sadtalker专题

用SadTalker搭建数字的步骤
下载源码并安装依赖 git clone https://github.com/OpenTalker/SadTalker.gitcd SadTalker conda create -n sadtalker python=3.8conda activate sadtalkerpip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torch
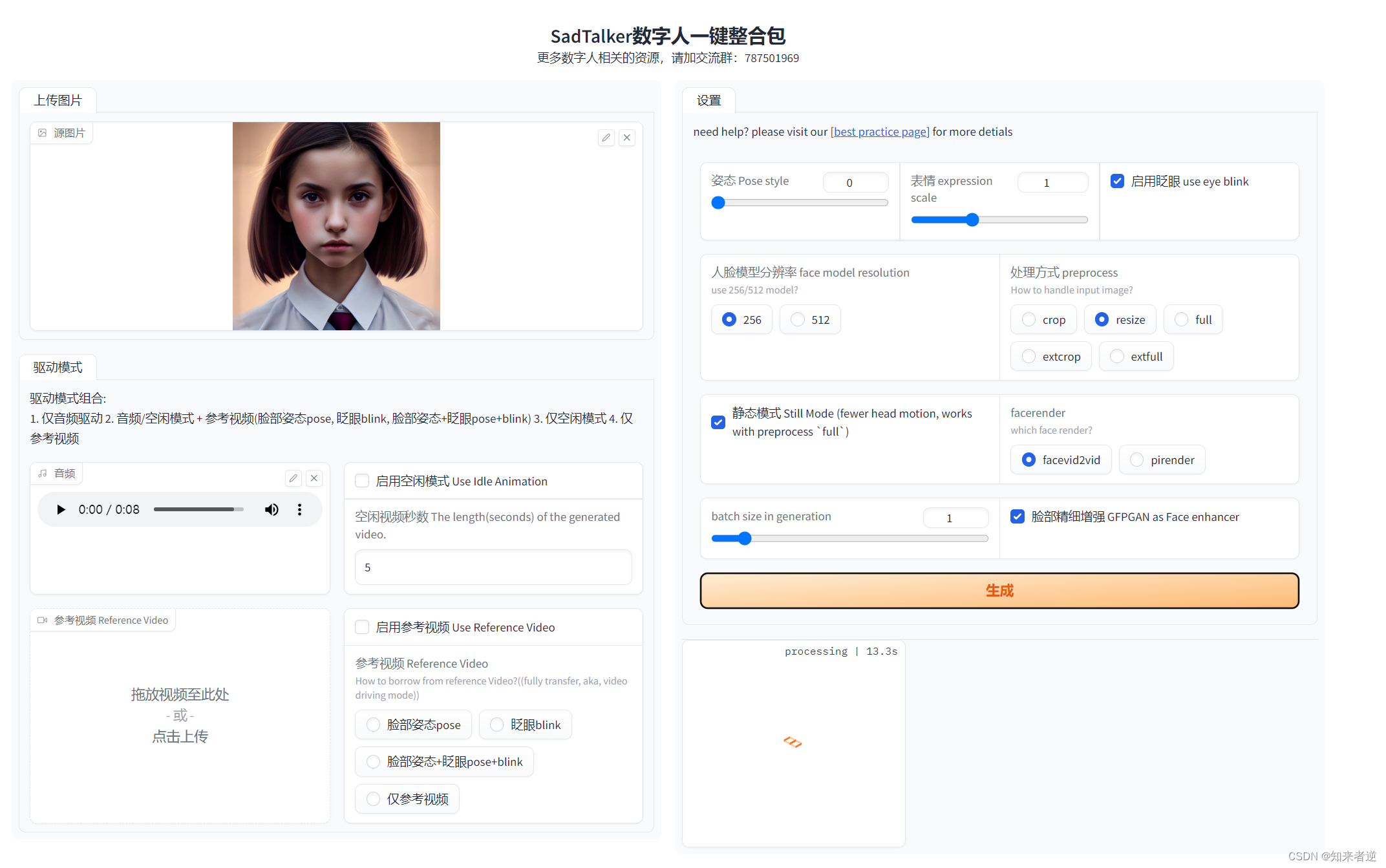
数字人解决方案— SadTalker语音驱动图像生成视频原理与源码部署
简介 随着数字人物概念的兴起和生成技术的不断发展,将照片中的人物与音频输入进行同步变得越来越容易。然而,目前仍存在一些问题,比如头部运动不自然、面部表情扭曲以及图片和视频中人物面部的差异等。为了解决这些问题,来自西安交通大学等机构的研究人员提出了 SadTalker 模型。 SadTalker 模型在三维运动场中学习如何从音频中生成3DMM的3D运动系数,包括头部姿势和表情,并利用全新的3D面
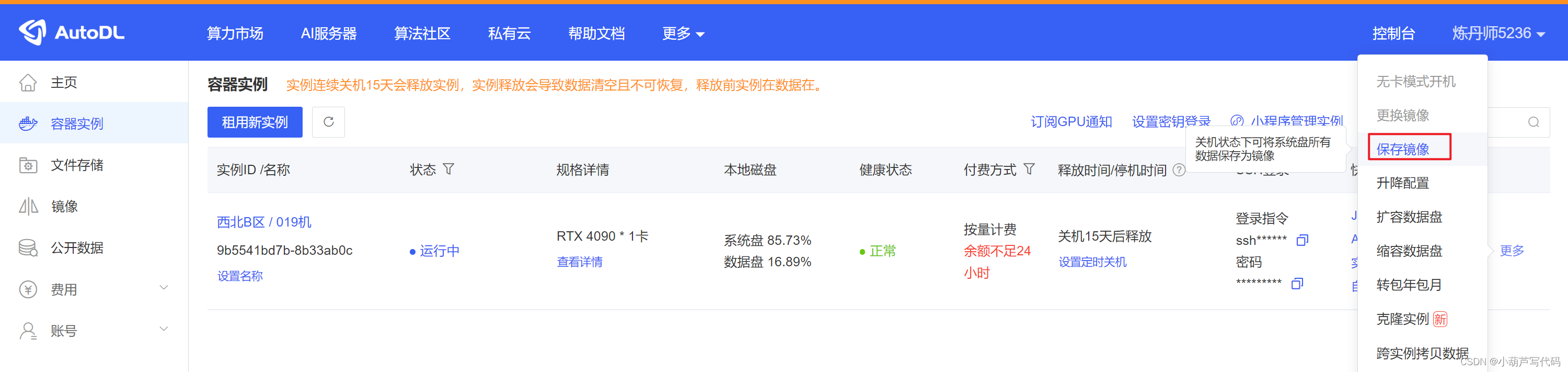
在autodl搭建stable-diffusion-webui+sadTalker
