本文主要是介绍尝试着在Stable Diffusion里边使用SadTalker进行数字人制作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先需要标明的是,我这里是图片说话类型,而且是看了知识星球AI破局俱乐部大航海数字人手册进行操作的。写下这篇文章是防止我以后遗忘。
我使用的基础软件是Stable Diffusion,SadTalker是作为插件放进来的,需要注意的是这对自己的电脑GPU要求比较高,至少需要8G,至少我的电脑是8G显存。
下载并安装ffmpeg
下载并安装ffmpeg,这一步的作用是语音格式的各种转换,虚拟数字人能开口说话,需要我们上传自己的语音,如果格式不符合会自动转换。
到https://ffmpeg.org/download.html选择自己操作系统然后选择下载格式。
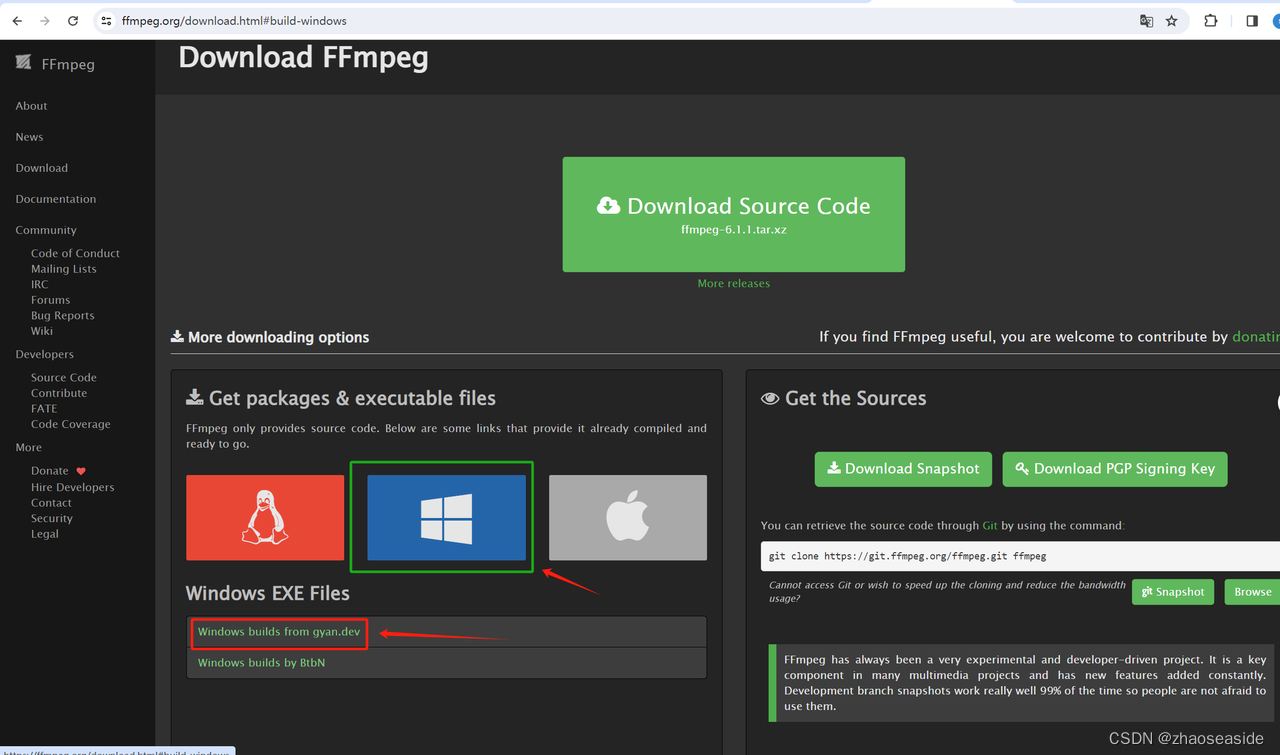
选择下载的类型,我选择全量版的。
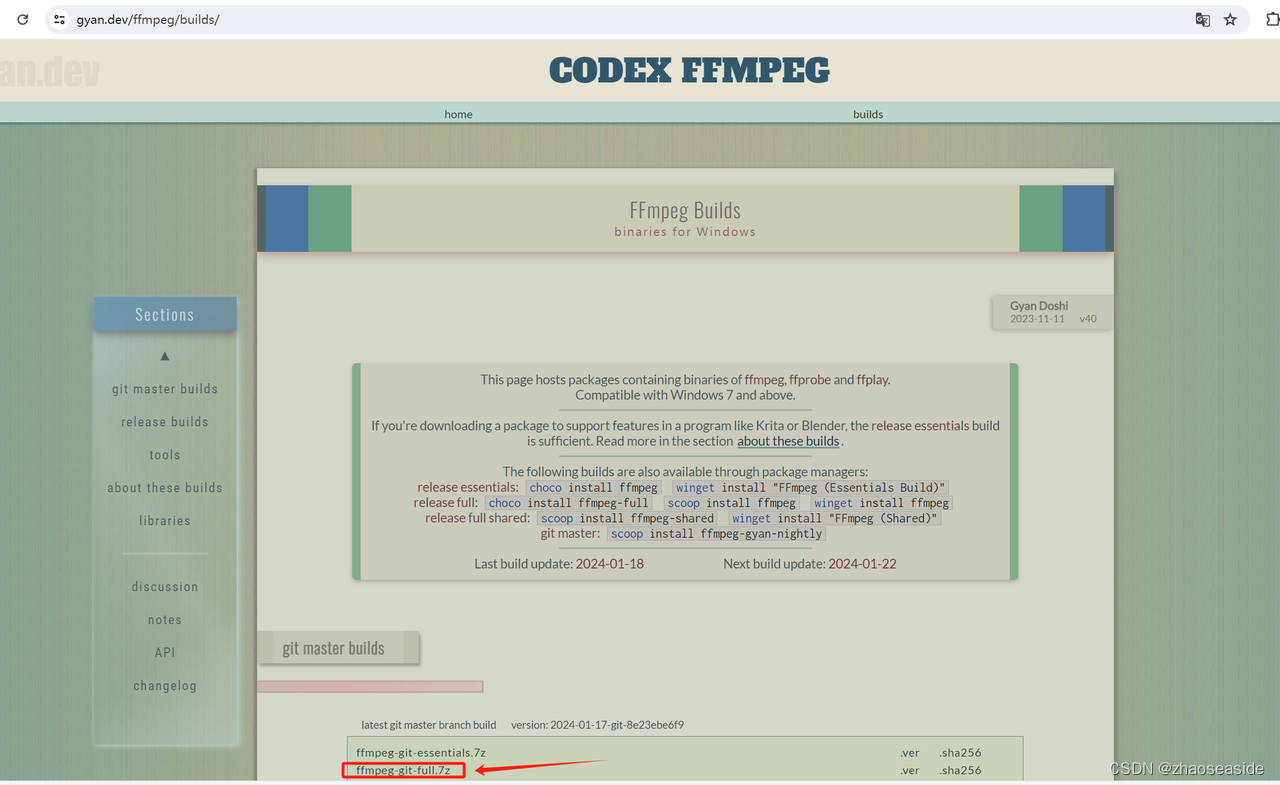
然后我解压到D:\VideoSoft目录下。
