本文主要是介绍【AI视野·今日Robot 机器人论文速览 第四十九期】Fri, 6 Oct 2023,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI视野·今日CS.Robotics 机器人学论文速览
Fri, 6 Oct 2023
Totally 29 papers
👉上期速览✈更多精彩请移步主页

Interesting:
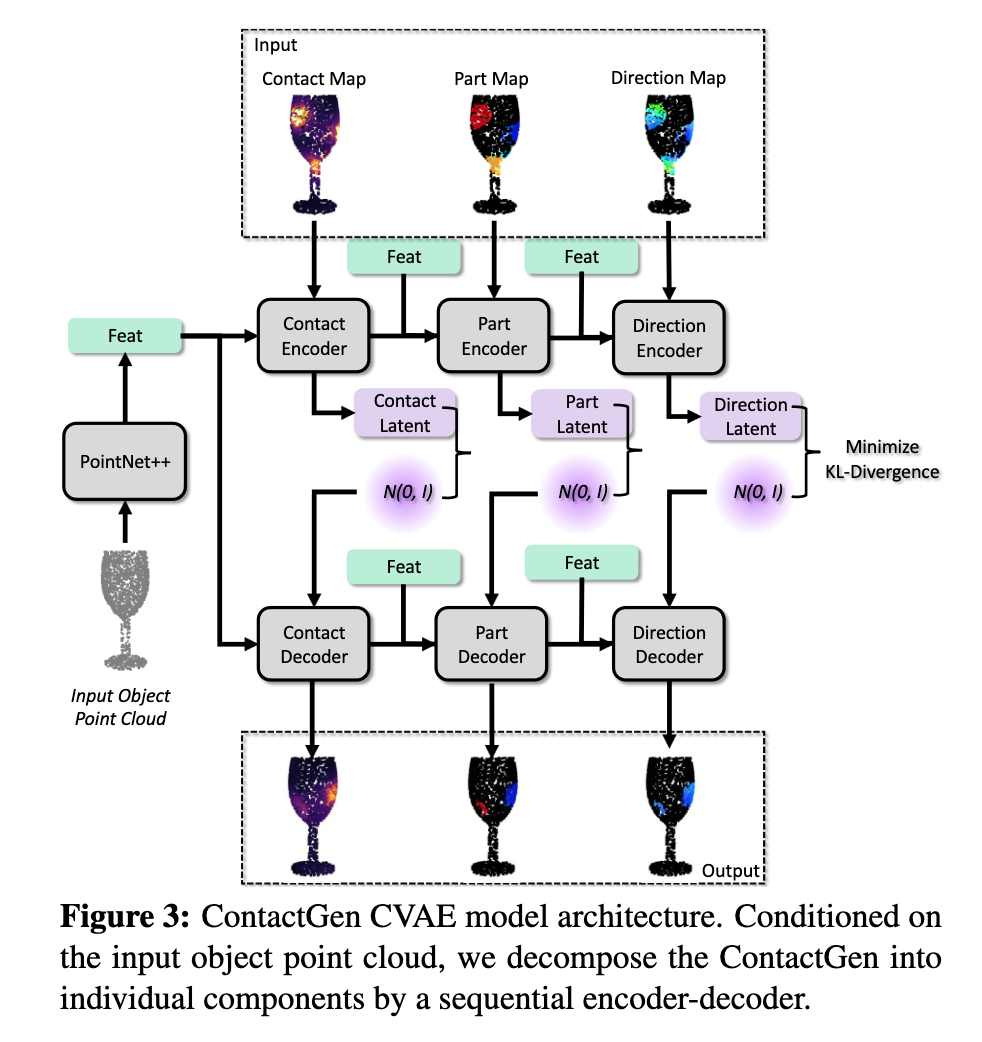