本文介绍在autodl.com搭建gpu服务器,实现stable-diffusion-webui+sadTalker功能,图片+音频 可生成视频。 autodl租GPU 自己本地部署SD环境会遇到各种问题,网络问题(比如huggingface是无法访问),所以最好的方式是租用GPU,可以通过以下视频了解如何使用autodl.com AutoDL算力云 | 弹性
stable-diffusion-webui+sadTalker开启GFPGAN as Face enhancer
接上一篇:在autodl搭建stable-diffusion-webui+sadTalker-CSDN博客 要开启sadTalker gfpgan as face enhancer, 需要将 1. stable-diffusion-webui/extensions/SadTalker/gfpgan/weights 目录下的文件拷贝到 :~/autodl-tmp/models/GF
如何本地部署虚拟数字克隆人 SadTalker
环境: Win10 SadTalker 问题描述: 如何本地部署虚拟数字克隆人 SadTalker 解决方案: SadTalker:学习逼真的3D运动系数,用于风格化的音频驱动的单图像说话人脸动画 单张人像图像🙎 ♂️+音频🎤=会说话的头像视频🎞 一、底层安装 安装 Anaconda、python 和 git 1.下载安装Anaconda conda是一个开源的软件
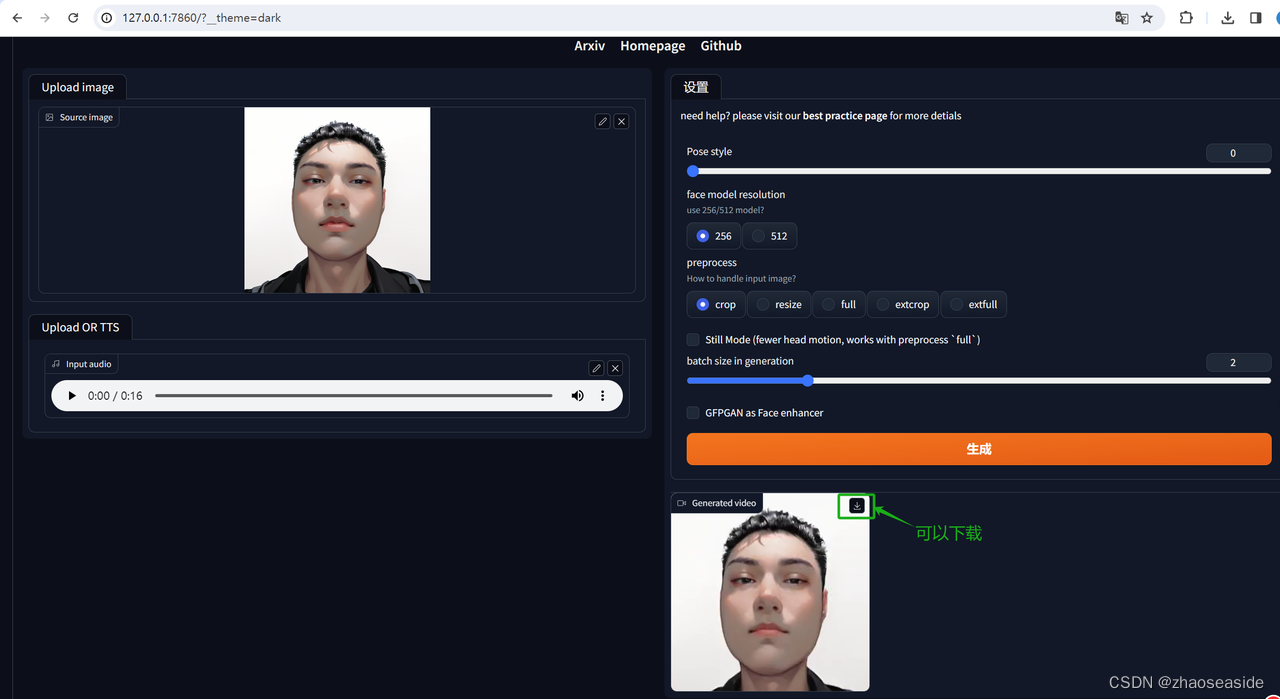
