使用它来完成大量繁重的工作,例如动画和批处理转换。
Jobs and ECS
作业系统集成到实体-组件-系统中。以下代码显示了 Unity 在其文档中的使用示例。
public class RotationSpeedSystem : JobComponentSystem
{ struct RotationSpeedRotation : IJobProcessComponentData<Rotation, RotationSpeed>{public float dt;public void Execute(ref Rotation rotation, [ReadOnly]ref RotationSpeed speed){rotation.value = math.mul(math.normalize(rotation.value), quaternion.axisAngle(math.up(), speed.speed * dt));}}// Any previously scheduled jobs reading/writing from Rotation or// writing to RotationSpeed will automatically be included in the // inputDeps dependency.protected override JobHandle OnUpdate(JobHandle inputDeps){var job = new RotationSpeedRotation() { dt = Time.deltaTime };return job.Schedule(this, inputDeps);}
}
JobComponentSystem现在不是继承自 ComponentSystem,而是基类。在 System 类内部,实际的Job被定义为 struct。之前在 OnUpdate 方法中实现的逻辑现在移至作业的Execute函数。该作业可以实现几个接口。最简单的是 IJobProcessComponentData。作为通用参数,输入类型被定义。然后,Unity 会将正确的数据传递给 Execute 函数,每个实体都会调用一次。如果您需要更多控制,可以使用 IJobParralelFor 接口。
代码中的JobComponentSystem和IJobProcessComponentData已经过时,这里只做了解。
依赖管理(Dependency Management)
当多个系统读取和写入相同的数据时会发生什么?幸运的是,Unity 添加了一个自动依赖管理系统。上一个示例中的 RotationSpeedSystem 系统更新了 RotationComponent。假设我们有一个 RenderSystem。这将读取当前的 Rotation 以及 PositionComponent 和可能的 ScaleComponent 并渲染对象。RenderSystem 只能在 RotationSpeedSystem 完成后启动。否则旋转数据不会完全更新。您可以使用 [UpdateBefor]、[UpdateAfter] 和 [UpdateInGroup] 三个属性来定义系统执行的顺序。
但是,您已安排并正在排队等待的作业当然也必须等待每个作业。这是由JobHandle完成的输入Deps。当您安排作业时,您可以选择传入另一个作业的作业句柄。如果你这样做了,新工作将等待另一份工作。如果您有多个依赖项,您还可以将多个句柄组合成一个新句柄。对于 JobComponentSystem,Unity 会自动将 JobHandle 传递给 OnUpdate 函数,该函数使用系统的依赖项进行初始化。
以下代码显示了如何管理 ECS 之外的依赖项。
public struct MyJob : IJobParallelFor
{// ....
}MyJob jobA = new MyJob();
MyJob jobB = new MyJob();// Schedule the job. The second parameter defines on how many elements a
// thread works in sequence. Think about: False Sharing
JobHandle handleA = jobA.Schedule(1000, 64);
// Add the handle of the first job as third argument.
