本文主要是介绍DPT-FSNET: DUAL-PATH TRANSFORMER BASED FULL-BAND AND SUB-BAND FUSION NETWORK FOR SPEECH ENHANCEMENT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- ICASSP 2022
- 1. Abstract
- 2. Intorduction
- 2. Improved Transformer
- 2.1 Multi-head self-attention
- 2.2 Modified position-wise feed forward network
- 3. Proposed DPT-FSNET
- 3.1 Encoder
- 3.2 Dual-path transformer processing module
- 3.3 Decoder
- 3.4 Loss function
- 4. Experiments
- 4.2 Experimental setup
- 5. Experimental Results
- 5.1 Results on the VCTK+DEMAND dataset
- 5.2 Ablation analysis
- 5.3 Results on the DNS dataset

ICASSP 2022
1. Abstract
子带模型对谱图的局部模式建模方面取得了较好的结果。已有部分工作将子带信息和全带信息进行融合,以提升模型的性能。本文提出了一种基于transformer的双分支全带、子带融合网络(DPT-FSNet),用于频域的语音增强。模型的intra和inter部分分别对子带信息和全带信息进行建模。本文提出的方法所使用的特征比时域的双分支网络所使用的的特征更易解释。本文在Voice Bank+ DEMAND和Interspeech2020 Deep Noise Suppression数据集上进行了实验对比,实现了SOTA性能。
2. Intorduction
子带处理将子带频谱特征作为网络的输入和输出,已有方法[9,10,11],子带模型独立处理每个频率,使模型能够关注频谱中的局部模式,从而提升语音增强的性能。
[9] Haohe Liu, Lei Xie, Jian Wu, and Geng Yang, “Channel-Wise Subband Input for Better Voice and Accompaniment Separation on High Resolution Music,” in Proc. Interspeech 2020, 2020, pp. 1241–1245.
[10] Geng Yang, Shan Yang, Kai Liu, Peng Fang, Wei Chen, and Lei Xie, “Multi-band melgan: Faster waveform generation for high-quality text-to-speech,” in 2021 IEEE Spoken Language TechnologyWorkshop (SLT). IEEE, 2021, pp. 492–498.
[11] Shubo Lv, Yanxin Hu, Shimin Zhang, and Lei Xie, “DCCRN+: Channel-Wise Subband DCCRN with SNR Estimation for Speech Enhancement,” in Proc. Interspeech 2021, 2021, pp. 2816–2820.
当前,已有部分工作使用双路径网络取得了较好的性能提升,这类方法能够对输入序列的局部和全局特征进行建模。这些方法都是在时域信号上直接处理,没有进一步探究双路径网络的输入对增强性能的影响。
