本文主要是介绍使用 Sealos 将 ChatGLM3 接入 FastGPT,打造完全私有化 AI 客服,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FastGPT 是一款专为客服问答场景而定制的开箱即用的 AI 知识库问答系统。该系统具备可视化工作流功能,允许用户灵活地设计复杂的问答流程,几乎能满足各种客服需求。
在国内市场环境下,离线部署对于企业客户尤为重要。由于数据安全和隐私保护的考虑,企业通常不愿意将敏感数据上传到线上大型 AI 模型 (如 ChatGPT、Claude 等)。因此,离线部署成为一个刚需。
幸运的是,FastGPT 本身是开源的,除了可以使用其在线服务外,也允许用户进行私有化部署。相关的开源项目代码可以在 GitHub 上找到:https://github.com/labring/FastGPT
正好上周 ChatGLM 系列推出了其最新一代的开源模型——ChatGLM3-6B。该模型在保留前两代模型流畅对话和低部署门槛的优点基础上,带来了以下新特性:
更强大的基础模型:ChatGLM3-6B 的基础模型,名为 ChatGLM3-6B-Base,具有更丰富的训练数据、更合理的训练策略和更多的训练步数。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中优秀的性能。
更完善的功能:ChatGLM3-6B 引入了全新设计的 Prompt 格式,除了支持正常的多轮对话,还原生支持如工具调用 (Function Call)、代码执行 (Code Interpreter) 和 Agent 任务等复杂场景。