JobHandle handleB = jobB.Schedule(1000, 64, handleA);// Block until jobB is finished
handleB.Complete();
自动竞争条件检查(Automatic race condition checks)
并行化代码时,竞争条件或者竞态条件(race condition)是最有问题的事情之一。因为查找和调试它们非常痛苦,Unity 创建了一个系统,可以自动检测 DEBUG 构建中的任何竞争条件。为了使这成为可能,C# 语言受到严格限制。最大的痛点是,不允许使用任何托管对象(存在于 C# 世界中的对象)。这完全禁止使用类。可以使用来自新 Collections API 的 NativeArrays 来代替 C# 数组。它们是指向 C++ 堆的指针,在不再需要它们后需要手动处理。C# 垃圾收集器不会释放保留的内存。这意味着没有指针/引用修复,所以没有类,没有引用,托管堆上没有任何东西。在设计数据时,您应该将其设计为使用简单类型,如 int、float、bool 等,以及仅包含这些类型的结构。您应该相应地规划您的数据类型。
当您创建竞争条件时,例如一个线程正在写入数组而另一个线程正在读取数据,您将收到运行时错误。
性能测试
以下测试将在作业中从上面运行示例 RotationSpeedSystem,并在主线程中同步运行。这是结果:
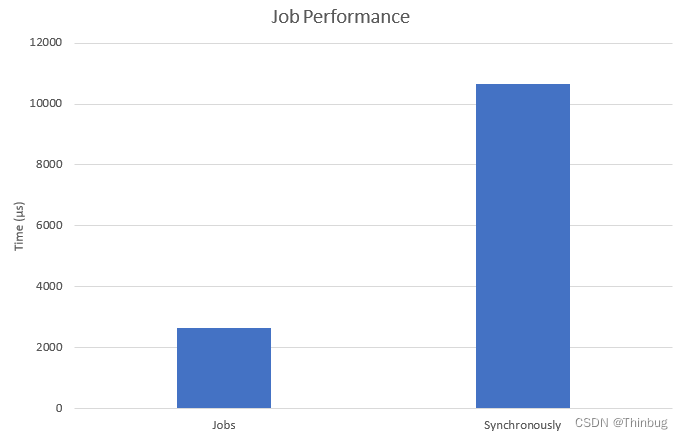
在具有 4 个内核的处理器上,这些作业的速度大约快 4 倍。
只要有可能,您应该并行化您的算法以使用全部硬件容量
使用 Burst-Compiler 进行编译器优化
归根结底,实现最佳性能归结为充分利用硬件。为此,您需要在最低级别优化您的代码。这意味着用 C++ 甚至 C 等语言编写可以直接在处理器上执行的逻辑。这为一些疯狂的优化打开了大门,例如 SIMD 指令、自定义汇编程序。除了必须纠正令人痛苦的复杂代码之外,缺点是这种方法会阻止您使用 Unity 最重要的功能之一:在多个平台上发布游戏的能力。Burst-Compiler 将您的 .NET 字节码转换为高度优化的机器码,让其在目标系统的处理器上运行,并且可以充分利用您正在编译的平台。
与 Job-System 一样,Burst-Compiler 也严格限制了 C# 语言。不允许托管对象(类类型和数组)。相反,您只能使用 blittable 数据(托管数据)类型。
SIMD
经典的处理器架构可以用一条指令处理一个数据值。这称为单指令单数据或 SISD。
但是现代 CPU 有一个额外的指令集,称为单指令多数据 (SIMD)。这是什么意思?一条加法指令可以在一个处理器周期内对多个值求和。
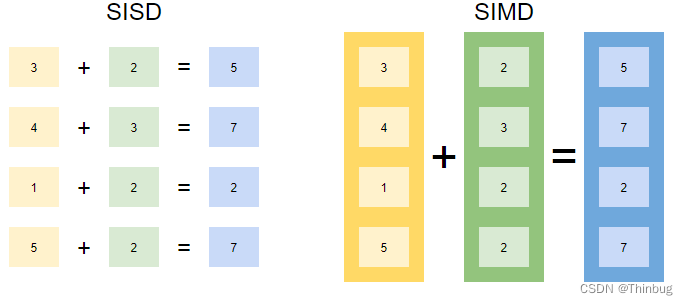
因为同时处理多个值,所以这也称为矢量化。向量大小大多为 16 或 32。
在台式计算机上,附加指令集称为 Streaming SIMD Extensions 4 (SSE4),并具有 54 个附加操作。它在 Intel 和 AMD 处理器上得到广泛支持。指令集取决于硬件。这意味着对于不同的目标平台,需要不同的指令集。这就是为什么许多编译器(包括 Mono)不支持 SIMD 指令的原因,但这正是 Burst-Compiler 的一个关键方面。它能够矢量化你的 for 循环以产生更有效的机器代码。
性能测试
// To use the Burst compile you have to add this attribute
[BurstCompile]
public struct JobWithBurst : IJobParallelFor
{public float Dt;public NativeArray<Rotation> RotationData;public NativeArray<RotationSpeed> SpeedData;public void Execute(int index){Rotation rotation = RotationData[index];rotation.Value = math.mul(math.normalize(rotation.Value), quaternion.AxisAngle(math.up(), SpeedData[index].Speed * Dt));RotationData[index] = rotation;}
}
该作业存在两次,一次使用 [BurstCompile],一次没有。让我们看看性能有何不同。
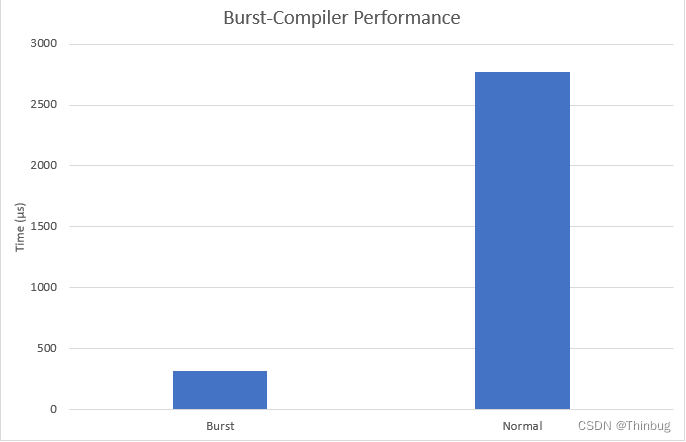
在这个例子中,使用突发编译代码的工作几乎快了 9 倍!