尝试着在Stable Diffusion里边使用SadTalker进行数字人制作
首先需要标明的是,我这里是图片说话类型,而且是看了知识星球AI破局俱乐部大航海数字人手册进行操作的。写下这篇文章是防止我以后遗忘。 我使用的基础软件是Stable Diffusion,SadTalker是作为插件放进来的,需要注意的是这对自己的电脑GPU要求比较高,至少需要8G,至少我的电脑是8G显存。 下载并安装ffmpeg 下载并安装ffmpeg,这一步的作用是语音格式的各种转换,虚拟数字

Sadtalker代码详解
目录 (一)裁剪以及3DMM(CropAndExtract()) def crop(self, img_np_list, still=False, xsize=512) (a) get_landmark(self, img_np) (b) align_face(self, img, lm, output_size=1024) 3DMM (二)读取逐帧计算的参考系数 API: reference_
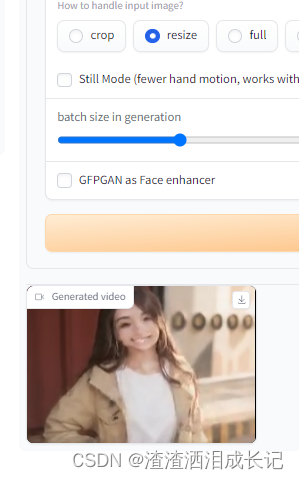
教你用SadTalker一键整合包轻松制作专属数字人
数字人的效果: 🎵我用SadTalker制作了专属虚拟数字人,还会唱歌哦,多多点赞关注就出教程呦💗 SadTalker有独立离线版Ai数字人,也可以在Stable Diffusion以插件的形式使用,但是如果显卡小的话还是建议使用独立版,毕竟Stable Diffusion也要占用显卡。 我在逛B站时,找到了一键整合包,直接下载双击启动就可以使用,非常方便,那么安装包可以如下方