更全面的开源计划:除了 ChatGLM3-6B,该团队还开源了基础模型 ChatGLM-6B-Base 和长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在登记后亦允许免费商业使用。
本文接下来将详细介绍如何私有化部署 ChatGLM3-6B,并与 FastGPT 结合,构建一个完完全全私有化的 AI 知识库问答系统。
通过这样的整合,企业不仅可以保证数据安全,还能利用最新、最强大的 AI 技术来提升客服效率和用户体验。
原文链接:https://forum.laf.run/d/1085
One API 部署
FastGPT 可以通过接入 One API 来实现对各种大模型的支持,你可以参考 FastGPT 的文档来部署 One API。
FastGPT 部署
如果你不嫌麻烦,可以选择在本地使用 Docker Compose 来部署 FastGPT。
我推荐直接使用 Sealos 应用模板来一键部署,Sealos 无需服务器、无需域名,支持高并发 & 动态伸缩。打开以下链接即可一键部署 👇
https://cloud.sealos.top/?openapp=system-fastdeploy%3FtemplateName%3Dfastgpt
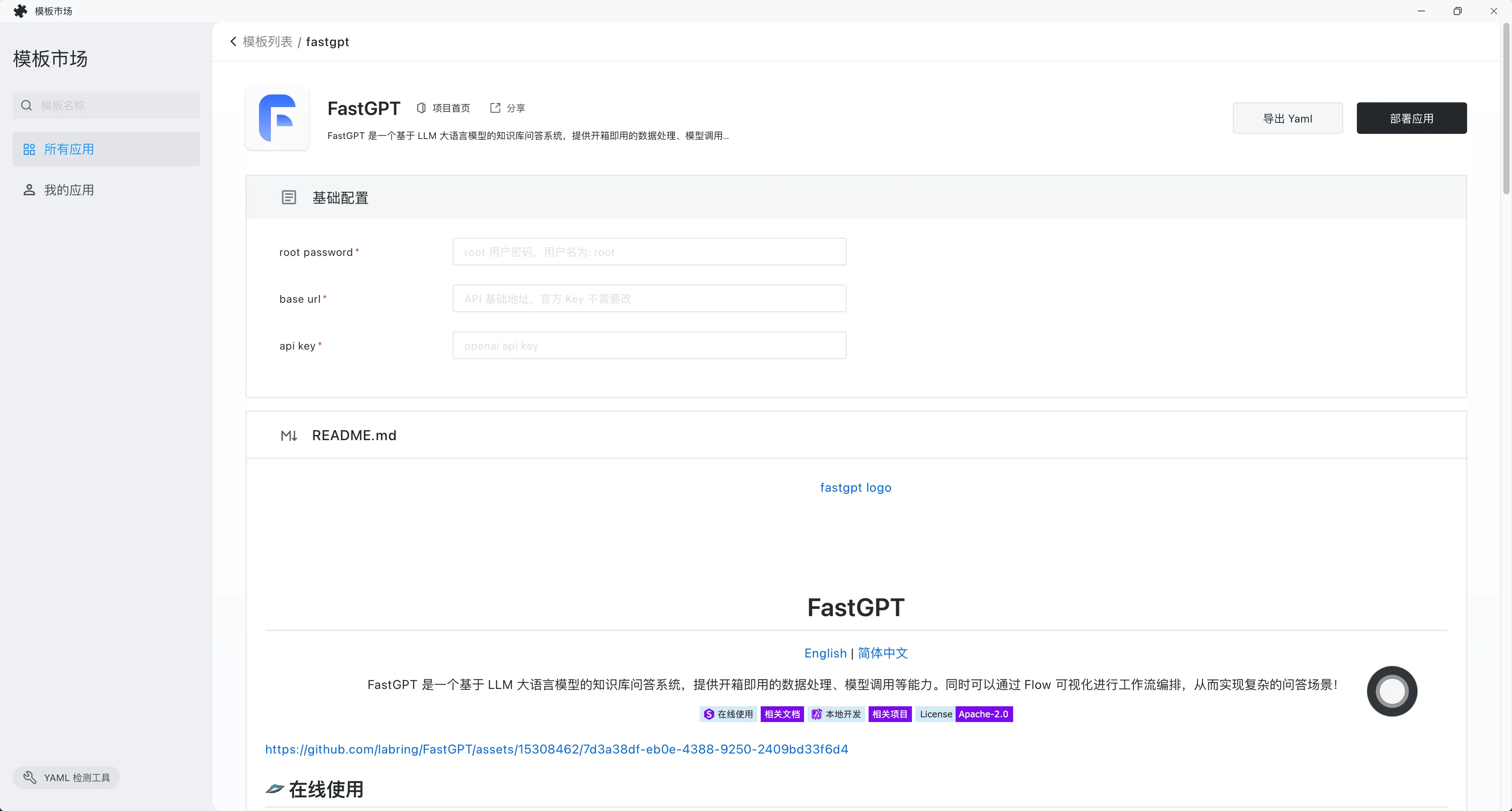
- root password 是默认的密码,默认用户名是 root。
- base url 填入 One API 提供的 API 接口。假设 One API 地址是 https://xxx.cloud.sealos.top,那么 base url 就是 https://xxx.cloud.sealos.top/v1。