没有使用ECS项目中的Jobs和Burst
Job System 和 Burst Compiler 完全独立于 ECS。
您在没有 ECS 的情况下仍然可以获得完整的性能。除了使用 Job-System 和 Burst-Compiler 之外,最大的变化是从面向对象的设计切换到面向数据的设计。ECS 完美地实现了面向数据的设计,并为您提供了一个干净的界面来处理您的数据。因此,ECS 在实际数据(组件)和您的逻辑(系统)之间添加了一个额外的层。这提供了很大的灵活性,但就像每个抽象层一样,也增加了一些性能开销。如果您的用例不需要 ECS 或者您无法迁移代码,您仍然可以使用其他技术堆栈,并通过将数据直接存储在 NativeArrays 中来获得相同甚至更好的性能。你唯一需要做的事:以数据为导向思考和编程。
以下示例将显示一个没有 ECS 的作业的简单设置。
[BurstCompile]
public struct Job : IJobParallelFor
{[ReadOnly]public NativeArray<IsometricCoordinateData> IsometricCoordinates;[ReadOnly]public NativeArray<HeightData> Heights;public NativeArray<TemperatureData> Temperature;public void Execute(int index){float iso = IsometricCoordinates[index].IsometricCoordinate.x / 90float alpha = 1 - math.abs(iso);float height = 1- Heights[index].Height;CellAirTemperatureData airTemperature = Temperature[index];airTemperature.Temperature = alpha * height;Temperature[index] = airTemperature;}
}
该作业根据到赤道的距离和高度计算行星上 0 到 1 之间的相对温度。它将工作分散在几个 CPU 内核上。以下代码将设置并运行该作业。
int cellCount = 100000;
// Create NativeArray arrays to store your data
NativeArray<IsometricCoordinateData> isometricCoordinateData = new NativeArray<IsometricCoordinateData>(cellCount, Allocator.TempJob);
NativeArray<HeightData> heightData = new NativeArray<HeightData>(cellCount, Allocator.TempJob);
NativeArray<TemperatureData> temperatureData = new NativeArray<TemperatureData>(cellCount, Allocator.TempJob);// Fill with data...