📚ContactGen, 基于生成模型的抓取手势生成,类人五指手。(from 伊利诺伊大学 香槟)
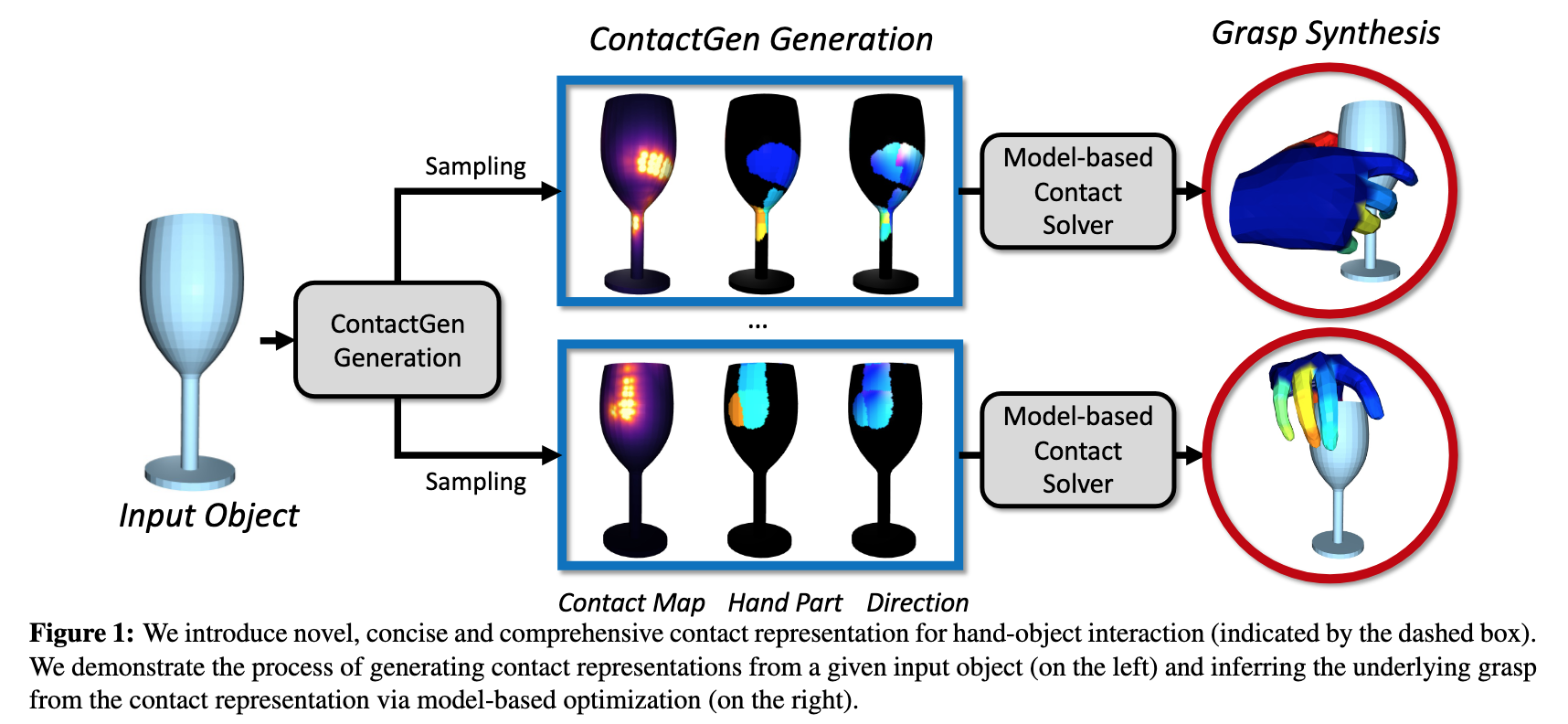
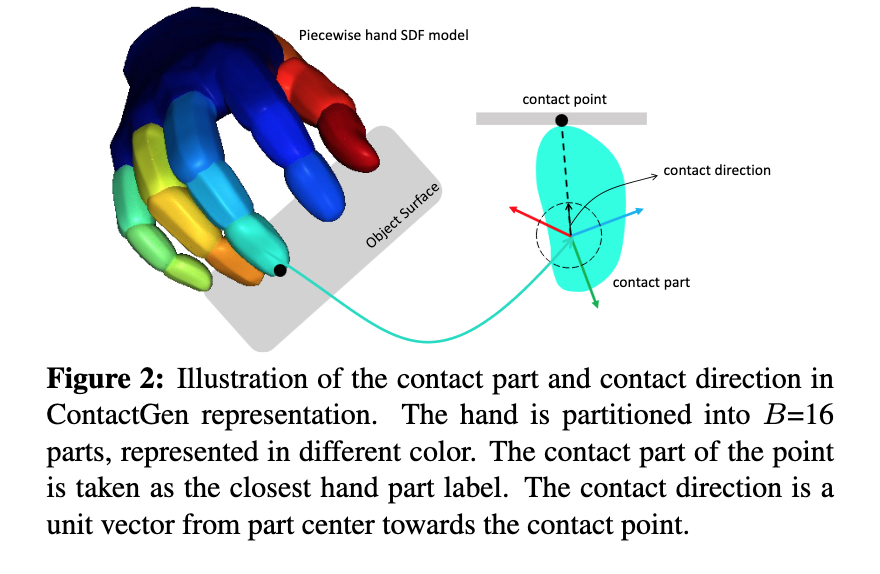
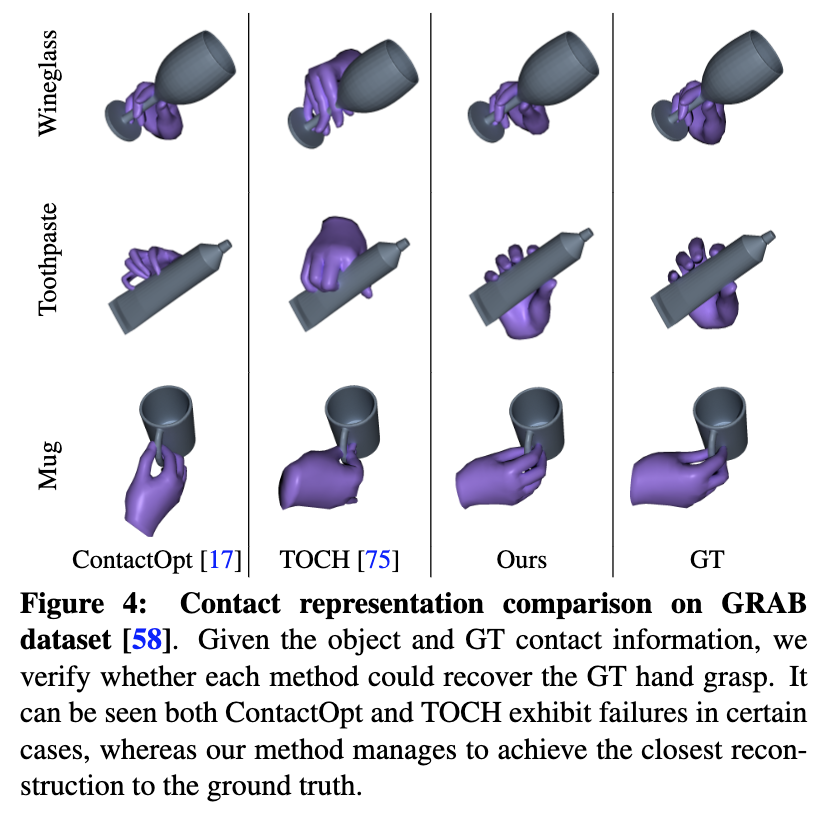
数据集:GRAB dataset [58] HO3D dataset [20].
