本文主要是介绍语音驱动数字人唇形模型:SadTalker-Video-Lip-Sync,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 项目介绍
本项目基于SadTalkers实现视频唇形合成的Wav2lip。通过以视频文件方式进行语音驱动生成唇形,设置面部区域可配置的增强方式进行合成唇形(人脸)区域画面增强,提高生成唇形的清晰度。使用DAIN 插帧的DL算法对生成视频进行补帧,补充帧间合成唇形的动作过渡,使合成的唇形更为流畅、真实以及自然。
项目结构:
SadTalker-Video-Lip-Sync
├──checkpoints
| ├──BFM_Fitting
| ├──DAIN_weight
| ├──hub
| ├── ...
├──dian_output
| ├── ...
├──examples
| ├── audio
| ├── video
├──results
| ├── ...
├──src
| ├── ...
├──sync_show
├──third_part
| ├── ...
├──...
├──inference.py
├──README.md代码地址:https://github.com/Zz-ww/SadTalker-Video-Lip-Sync
2 项目部署与运行
2.1 conda环境准备
conda环境准备详见:annoconda
2.2 运行环境构建
git clone https://github.com/Zz-ww/SadTalker-Video-Lip-Sync.git
cd SadTalker-Video-Lip-Sync/conda create -n lipsyn python=3.8
conda activate lipsynpip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpegpip install -r requirements.txt
pip install ninjapython -m pip install paddlepaddle-gpu==2.3.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html2.3 预训练模型下载
预训练模型下载后,存储在checkpoints路径下:
【地址1】百度网盘:百度网盘 请输入提取码 提取码:klfv
【地址2】谷歌网盘:https://drive.google.com/file/d/1lW4mf5YNtS4MAD7ZkAauDDWp2N3_Qzs7/view?usp=sharing
【地址3】夸克网盘:夸克网盘分享 提取码:zMBP
下载完成后显示如下:
├──checkpoints
| ├──BFM_Fitting
| ├──DAIN_weight
| ├──hub
| ├──auido2exp_00300-model.pth
| ├──auido2pose_00140-model.pth
| ├──epoch_20.pth
| ├──facevid2vid_00189-model.pth.tar
| ├──GFPGANv1.3.pth
| ├──GPEN-BFR-512.pth
| ├──mapping_00109-model.pth.tar
| ├──ParseNet-latest.pth
| ├──RetinaFace-R50.pth