// You can also use Allocator.Persistance if you only want to fill the
// arrays once and reuse it every frame// Create a new job and assign the data
var job = new Job
{Temperature = temperatureData,IsometricCoordinates = isometricCoordinateData,Heights = heightData
};
// Put the job into the queue
var jobHandle = job.Schedule(cellCount, 32);
// You don´t need to call Complete() directly after schedule, because it
// will block the main thread. Instead call it when you actually need
// the result
jobHandle.Complete();// You need to dispose arrays manually, because they are not managed by
// the garbage collector
isometricCoordinateData.Dispose();
heightData.Dispose();
temperatureData.Dispose();
考虑数据是否只读
声明只读数据很重要,因为它允许 Job Scheduler 安全地并行化处理它的作业。这反过来又为作业调度程序提供了更多选项来确定如何安排已调度的作业,从而最有效地使用可用 CPU 线程。在包含反应式系统(即仅在数据更改时更新的系统)的项目中,正确地将数据声明为只读也很重要。以读/写方式访问数据会导致这些反应式系统运行,即使数据实际上并没有改变。由于这些原因,您应该将只读数据(在某些转换中)与读/写数据分离为不同的组件。
在 Entities.ForEach() 和作业中正确声明写入权限
为Entities.ForEach()定义 lambda 函数时,请确保使用in关键字将组件参数声明为只读。如果您需要修改 lambda 中的组件数据,请将这些参数声明为ref。in 参数必须在ref参数之后。
使用属性标记作业中的 [ReadOnly] 变量
在作业结构(例如IJobChunk)中声明数据时,请确保未在作业的Execute()方法中写入的变量标记为[ReadOnly] 。
尽可能使用 ComponentDataFromEntity 或 BufferFromEntity 的只读版本
请注意,这两种方法都采用可选的布尔值,如果您只打算读取组件/缓冲区数据,则应将其作为 true 传递。
最后举例:
var fooFromEnt = GetComponentDataFromEntity<Foo>(true);
var myBufferFromEnt= GetBufferFromEntity<MyBufferData>(true); Entities.WithAll<Qux>().WithReadOnly(fooFromEnt).WithReadOnly(myBufferFromEnt).ForEach((ref Bar bar, in Baz baz) => { // ... }.ScheduleParallel();
- 必须对具有组件的实体进行操作:Bar 、Baz 、Qux
- 必须将 Bar 视为读/写,将Baz视为只读。不需要读取或写入Qux
- 必须具有对实体的Foo组件和MyBufferData缓冲区的随机、非线性、只读访问权限,您将在每个实体的基础上进行查找
- 您想安排作业并行运行
视情况而定的优化
当您做出决定时,请考虑给定的代码是每帧运行 100,000 次、每帧运行一次、每隔几秒运行一次,还是仅在初始化期间运行。专注于频繁的操作。
不要使用字符串
Job System 和 Burst 支持许多原始类型,包括各种大小的整数和浮点类型,以及bool 。将来会支持char 。但是,Job System 和 Burst 不支持 C#字符串类型,因为字符串是托管类型。
对于大多数其他内部目的,您应该将人类可读的字符串标识符转换为 blittable、运行时友好的格式,以加快处理速度。根据您的用例,这可能是一个枚举、一个简单的整数索引,或者可能是从字符串计算的哈希值。Entities 0.16 提供了XXHash类,它可以为此目的生成 32 位或 64 位哈希。
如果您需要使用字符串,有一些对 DOTS 友好的选项。Collections 包包含许多类型,例如FixedString32和FixedString64。注意:在 0.11 之前的 Collections 包版本中,它们分别称为 NativeString32 和 NativeString64。
以上简单的阐述了DOTS的学习。
结束语
从面向对象设计转向面向数据设计与学习一种新的编程语言或一种新的编码方式不同。相反,这是您处理编码方式的转变,以及您通过代码构建的信息的表示方式。
即使对于经验丰富的开发人员来说,向以数据为导向的思维转变也可能具有挑战性。这是因为代码设计实践和抽象行为的方式已经成为第二天性需要重新成像。使用面向数据的方法,您被迫以不同的方式考虑代码,将对象、类和行为减少到所需的数据,并有效地组织这些数据,以便可以对其进行转换以首先解决您的常见问题。在实践中,这不是一项微不足道的任务,需要时间来改进并专注于理解数据和学习如何使用 DOTS 以最好地处理数据。
DOTS 是 Unity 的未来。Unity 的架构正在向各个方面采用 DOTS。这正在缓慢发生,但是通过现在了解 DOTS,随着我们在 Unity 功能中推出 DOTS,过渡会更容易。
面向数据的设计 (DoD) 是实时 3D 行业的未来。利用 DoD 原则和实现来解决问题和开发复杂解决方案的趋势越来越明显,尤其是在游戏领域。
引用:
面向数据的设计
Unity`s “Performance by Default” under the hood
DOTS Best Practices
What is DOTS and why is it important?
这篇关于Unity DOTS 学习笔记3 - 面向数据设计的基本概念(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






