《面向应用于社会TV分析的应用了SDN的大数据平台》
Abstract
social TV analytics 是什么,就是说很多TV观众在微博、微信和推特等这些地方分享他们的观感时,然后有人就对这个进行挖掘分析,这就被称作social TV analytics。不仅如此,这些人还将大数据研究运用进TV中。想要发展一个研究social TV的平台,但是面临很多挑战,于是作者就提出在SDN的support下来搭建一个cloud-centric 平台,来提供按需虚拟机和可重构网络。这套系统的架构主要有三个关键点:一是很鲁棒的数据采集(爬行)系统;二是运用了SDN的大数据处理系统;三是社交媒体分析系统。
这个采集系统就是采集感兴趣的电视节目信息;处理系统运用了SDN和分布式计算,在不同的处理单元中传输数据,说白了就是加快了数据的处理速率;分析系统主要抓取公众关于tv节目的信息。
【
OSNs 类似微博,推特之类的
envision 想象、预见
extract 提取、拔出、取得
in a real-time manner 以实时的方式
tremendous 巨大的
on-demand 按需
crawler 爬行者
a distributed architecture 分布式体系结构
circumvent 绕过、避免
Hadoop 分布式计算
exploit 开采、开拓
extract 取得
perception 观念、想法之类的
microblog 微博
proof-of-concept demo 用于观念证明的演示
over prep在…的上面
Feature verification 特征验证
】
Content
OSN的出现方便人们的分享,其中就有TV的信息,故衍生出对此的分析。深挖这些与TV节目的社交媒体信息可以带来一个新的商业模式,例如我们现在所熟知的目标客户广告的精准投放。
【
interact 相互作用 interactive 相互作用的
various entities 各种实体
tweet 呜呜叫
】
可是呢,对于采集分析来说,微博有很多的限制,比如说140字啦,缩略语的使用啦(常见于推特),这对于系统去收集、存储、分析这么多的信息来说就很困难。首先微博上某一时刻就出现大量信息,实时采集TV节目的信息很困难,尤其是微博还给你限制的情况下。其次,微博可以图文表述,还可以插入音乐之类的,这对于分析来说也是一个挑战。对于大数据平台来说,要将这些信息分层次的分析,而且关键还是要实时分析。
【
abbreviation 缩写
posit 假定,假想
elicit 引出
adequate 足够的
the access constraints 访问约束
format 版式
facilitate 促进,助长
】
信息收集方法取决于由社交媒体平台所提供的API而且受其访问约束控制。通常,数据收集方法有三类:一类是基于流的,即按照已设置好的特定的关键词进行检索;一类是基于用户的,顾名思义即查看特定用户的;一类是基于搜索的,查询给定的关键词。总的来说就是数据的收集方法取决于关键词/用户的完备性。
【
paramount 最高的
epidemic 流行病
track 跟踪
query 质疑
representativeness 典型性、代表性
】
为了高效处理,于是就引入了SDN和分布式计算。分布式计算的核心部分就是MapReduce【5】计算框架,包含两个部分:Map和Reduce,为应用提供一个通用的范例,尤其在网络流量控制上有很大的性能优化。近年来,SDN的出现提供了一个灵活且动态的网络框架,其主要思想是将数据平面和控制平面分离。于是就有人将SDN和Hadoop等结合来实现智能数据流路由,详看【[7]】。
【
MapReduce 分布式计算系统
】