| ├──shape_predictor_68_face_landmarks.dat
| ├──wav2lip.pth2.4 启动项目推理
命令行格式如下:
python inference.py --driven_audio <audio.wav> \--source_video <video.mp4> \--enhancer <none,lip,face> \ #(默认lip)--use_DAIN \ #(使用该功能会占用较大显存和消耗较多时间)--time_step 0.5 #(插帧频率,默认0.5,即25fps—>50fps;0.25,即25fps—>100fps)使用示例:
python inference.py --driven_audio examples/driven_audio/demo.wav --source_video examples/driven_video/demo.mp4 --enhancer lip --use_DAIN --time_step 0.52.5 合成效果
#合成效果展示在./sync_show目录下:
#original.mp4 原始视频
#sync_none.mp4 无任何增强的合成效果
#none_dain_50fps.mp4 只使用DAIN模型将25fps添帧到50fps
#lip_dain_50fps.mp4 对唇形区域进行增强使唇形更清晰+DAIN模型将25fps添帧到50fps
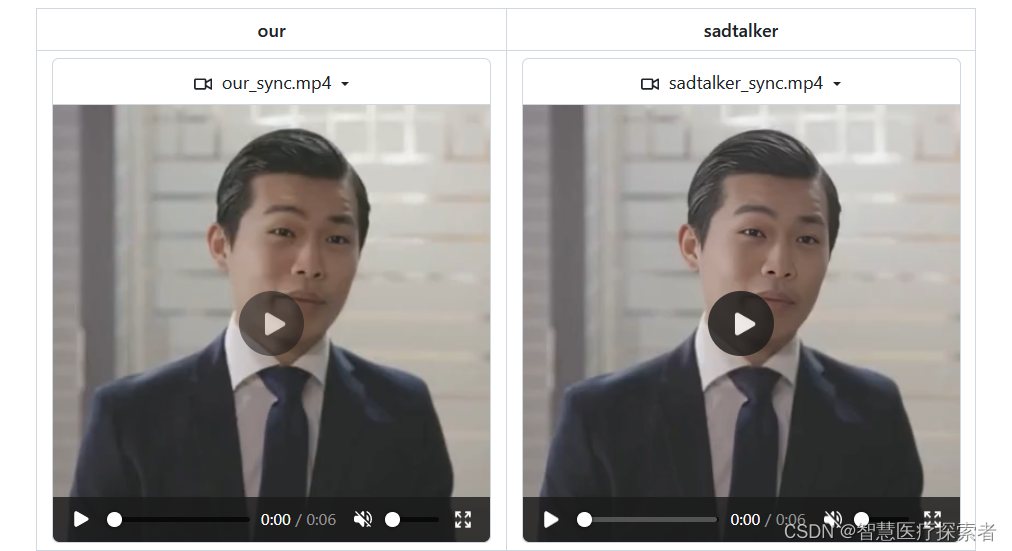
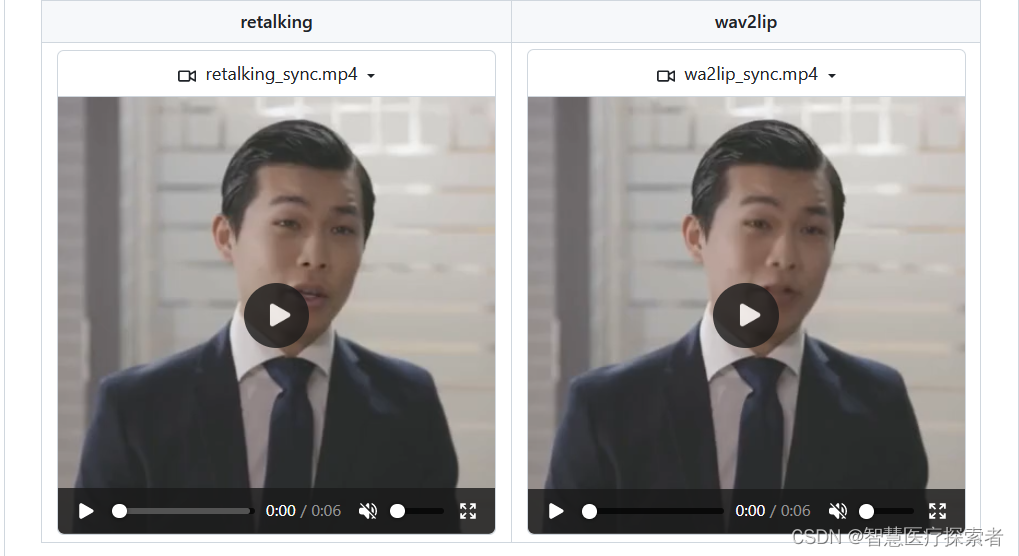
#face_dain_50fps.mp4 对全脸区域进行增强使唇形更清晰+DAIN模型将25fps添帧到50fps#下面是不同方法的生成效果的视频
#our.mp4 本项目SadTalker-Video-Lip-Sync生成的视频
#sadtalker.mp4 sadtalker生成的full视频
#retalking.mp4 retalking生成的视频
#wav2lip.mp4 wav2lip生成的视频典型的模型合成效果比较如下所示:
原始视频:63ad0daf14ce.mp4
sadtalker合成视频:2649ccd39616.mp4
video_retalking合成视频:f6b40070e2ca.mp4
wav2lip合成视频:a8285e728ecb.mp4
本模型合成视频:902cc7711b8a.mp4
3 问题解决
项目运行,出现错误提示:error: face_alignment.LandmarksType._2D,通过修改代码解决,解决方案如下:
vi src/face3d/extract_kp_videos.py self.detector = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, device=device)更改为:
self.detector = face_alignment.FaceAlignment(face_alignment.LandmarksType.TWO_D, device=device)这篇关于语音驱动数字人唇形模型:SadTalker-Video-Lip-Sync的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