相关方法:GraspTTA [28] Grasping Field [31] (GF) HALO [30]
website:https://stevenlsw.github.io/contactgen/
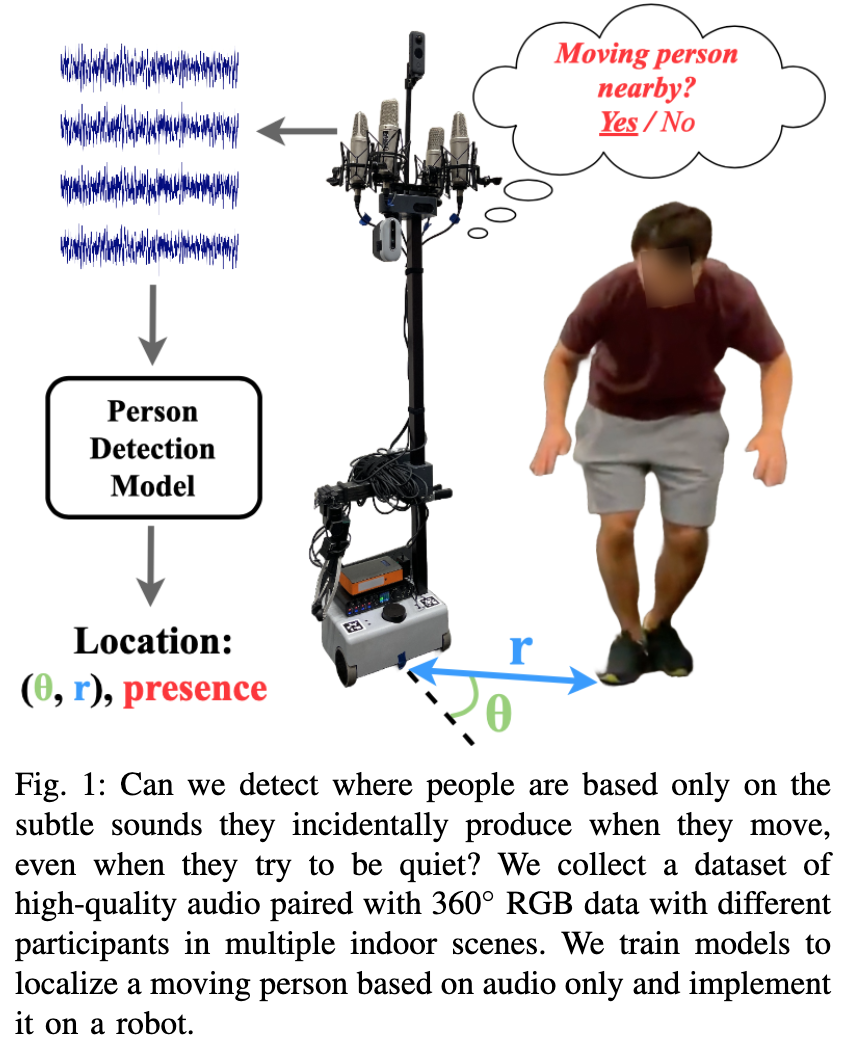
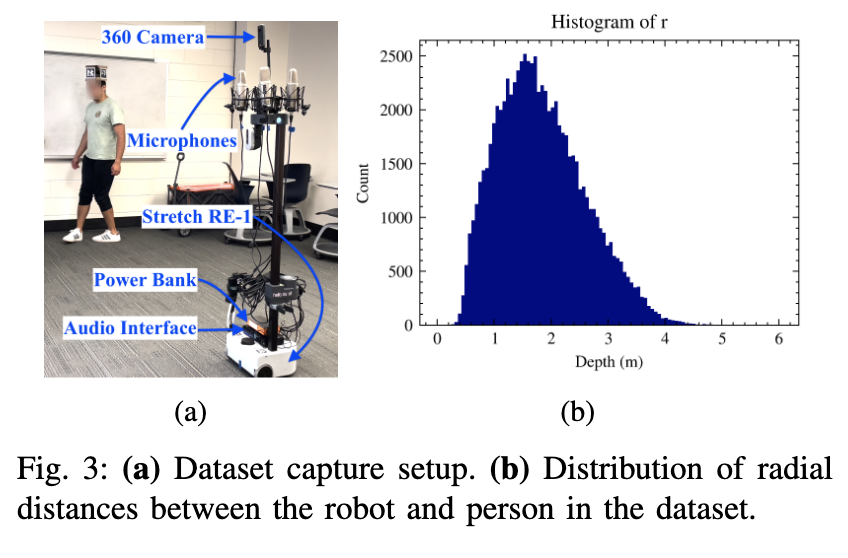
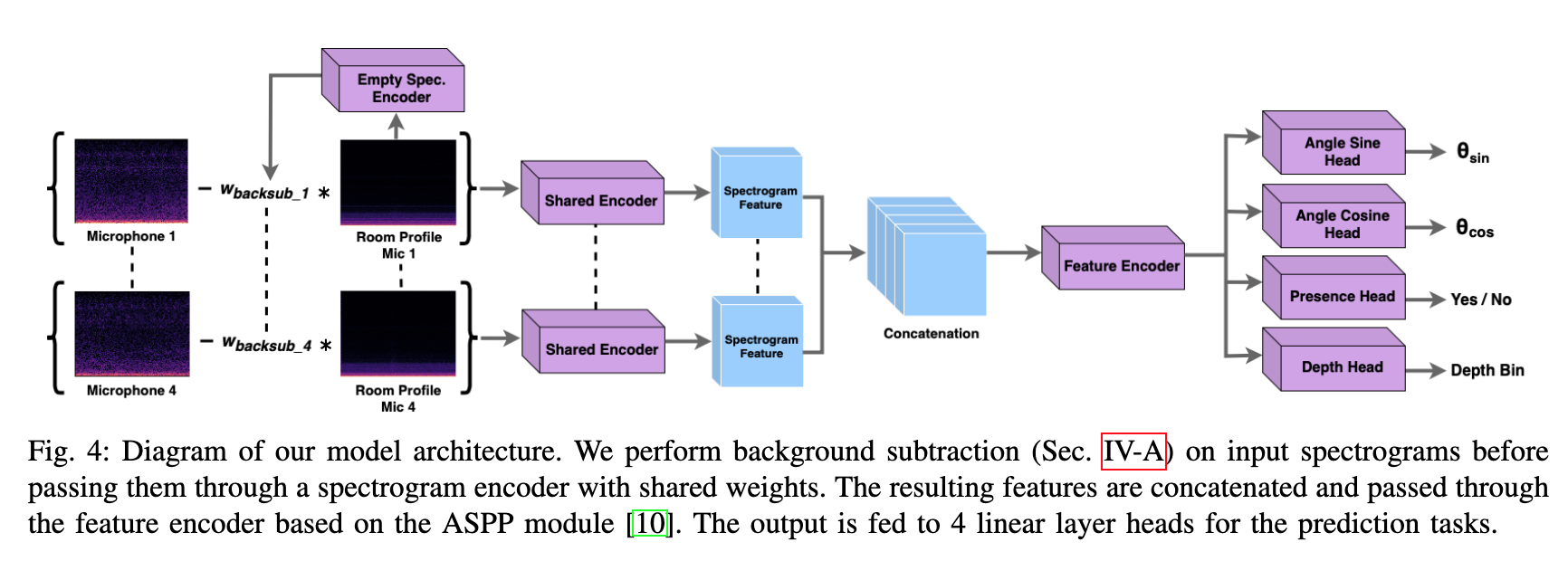
📚The Un-Kidnappable Robot, 基于声学信号判断定位周围的人。利用360度相机收集GTpose和position,micphone阵列收集声音信号(from 佐治亚理工)
website:https://sites.google.com/view/unkidnappable-robot
Daily Robotics Papers
| The Un-Kidnappable Robot: Acoustic Localization of Sneaking People Authors Mengyu Yang, Patrick Grady, Samarth Brahmbhatt, Arun Balajee Vasudevan, Charles C. Kemp, James Hays 偷偷接近机器人有多容易我们研究是否可以仅利用人们移动时发出的附带声音来检测人们,即使他们试图保持安静。我们收集了高质量 4 通道音频的机器人数据集,以及在不同室内环境中移动的人员的 360 度 RGB 数据。我们训练模型仅使用音频来预测附近是否有移动的人及其位置。我们在机器人上实现了我们的方法,使其能够仅通过被动音频传感来跟踪安静移动的单个人。 |
| PV-OSIMr: A Lowest Order Complexity Algorithm for Computing the Delassus Matrix Authors Ajay Suresha Sathya, Wilm Decre, Jan Swevers 我们提出了 PV OSIMr,一种用于计算 Delassus 矩阵(也称为运动树的逆运算空间惯性矩阵)的有效算法,具有文献中已知的最低阶计算复杂度。 PV OSIMr 是通过使用力和运动传播器的组合来优化 Popov Vereshchagin PV 求解器计算而得出的。与原始 PV OSIM 算法的 O n m 2d 和扩展力传播器算法 EFPA 的 O n md m 2 相比,它的计算复杂度为 O n m 2 ,其中 n 是关节数量,m 是约束数量,d是运动树的深度。由于Delassus矩阵计算需要构造一个m x m大小的矩阵,并且必须至少考虑一次所有n个关节,因此PV OSIMr的渐近计算复杂度是最优的。 |
| A Suspended Aerial Manipulation Avatar for Physical Interaction in Unstructured Environments Authors Fanyi Kong, Grazia Zambella, Simone Monteleone, Giorgio Grioli, Manuel G. Catalano, Antonio Bicchi 本文提出了一种漂浮机器人,能够在非结构化环境中在人类监督下以类似人类的灵活性执行物理交互任务。该机器人由连接到六轴飞行器的人形躯干组成。两个自由度头部和两个配备软手的五自由度手臂提供了必要的灵活性,使操作员能够执行各种任务。手臂特意设计了坚固的腱驱动结构,大大减少了手臂惯性对运动中浮动底座的影响。此外,肌腱为关节提供了灵活性,从而增强了手臂的坚固性,防止与环境相互作用时造成损坏。为了增加航空系统的有效负载和电池寿命,我们使用悬挂空中操纵的概念,即飞行人形机器人可以通过系绳连接到结构,例如更大的机载载体或支撑起重机。重要的是,为了最大限度地提高便携性和适用性,我们采用模块化方法,利用无人机硬件和自动驾驶仪的商业组件,同时开发全身外部控制回路来稳定机器人姿态,补偿系绳力以及人形头部和手臂运动。该人形机器人可以由远程操作员控制,从而有效地实现了悬浮空中操纵化身。 |
| Resilient Legged Local Navigation: Learning to Traverse with Compromised Perception End-to-End Authors Jin Jin, Chong Zhang, Jonas Frey, Nikita Rudin, Matias Mattamala, Cesar Cadena, Marco Hutter 自主机器人必须在未知环境中可靠地导航,即使在外部感知受损或感知失败的情况下也是如此。当恶劣的环境导致感知能力下降,或者感知算法由于泛化能力有限而误解场景时,通常会发生此类故障。在本文中,我们将感知失败建模为看不见的障碍物和坑,并训练基于强化学习的局部导航策略来引导我们的腿式机器人。与之前依靠启发式和异常检测来更新导航信息的工作不同,我们训练导航策略以从损坏的感知中重建潜在空间中的环境信息,并对感知失败进行端到端的反应。为此,我们将本体感觉和外感觉都纳入我们的策略输入中,从而使策略能够感知不同身体部位和凹坑的碰撞,从而引发相应的反应。我们在仿真中以及在实时运行 10 毫秒 CPU 推理的真实四足机器人 ANYmal 上验证了我们的方法。与现有的基于启发式的局部反应规划器进行定量比较,我们的策略在面临感知失败时将成功率提高了 30 以上。 |
