本文主要是介绍论文阅读:SCL-WC: Cross-Slide Contrastive Learning for Weakly-Supervised Whole-Slide Image Classification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读:SCL-WC: Cross-Slide Contrastive Learning for Weakly-Supervised Whole-Slide Image Classification
- 论文信息
- 摘要
- 1 引言
- 2 相关工作
- 2.1 弱监督WSI分类
- 2.2 对比表示学习(Contrastive representation learning)
- 3 方法
- 3.1 弱监督WSI分类定义
- 3.2 特征编码
- 3.3 特定任务特征聚合(Task-specific feature aggregation)
- 4. 实验
- 4.1 在Camelyon16数据集上的结果
- 4.2 在BRACS, PANDA和DiagSet数据集上的结果
- 4.3 不同特征提取器和特征聚合器之间的比较
- 4.4 消融研究
- 5 总结
- 总结
论文信息
本篇论文来自NeurIPS 2022,讲述的是关于全视野数字切片的分类。
论文地址为:https://proceedings.neurips.cc/paper_files/paper/2022/hash/726204cea3ec27790a644e5b379175e3-Abstract-Conference.html
代码地址为:https://github.com/Xiyue-Wang/SCL-WC(至发文日期没有公开)

摘要
弱监督全视野数字切片图像 (WSI) 分类 (WSWC) 是一项具有挑战性的任务,其中每个 WSI (bag) 中存在大量未标记补丁(实例),而只给出Slide标签。尽管基于多实例学习 (MIL) 的 WSI 分析最近取得了进展,但主要限制是它通常侧重于易于区分的诊断阳性区域,而忽略了在整个 WSI 中占据较小比例的阳性。为了获得更具区分性的特征,我们提出了一种新的基于跨Slide对比学习(称为SCL-WC)的弱监督分类方法,该方法依赖于与任务无关的自监督特征提取和特定于任务的弱监督特征精化和聚合来进行WSI级别的预测。为了实现WSI内部和WSI间信息交互,我们分别提出了一种正负感知模块(PNM)和弱监督跨Slide对比学习(WSCL)模块。WSCL旨在将具有相同疾病类型的WSIs拉近,并将不同的WSIS推开。PNM旨在促进每个WSI中肿瘤样斑块和正常斑块的分离。大量实验表明,我们的方法在三个不同的分类任务中(例如,Camelyon16 中的 AUC 超过 2%,BRACS 中的 F1 分数为 5%,DiagSet 中的 AUC 为 3%)。我们的方法在弱监督定位和半监督分类实验中也显示出卓越的灵活性和可扩展性(例如,在 BRIGHT 挑战中排名第一)。我们的代码将在 https://github.com/Xiyue-Wang/SCL-WC 获得。(PS: 但是截止至发文日期,也没见到开源代码,只是建立了一个github库)。
1 引言
癌症诊断的黄金标准是通过检查病理切片得出的。随着扫描技术的进步,组织载玻片被扫描到全视野数字切片图像(WSIs)中,以便更好地管理和处理,促进了计算病理学的发展[1,2]。由于WSIs的千兆像素大小及其广泛的变化(如肿瘤类型和染色协议)[3,4],获取详尽的像素/补丁级注释非常耗时且昂贵。随着数据集大小的增加,这种足够的标签显然是不切实际的。在实践中,WSI 级别的弱注释在临床报告中更容易获得,这有助于弱监督 WSI 分类 (WSWC) 研究的出现。
现有的WSWC研究通常基于多实例学习(MIL)来制定,它将每个WSI定义为包,并从WSI中裁剪的补丁定义为单个实例[5;6;7;8;9;10;11;12;13;14]。值得注意的是,正包至少包含一个正实例,而负包包含所有负实例[15]。MIL范式的训练过程包括两个步骤:(i) 从 WSI 裁剪的补丁特征编码,以及 (ii) 同一 WSI 下的特征聚合。对于特征编码,最近的大多数方法都直接采用ImageNet预训练的骨干作为现成的特征提取器[8;9;10;11;12;14],一些研究采用自监督组织病理学预训练特征[13]。对于特征聚合,深度注意池[10;11;12;13]、图神经网络[14]和序列模型[5,8]用于有效的特征聚合。深度注意方法驱动每个补丁对最终WSI预测的重要性,生成可解释的结果。图神经网络和序列模型充分考虑了 WSI 内部上下文和长期依赖关系。