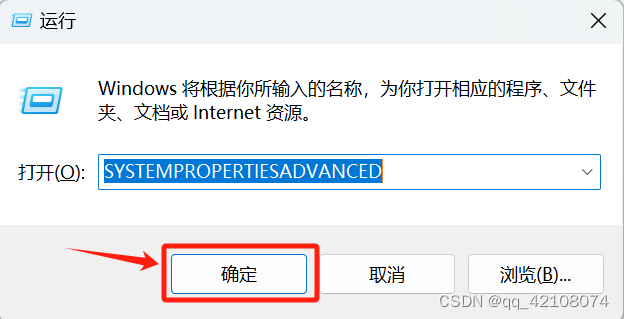
需要配置环境变量了。
Windows+r同时按下,然后输入SYSTEMPROPERTIESADVANCED,然后点击确定。
然后选择高级,点击环境变量。
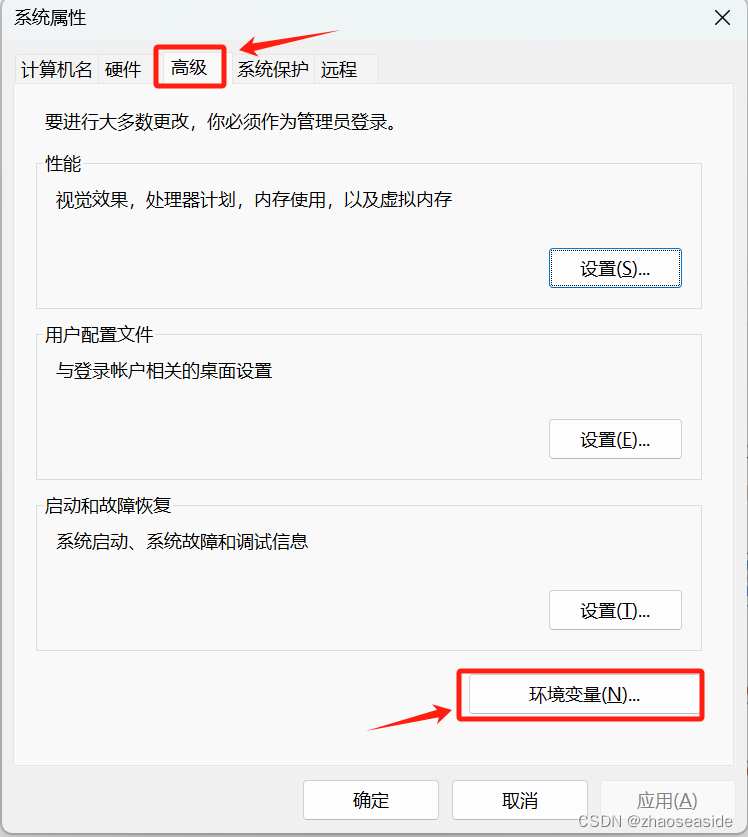
选择Path,然后点击编辑。
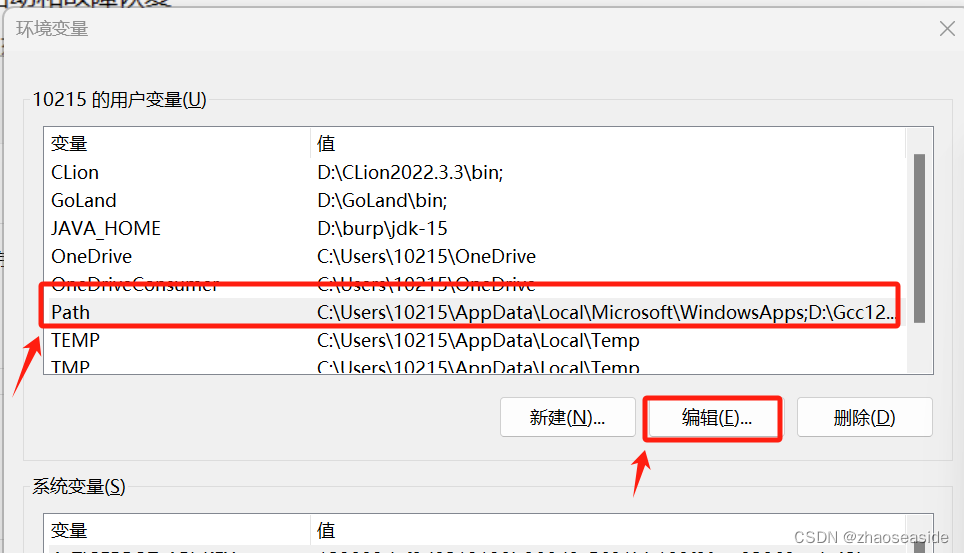
然后点击新建。
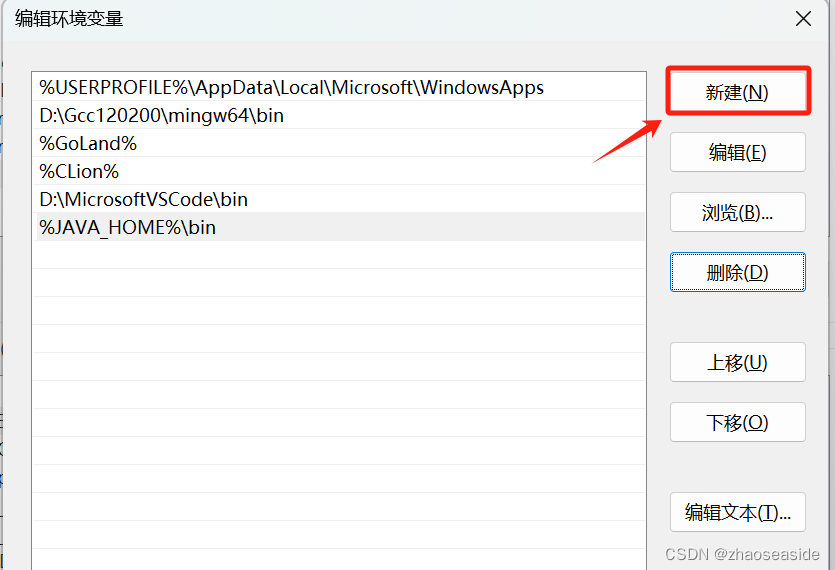