如果你的 One API 和 FastGPT 都部署在 Sealos 中,这里的 base url 可以填入 One API 的内网地址,例如我的内网地址是:http://one-api-wkskpejy.ns-sbjre322.svc.cluster.local:3000/v1
- api key 填入由 One API 提供的令牌。
填好参数之后,点击【部署应用】:
部署完成后,点击【确认】跳转到应用详情。

等待应用的状态变成 running 之后,点击外网地址即可通过外网域名直接打开 FastGPT 的 Web 界面。
我们暂时先不登录,先把 ChatGLM3-6B 模型部署好,然后再回来接入 FastGPT。
ChatGLM3-6B 部署
ChatGLM3 的项目地址为:https://github.com/THUDM/ChatGLM3
该项目 README 已经提供了在 GPU 环境中如何进行部署的详细步骤。但本文我们将专门讨论如何在没有 GPU 支持的情况下,仅使用 CPU 来运行 ChatGLM3。
首先登录 Sealos 国内版集群:https://cloud.sealos.top/
然后打开【应用管理】:
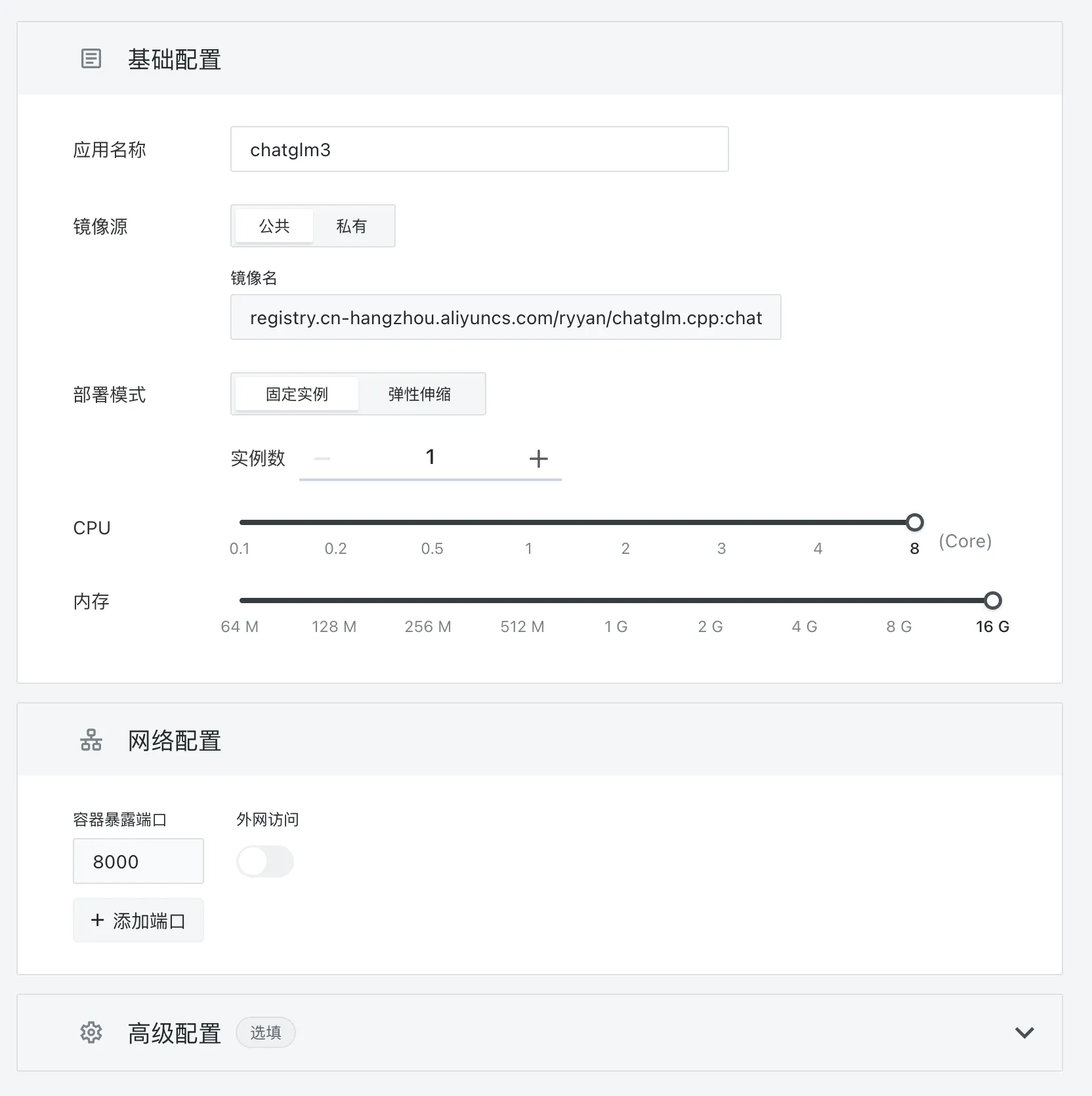
应用名称随便填,镜像名为:registry.cn-hangzhou.aliyuncs.com/ryyan/chatglm.cpp:chatglm3-q5_1
CPU 和内存拉到最大值,不然跑不起来。容器暴露端口设置为 8000。然后点击右上角的【部署】:
部署完成后,点击查看运行日志:
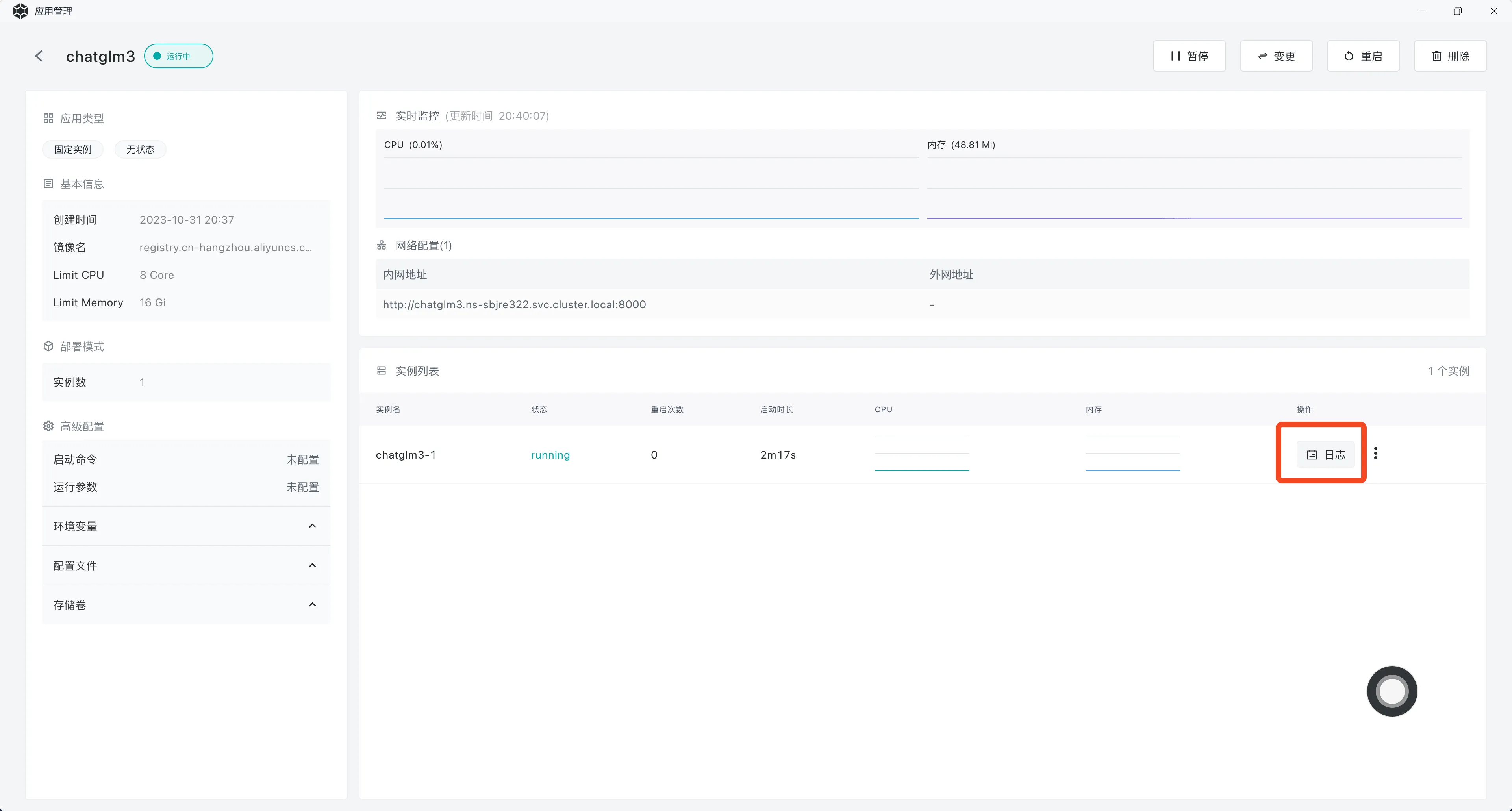
很好,三分钟解决战斗!