然而,这些方法仍然有两个限制。首先,以前的特征编码器要么以有监督的方式在域外图像上进行训练,要么以自监督的方式在有限的域内数据上进行预训练,由于难以捕获器官和疾病之间的足够可变性,无法扩展到组织病理学图像的大型数据集。因此,缺乏在大型和多样化的组织病理学图像上训练的通用特征提取器。其次,不幸的是,以前的特征聚合器无法探索WSI间可分离性,而忽略了跨训练WSIs的全局特征比较,导致WSIs的泛化能力有限,疾病阳性区域比例很小。
为了提高每个补丁的特征识别能力,我们提出了一种新的WSWC方法,称为SCL-WC,旨在实现WSI内局部补丁分离和WSI间全局特征对比。具体来说,我们首先应用MoCo v3框架[16]来预训练Swin Transformer[17],然后将其作为所有补丁的离线特征编码器,这为缓解过拟合问题提供了适当的初始化。然后,我们设计了一种新的聚合算法,该算法包含三个模块,即特定于类的深度注意(CDA)、正负感知建模(PNM)和弱监督跨幻灯片对比学习(WSCL)。CDA遵循之前的深度注意范式为每个补丁分配一个可学习的权重,以表明它对WSI预测的贡献。PNM显式地对WSIs中正负斑块的外观进行建模,以捕获鉴别特征表示,促进正常/异常组织分离。WSCL 在 WSI 之间构建了不同的特征比较来细化特定于任务的特征,其中 WSI 级别的监督为对比学习设置中的每个类提供了更可靠的分离能力,有助于捕获信息特征。
我们的 贡献 总结如下。(i) 开创性地提出了一种新颖的 WSCL 模块,用于跨 WSI 的全局特征对比,这有助于提取更多可区分的特征,以促进类间可分离性和类内紧凑性。(ii) PNM 旨在明确地将每个 WSI 特征空间拆分为正负子空间,从而帮助排除无信息的补丁。(iii) 与其他 WSWC 方法相比,我们提出的 SCL-WC 实现了显着的性能提升。通过可行将其扩展到半监督分类任务,我们的方法在 BRIGHT 挑战中获得了第一名。
2 相关工作
2.1 弱监督WSI分类
WSWC 任务旨在选择具有代表性的补丁来触发相应的 WSI 级标签。目前,MIL 已被应用于以显着成功制定这个问题 [5;6;7;8;9;10;11;12;13;14],这需要两个关键技术:用于表示WSI 的补丁级特征编码(patch-level feature encoding)和特征聚合。
这些特征编码器可以分为在线和离线模型,其中在线网络模型需要实时更新[5;6;7],与经过良好训练的离线模型相比,导致需要更多的训练周期来收敛。使用的离线特征提取器包括有监督的ImageNet-Well-pretrained[8;9;10;11;12;14]和无监督的组织病理学图像预训练模型[13]。然而,自然图像(域外数据)很难在没有任何微调的情况下准确地捕捉组织病理学图像的纹理和形态特征。使用的自监督模型在少量未标记样本上进行预训练,导致特征表示有限。
利用特征聚合的算法可分为部分实例贡献(partial-instance-contributed)和全实例贡献(full-instance-contributed)两种方法。部分实例贡献的方法通过从组织区域[7]中随机抽样来保持每个WSI中固定数量的补丁,选择置信度分数较高的top-k补丁[5],或者从每个补丁级集群中选择一个子集[6;9]。一小部分补丁可能无法完全捕获每个WSI的形态特征,导致误诊和漏诊。全实例贡献的方法采用深度注意池[10;11;12;13]、图神经网络[14]和序列模型[5,8]来整合WSI中的所有补丁,其中补丁可以通过网络训练分配适当的权重参数来驱动WSI级表示。这些方法考虑了所有补丁的贡献,比以前的有限代表性补丁更灵活和适应其他任务。
2.2 对比表示学习(Contrastive representation learning)
对比表示学习旨在通过将属于同一类的样本拉在一起并将属于不同类别的样本推开来学习通用特征。最流行的无监督对比学习方法是SimCLR[18;19]和MoCo[20;21;16],它将来自同一图像的数据增强作为阳性,将来自不同图像的数据增强作为阴性。在后来的监督对比学习中,数据注释有助于制定正确的对比对,从而产生更具代表性的特征[22]。基于之前的研究,本项工作在 MIL 设置中提出了一个 WSCL 模块,旨在在特定任务中提取特定于类的可区分特征。
3 方法