本文提出了DPT-FSNet网络,包含一个encoder,decoder和一个双路径transformer。模型使用convolutional encoder-docoder(CED)结构为双路径transformer提取有效的latent 特征空间。编码器和解码由1x1卷积层和dense block组成,dense block中包含膨胀卷积,用于学习上下文信息。双路径transformer由两部分组成,分别为intra-transformer和inter-transformer。前者对子带信息进行建模,后者对全带信息进行建模
2. Improved Transformer
本文选用transformer模型的encoder部分作为本文transformer部分的基础模块,原始的transformer encoder通常包含三个模块:位置编码,多头自注意力和position-wise前馈网络。本文的transformer模型包含两个部分:多头自注意力和改进的position-wise前馈网络。
2.1 Multi-head self-attention
本文使用文献【17】提出的多头自注意力机制。
Attention is all you need
2.2 Modified position-wise feed forward network
transformer 的一个关键问题是如何利用语音序列中的顺序信息。
已有工作发现,原始transformer中的位置编码不适用于dual-path网络。受到RNN网络在学习顺序信息方法的启发,本文使用一个GRU层代替前馈网络中的第一个全连接层来学习位置信息。

FFN(.)表示position-wise前馈网络的输出, W 1 ∈ R d f f × d , b 1 ∈ R d , d f f = 4 × d W_1 \in \mathbb{R}^{d_{ff}\times d}, b_1 \in \mathbb{R}^d, d_{ff}=4\times d W1∈Rdff×d,b1∈Rd,dff=4×d。
3. Proposed DPT-FSNET
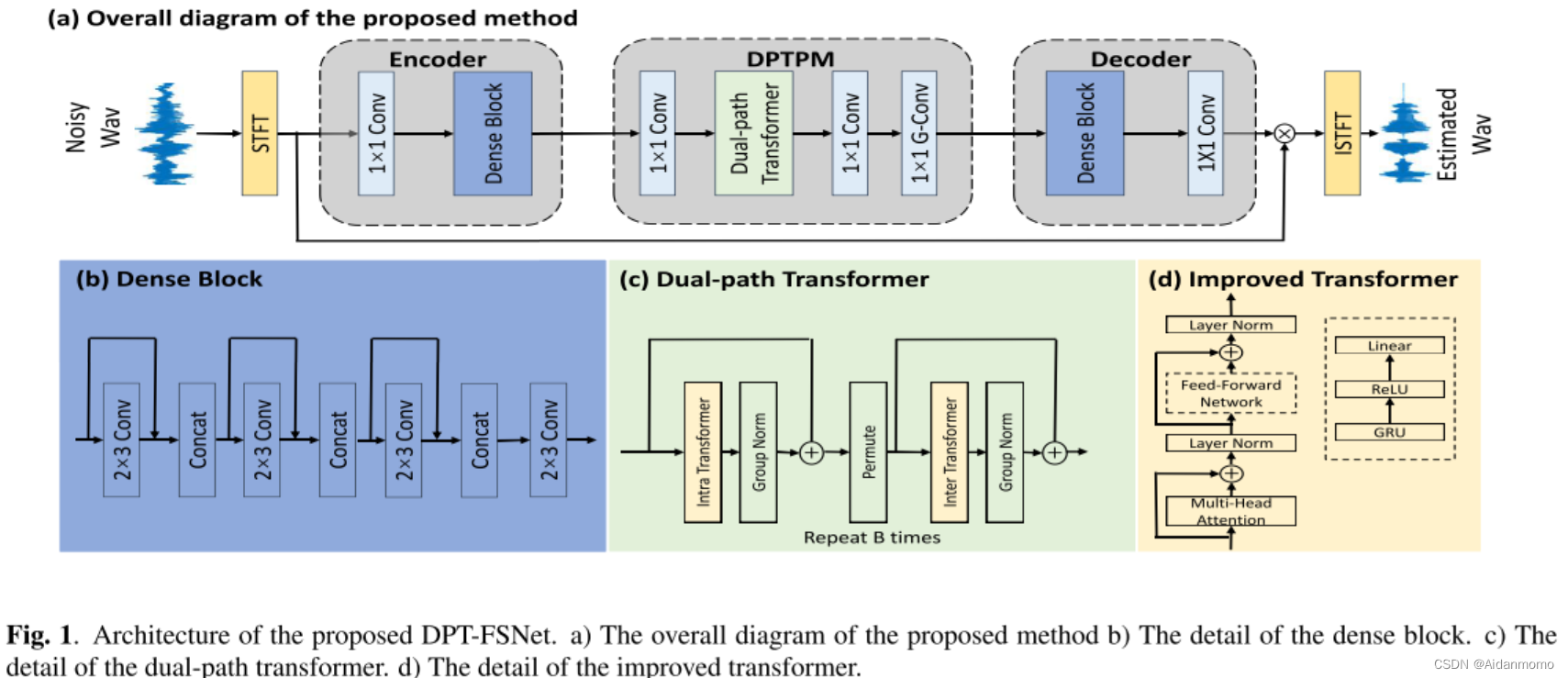
DPTPM: dual-path transformer processing module.
3.1 Encoder
编码器层包含一个1x1卷积层和一个dilated-dense块,后者由四个膨胀卷积层组成。Encoder的输入为复数谱 X ∈ R 2 × T × F X \in \mathbb{R}^{2 \times T \times F} X∈R2×T×F,输出高维特征表示 U ∈ C × T × F U \in \mathbb{C \times T \times F} U∈C×T×F。
3.2 Dual-path transformer processing module
DPTPM包含两个1x1卷积层,B个dual-path transformers(DPTs),一个门控1x1卷积层。特征输入DPTs之前,本文使用一个1x1卷积层将通道数减半,即DPTs的输入可以表示为 D ∈ R C ′ × T × F D \in R^{C^{'} \times T \times F} D∈RC′×T×F。每个DPT包含一个intra-transformer和一个inter-transformer,前者对子带信息进行建模,后者对全带信息进行建模。不同于【22】,DPT交替地处理时间和频率路径,而不是并行处理。
[22] Chuanxin Tang, Chong Luo, Zhiyuan Zhao, Wenxuan Xie, and Wenjun Zeng, “Joint time-frequency and time domain learning for speech enhancement,” in Proceedings ofthe Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, 2021, pp. 3816–3822.
