本文主要是介绍干货!端到端的目标检测器——香港大学PhD孙培泽,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
最近提出的DETR目标检测器在检测流程的最后一个不可微分部分、NMS(非极大值抑制)以及建立一个端到端的目标检测器方面都取得了很大的进步。然而,DETR的缺点是降低训练过程的收敛速度和小目标检测效果不佳,其主要原因是每个检测目标都需要对全图特征进行交互。本文提出了一种每个目标只对局部特征进行交互的Sparse R-CNN,其各个尺度检测精度和训练收敛表现在现有典型目标检测器发挥优秀。
本期AI TIME PhD直播间邀请到了香港大学博士生孙泽培,带来分享——《基于图结构学习的归纳式协同过滤》。

香港大学二年级博士生,导师为罗平副教授。主要研究方向是目标检测、分割、跟踪等,曾在CVPR、ICML、ICCV等国际会议发表论文多篇。
01
背 景
目标检测的目的是在图像中对一组目标进行定位并识别它们的类别,而稠密先验(dense prior)一直是检测器成功的基础。目标检测主流的两大类方法包括一阶段的Dense detector和两阶段的Dense-to-Sparse detector。
一阶段Dense detector的做法是在高为H宽为W的feature map上预设anchor boxes、reference points等,基于这些检测框预测目标的位置和类别。
两阶段Dense-to-Sparse detector是在一阶段的基础上进行进一步的调优:由一阶段给出的proposal得出物体特征然后进行预测类别和检测候选框。
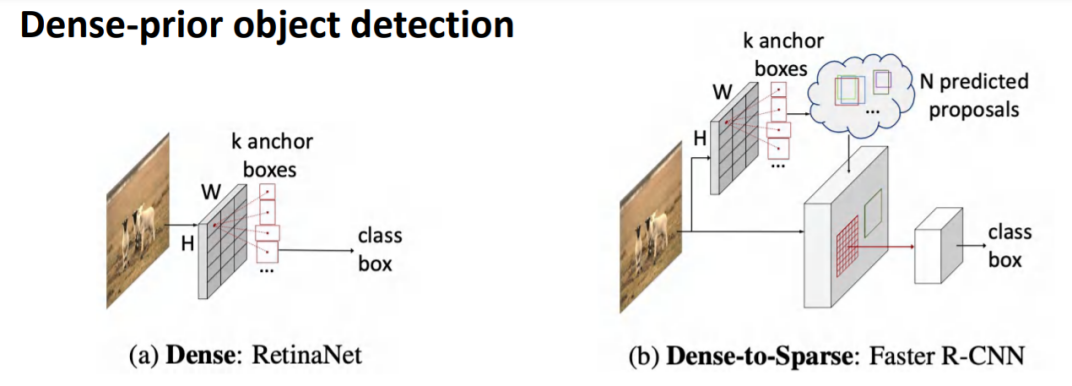
上述两种目标检测方法的局限性:
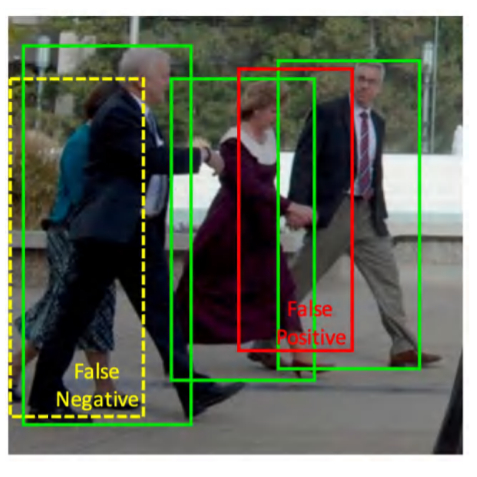
i. 需要NMS来去除冗余候选框。
拥挤场景下NMS窘境:
NMS阈值过小,即两个候选框的IoU(交并比)较大时才会去掉其中一个,导致产生更多false positives(假的正样本),如下图的红色候选框。
NMS阈值过小,两个候选框的IoU较小也会去掉其中一个,导致减少true positives(真的正样本),如下图黄色候选框。
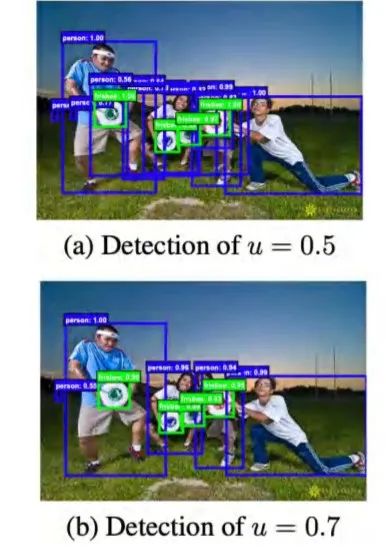
ii. One-to-many label assignment:由于会有大量候选框,使得一个物体可能存在多个正样本。