3.1 弱监督WSI分类定义
假设我们有一系列训练WSIs { s n } n = 1 N \left \{ s_n\right \}_{n=1}^{N} {sn}n=1N及其对应的WSI级标签 { y n } n = 1 N \left \{ y_n\right \}_{n=1}^{N} {yn}n=1N,其中 y n ∈ { 0 , 1 , ⋅ ⋅ ⋅ , C } y_n∈\left \{0,1,···,C\right \} yn∈{0,1,⋅⋅⋅,C}表示第 n t h n^{th} nth个WSI的标签,C表示类的数量(如癌症亚型),0对应正常(负)组织。第 n t h n^{th} nth个WSI可以表示为 s n = { P n , l } l = 1 L n s_n = \left \{P_{n,l}\right \}_{l=1}^{L_n} sn={Pn,l}l=1Ln,其中 P n , l P_{n,l} Pn,l是滑动窗口从WSI中裁剪的第 l t h l^{th} lth个补丁, L n L_n Ln表示WSI内的补丁数量,这可能因不同图像大小的WSI而异。值得注意的是,只有WSI级别的标签存在,内部补丁的标签不明确。WSWC 任务旨在训练一个弱标签的模型来进行WSI级别的预测。我们提出的SCL-WC方法的概述如图1所示,主要包括特征编码过程和特定于任务的特征聚合。
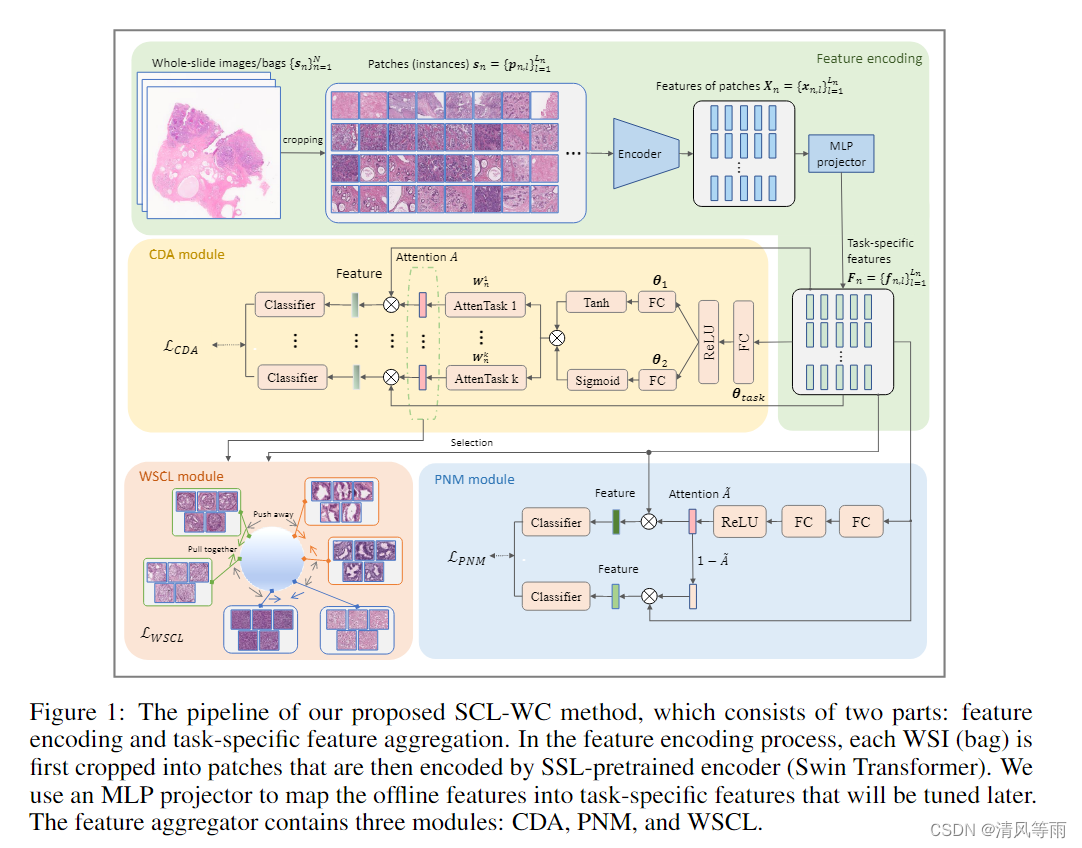
3.2 特征编码
自监督学习(Self-supervised learning,SSL)能够在数据本身的监督下训练通用特征编码器,已广泛应用于计算机视觉和医学图像分析[18;20;23;24]。得益于其显著的成功,本项工作将MoCo v3框架[20;16]对来自TCGA[25]和PAIP[26]数据集的1500万个未标记补丁(没有标签)上预训练特征编码器(Swin-Transformer[17])。然后,将经过良好预训练的主干作为离线特征提取器,将补丁转换为一系列 q 维向量。例如,第 n t h n^{th} nth 个幻灯片的特征向量可以表示为 X n = { x n , l } l = 1 L n X_n = \left \{x_{n,l}\right \}_{l=1}^{L_n} Xn={xn,l}l=1Ln,其中 X n , l ∈ R q X_{n,l} \in R^q Xn,l∈Rq 表示第 l t h l^{th} lth 个补丁的向量, X n ∈ R L n × q X_n \in R^{L_n×q} Xn∈RLn×q是通过堆叠 WSI 中的所有补丁来获得的。由于这些预训练的特征与任务无关,我们使用全连接层和非线性激活函数将它们映射到特定的任务的空间。因此,第 n t h n^{th} nth个幻灯片中的任务特定特征可以表示为 F n = { f n , l } l = 1 L n = R E L U ( F C ( X n , θ t a s k ) ) F_n = \left \{f_{n,l}\right \}_{l=1}^{L_n}=RELU(FC(X_n, \theta_{task})) Fn={fn,l}l=1Ln=RELU(FC(Xn,θtask)),其中 F n ∈ R L n × d F_n \in R^{L_n \times d} Fn∈RLn×d, θ t a s k \theta_{task} θtask 是全连接层中的可训练参数。
3.3 特定任务特征聚合(Task-specific feature aggregation)
我们的特定任务特征聚合器由三个模块组成:CDA、PNM和WSCL。CDA旨在参数化每个补丁对最终WSI预测的贡献,帮助提供可解释的结果。PNM由阳性感知损失和阴性感知损失组成,旨在减轻每个WSI中大量阳性(阴性)子区域所引起的噪声。WSCL考虑全局图像信息,将阳性的包拉得更近,将阴性的包推得更远。这三个模块的组合使特征聚合器能够探索WSI内部和之间的互补信息,帮助调整特定任务的特征层,以获得更具判别性的补丁级表示,并进一步提高弱监督分类和定位性能。