将 ChatGLM3-6B 接入 One API
打开 One API 的 Web 界面,添加新的渠道:
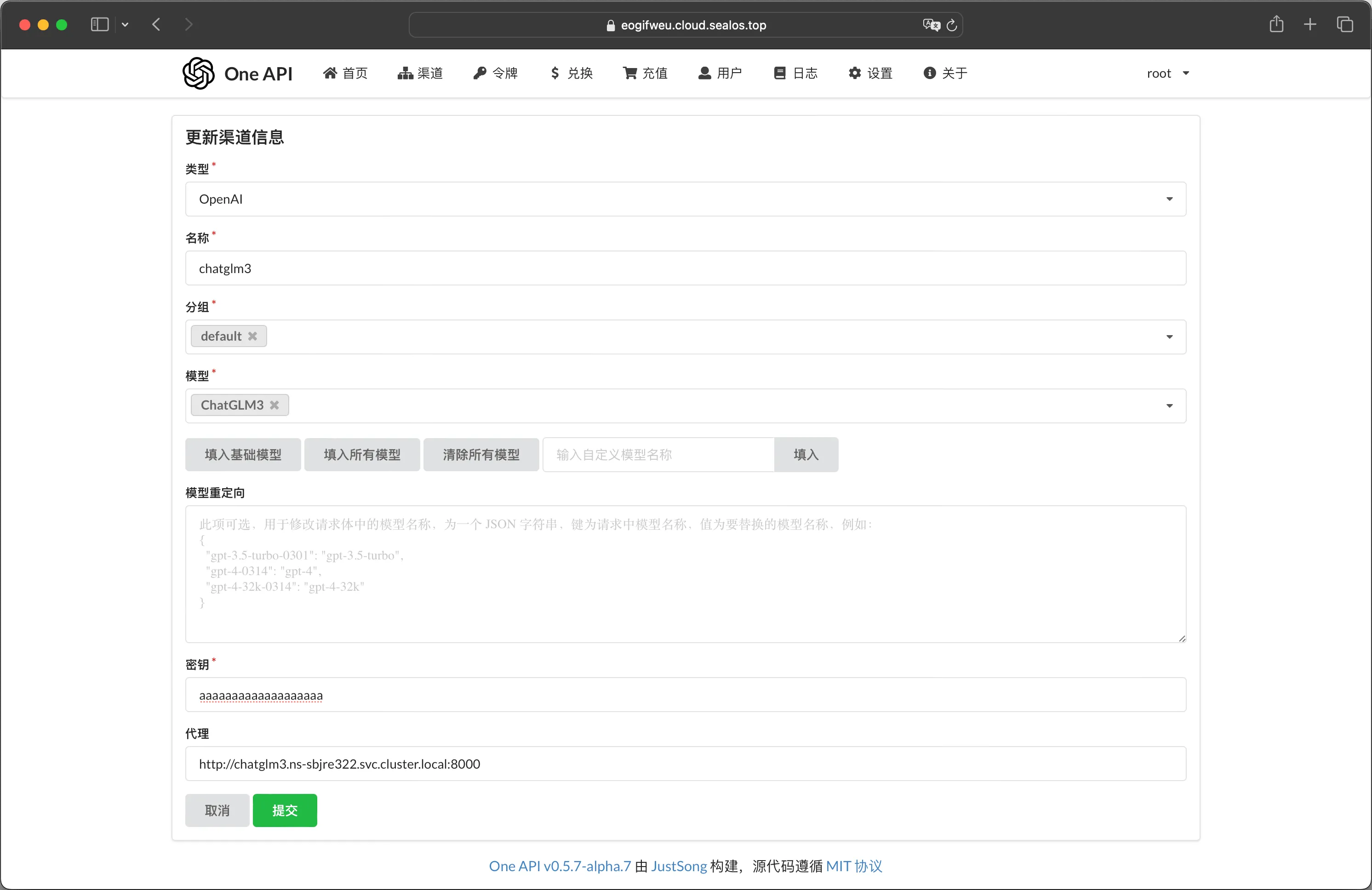
- 类型选择 OpenAI。
- 名称按自己的心意填。
- 模型名称可以通过自定义模型名称来设置,例如:ChatGLM3。
- 密钥随便填。
- 代理地址填入 ChatGLM3-6B 的 API 地址。如果你按照本教程把 One API 和 ChatGLM3-6B 全部部署在 Sealos 中,那就可以直接填 ChatGLM3-6B 的内网地址。
最后点击【提交】即可。
将 ChatGLM3-6B 接入 FastGPT
最后我们来修改 FastGPT 的配置,将 ChatGLM3-6B 接入 FastGPT。
首先在 FastGPT 的应用详情中点击【变更】:
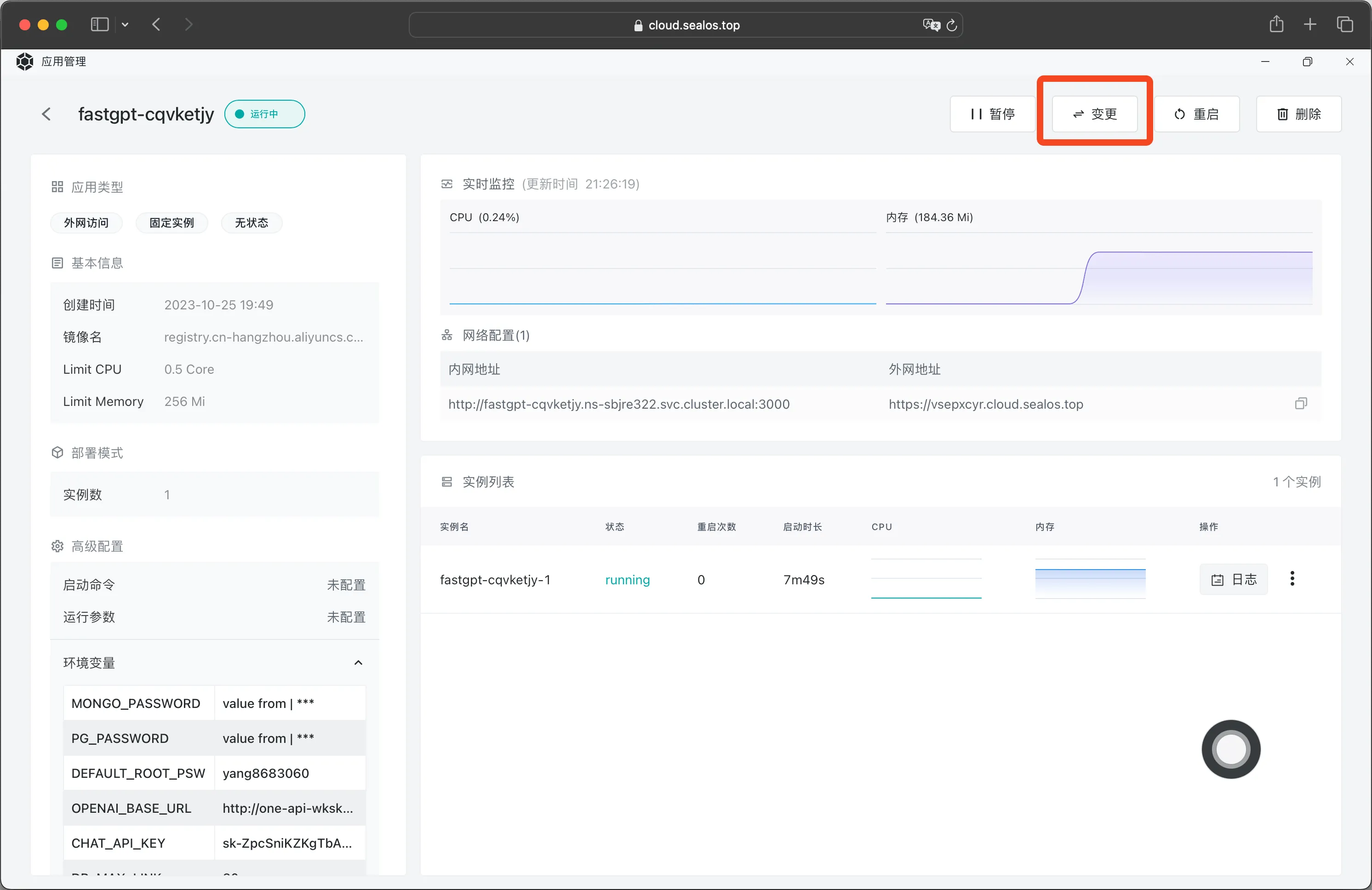