把你上边解压的目录找到bin那级的目录放到环境变量里边,然后点击确定。
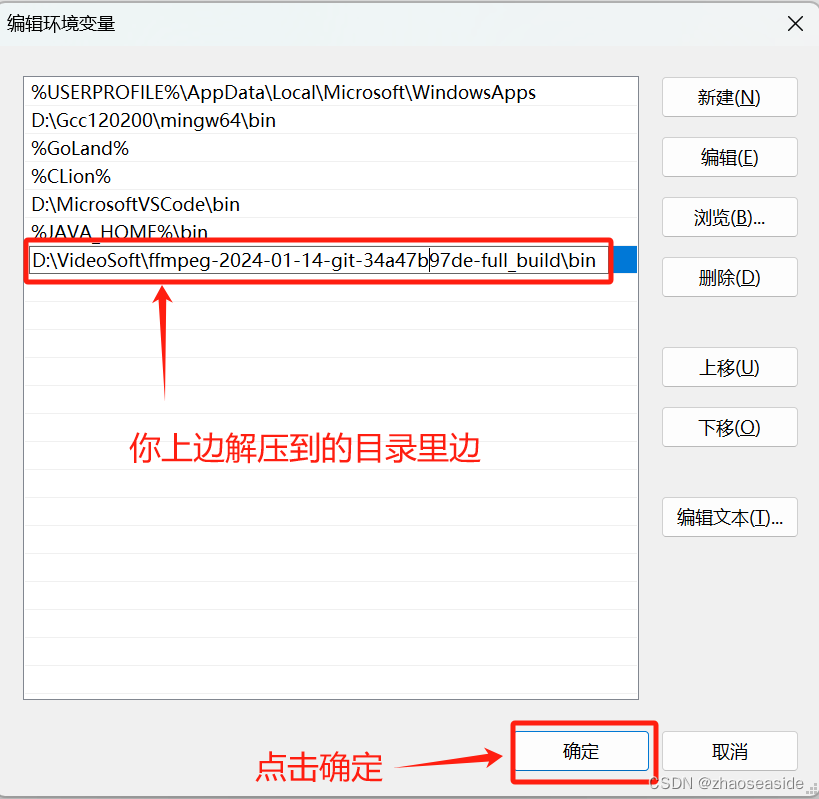
把上一级窗口也点击确定。
系统属性这一级窗口也点击确定。
然后同时按下Windows+r,输入cmd然后按下确定键。
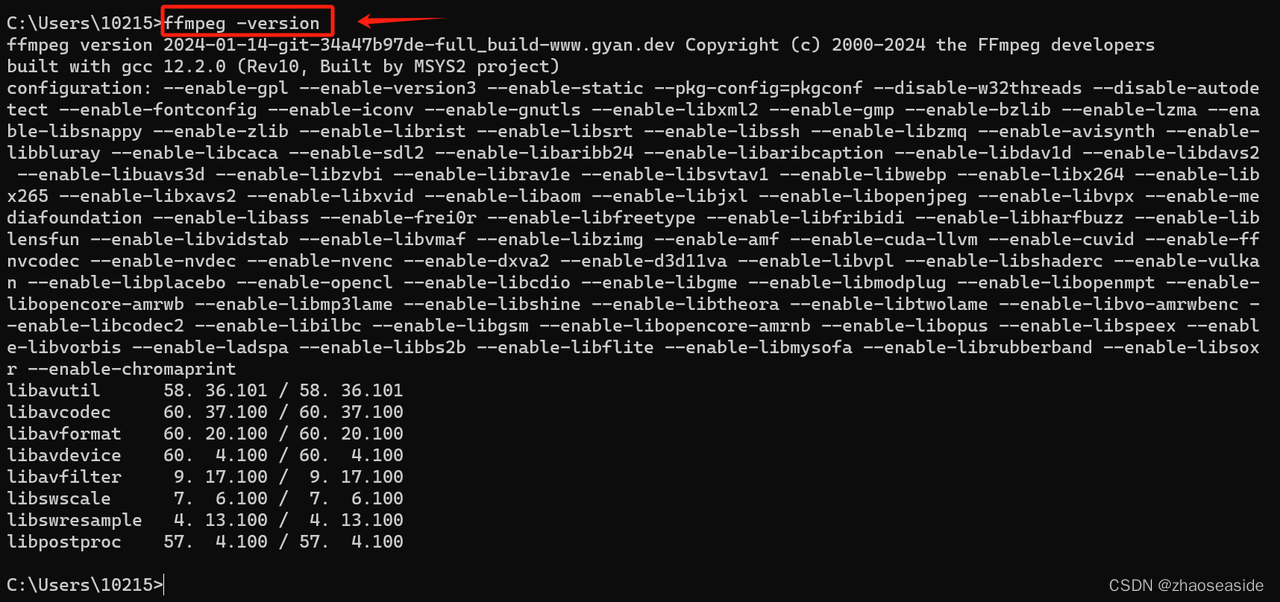
然后输入ffmpeg -version,要是显示出来很多内容,那么就是正常安装好了。
Stable Diffusion安装插件
我使用的Stable Diffusion是秋叶版的。