特定类的深度关注(Class-specific deep attention)。CDA模块作为一个主要分支,使用基于深度注意力的MIL池[15]将这些补丁级特征 F n = { F n , l } l = 1 L n F_n = \left \{F_{n,l}\right \}_{l=1}^{L_n} Fn={Fn,l}l=1Ln聚合成幻灯片级向量 F n ~ \tilde{F_n} Fn~, 该池为WSI中的每个补丁分配权重,以指定其对最终WSI预测的相对贡献。这种深度注意机制由几个全连接层实现。我们用 A n i , l A_n^{i,l} Ani,l表示第 i t h i^{th} ith类在第 n t h n^{th} nth张幻灯片中第 l t h l^{th} lth个patch的权重分数,计算为 A n i , l = e x p { W n i ( t a n h ( θ 1 f n , l T ) ⊙ s i g m ( θ 2 f n , l T ) ) } ∑ j = 1 L n e x p { W n i ( t a n h ( θ 1 f n , l T ) ⊙ s i g m ( θ 2 f n , l T ) ) } A_n^{i,l}=\frac{exp \left \{W_{n}^{i}(tanh(\theta_1f_{n,l}^T) \odot sigm(\theta_2f_{n,l}^T)) \right \}}{\sum_{j=1}^{L_n}exp \left \{W_{n}^{i}(tanh(\theta_1f_{n,l}^T) \odot sigm(\theta_2f_{n,l}^T)) \right \}} Ani,l=∑j=1Lnexp{Wni(tanh(θ1fn,lT)⊙sigm(θ2fn,lT))}exp{Wni(tanh(θ1fn,lT)⊙sigm(θ2fn,lT))}其中 θ 1 ∈ R M × d \theta_1 \in R^{M ×d} θ1∈RM×d, θ 2 ∈ R M × d \theta_2 \in R^{M ×d} θ2∈RM×d, W n i ∈ R 1 × M W_n^i \in R^{1×M} Wni∈R1×M, ⊙ \odot ⊙表示逐元素乘法。注意力分数 A n i , l A_n^{i,l} Ani,l 范围从 0 到 1,每个WSI中每个类的最终注意力矩阵被归一化,使得这些权重的总和为 1,即 ∑ l = 1 L n A n i , l = 1 \sum_{l=1}^{L_n} A_n^{i,l}=1 ∑l=1LnAni,l=1。第 n t h n^{th} nth个slide的注意矩阵计算为 A n ∈ R L n × C A_n \in R^{L_n×C} An∈RLn×C。然后,第i个类的加权slide级特征可以表示为 F n i ∈ R d ~ \tilde{F_n^i \in R^d} Fni∈Rd~,其计算公式为 F n i ~ = ∑ l = 1 L n A n i , l f n , l , \tilde{F_n^i}=\sum_{l=1}^{L_n} A_n^{i,l}f_{n,l}, Fni~=l=1∑LnAni,lfn,l,接下来,这些特征被送到第 i t h i^{th} ith个分类器中,以驱动对这个类的预测概率。然后,对每个类应用 softmax 来归一化概率分布。我们使用 p n i p_n^i pni来表示WSI属于第i个类别的概率, y n i y_n^i yni表示 one-hot 形式的第 n 个WSI的真实标签。它们用于计算在B中的最小批尺寸大小(min-batch size)中基于MIL 的WSI分类损失 L m i l \mathcal{L_{mil}} Lmil,如下所示 L m i l = − 1 B ∑ n = 1 B ∑ i = 0 C y n i l o g ( p n i ) , \mathcal{L_{mil}}=-\frac{1}{B}\sum_{n=1}^{B}\sum_{i=0}^{C}y_n^ilog(p_n^i), Lmil=−B1n=1∑Bi=0∑Cynilog(pni),除了 L m i l \mathcal{L_{mil}} Lmil,我们还考虑了添加一个辅助实例判别损失来进一步增强特定类的特征。由于补丁级别的标签不可用,我们为这些高注意力补丁(即 top-k 注意力分数)生成标签为1的伪标签,并为这些低注意力补丁(即底部 k 注意力分数)生成 0,通过对对应于 WSI 的真实类别的 A n A_n An指定列中的注意力分数进行排序,其中包含总共 2k 个样本用于分类任务,使用一个用了二元交叉熵损失的线性分类器,如下所示。 