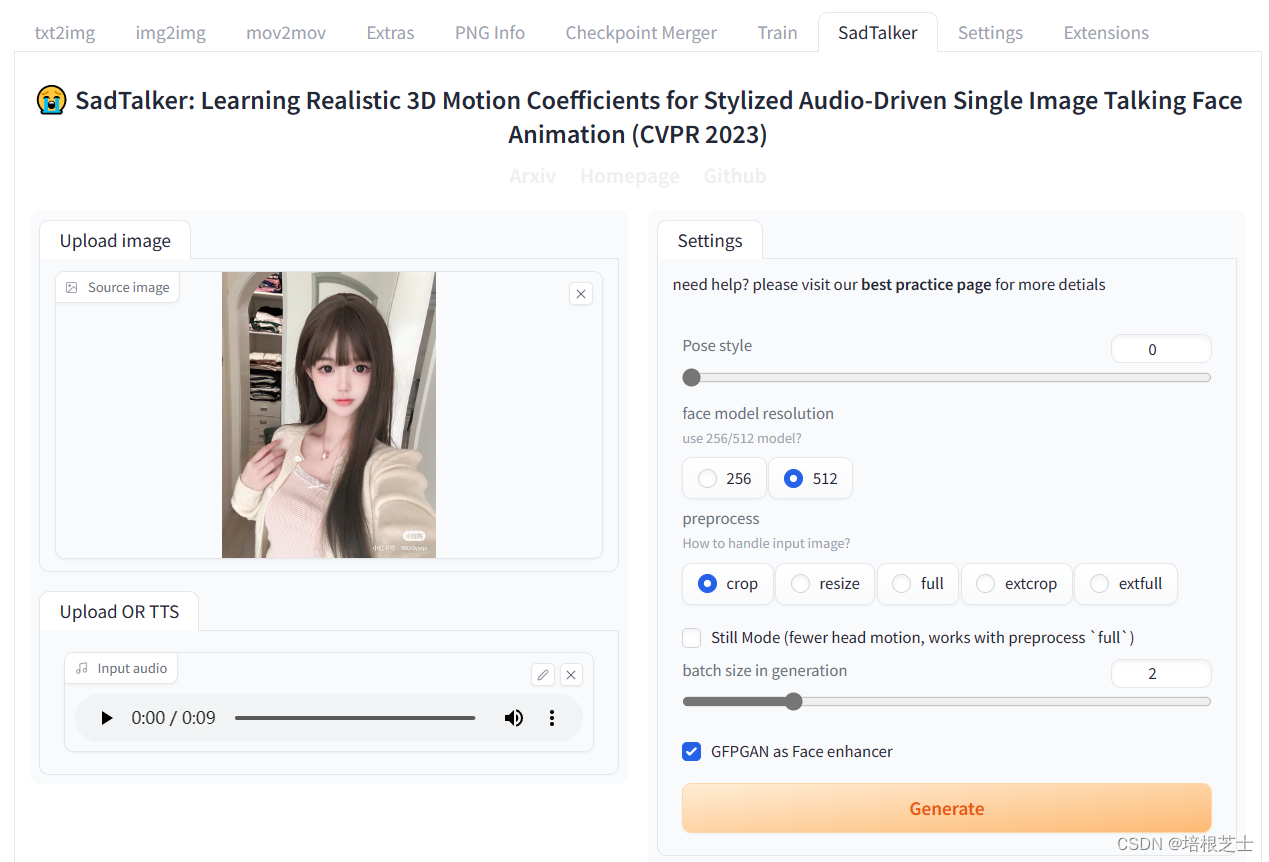
Stable Diffusion WebUI安装合成面部说话插件SadTalker
SadTalker可以根据一张图片、一段音频,合成面部说这段语音的视频。图片需要真人或者接近真人。 安装ffmpeg 下载地址: https://www.gyan.dev/ffmpeg/builds/ 下载ffmpeg-git-full.7z 后解压,将解压后的目录\bin添加到环境变量的Path中。 在终端输入ffmpeg命令,查看ffmpeg是否安装成功。 安装SadTa

SadTalker数字人增加视频输出mp4质量精度
最近在用数字人简易方案,看到了sadtalker虽然效果差,但是可以作为一个快速方案,没有安装sd的版本,随便找了个一键安装包 设置如上 使用倒是非常简单,但是出现一个问题,就是输出的mp4都出马赛克了 界面上却没有一个可以调节mp4生成质量的地方(并非换脸效果), 先说结论 进入SadTalker\src\utils修改videoio.py cmd = r'ffmpeg -

南洋才女,德艺双馨,孙燕姿本尊回应AI孙燕姿(基于Sadtalker/Python3.10)