| RadaRays: Real-time Simulation of Rotating FMCW Radar for Mobile Robotics via Hardware-accelerated Ray Tracing Authors Alexander Mock, Martin Magnusson, Joachim Hertzberg RadaRays 可以对复杂环境中的旋转 FMCW 雷达传感器进行精确建模和仿真,包括模拟雷达波的反射、折射和散射。我们的软件能够处理大量物体和材料,使其适用于各种移动机器人应用。我们通过一系列实验证明了 RadaRays 的有效性,并表明与自动驾驶模拟器中常用的基于光线投射的激光雷达模拟相比,它可以更准确地再现 FMCW 雷达传感器在各种环境中的行为。作为卡拉。我们的实验还为研究人员评估他们自己的雷达模拟提供了宝贵的参考点。通过使用 RadaRays,开发人员可以显着减少与原型设计和测试基于 FMCW 雷达的算法相关的时间和成本。 |
| RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation Authors Boshi An, Yiran Geng, Kai Chen, Xiaoqi Li, Qi Dou, Hao Dong 机器人操纵需要对环境进行准确的感知,由于其固有的复杂性和不断变化的性质,这构成了重大挑战。在这种情况下,RGB 图像和点云观测是基于视觉的机器人操作中两种常用的模式,但每种模式都有其自身的局限性。由于发射接收成像原理的限制,商业点云观测经常遇到采样稀疏、输出噪声等问题。另一方面,RGB 图像虽然富含纹理信息,但缺乏对机器人操作至关重要的基本深度和 3D 信息。为了缓解这些挑战,我们提出了一种仅图像的机器人操纵框架,该框架利用安装在机器人平行夹具上的手眼单目相机。通过与机器人夹具一起移动,该相机能够在操纵过程中从多个角度主动感知物体。这使得能够估计可用于操纵的 6D 物体姿势。虽然从更多和不同的角度获取图像通常可以改善姿势估计,但它也会增加操作时间。为了解决这种权衡问题,我们采用强化学习策略将操纵策略与主动感知同步,从而实现 6D 姿态准确性和操纵效率之间的平衡。我们在模拟和现实环境中的实验结果展示了我们方法的最先进的有效性。据我们所知,这是第一个通过主动姿态估计实现稳健的现实世界机器人操作的技术。 |
| Cyber Physical System Information Collection: Robot Location and Navigation Method Based on QR Code Authors Hongwei Li, Tao Xiong 在本文中,我们提出了一种使用 QR 码中存储的四个特征点的准确地理坐标快速响应码和从 QR 码分析的四个特征点的像素坐标来估计网络物理系统中摄像机的准确位置的方法相机拍摄的图像。首先,设计P4P Perspective 4 Points算法,利用所选QR码的四个特征点唯一确定QR坐标系相对于相机坐标系的初始位姿估计值。第二步,设计流形梯度优化算法。以旋转矩阵和位移向量作为迭代的初始值,进行迭代优化,以提高定位精度,获得精度更高的旋转矩阵和位移向量。第三步,将QR坐标系相对于相机坐标系的位姿转换为AGV自动导引车相对于世界坐标系的位姿。最后,在相同条件下对流形梯度优化算法和P4P解析算法的性能进行了仿真比较。可以看出,当信噪比较小。随着信噪比的增加,P4P解析算法的性能接近流形梯度优化算法。当噪声相同时,流形梯度优化算法的性能更好。 |
| RUSOpt: Robotic UltraSound Probe Normalization with Bayesian Optimization for In-plane and Out-plane Scanning Authors Deepak Raina, Abhishek Mathur, Richard M. Voyles, Juan Wachs, SH Chandrashekhara, Subir Kumar Saha 自主机器人超声系统面临的重大挑战之一是获取不同患者的高质量图像。机器人探头的正确方向对于控制超声图像的质量起着至关重要的作用。为了应对这一挑战,我们提出了一种有效的方法来自动调整超声探头垂直于扫描表面接触点的方向,从而改善探头的声耦合和最终的图像质量。我们的方法利用基于贝叶斯优化 BO 的扫描表面搜索来有效地搜索归一化探针方向。我们为 BO 制定了一个新颖的目标函数,它利用接触力测量和基础力学来识别法线。我们进一步在 BO 中加入正则化方案来处理噪声目标函数。所提出策略的性能已通过膀胱模型实验进行了评估。这些体模包括平面、倾斜和粗糙的表面,并使用具有不同搜索空间限制的线性和凸面探头进行检查。此外,还使用 3D 人体网格模型进行了基于模拟的研究。 |