L i n s = − 1 2 k ∑ j = 1 2 k ( y j l o g ( p j ) − ( 1 − y j ) l o g ( 1 − p j ) ) , \mathcal{L_{ins}=-\frac{1}{2k}\sum_{j=1}^{2k}(y_j log(p_j)-(1-y_j)log(1-p_j))}, Lins=−2k1j=1∑2k(yjlog(pj)−(1−yj)log(1−pj)),其中 y j y_j yj 和 p j p_j pj 分别表示第 j 个实例的伪标签和预测概率。最终的基于 CDA 的损失 L C D A \mathcal{L_{CDA}} LCDA的总和如下: L C D A = λ 1 L m i l + λ 2 L i n s \mathcal{L_{CDA}}= λ_1\mathcal{L_{mil}} + λ_2\mathcal{L_{ins}} LCDA=λ1Lmil+λ2Lins。
正负感知建模(Positive-negative-aware modeling)。我们提出了一个 PNM 模块来考虑阳性WSI 中大量正常(阴性)组织的存在,这些组织应尽可能与异常(阳性)区域分开。为此,我们将阳性WSI的特征空间分为阳性子空间和阴性子空间,以实现可区分的特征学习。具体来说,我们首先通过两个全连接层计算第 l t h l^{th} lth个补丁与WSI级预测的类不相关权重分数 A n l ~ \tilde{A_n^l} Anl~来表示他们的相关性,即 A n l ~ = s i g m ( θ 4 ( R e L U ( θ 3 f n , l T ) ) ) \tilde{A_n^l}=sigm(\theta_4(ReLU(\theta_3f_{n,l}^T))) Anl~=sigm(θ4(ReLU(θ3fn,lT)))。然后我们使用 1 − A ~ n l 1-\tilde{A}_n^l 1−A~nl对专注于阴性子区域的WSI级特征进行加权。这些新的加权WSI特征由下式计算 A ‾ n p o s = 1 L n ∑ l = 1 L n A n l ~ f n , l , A ‾ n n e g = 1 L n ∑ l = 1 L n ( 1 − A n l ~ ) f n , l , \overline{A}_n^{pos}=\frac{1}{L_n}\sum_{l=1}^{L_n}\tilde{A_n^l}f_{n,l}, \overline{A}_n^{neg}=\frac{1}{L_n}\sum_{l=1}^{L_n}(1 - \tilde{A_n^l})f_{n,l}, Anpos=Ln1l=1∑LnAnl~fn,l,Anneg=Ln1l=1∑Ln(1−Anl~)fn,l,其中, A ‾ n p o s \overline{A}_n^{pos} Anpos和 A ‾ n n e g \overline{A}_n^{neg} Anneg分别为阳性、阴性样本预测的加权滑动水平特征。 A n l ~ \tilde{A_n^l} Anl~为WSI内第n个patch的权重得分,取值范围为0 ~ 1。然后用softmax函数将 A ‾ n p o s \overline{A}_n^{pos} Anpos和 A ‾ n n e g \overline{A}_n^{neg} Anneg送到全连接层中,得到阳性 P n p o s P_n^{pos} Pnpos和消极 P n n e g P_n^{neg} Pnneg特征的slide级预测概率。则基于PNM的分类损失可计算为 L P N M = − 1 B ∑ n = 1 B ( l o g P n p o s − l o g P n n e g ) , \mathcal{L_{PNM}}= -\frac{1}{B}\sum_{n=1}^{B}(logP_n^{pos}-logP_n^{neg}), LPNM=−B1n=1∑B(logPnpos−logPnneg),其中, L P N M \mathcal{L_{PNM}} LPNM是两个交叉熵损失函数的总和:正感知分类损失和负感知分类损失。