然后点击配置文件中的 /app/data/config.json:

将文件值修改为如下的值:
{"SystemParams": {"pluginBaseUrl": "","openapiPrefix": "openapi","vectorMaxProcess": 15,"qaMaxProcess": 15,"pgIvfflatProbe": 10},"ChatModels": [{"model": "ChatGLM3","name": "ChatGLM3","price": 0,"maxToken": 4000,"quoteMaxToken": 2000,"maxTemperature": 1.2,"censor": false,"defaultSystemChatPrompt": ""}],"QAModels": [{"model": "ChatGLM3","name": "ChatGLM3","maxToken": 8000,"price": 0}],"CQModels": [{"model": "ChatGLM3","name": "ChatGLM3","maxToken": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"ExtractModels": [{"model": "ChatGLM3","name": "ChatGLM3","maxToken": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"QGModels": [{"model": "ChatGLM3","name": "ChatGLM3","maxToken": 4000,"price": 0}],"VectorModels": [{"model": "text-embedding-ada-002","name": "Embedding-2","price": 0.2,"defaultToken": 700,"maxToken": 3000},{"model": "m3e","name": "M3E(测试使用)","price": 0.1,"defaultToken": 500,"maxToken": 1800}]
}修改完成后,点击【确认】,然后点击右上角的【变更】,等待 FastGPT 重启完成后,再次访问 FastGPT,点击【立即开始】进入登录界面,输入默认账号密码后进入 FastGPT 控制台:
新建一个应用,模板选择【简单的对话】,点击【确认创建】。

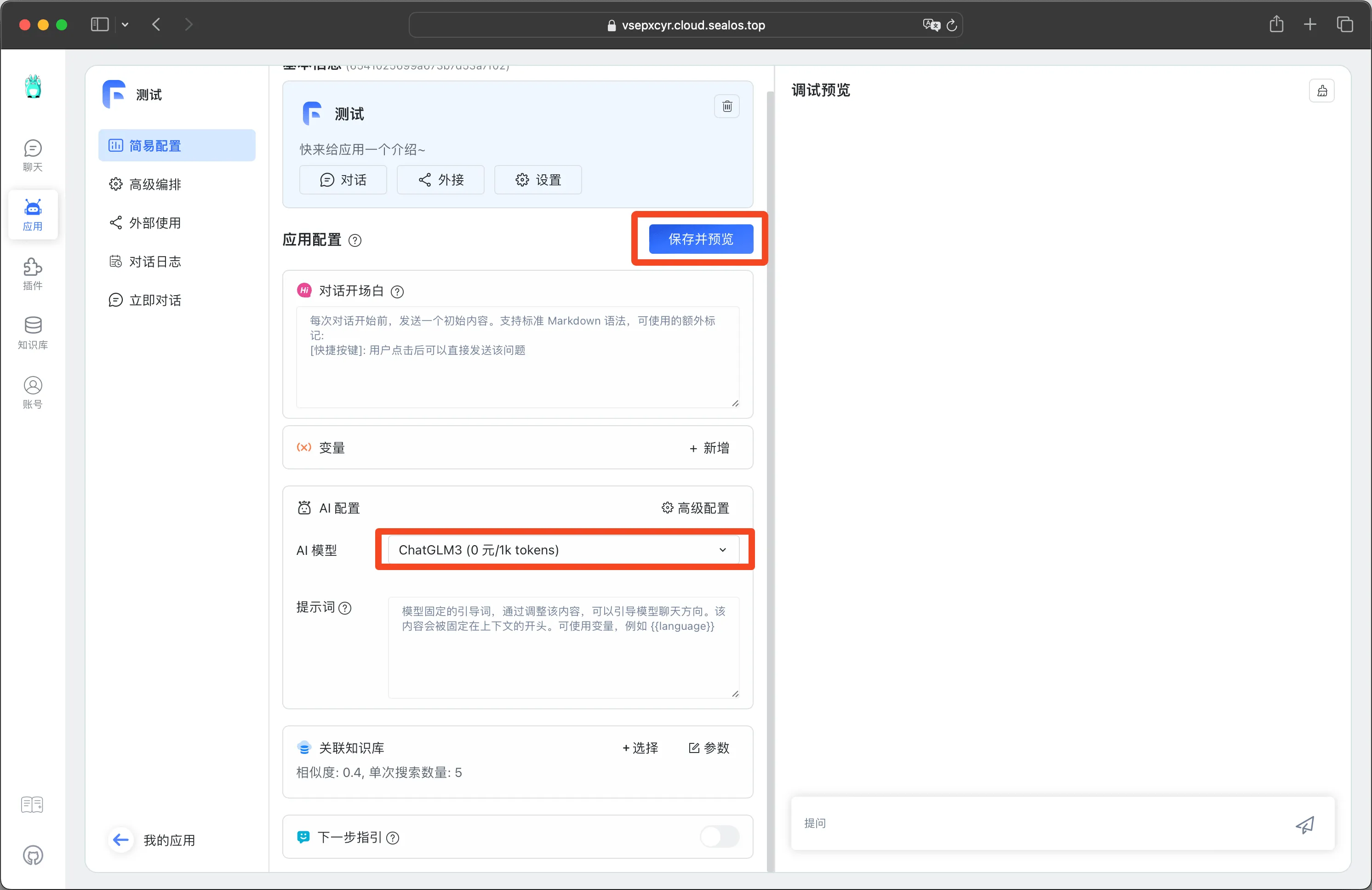
AI 模型选择 ChatGLM3,然后点击【保存并预览】。
点击左上角【对话】打开一个聊天会话窗口:
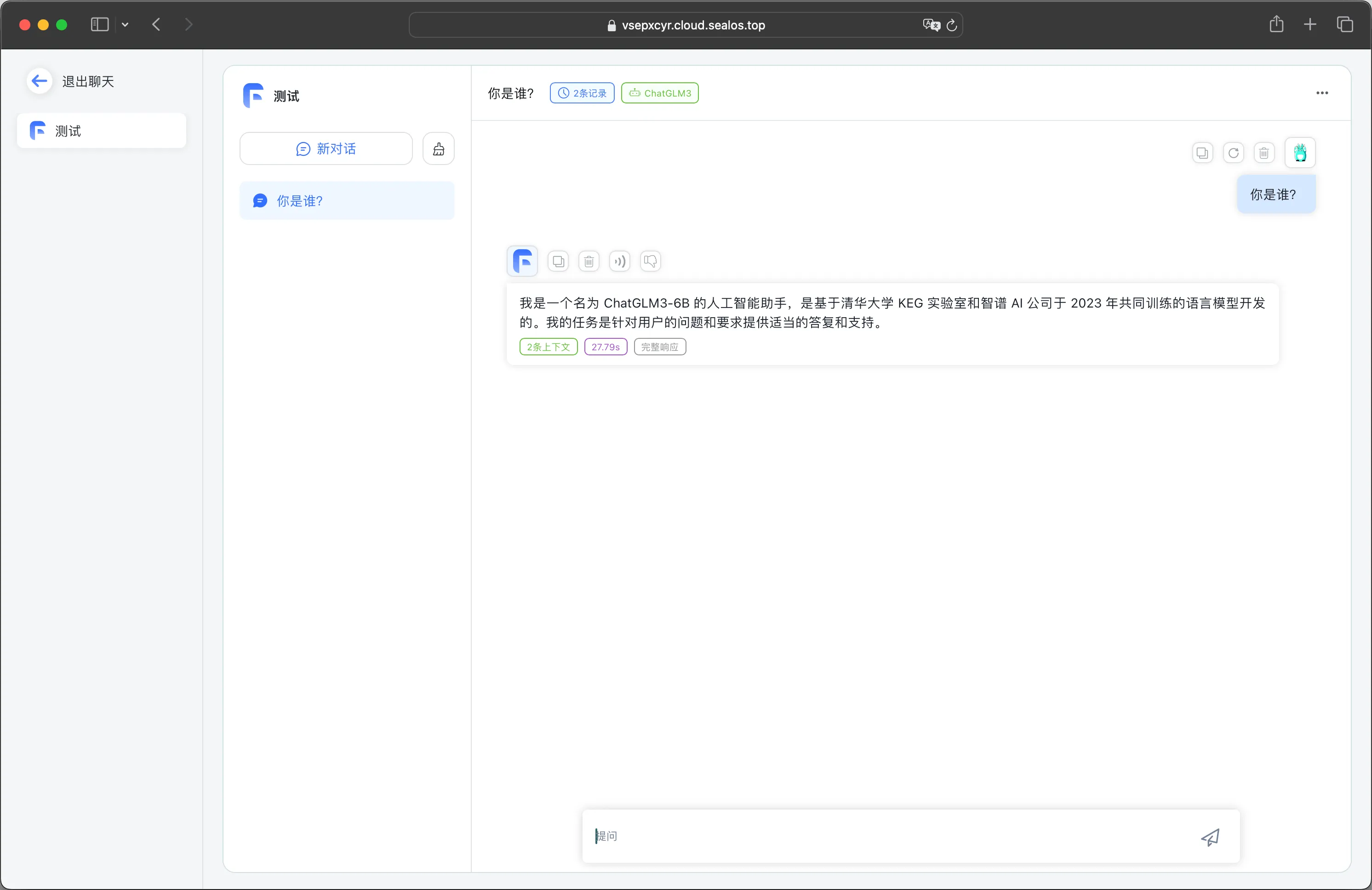
按国际惯例先来测试一下它的自我认知:
