本文主要是介绍GEE——Publisher Data Catalogs发布者数据目录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
发布者数据目录
发布者数据目录由数据集发布者策划,供更大范围的 Google 地球引擎社区使用,并作为地球引擎资产集公开共享。这些目录并非由 Google 编制。这里是GEE团队简政放权的一个过程,也就是说这些数据集的后续更新和维护并不由GEE团队负责。也就是后续这个数据集是否更新和运营都不和GEE有什么瓜葛。前言 – 人工智能教程
https://developers.google.com/earth-engine/datasets/publisher
目前这个数据集仅有两个公开数据集,
澳大利亚地球科学
1 个数据集
澳大利亚地球科学组织为决策者提供地球观测服务、专家建议和信息。该计划的目标是确保获取遥感信息的连续性,以支持政府的优先事项;促进卫星图像在政府和更广泛的社区中的使用和价值;通过充分挖掘 EOS 的价值和使用其潜力来推动遥感科学的发展;提供数据管理以确保数据的获取;以及为灾害和紧急情况提供国家图像协调。
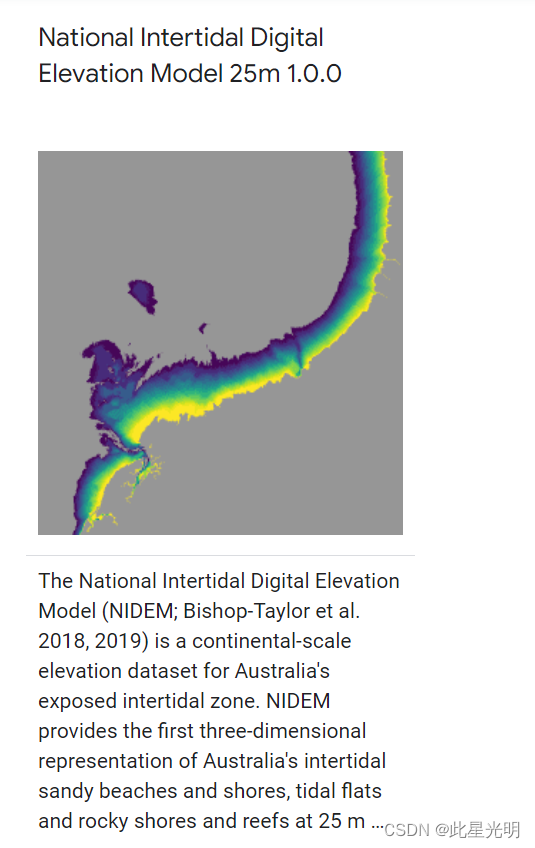
https://developers.google.com/earth-engine/datasets/catalog/projects_geoscience-aus-cat_assets_NIDEM
本数据集是出版商目录的一部分,不由 Google 管理。如发现错误,请联系澳大利亚地球科学组织,或查看澳大利亚地球科学组织目录中的更多数据集。了解有关出版商数据集的更多信息。
行星
3 个数据集
Planet 每天提供卫星数据,帮助企业、政府、研究人员和记者了解物理世界并采取行动。通过挪威国际气候与森林倡议(NICFI),用户现在可以访问 Planet 高分辨率、可分析的全球热带地区镶嵌图,以帮助减少和扭转热带森林的损失,应对气候变化,保护生物多样性,促进非商业用途的可持续发展。
https://developers.google.com/earth-engine/datasets/publisher/planet-nicfi
这篇关于GEE——Publisher Data Catalogs发布者数据目录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