弱监督交互slide对比学习(Weakly-supervised cross-slide contrastive learning)。以往用于组织病理图像的对比学习方法采用patch作为正/负单位[13],忽略了slides之间的信息交互,只捕获局部特征表示。与它们不同的是,我们提出了一个WSCL,旨在通过比较slides之间的特征表示来生成更具区别性的特定于类的特征,即将属于同一类的幻灯片拉得更近,而将属于不同类的幻灯片推得更远。由于每个WSI内部存在巨大的异质性,直接比较WSI容易受到噪声的干扰,反而不利于网络训练。因此,我们根据上述获得的类别特定关注,通过在每个WSI中选择最具代表性的补丁来构建一系列新的包。具体来说,我们使用三种类型的子记忆库分别存储阳性、阴性和硬阳性包。我们将每个阳性WSI内的前k个补丁放入阳性袋中。同样,分别将每个阴性WSI内的前k个和后k个补丁分别插入硬阴性和阴性包中。需要注意的是,属于不同阳性类别的样品应存放在单独的阳性包中。基于上述定义,我们基于wscl的损失可以定义为 L W S C L = ∑ Z i ∈ B − 1 k × ∣ P ∣ ∑ P r ∈ P ∑ z j ∈ P r l o g e x p ( z i ⋅ z j / τ ) ∑ a ∈ Q e x p ( z i ⋅ z a / τ ) , \mathcal{L_{WSCL}}=\sum_{Z_i \in B}\frac{-1}{k \times \left | P\right |}\sum_{P_r \in P}\sum_{z_j \in P_r}log\frac{exp(z_i\cdot z_j/\tau)}{\sum_{a\in Q}exp(z_i\cdot z_a/\tau)}, LWSCL=Zi∈B∑k×∣P∣−1Pr∈P∑zj∈Pr∑log∑a∈Qexp(zi⋅za/τ)exp(zi⋅zj/τ),其中B为一个锚包(anchor bag), z i ( z i ∈ B ) z_i (z_i \in B) zi(zi∈B)是来自锚包的第i个锚补丁。对于锚包,P、N 和 H 用于表示其对应的阳性包、阴性包和硬阴性包集合,|P|、|N| 和 |H|分别用于表示它们对应的包的数量数。 p r p_r pr 用于表示阳性集P中的第r个包。 Q = P ∪ N ∪ H Q = P \cup N \cup H Q=P∪N∪H表示WSCL计算过程中使用的总包。
最终的损失函数是基于CDA的损失、基于PNM的损失和基于WSCL的损失的总和,计算为 L t o t a l = L C D A + β L P N M + γ L W S C L \mathcal{L_{total}} = \mathcal{L_{CDA} }+\beta\mathcal{L_{PNM}} +\gamma\mathcal{L_{WSCL}} Ltotal=LCDA+βLPNM+γLWSCL,其中 β \beta β和 γ \gamma γ是用于调整每个损失贡献的超参数。
4. 实验
在本节中,我们在五个公共组织病理学图像数据集上构建了一系列实验。这五个数据集是从三个不同的器官收集的,包括前列腺(PANDA[27]和DiagSet[28])、乳房(Camelyon16[29]和BRACS[30])和结肠直肠(TCGA-CRC-DX),详见表1。

数据集. Camelyon16 发布用于转移性乳腺癌检测,其中包含 240 个具有转移的 WSI 和 159 个正常 WSI。这些WSIS被分成包含270个WSI的训练集和一个包含129个WSI的测试集。尽管数据集中的像素级注释可用,但它们仅用于评估我们的弱监督定位性能。
BRACS 是发布在BRIGHT挑战中,用于对乳腺肿瘤亚型进行分类的数据集。我们遵循 这个挑战的WSI 3分类:正常(Non. 288个WSI),癌前(Pre. 155个WSI)和癌症(Can. 260个WSI)。挑战组织者将 703 个 WSI 的总数拆分为 包含423个WSI的训练集、包含80个WSI的测试集和包含200个WSI的测试集。值得注意的是,他们还提供了一些注释良好的补丁(3566个)用于训练,这在我们的 WSWC 任务中被忽略了,并在参与挑战时用于半监督分类的训练过程。
PANDA 是前列腺癌分类(2分类)的最大公开可用的WSI数据,总共发布了 10,616 个 WSI(7724个Can. 和2892 Non. )。我们以7:1:2的比例将它们分成训练集、验证集和测试集。
DiagSet包含三个用于前列腺癌2分类的组织病理学图像子集:DiagSet-A、DiagSet-B 和 DiagSet-C。这些子集被用作三个外部测试集,以证明模型对看不见的数据的泛化能力。DiagSet-A、DiagSet-B 和 DiagSet-C 分别包含 430 个 WSI(Can.有228个WSI,Non.有202 个 WSI)、4675 个 WSI(Can.有2090 个,Non.有2585 个 WSI),以及 46 个 WSI(Can.有37 个 WSI,Non.有9 个 WSI)。