孙燕姿果然不愧是孙燕姿,不愧为南洋理工大学的高材生,近日她在个人官方媒体博客上写了一篇英文版的长文,正式回应现在满城风雨的“AI孙燕姿”现象,流行天后展示了超人一等的智识水平,行文优美,绵恒隽永,对AIGC艺术表现得极其克制,又相当宽容,充满了语言上的古典之美,表现出了“任彼如泰山压顶,我只当清风拂面”的博大胸怀。 本次我们利用edge-tts和Sadtalker库让AI孙燕姿朗诵本尊的博文,让
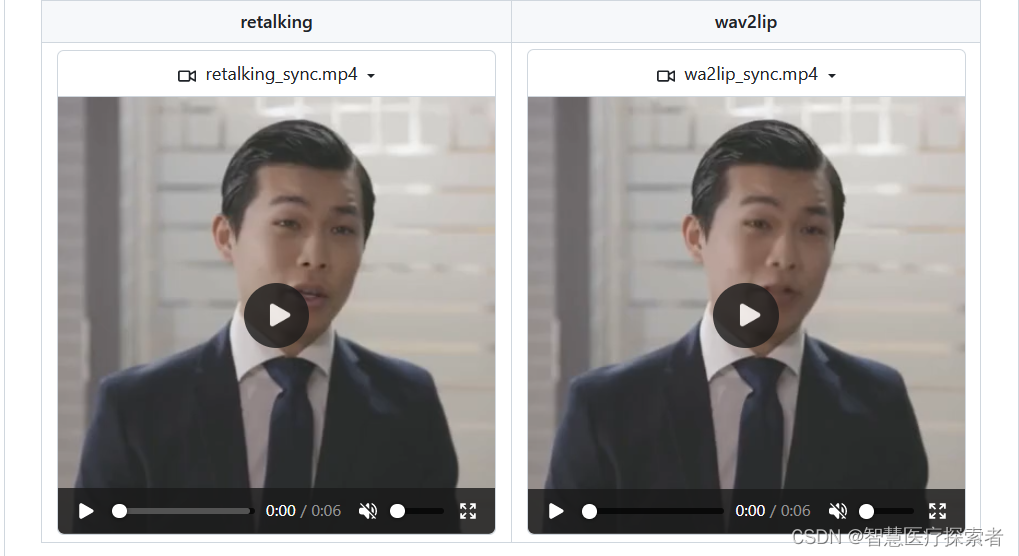
语音驱动数字人唇形模型:SadTalker-Video-Lip-Sync
1 项目介绍 本项目基于SadTalkers实现视频唇形合成的Wav2lip。通过以视频文件方式进行语音驱动生成唇形,设置面部区域可配置的增强方式进行合成唇形(人脸)区域画面增强,提高生成唇形的清晰度。使用DAIN 插帧的DL算法对生成视频进行补帧,补充帧间合成唇形的动作过渡,使合成的唇形更为流畅、真实以及自然。 项目结构: SadTalker-Video-Lip-Sync├──check
3D人脸重构论文汇总【PV3D\EG3D\AvatarGen\Face2FaceRHO\RODIN\DCFace\SadTalker\NeuFace\Next3D\SCULPT\HumanLiff等】