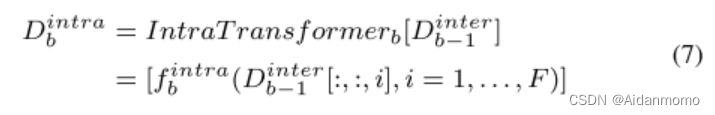
f b i n t r a f^{intra}_b fbintra表示transformer定义的映射函数, b = 1 , 2 , . . . , B b=1,2,...,B b=1,2,...,B, D o i n t e r = D , D b − 1 i n t e r [ : , : , i ] ∈ R C ′ × T D_o^{inter}=D, D_{b-1}^{inter}[:,:,i] \in R^{C^{'} \times T} Dointer=D,Db−1inter[:,:,i]∈RC′×T表示由第i个子带的所有T个时间步长定义的序列。
inter-transformer块用于聚合每个子带的信息,从而捕获全局信息,作用于D的最后一个维度。
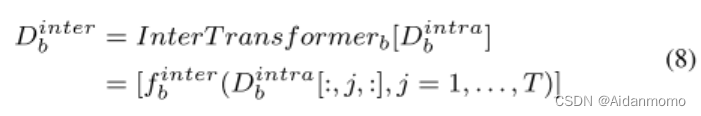
D b − 1 i n t r a [ : , j , : ] ∈ R C ′ × F D_{b-1}^{intra}[:,j,:] \in R^{C^{'} \times F} Db−1intra[:,j,:]∈RC′×F 表示由第j个时间步对应的F个子带定义的序列。经过处理, D b i n t r a D^{intra}_b Dbintra中的每个时间步包含了对应子带的所有信息,从而实现对语音信号的全局信息进行建模。
特征信息经过transformer后,通过一个1x1卷积层恢复通道数,然后通过一个门控卷积层,使DPTPM的输出值平滑。