IoU值较低会导致预测结果含有许多噪声(如图a),IoU过高使得数据集正样本极少,从而使得detector对这些正样本进行过拟合(如图b)。
FaceBook提出一个稀疏先验(Sparse-prior)的目标检测器——DETR(End-to-end object detection with transformers)创造性地解决了以上两个问题。DETR的创新之处是Sparse-prior,首先预设一组object queries,其数量远小于之前dense的工作,一般为100个左右。然后object queries经过编码器和解码器之后生成一组box predictions。将box prediction与物体进行二分匹配,一个物体只有一个正样本,因此解决了NMS和One-to-many label assignment问题。
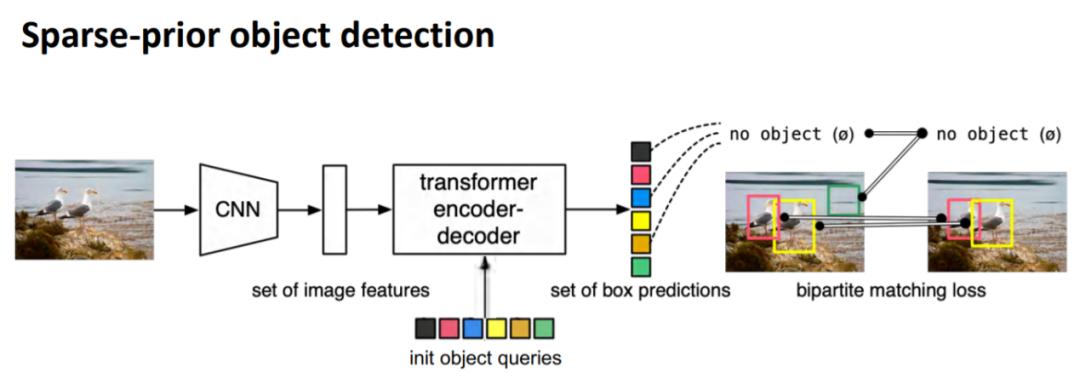
DETR在解决NMS和一对多问题上确实是里程碑的工作,但是也有以下两个需要关注的问题。1) DETR在训练过程中收敛很慢;2)由于使用了transformer结构,物体的feature map上的每个点都需要两两交互,因此限制了feature map的分辨率不能太大,因此对于小物体的检测性能有限。
02
方 法
为了解决DETR在目标检测任务中存在的问题,本文提出了Sparse R-CNN模型。
Sparse R-CNN继承了DETR的Sparse-prior的性能,也是仅通过一组较少数量的proposal boxes来完成目标检测任务。本文认为DETR收敛较慢的原因是每个object query需要和feature map上的所有点进行交互,如果这个是稀疏的,即每个proposal仅与局部区域进行交互,具体是仅与proposal对应的RolPooling、ROIAlign取出来的feature交互,就可以极大加速收敛过程。由于交互仅在局部发生,可使proposal去和高分辨率的feature map进行交互,从而提升小物体的检测效果。
下图是Sparse R-CNN的模型结构图,输入一张图片提取feature map和一组proposal box及对应的proposal feature。Sparse feature可以理解我DETR中的object query。proposal box和proposal feature与网络参数一样在后续训练中都是能够学习优化的。