再来检测一下数学能力:
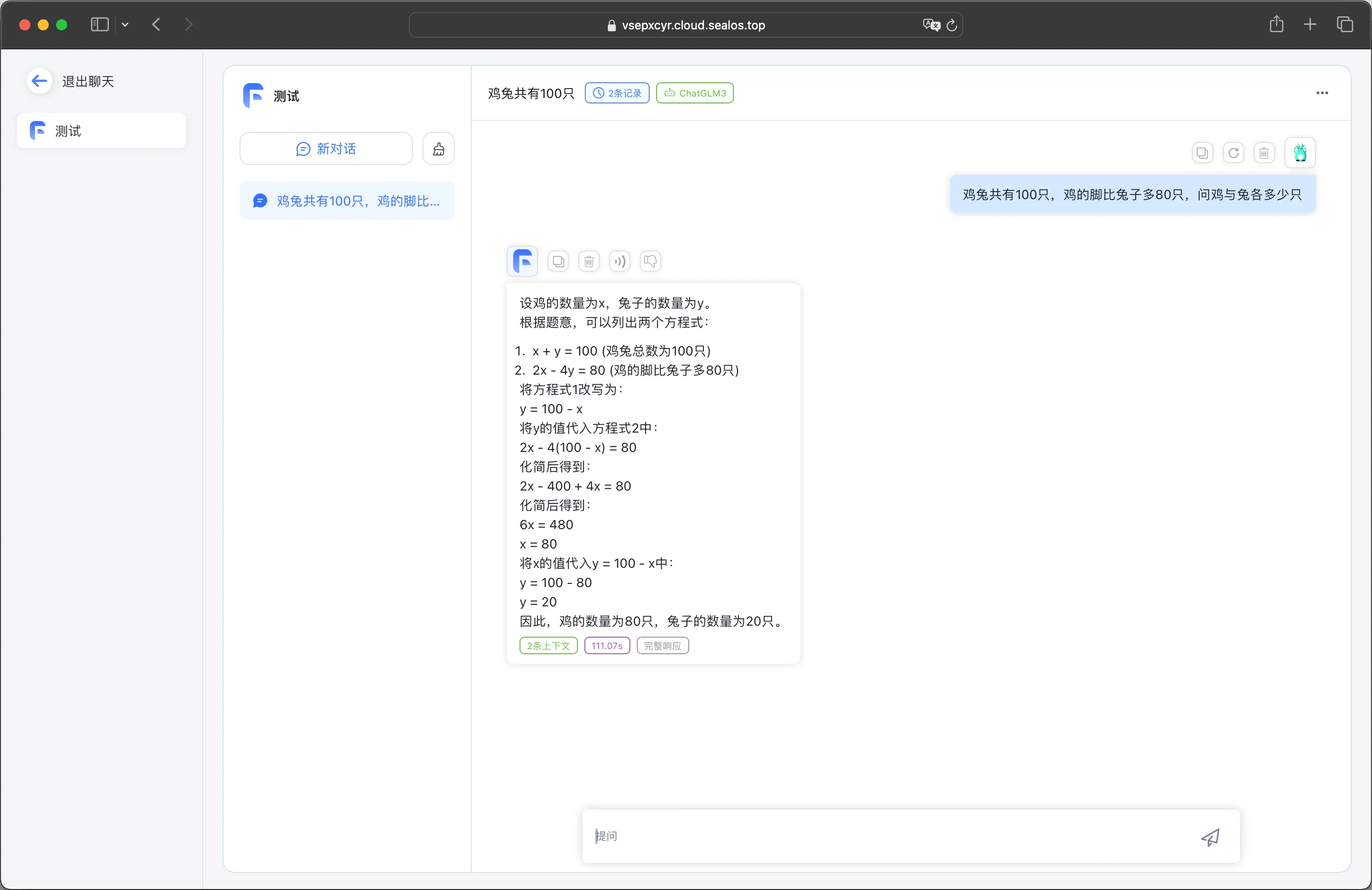
逻辑推理能力:
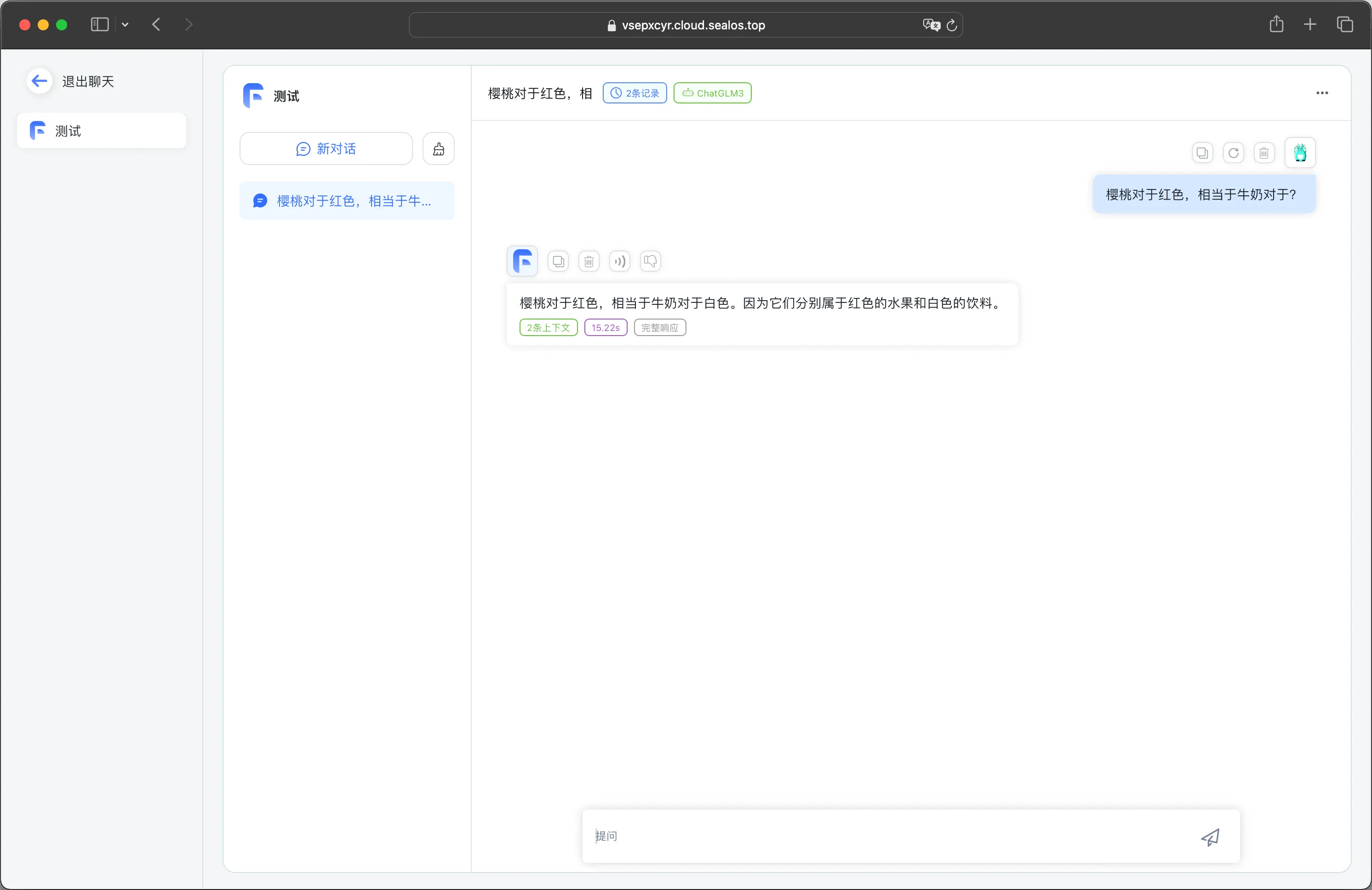
接入 M3E 向量模型
刚刚我们只是测试了模型的对话能力,如果我们想使用 FastGPT 来训练知识库,还需要一个向量模型。FastGPT 线上服务默认使用了 OpenAI 的 embedding 模型,如果你想私有部署的话,可以使用 M3E 向量模型进行替换。M3E 的部署方式可以参考文档:https://doc.fastgpt.in/docs/custom-models/m3e/
这篇关于使用 Sealos 将 ChatGLM3 接入 FastGPT,打造完全私有化 AI 客服的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