站在巨人的肩膀上,本文就想建一个针对social TV分析的统一大数据平台。作者设计并implement了一个运用SDN的云中心平台,能够将虚拟化技术和OpenFlow结合。针对social Tv的解决方案,主要的三点就是上面摘要中所提到的:the data crawler system, the sdn-enabled big data process system, the social media analytics system。一个用于数据爬取,一个用于数据的加速传输,还有一个用于挖掘与社交媒体有关的东西。本文的独特贡献就是:
1. 所提的分布式大局爬取平台由两个核心部分组成:一个程序描述符和一个分布式爬取器。程序描述符用于描述电视节目,分布式爬取器可以产生爬取和处理任务。
2. 基于分布式计算的SDN架构可以加速分析速率。
【
leverage 利用
customize 定制,定做
segmentation 分割,分段
collaborate 合作
exploit 开采,利用
representativeness 典型性,代表性
shuffle 混洗
intermediate 中间的
clusters 群,组
】
这个原型系统是在南阳技术学院初步实施的。
【
prototype system 原型系统
demonstrate 证明
preliminary 初步的
】
A Generic Big Data Platform for Social TV Analytics
有一个通用架构用于social TV analytics,如图1所示: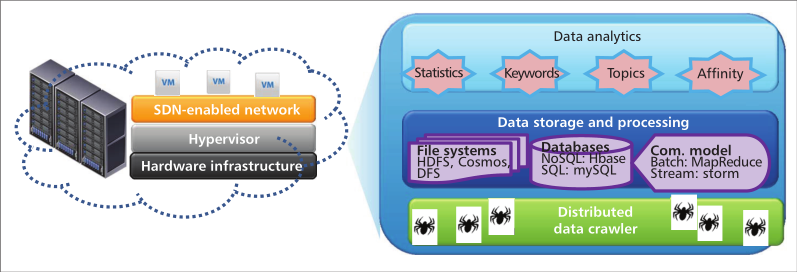
主要由四个层次构成:基础层,分布式数据爬取层,数据存储和处理层,数据分析层。下面来详细地描述一下各个层到底干啥用:
【
illustrated 有插画的东东
anatomy 分解,分析
elaborate 详尽说明
】
Infrastructure:通过云计算范式,可以将未处理的信息和资源抽象化为资源池,并以虚拟机的形式提供出去。此外,运用的SDN的交换机可以被用来construct数据中心网络。系统管理员就可以查看虚拟机和动态网络的使用情况,并可以动态进行调整。就是说,这样可以优化资源配置并防止网络拥塞。
Distributed data crawler:分布式数据爬取系统是部署在a collection of nodes distributed in several ip segmentations。选择一个节点作为调度程序,将爬行任务调度到其他爬虫节点。每个爬行节点都可以采用多线程来爬取数据。目标呢就是爬取更多的数据。
Data storage and processing:这一层主要用来高效管理和处理社交媒体流。Hadoop和Storm和两个大数据分析平台,其中Hadoop整合了分布式文件管理系统(HDFS)、NoSQL数据库(Hbase)、批式编程模型(MapReduce)。作为补充,Strom在实时分析中充当流计算的角色。
Data analytics:这一层可以提供不同level的数据分析结果,从统计到内容的分析。从用处上看很大,可以用于预测、分析。比如一个用户的背景、喜欢看啥、在讲啥东西等等。
【
a resource pool 资源库
construct 构建
utilization 利用
bandwidth reservation 带宽预留
congestion 拥挤,堵塞
simultaneously 同时地
segmentation 分节
scheduler 调度程序
dispatch 调度,派遣
batch-style 批式
supplement 补充
statistics 统计,统计学
perception 直觉,觉察
】
System Prototype