下载扩展
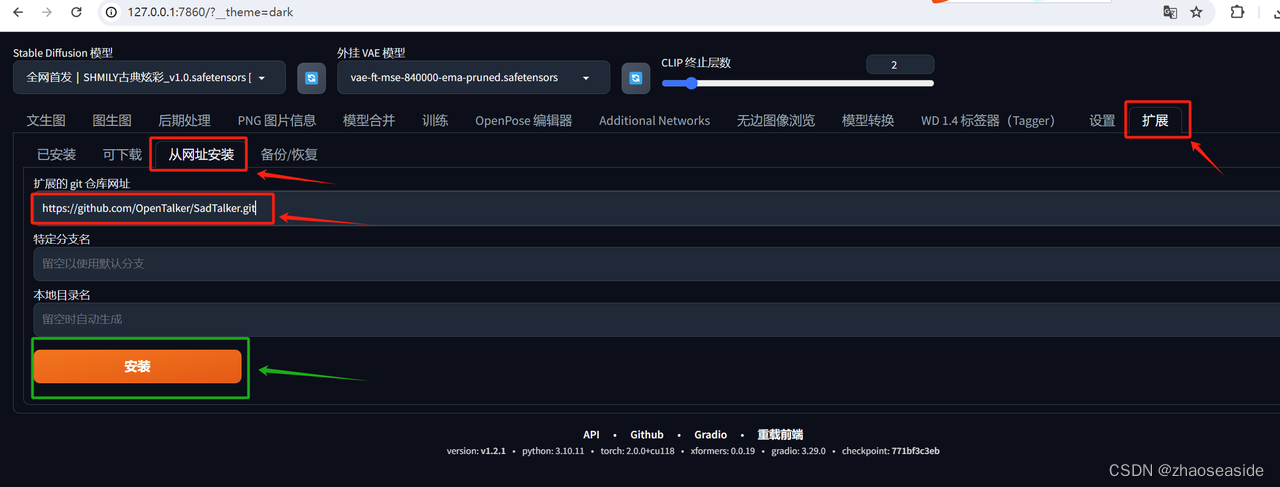
点击扩展,选择从网址安装,然后把git仓库https://github.com/OpenTalker/SadTalker.git放入指定的位置,然后点击安装。
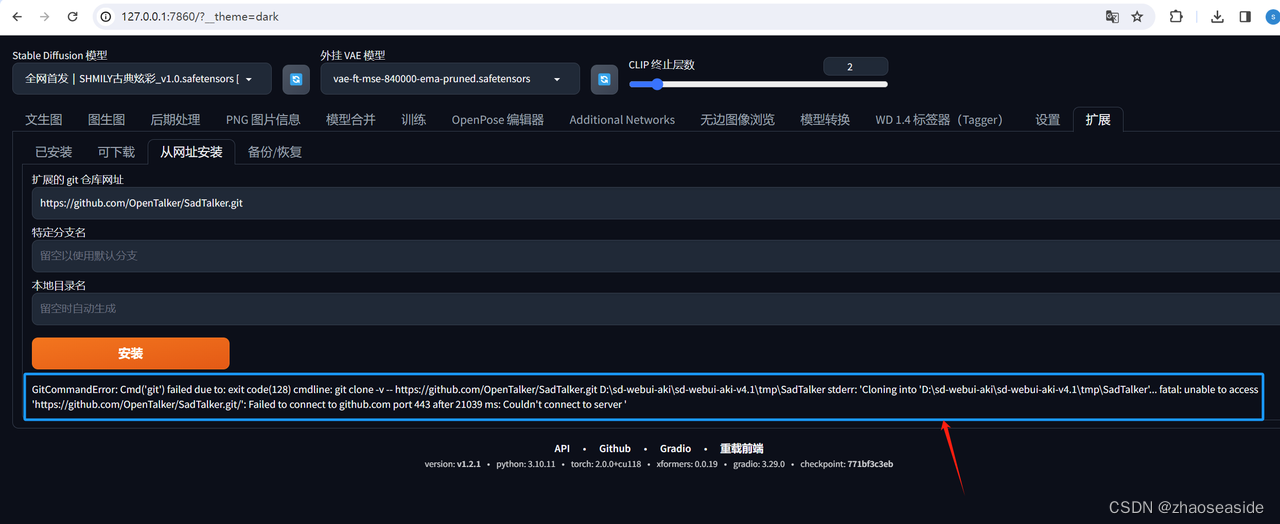
发现报错如下:
GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git clone -v -- https://github.com/OpenTalker/SadTalker.git D:\sd-webui-aki\sd-webui-aki-v4.1\tmp\SadTalker stderr: 'Cloning into 'D:\sd-webui-aki\sd-webui-aki-v4.1\tmp\SadTalker'... fatal: unable to access 'https://github.com/OpenTalker/SadTalker.git/': Failed to connect to github.com port 443 after 21039 ms: Couldn't connect to server '
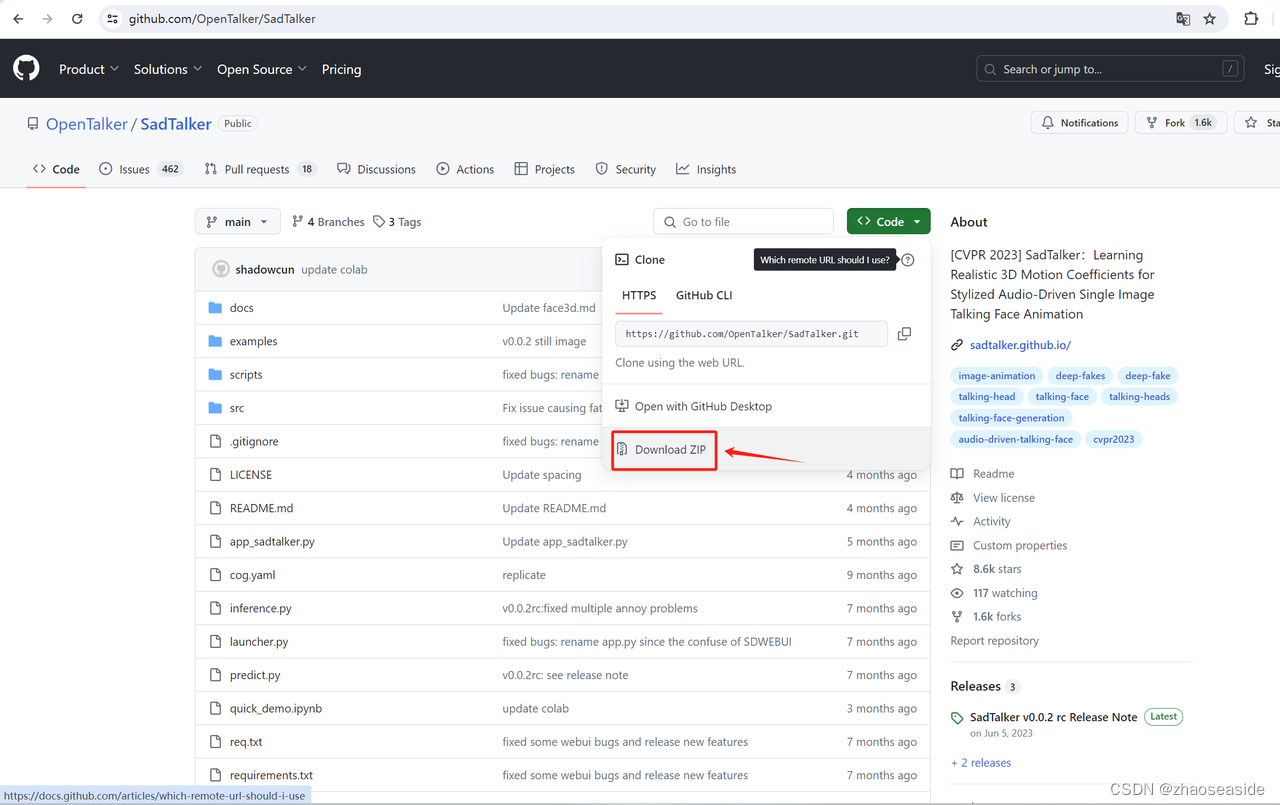
我到https://github.com/OpenTalker/SadTalker里边,下载源代码的zip包。
然后把压缩包解压至Stable Diffusion启动器所在的目录下一级目录extensions里边,目录如下所示。
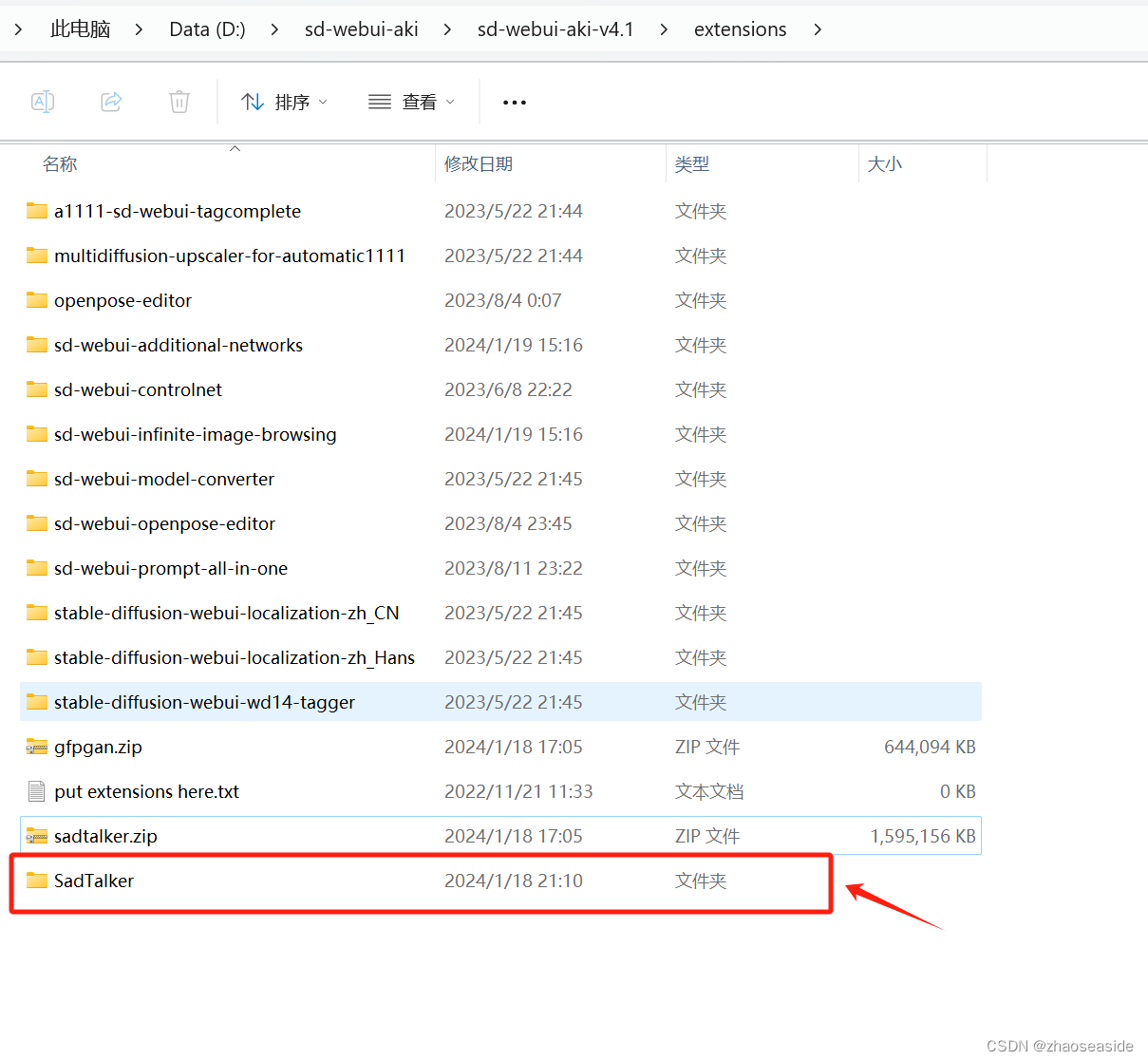