3.3 Decoder
Decoder包含一个1x1卷积层和一个dilated-dense块,与encoder部分相同。特征信息通过decoder之后,得到复数比值掩码的估计。
3.4 Loss function
本文的损失函数同时利用时域损失和T-F域损失:
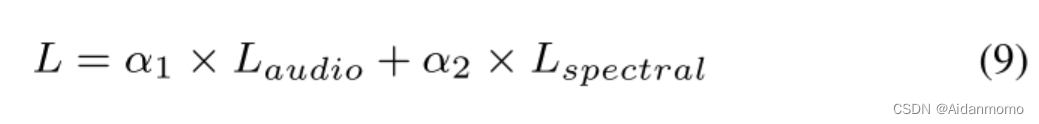
其中 L a u d i o L_{audio} Laudio表示MSE损失(Mean square error):
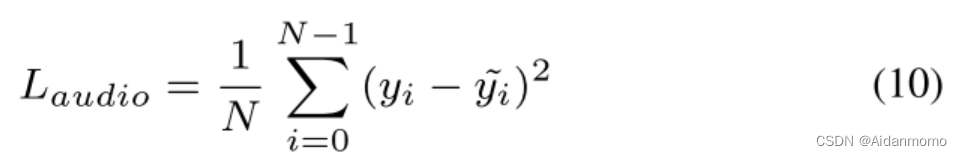
L s p e c t r a l L_{spectral} Lspectral表示L1损失:
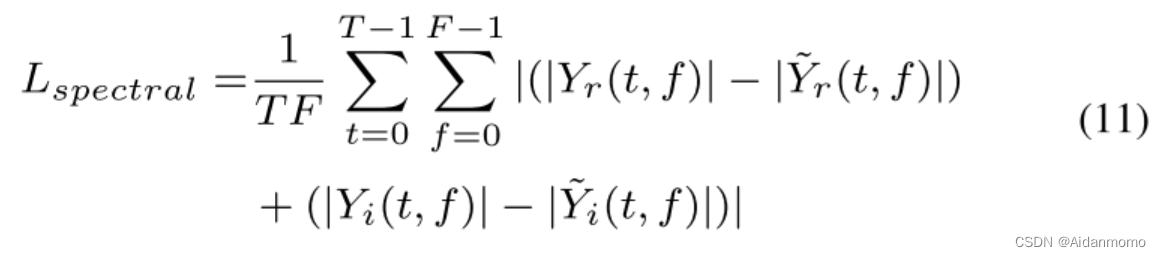
4. Experiments
本文使用了两个数据集
小规模数据集:VCTK+DEMAND
大规模数据集:DNS dataset
4.2 Experimental setup
STFT的窗长和窗移分别为25ms和6.25ms,FFT长度为512。通道数C设置为64,encoder 和decoder中所有卷积操作后都会使用层归一化和PReLU。DPTPM中的卷积层后使用PReLU。dense block包含4个膨胀卷积层,膨胀系数d=2。因此4个膨胀卷积的输入特征的通道数分别为C,2C,3C,4C,输出通道数为C。