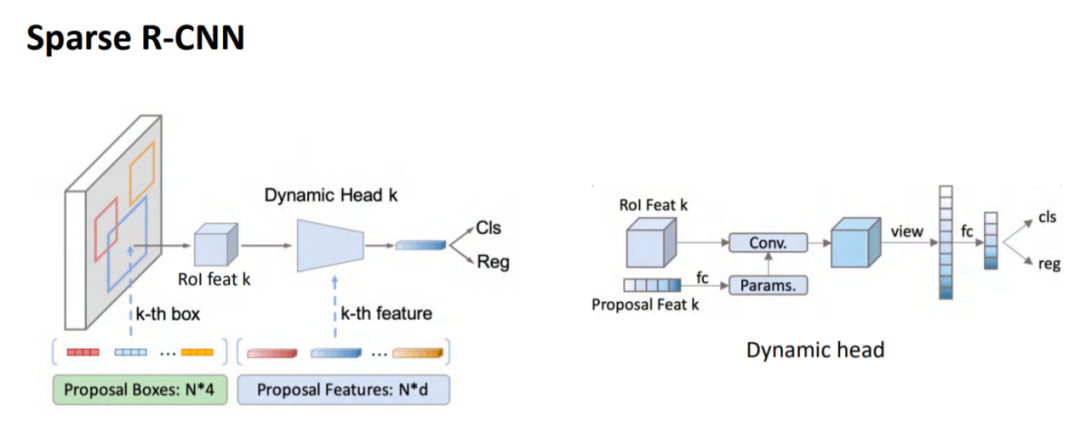
Sparse R-CNN继承了DETR中的损失函数,一个物体只有一个正样本。
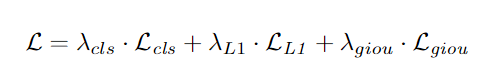
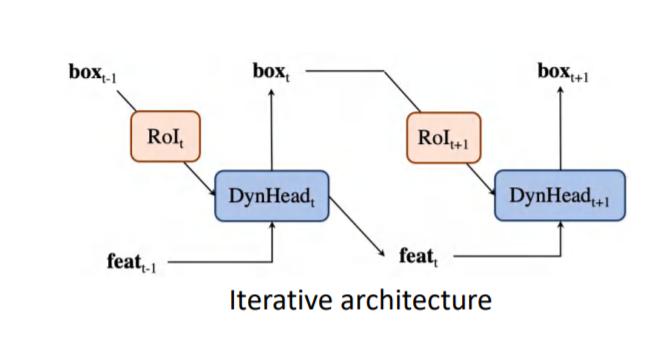
本文认为Sparse的结构只进行以此调优是远远不够的,因此本模型采用迭代的结构进行多次调优,得到与之前dense的工作相比的性能。具体实现是采用新生成的proposal box和proposal feature作为下一阶段的proposal box和proposal feature。
03
实 验
(1) 训练收敛情况
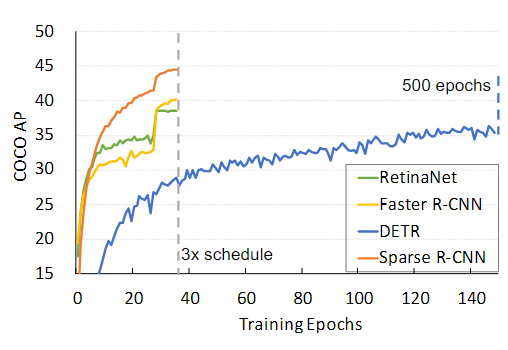
下图是多个目标检测模型在COCO数据集上的训练迭代情况,本文模型Sparse R-CNN的收敛速度与经典的模型对比基本持平,且远快于DETR。
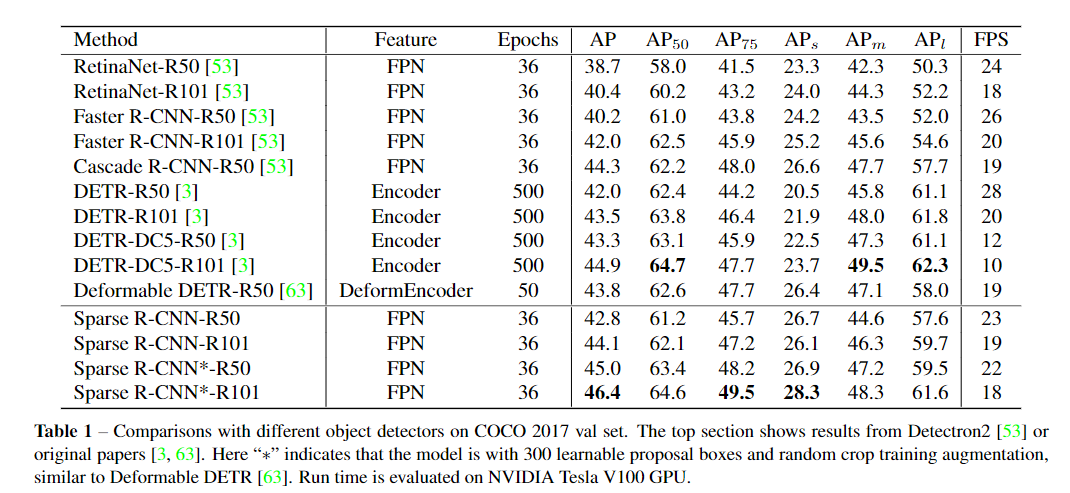
(2) 小物体的目标检测性能
下图是多个目标检测模型的消融实验,APs那一列表示小物体的检测精度,Sparse R-CNN对于小物体的检测性能优于DETR,在其他Dense detector或者经典目标检测器中也是很优秀的。
04
总 结
本文提出了一种用于图像中目标检测的方法——Sparse R-CNN,给出了一组可学习的稀疏的物体proposal进行分类和定位。Sparse R-CNN参考了DETR的一对一的proposal,直接输出最终的预测结果,不需要进行NMS。Sparse R-CNN在拥挤场景下可以实现更精确的检测,并且在准确性、训练收敛性能上都优于DETR。
今日视频推荐
整理:爱国
审核:孙培泽
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

我知道你在看哟

点击“阅读原文”查看精彩回放
这篇关于干货!端到端的目标检测器——香港大学PhD孙培泽的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)


![[数据集][目标检测]智慧农业草莓叶子病虫害检测数据集VOC+YOLO格式4040张9类别](https://i-blog.csdnimg.cn/direct/4a9ca83db964467783f221a1fd15ab5b.png)