目录 《Face2FaceRHO: Real-Time High-Resolution One-Shot Face Reenactment》 《RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion》 《DCFace: Synthetic Face Generation with Dual Cond
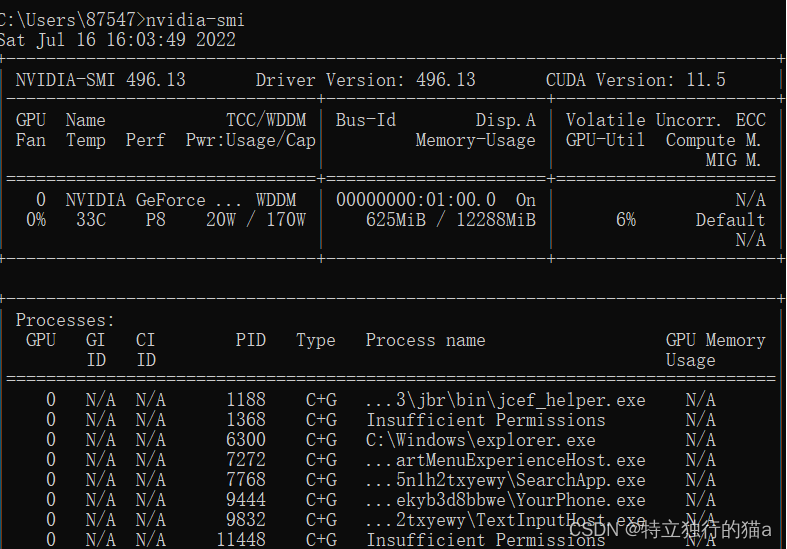
让照片人物开口说话,SadTalker 安装及使用(避坑指南)
AI技术突飞猛进,不断的改变着人们的工作和生活。数字人直播作为新兴形式,必将成为未来趋势,具有巨大的、广阔的、惊人的市场前景。它将不断融合创新技术和跨界合作,提供更具个性化和多样化的互动体验,成为未来的一种趋势。 SadTalker介绍 西安交通大学开源了人工智能SadTaker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质
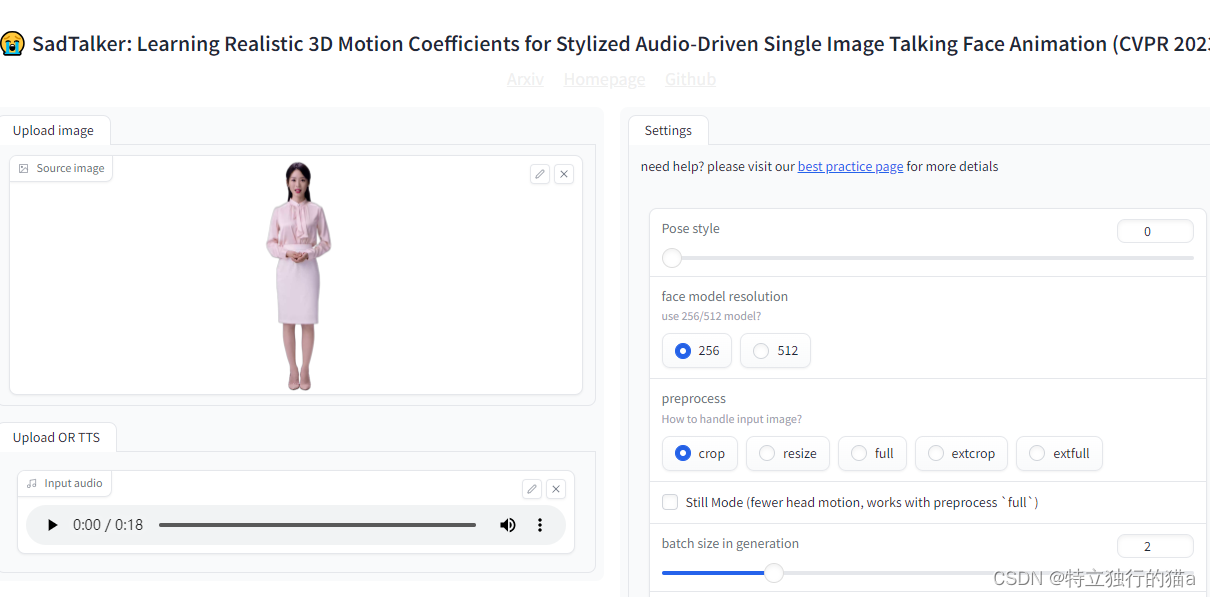
让照片人物开口说话,SadTalker 安装及使用(避坑指南)
AI技术突飞猛进,不断的改变着人们的工作和生活。数字人直播作为新兴形式,必将成为未来趋势,具有巨大的、广阔的、惊人的市场前景。它将不断融合创新技术和跨界合作,提供更具个性化和多样化的互动体验,成为未来的一种趋势。 SadTalker介绍 西安交通大学开源了人工智能SadTaker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质