| Kinodynamic Motion Planning for a Team of Multirotors Transporting a Cable-Suspended Payload in Cluttered Environments Authors Khaled Wahba, Joaquim Ortiz Haro, Marc Toussaint, Wolfgang H nig 我们提出了一种运动规划器,用于在充满障碍物的环境中使用多个无人机进行电缆驱动的有效负载运输。我们的规划器是运动动力学的,即它考虑了运输系统的完整动力学模型,包括驱动约束。由于规划问题的高维性,我们使用分层方法,首先使用基于采样的方法和新颖的采样器来解决几何运动规划,然后进行考虑系统完整动态的约束轨迹优化。两个规划阶段都考虑机器人之间和机器人障碍物碰撞。我们在软件在环仿真中证明,与单独规划有效载荷的标准方法相比,这种有效载荷运输系统的运动动力学运动规划在有效载荷跟踪误差和能耗方面具有显着的优势。 |
| Progressive Adaptive Chance-Constrained Safeguards for Reinforcement Learning Authors Zhaorun Chen, Binhao Chen, Tairan He, Liang Gong, Chengliang Liu 强化学习 RL 的安全保证对于现实场景中的探索至关重要。在处理约束马尔可夫决策过程时,当前的方法在最优性和可行性之间进行权衡时遇到了内在的困难。直接优化方法不能严格保证训练安全性的状态,而基于投影的方法通常效率低下,并且需要通过长时间的迭代才能正确执行操作。为了解决这两个挑战,本文提出了一种安全成本的自适应替代机会约束,以及一种通过快速拟牛顿法纠正上层策略层产生的动作的分层架构。理论分析表明,放宽的概率约束能够充分保证安全集的前向不变性。我们在 4 个模拟和现实世界的安全关键机器人任务上验证了所提出的方法。 |
| Design Optimizer for Planar Soft-Growing Robot Manipulators Authors Fabio Stroppa 软生长机器人是一种创新设备,其特点是受植物启发而生长以适应环境。由于它们具有适应周围环境的智能以及驱动和制造方面的最新创新,因此可以利用它们来执行特定的操作任务。 |
| Time-Optimal Trajectory Planning in Highway Scenarios using Basis-Spline Parameterization Authors Philip Dorpm ller, Thomas Schmitz, Naveen Bejagam, Torsten Bertram 基础样条可以在有限数量的约束下进行时间连续的可行性检查。约束适用于需要无碰撞且动态可行轨迹的运动规划应用的整个轨迹。现有的运动规划器依赖于基于梯度的优化,应用时间缩放来实现缩小的规划范围。它们既不能保证递归可行的轨迹,也不能在不同的时间尺度上到达两个终端流形部分。本文提出了一种非线性优化问题,解决了现有方法的缺点。因此,样条断点包含在优化变量中。实现样条基之间的变换,从而实现稀疏问题的表述。断点移除策略使得收敛到终端流形成为可能。 |
| Generalized Benders Decomposition with Continual Learning for Hybrid Model Predictive Control in Dynamic Environment Authors Lin Xuan 具有连续变量和离散变量的混合模型预测控制 MPC 广泛适用于机器人控制任务,特别是涉及与环境接触的机器人控制任务。由于组合复杂性,混合 MPC 的求解速度对于实时应用来说可能不够。在本文中,我们提出了一种基于持续学习的广义 Benders 分解 GBD 的混合 MPC 求解器。该算法从子问题的不变对偶空间累积切割平面。经过短暂的冷启动阶段后,累积的削减为新问题实例提供热启动,以提高解决速度。尽管环境随机变化,控制没有做好准备,但求解速度仍保持不变。 |
| Enhanced Human-Robot Collaboration using Constrained Probabilistic Human-Motion Prediction Authors Aadi Kothari, Tony Tohme, Xiaotong Zhang, Kamal Youcef Toumi 人体运动预测是高效、安全的人机协作的重要步骤。当前的方法要么纯粹依赖于以某种形式的基于神经网络的架构来表示人体关节,要么使用离线回归模型来拟合超参数,以期捕获包含人体运动的模型。虽然这些方法提供了良好的初步结果,但它们错过了利用经过充分研究的人体运动学模型以及身体和场景约束,这些约束可以帮助提高这些预测框架的功效,同时也明确避免不可信的人体关节配置。我们提出了一种新颖的人体运动预测框架,该框架将人体关节约束和场景约束纳入高斯过程回归 GPR 模型中,以预测设定时间范围内的人体运动。该公式与在线上下文感知约束模型相结合,以利用任务相关的运动。它在人类手臂运动学模型上进行了测试,并在带有 UR5 机器人手臂的人类机器人协作设置上实施,以展示我们方法的实时能力。还对 HA4M 和 ANDY 等数据集进行了模拟。 |