TCGA-CRC-DX(癌症基因组图谱结肠癌和直肠癌)[31]用于测试我们的SCL-WC方法在微卫星(microsatellite)不稳定性预测方面的性能,总共包含 428 个 WSI(62 个具有微卫星不稳定性的 WSI 和具有微卫星稳定性的 366 个WSI)。数据拆分过程与原始参考 [31] 保持一致,即基于公开发布的拆分表的 4 折交叉验证。
评估指标。为了与以前的方法进行公平比较,我们采用准确度 (ACC)、曲线下面积 (AUC) 和 F1 分数作为指标来评估我们的弱监督分类性能的指标。遵循Camelyon16挑战,使用自由响应操作特征曲线(FROC)来评估肿瘤定位性能[29]。实验设置可以在补充材料中找到。
4.1 在Camelyon16数据集上的结果
本小节通过将 Camelyon16 数据集上的弱监督分类和定位能力与最先进的相关方法进行比较,来验证我们在 Camelyon16 数据集上的弱监督分类和定位能力。详细结果如表2所示,其中最好的结果用粗体表示,第二好的用下划线表示。值得注意的是,除了CLAM和TransMIL算法外,[13]中已经报道了以前的方法,这些方法都是使用它们对应的官方代码实现的,以及[13]的SSL预训练特征。CLAM 和 TransMIL 算法是通过使用它们发布的代码和我们的预训练特征来实现的。因此,我们可以直接将我们的聚合算法与这些方法进行比较。

如表 2 所示,我们的方法在很大程度上优于其他 WSWC 算法。例如,我们的方法在 ACC 中比之前的最佳性能 TransMIL 高出约 2%,AUC 高出 2%。原因可以分析如下。在 Camelyon16 数据集中,每个 WSI 中异常区域的百分比通常低于 10%。因此,以前的方法特别容易受到噪声的影响,从而导致可能漏检。我们提出的 SCL-WC 通过 WSI 内部和 WSI 间互补信息收敛实现了独特的分类特征提取,有助于缓解 WSI 中一小部分病变的问题。
CDA模块为每个补丁分配一个可学习的权重来表示其对WSI预测的重要性,并与WSCCL和PNM模块中的特征细化过程相结合,以促进更好的病变定位能力。详细的诊断阳性定位结果如表2、图2和补充材料所示。如表2所示,我们的方法获得了0.5659的FROC,优于其他方法超过10%,FROC为0.6543,显示出接近完全监督性能的潜力。在图2和补充材料中,较暖的彩色子区域意味着异常组织的概率更高,这直观地证明了我们的优越的定位性能,即使是微小的病变。

4.2 在BRACS, PANDA和DiagSet数据集上的结果
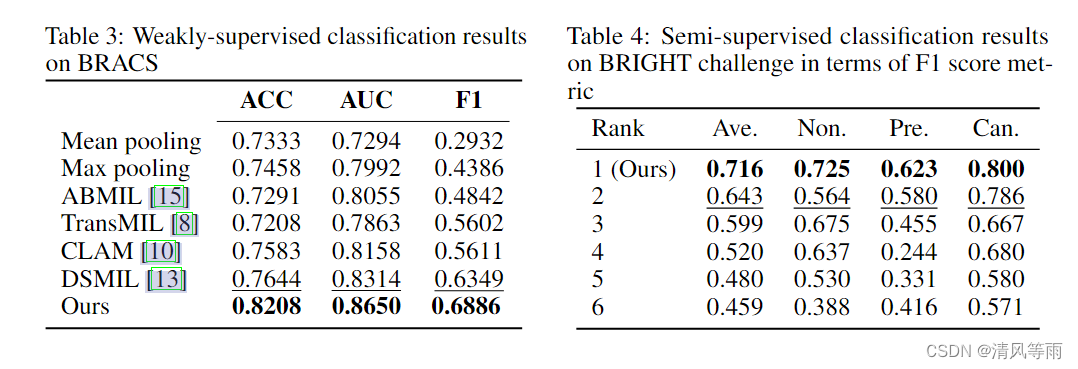
在本小节中,我们首先对表 3 中的 BRACS 数据集进行 3分类弱监督分类实验。这些比较方法的结果是根据他们发布的官方代码获得的。由于一些非癌前和癌前区域之间的特征无法区分,3 类分类任务非常具有挑战性(例如病理良性 VS 扁平上皮异型)或一些癌前和癌症组织(如非典型导管增生VS 导管原位癌)。因此,当前最先进的方法中整体分类性能不到 90%。以前的最佳性能方法是 BRACS 数据集中的 DSMIL 方法,但是,它在其他数据集中表现出次优性能(例如,表 2 和表 5)。我们提出的 SCL-WC 在所有这些数据集上仍然是最有效的,这反映了它的稳定性。
然后,在表 4 中,我们展示了我们在参与 2022 BRIGHT 挑战时的结果,该挑战是使用从我们的 SCL-WC 扩展的半监督分类方案实现的,几乎没有区别使用少量注释良好的补丁。如表 4 所示,我们的方法在 BRIGHT 挑战中排名第一,这表明了我们提出的 SCL-WC 方法的高度灵活性和可扩展性。
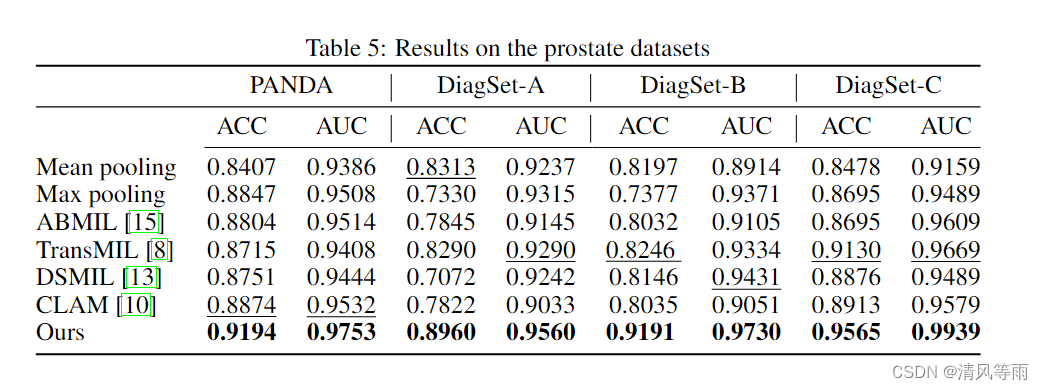
接下来,我们在两个更大的前列腺数据集上验证了我们的算法。此外,进行了广泛的外部测试,以进一步确认我们算法的鲁棒性和泛化性能。详细结果总结在表 5 中,其中 PANDA 数据集用于算法开发和内部验证,其余三个 DiagSet 子集用于外部测试。这些比较方法的结果是使用他们发布的代码获得的。如表 5 所示,我们的方法在这些数据集上始终表现得更好。具体来说,我们的方法在 PANDA 数据集中比 CLAM 方法高出约 3% ACC 和 2% AUC。在最大的外部测试集 DiagSet-B 中,我们的方法在 ACC 和 AUC 中分别比 DSMIL 高出约 10% 和 3%。