本节主要开始介绍social TV analytics的三个关键组成,分别是分布式大叔爬取部分,运用sdn的数据处理部分,与社交媒体分析有关的TV程序部分。
【
generic 一般的
】
Distributed Data Crawler
爬取是后续阶段的基础,因为与TV相关的信息很多,所以必须爬取一些典型的信息,而且微博会对信息的获取做一些限制,所以必须考虑相应的对策。
Program descriptor:我们设计四种类型的items来描述一个TV节目:fixed keywords, dynamic keywords, known accouts, and dynamic key users。首先先选择一些固定关键词,然后再次基础之上再选出动态关键词。特定用户也是先手动挑选出来的,二动态的关键用户就是哪些特定用户中发表相关信息很多的那一撮。但是可能有时候特定用户并未发表相关的TV信息,可能他发了旅游照片而不是TV节目信息,这就需要数据分析环节来处理了。
【
trivial 无价值的
representative 有代表性的
coverage 范围
authorize 授权,委托
violate 违反,妨碍
tackle 处理
elaborate 详细说明,详细制定
】
Distributed crawler:
根据给出的关键词和特定用户,我们就可以进行查询和收集了。爬取程序采用的是分布式的行为,这样可以避免OSN的限制,比如可以设置在一个较短的时间内进行查询。另外每个爬取节点都是采用多线程进行发送请求,为了避免OSN的限制,每个节点可以和一个应用的key进行动态绑定。线程和应用的key取决于访问频率和数量的限制。
【
correspond to 对应于
distinct 有区别的,不同的
exceed 超过
threshold 门槛,阈值
a time slot 时隙
region 地域,领域
dispatch 派遣,处理
empirically 以经验为主的
】
图二展示了分布式数据爬取器的架构: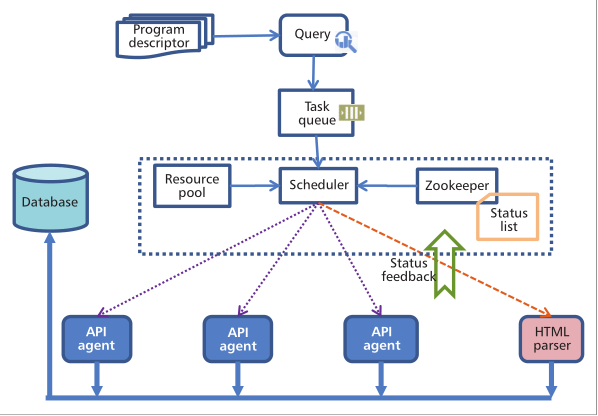
每个TV节目都被一个节目描述符所描述,由4个可动态扩展的items组成。对于每个item,系统首先发送一个请求来得知在这一段时间内有多少的相关微博信息,然后考虑是否要将查询分成多个子查询。然后每个子查询就被发送到Task queue中去。考虑到访问约束,我们建立一个Recourse pool来保证受限的相关资源,例如应用keys和ip地址。用Zookeeper来监视所有机器的运行状态。根据系统状态,Scheduler以负载均衡的方式将任务分派给执行节点(the execution nodes)。已经实现了有两种的执行节点,the API-agent 和 the html parser。the API-agent是通过提供的api来获取信息的,而 the html parser则是直接从网页上爬取下来的,可以说各有各的优点吧。一旦Zookeeper检测到某一爬取节点down掉了,其任务就会被转移至其他活跃的节点。最后,收集到的所有tweets都由SWM分类器进行去噪,然后存储在我们的存储系统中。
【
depict 描绘
split 分裂,分开
emit 发出,放出
execution 执行
quota 配额
notify 通知,告知
classifier 分类器
】
SDN-Enabled Data Processing Platform
一旦采集到足够的数据,我们就将其混合起来并利用Hadoop进行分析,但这种方法有延迟。一种改进的方法就是对数据进行局部(locally)分析,聚集产生的结果到一起形成最后的结果。
如图三所示,作者采用应用了sdn的分布式框架,与带有分布式任务调度程序的sdn控制器相结合来解决这个问题。框架由local层和global层组成。local层包括位于不同IP段的数据中心的集合。所有的本地控制器都和全局控制器相连。意思就是说有很多个本地的,还有一个是全局的。