| A Two-stage Based Social Preference Recognition in Multi-Agent Autonomous Driving System Authors Jintao Xue, Dongkun Zhang, Rong Xiong, Yue Wang, Eryun Liu 多智能体强化学习MARL已成为在复杂密集场景下构建多智能体自动驾驶系统MADS的有前景的解决方案。但大多数方法都认为代理人的行为是自私的,这会导致冲突行为。一些现有的工作结合了社会价值取向SVO的概念来促进协调,但它们缺乏对其他智能体SVO的了解,导致操作保守。在本文中,我们的目标是通过使智能体能够理解其他智能体 SVO 来解决上述问题。为了实现这一目标,我们提出了一个两阶段系统框架。首先,我们通过允许代理共享其真实 SVO 来建立协调的流量来训练策略。其次,我们开发了一个识别网络,用于估计智能体 SVO 并将其与第一阶段训练的策略相结合。 |
| ${\tt MORALS}$: Analysis of High-Dimensional Robot Controllers via Topological Tools in a Latent Space Authors Ewerton R. Vieira, Aravind Sivaramakrishnan, Sumanth Tangirala, Edgar Granados, Konstantin Mischaikow, Kostas E. Bekris 估计机器人系统控制器的吸引区域 tt RoA 对于安全应用和控制器组合至关重要。许多现有方法需要访问封闭式表达式,这限制了数据驱动控制器的适用性。仅在轨迹推出时运行的方法往往需要大量数据。在之前的工作中,我们已经证明基于莫尔斯图的拓扑工具可以提供数据高效的 tt RoA 估计,而无需分析模型。然而,当高维系统在状态空间的离散化上运行时,它们会遇到困难。本文介绍了莫尔斯图帮助发现它的区域对学习它的潜在它空间道德的吸引力。该方法将自动编码神经网络与莫尔斯图相结合。 tt MORALS 在估计吸引子及其 tt RoA 方面表现出了有前途的预测能力,适用于在高维系统上运行的数据驱动控制器,包括 67 度人形机器人和 96 度三指机械臂。它首先将受控系统的动态投射到学习的潜在空间中。然后,它构建了一种简化形式的莫尔斯图,表示基础动力学的双稳定性,即检测控制器何时导致期望的行为和不期望的行为。 |
| Roadmaps with Gaps over Controllers: Achieving Efficiency in Planning under Dynamics Authors Aravind Sivaramakrishnan, Noah R. Carver, Sumanth Tangirala, Kostas E. Bekris 本文旨在利用学习控制器来提高具有非平凡动力学的移动机器人运动规划的计算效率。它采用解耦策略,首先在空环境中对系统特定控制器进行离线训练,以处理系统的动态。对于一个环境,所提出的方法离线构建一个数据结构,一个带有差距的路线图,以近似学习如何使用学习的控制器来解决该环境中的规划查询。它的节点对应于局部区域,边缘对应于近似连接这些区域的学习控制策略的应用。由于控制器没有沿着边缘完美连接各个状态对,因此出现了间隙。在线,给定查询,基于树采样的运动规划器使用路线图,以便向目标区域通知树的扩展。树扩展选择局部子目标,给定路线图上引导目标的波前。当控制器无法到达子目标区域时,规划器采用随机探索来保持概率完整性和渐近最优性。 |
| Sim-to-Real Learning for Humanoid Box Loco-Manipulation Authors Jeremy Dao, Helei Duan, Alan Fern 在这项工作中,我们提出了一种基于学习的人形机器人箱形操纵方法。这是一个特别具有挑战性的问题,因为需要全身协调才能举起不同重量、位置和方向的箱子,同时保持平衡。为了应对这一挑战,我们提出了一种从模拟到真实的强化学习方法,用于训练双足机器人 Digit 的一般盒子拾取和搬运技能。我们的奖励函数旨在与盒子产生所需的交互,同时也重视平衡和步态质量。我们将学到的技能结合到一个完整的盒子机车操作系统中,以实现将具有各种尺寸、重量和初始配置的盒子从一张桌子移动到另一张桌子的任务。 |
| Multi-Domain Walking with Reduced-Order Models of Locomotion Authors Min Dai, Jaemin Lee, Aaron D. Ames 这项工作受到人类多域行走的启发,提出了一种基于降阶模型的新型框架,用于实现多域机器人行走。我们方法的核心是这样的观点:人类行走可以用混合动力系统来表示,具有完全驱动、欠驱动和过度驱动的连续阶段,以及随接触变化而发生的驱动类型的离散变化。利用这个视角,我们合成了多域线性倒立摆 MLIP 运动模型。利用 MLIP 模型的逐步动力学,我们成功地在双足机器人 Cassie(高自由度 3D 双足机器人)上演示了多域行走行为。因此,我们展示了弥合多域降阶模型和全阶多接触运动之间差距的能力。 |