4.3 不同特征提取器和特征聚合器之间的比较
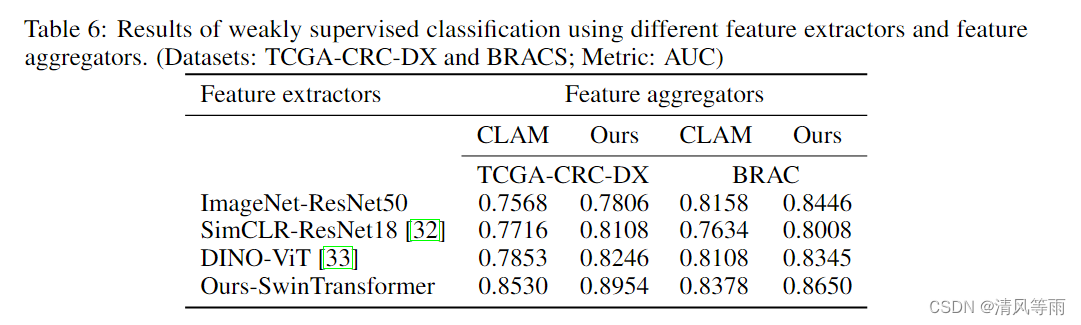
所提出的特征提取器与现有的广泛用于组织病理学图像分析任务的特征提取器进行了比较,包括 ImageNet 预训练的特征提取器和在组织病理学图像上预训练的另外两个基于 SSL 的特征提取器(SimCLR 和 DINO)[32, 33]。为此,我们进行了新的实验来研究我们的SCL-WC方法在使用不同的特征提取器对TCGA-CRC-DX数据和BRACS数据上的乳腺肿瘤亚型进行微卫星不稳定性预测时的性能。这些现有的特征提取器已经被以前的研究预训练,可以用作现成的特征提取器进行比较。详细结果见表6。可以看出,通过将所提出的特征提取器与所提出的特征聚合器相结合,实现了最佳性能。比较在TCGA-CRC-DX数据上测试的不同特征提取器,也表明我们的特征提取方法在两种聚合方法下都优于之前性能最好的DINO-ViT约7%。
表 6 还显示了在测试不同特征聚合器(CLAM 和我们的)的同时保持相同的特征提取器,所提出的特征聚合方案的有效性。比较表6中TCGA-CRC-DX数据的相应列,可以看出,对于四种不同的特征提取器中的任何一个,我们的聚合方案都优于CLAM方法约4%。
4.4 消融研究
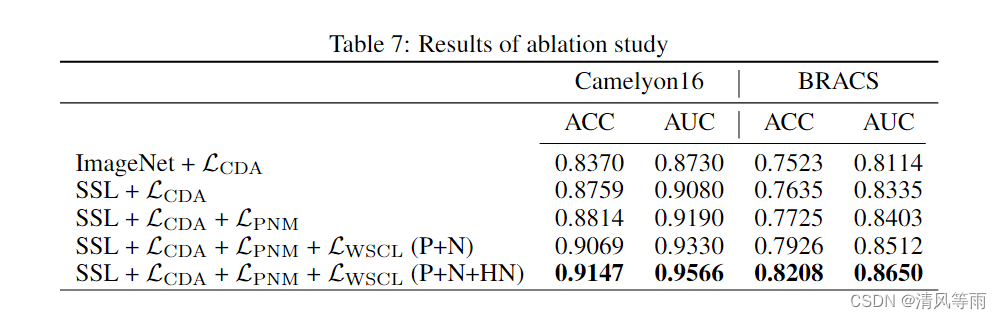
我们在表 7 中构建了一组消融实验,以证明我们提出的 SCL-WC 方法中关键组件的有效性,包括基于 SSL 的特征提取器、 L C D A \mathcal{L_{CDA}} LCDA、 L P N M \mathcal{L_{PNM}} LPNM 和 L W S C L \mathcal{L_{WSCL}} LWSCL(有和没有硬阴性(hard negatives)样本)。如表 7 所示,前两行的结果表明,与 ImageNet 预训练网络相比,基于 SSL 的组织病理学预训练的特征提取器在 Camelyon16 上提高了约 3%,在 AUC 方面提高了 2%。如表 7 的第二行和第三行所示,我们的正负感知损失在所有数据集上和指标带来了一致的 1% 的性能提升,这验证了 PNM 模块的重要性。WSCL模块的有效性可以在表7的最后三行中看到。当不考虑硬阴性样本时,两个数据集的性能都比第三行的结果提高了2%左右,当添加硬负样本时,性能进一步提高,如表7最后一行所示。
5 总结
我们提出了一种新的 WSWC 方法 SCL-WC,该方法基于特定领域的 SSL 特征提取器和特定于任务的特征聚合器构建。特征聚合器包括三个有效的模块:CDA、PNM 和 WSCL,它们组合起来进行判别补丁级特征细化,不仅提供可解释的结果,还提供精细的病变定位。所提出的 SCL-WC 方法在二分类/多分类任务的五个公开可用数据集上优于最先进的 WSWC 研究,这也在弱监督定位和半监督分类任务中显示出良好的可行性和可扩展性。然而,在部署之前,我们的方法应该在来自真实世界临床设置的更大队列中得到广泛验证,我们将在今后的工作中对此进行探讨。
总结
作者首先从问题出发,认为现阶段的方法大都让网络侧重与提取WSI中占比面积比较大的阳性组织区域(如癌症区域),而会忽略面积较小的部分。这会导致最终结果不是很好。为了更好地去获得有区分性的特征,作者首先通过自监督学习框架(MoCo v3)来训练一个编码器(Swin Transformer),之后,再利用这个训练好的网络来提取特征。特征提取完之后,利用CDA模块来进行参数化预估每个patch对最终WSI分类的贡献。同时,利用PNM模块来区分每个WSI中的阴性、阳性区域,并将其分为阳性、阴性和硬阴性(也许称为强阴性会更好。至于为什么这么划分我也不清楚,可能这样能更加容易区分它们之间的特征区别。但有个疑问是硬阴性是什么)。最后,利用对比学习(对比不同patch)来对这些特征进行聚类,从而得出更加精准的分类结果。从结果上面来看,所提出的方法是不错的(当然效果不好一般也发不了文章),但由于代码至今也还没有开源,因此这篇文章的目前没能复现,对里面的具体架构以及损失的作用都不是很清楚。
更多内容请关注微信公众号:

这篇关于论文阅读:SCL-WC: Cross-Slide Contrastive Learning for Weakly-Supervised Whole-Slide Image Classification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