模型中包含4个双路transformer,参数设置B=4, h=4(多头数量)。超参数 α 1 和 α 2 \alpha1和 \alpha2 α1和α2分别设置为0.4和0.6。共训练100个epochs,Adam优化器,使用最大L2范数为5的梯度裁剪来避免梯度爆炸。采用如下动态策略来调整学习率:
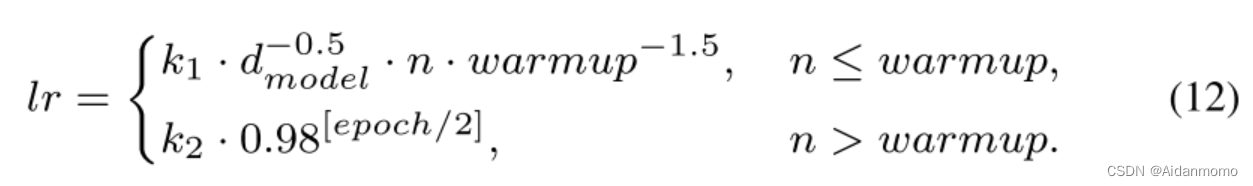
其中n表示步数, d m o d e l d_{model} dmodel表示特征大小。本文将k1,k2,d_model和warmup分别设置为0.2, 4 e − 4 4e^{-4} 4e−4,32,4000。
5. Experimental Results
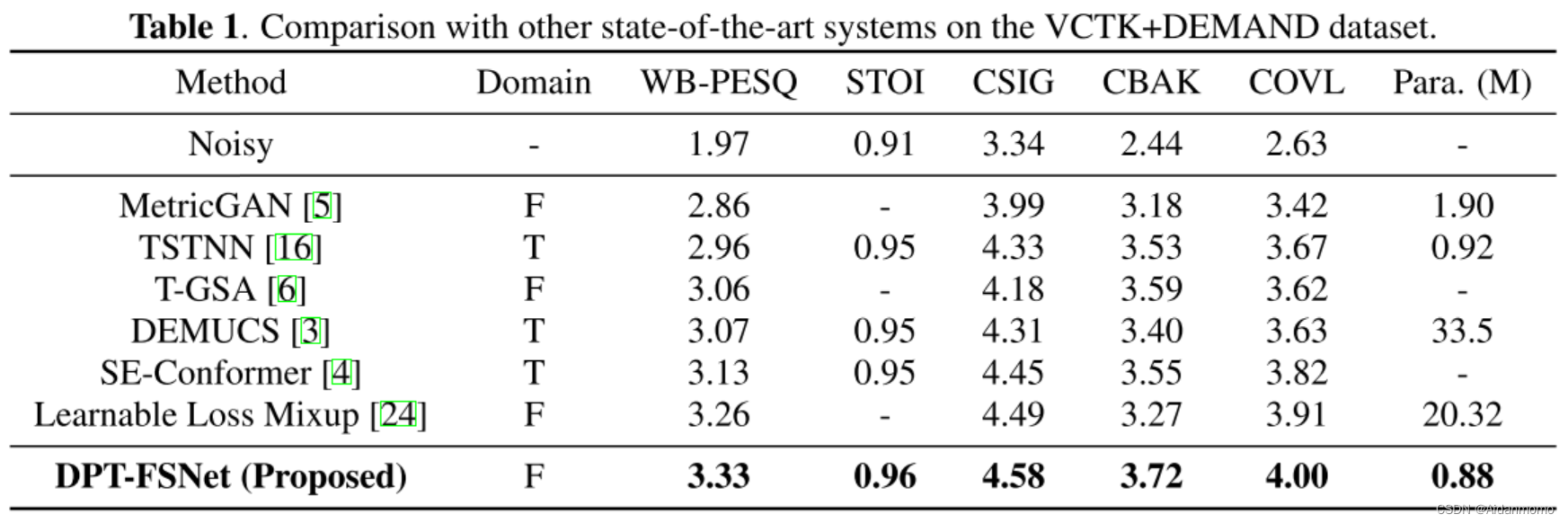
5.1 Results on the VCTK+DEMAND dataset
5.2 Ablation analysis

实验1使用时域输入数据。
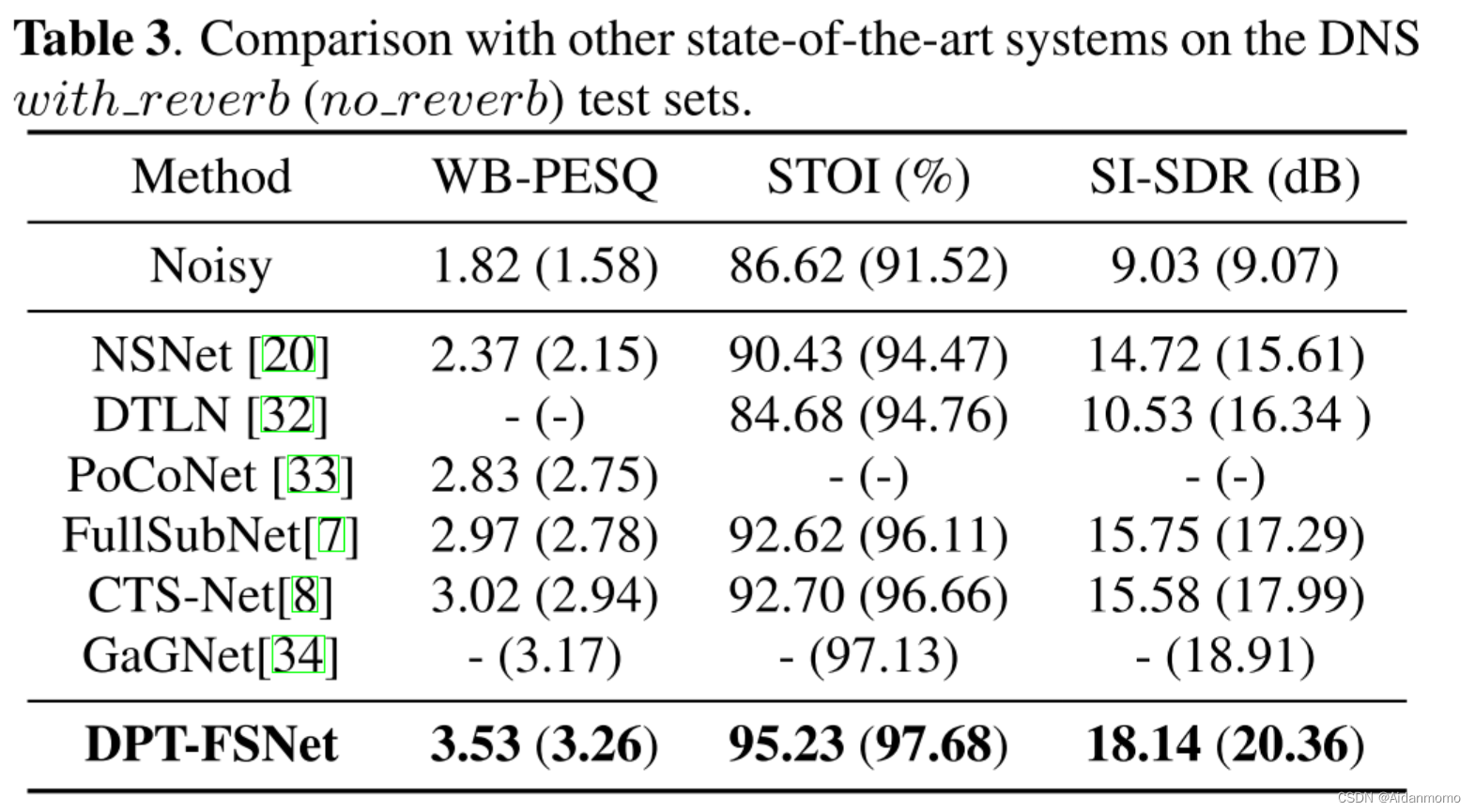
5.3 Results on the DNS dataset
这篇关于DPT-FSNET: DUAL-PATH TRANSFORMER BASED FULL-BAND AND SUB-BAND FUSION NETWORK FOR SPEECH ENHANCEMENT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