| Optimization and Evaluation of Multi Robot Surface Inspection Through Particle Swarm Optimization Authors Darren Chiu, Radhika Nagpal, Bahar Haghighat 机器人群可以在空中、水生和地面环境中执行各种自动传感和检查应用。在本文中,我们研究了简化的两个结果表面检查任务。我们要求一组机器人根据投影在表面上的二进制图案来检查二维表面部分并对其进行集体分类。我们使用分散的贝叶斯决策算法,并部署一群微型 3 cm 大小的轮式机器人来检查 1m × 1m 的随机黑白瓷砖。我们首先描述表征我们的模拟环境、机器人群和检查算法的模型参数。然后,我们采用基于粒子群优化 PSO 的抗噪声启发式优化方案,使用结合了决策准确性和决策时间的适应度评估。我们使用健身测量定义,通过 100 次改变表面图案和初始机器人姿势的随机模拟来评估优化参数。 |
| Speech-Based Human-Exoskeleton Interaction for Lower Limb Motion Planning Authors Eddie Guo, Christopher Perlette, Mojtaba Sharifi, Lukas Grasse, Matthew Tata, Vivian K. Mushahwar, Mahdi Tavakoli 本研究提出了一种为下肢外骨骼开发的基于语音的运动规划策略 SBMP,以促进安全、合规的人机交互。语音处理系统、有限状态机和中央模式生成器是所提出的外骨骼轨迹在线规划策略的构建块。根据实验评估,该语音处理系统实现了较低水平的单词和意图错误。在移动方面,使用语音命令的用户完成时间比使用移动应用界面的用户快 54 倍。通过所提出的 SBMP,用户能够解放双手来保持姿势稳定性。 |
| Application-Oriented Co-Design of Motors and Motions for a 6DOF Robot Manipulator Authors Adrian Stein, Yebin Wang, Yusuke Sakamoto, Bingnan Wang, Huazhen Fang 这项工作研究了一个应用程序驱动的协同设计问题,其中六自由度机器人操纵器的运动和电机同时优化,并且该应用程序的特点是一组任务。与从产品目录中选择电机并针对单个任务进行协同设计的现有技术不同,这项工作针对特定应用设计电机几何形状和运动。为以计算有效的方式解决所提出的协同设计问题做出了贡献。首先,提出了一个两步过程,其中通过针对多个任务逐一优化运动和电机来确定多个电机设计,然后进行协调以确定最终的电机设计。其次,利用磁等效电路建模来建立从电机设计参数到动态模型和目标函数的解析映射,以方便后续的可微分仿真。第三,开发了基于直接搭配的电机和机械臂动力学的可微分模拟器,以平衡计算复杂性和数值稳定性。 |
| ContactGen: Generative Contact Modeling for Grasp Generation Authors Shaowei Liu, Yang Zhou, Jimei Yang, Saurabh Gupta, Shenlong Wang 本文提出了一种新颖的以对象为中心的接触表示 ContactGen,用于手部对象交互。 ContactGen 包括三个组件:接触图指示接触位置,部件图表示接触手部,方向图告诉每个部件内的接触方向。给定一个输入对象,我们提出了一个条件生成模型来预测 ContactGen 并采用基于模型的优化来预测多样化且几何上可行的抓取。实验结果表明,我们的方法可以为各种物体生成高保真度和多样化的人类抓握。 |
| Aligning Text-to-Image Diffusion Models with Reward Backpropagation Authors Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, Katerina Fragkiadaki 文本到图像扩散模型最近出现在图像生成的最前沿,由大规模无监督或弱监督文本到图像训练数据集提供支持。由于它们的训练不受监督,控制它们在下游任务中的行为(例如最大化人类感知图像质量、图像文本对齐或道德图像生成)是很困难的。最近的工作使用普通强化学习将扩散模型微调到下游奖励函数,该学习因梯度估计器的高方差而臭名昭著。在本文中,我们提出了 AlignProp,一种通过去噪过程使用奖励梯度的端到端反向传播将扩散模型与下游奖励函数对齐的方法。虽然这种反向传播的简单实现需要大量的内存资源来存储现代文本到图像模型的偏导数,但 AlignProp 微调低等级适配器权重模块并使用梯度检查点,以使其内存使用可行。我们测试 AlignProp,将扩散模型微调到各种目标,例如图像文本语义对齐、美观、存在对象数量及其组合的可压缩性和可控性。我们证明 AlignProp 比其他方案以更少的训练步骤获得了更高的奖励,同时概念上更简单,使其成为优化扩散模型以实现感兴趣的可微分奖励函数的直接选择。 |