【
exploit 开采,利用
incur 遭受,导致
sustain 维持
congestion 拥挤,堵车
tackle 着手处理
】
在这个平台,我们需要将中间数据传送到数据中心,然后生成最后的结果。时间的花费分为两个部分,其中一部分就是传送的部分,所以数据中心的选择对系统的表现也很重要。目标是找到一个可以使传输时间和处理时间最小的那个节点。
【
execution 实施,实行
estimation 估计,估价
calculate 计算,估计
】
TV-Program-Related Social Media Analytics
作者们用了很多的度量指标来展示公众的兴趣,比如说统计的地理指标,用户id,微博的发表次数,分享时间等等,这些有助于目标广告的投放。
【
metric 公制的
propagation 传播,传输
extract 提取,萃取
】
Dynamic keyword generation:关键字逐渐在一段时间内动态生成。
【
construct 构建,构想
predefined 预定义
interval 间隔
vocabulary 词汇表
】
Key user generation:根据用户所发的相关微博数量以及和粉丝的互动程度,对用户进行排列,得分最高者将荣幸成为key users。
【
employ 雇佣,使用
cluster 聚集,集中
categorize 把…归类
incorporate 使混合,使具体化
】
Evaluation
在这个章节,作者将要在私有数据中心建立一个实验,并验证其有效性,然后展示效果。
【
preliminary 初步的
】
System Setup
介绍系统的配置。该数据中心设置在NTU中,由10个racks组成,每个rack由30个HP和2个gigabit Cisco 交换机组成。
【
modular 组合式的,模块化的
utilize 利用,使用
rack 支架
】
Performance Evaluation for SDN-Enabled Big Data Platform
采用3个racks来构建一个2层架构,如图4a所示: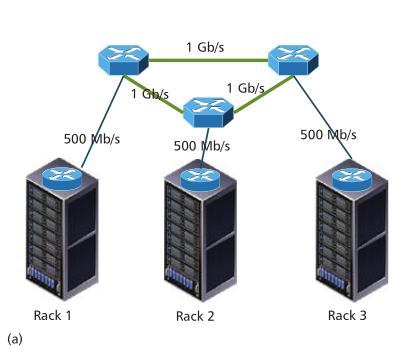
服务器在3个rack上分别设置为10个、8个和5个,在rack里的所有服务器通过rack顶部开关和SDN交换机相连。作者比较了传统的和SDN的解决办法。如图4b所示: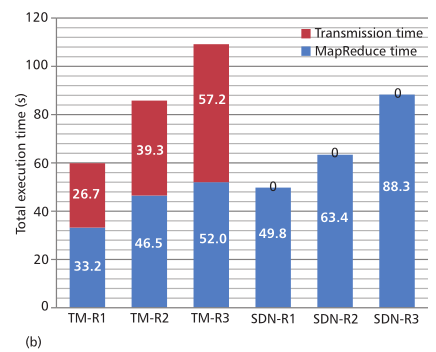
【
respectively 各自地
execution 实行
】
Social Perception of TV Programs
如图5所示,作者提供了几个初步的结果。以“龙门镖局”为例,5a展示了数据集的地理分布;5b展示了几个指标的变化情况;5c展示了观众登录微博的情况分布;5d展示了众多信息中的关键词。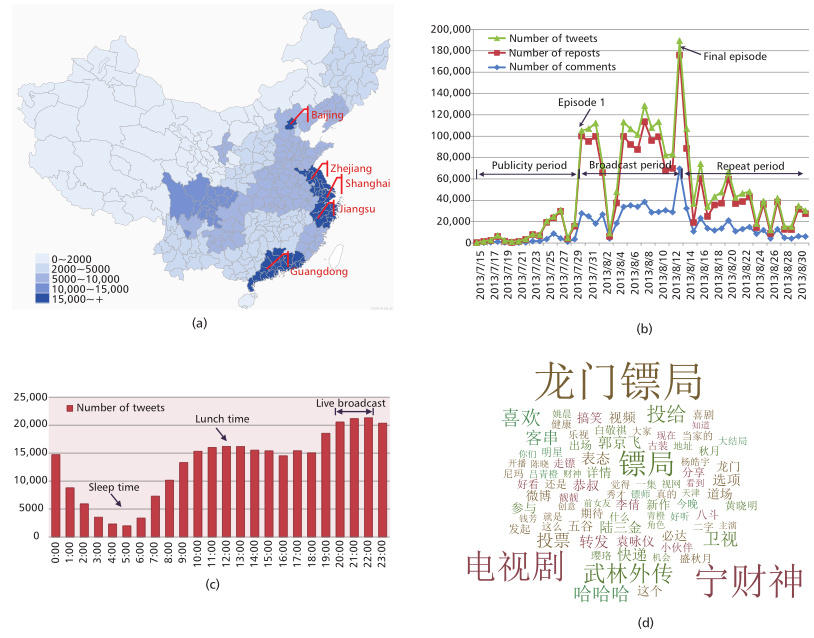
Conclusion
在这篇文章中,作者提出了一个以云为中心的社交电视分析的大数据平台,旨在挖掘TV节目的一些社交观点。
【
affinity 密切关系
】
Q:
MapReduce是什么?
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。通俗来说,MAP主要是处理原始的数据,即杂乱无章的数据,到了Reduce阶段,这些信息就有了相关性。我们在此基础之上做进一步的处理便可得到想要的结果。
shuffle state是什么?
Hadoop的shuffle过程就是从map端输出到reduce端输入之间的过程。