| Probabilistic Generative Modeling for Procedural Roundabout Generation for Developing Countries Authors Zarif Ikram, Ling Pan, Dianbo Liu 由于资源有限和经济快速增长,以具有成本效益的方式通过交通模拟和验证来设计最佳交通道路网络对于发展中国家至关重要,因为在这些国家进行广泛的手动测试成本高昂且往往不可行。当前基于规则的道路设计生成器缺乏多样性,而多样性是设计稳健性的关键特征。生成流网络 GFlowNet 学习随机策略,从非标准化奖励分布中进行采样,从而生成高质量的解决方案,同时保留其多样性。在这项工作中,我们通过马尔可夫决策过程制定了将事件道路连接到环形交叉口的圆形交叉路口的问题,并利用 GFlowNets 作为交汇处艺术道路生成器。 |
| High-Degrees-of-Freedom Dynamic Neural Fields for Robot Self-Modeling and Motion Planning Authors Lennart Schulze, Hod Lipson 机器人自身模型是机器人物理形态的与任务无关的表示,可在缺乏经典几何运动学模型的情况下用于运动规划任务。特别是,当后者难以设计或机器人的运动学发生意外变化时,人类自由自我建模是真正自主代理的必要特征。在这项工作中,我们利用神经场来允许机器人将其运动学自我建模为仅从用相机姿势和配置注释的 2D 图像学习的神经隐式查询模型。与依赖于深度图像或几何知识的现有方法相比,这具有更大的适用性。为此,除了课程数据采样策略之外,我们还提出了一种新的基于编码器的神经密度场架构,用于以大量自由度为条件的动态对象为中心的场景。在 7 DOF 机器人测试设置中,学习的自我模型实现了机器人工作空间尺寸 2 的倒角 L2 距离。 |
| BID-NeRF: RGB-D image pose estimation with inverted Neural Radiance Fields Authors goston Istv n Csehi, Csaba M t J zsa 我们的目标是改进反向神经辐射场 iNeRF 算法,该算法将图像姿态估计问题定义为基于 NeRF 的迭代线性优化。 NeRF 是新颖的神经空间表示模型,可以合成现实世界场景或物体的逼真新颖视图。我们的贡献如下:我们使用基于深度的损失函数扩展了定位优化目标,我们引入了基于多图像的损失函数,其中使用具有已知相对姿势的图像序列而不增加计算复杂度,我们在体积渲染期间省略了分层采样,意味着仅使用粗略模型进行姿态估计,我们如何通过扩展采样间隔收敛来实现甚至或更高的初始姿态估计误差。 |
| 3D-Aware Hypothesis & Verification for Generalizable Relative Object Pose Estimation Authors Chen Zhao, Tong Zhang, Mathieu Salzmann 解决可概括的物体姿态估计问题的现有方法高度依赖于对未见物体的密集视图。相比之下,我们解决的是只有对象的单个参考视图可用的情况。我们的目标是估计该参考视图和以不同姿势描绘对象的查询图像之间的相对对象姿势。在这种情况下,由于测试期间存在看不见的对象以及参考和查询之间的大规模对象构成变化,因此鲁棒的泛化势在必行。为此,我们提出了一种新的假设和验证框架,在该框架中我们生成并评估多个姿势假设,最终选择最可靠的一个作为相对对象姿势。为了衡量可靠性,我们引入了 3D 感知验证,该验证将 3D 变换显式应用于从两个输入图像中学习到的 3D 对象表示。 |
| Safe Exploration in Reinforcement Learning: A Generalized Formulation and Algorithms Authors Akifumi Wachi, Wataru Hashimoto, Xun Shen, Kazumune Hashimoto 安全探索对于在许多现实场景中实际使用强化学习 RL 至关重要。在本文中,我们提出了一个广义安全勘探 GSE 问题,作为常见安全勘探问题的统一表述。然后,我们以安全探索元算法 MASE 的形式提出了 GSE 问题的解决方案,它将无约束的 RL 算法与不确定性量词相结合,以保证当前事件的安全性,同时在实际安全违规之前适当惩罚不安全的探索,以阻止他们在未来的剧集中。 MASE的优点是我们可以优化策略,同时保证在适当的假设下不会违反安全约束。具体来说,我们提出了 MASE 的两种变体,它们具有不同的不确定性量词结构,一种基于广义线性模型,具有安全性和接近最优性的理论保证,另一种结合了高斯过程以确保安全性和深度 RL 算法以最大化奖励。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com
这篇关于【AI视野·今日Robot 机器人论文速览 第四十九期】Fri, 6 Oct 2023的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