checkpoint文件下载和配置,
需要到https://github.com/OpenTalker/SadTalker/releases,下载以下四个文件。
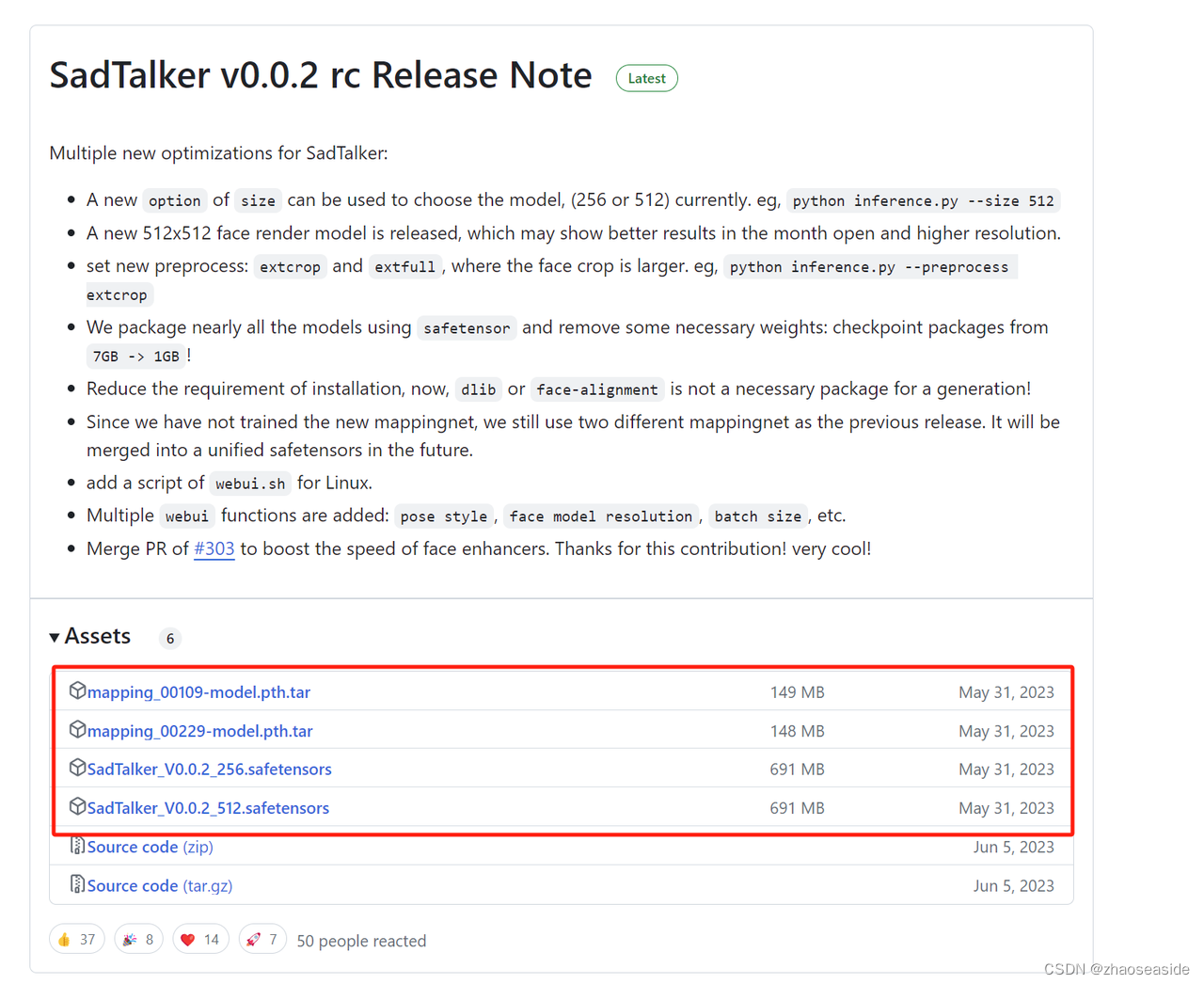
然后当前网页上边,往下滑动,点开Assets,然后下载红圈中的文件。
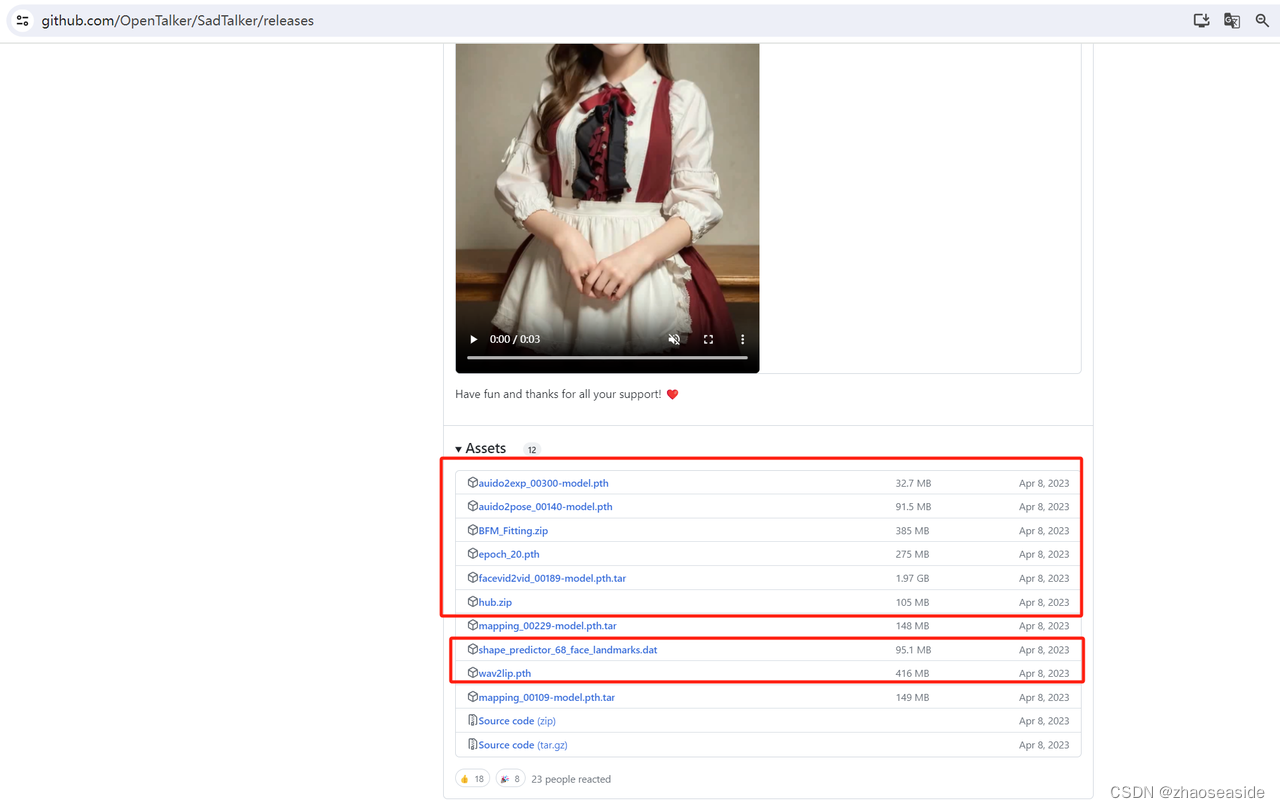
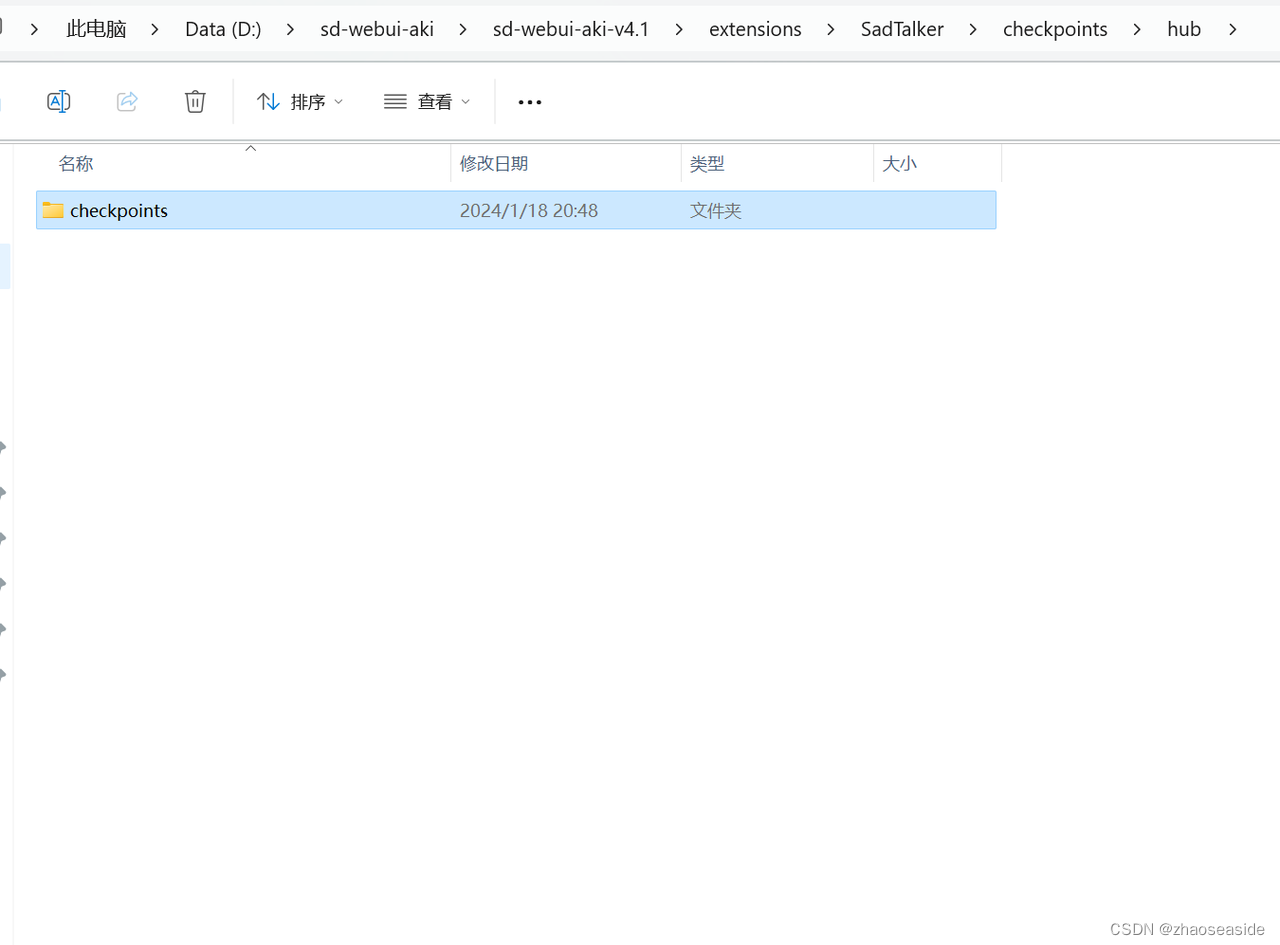
将上边下载好的文件放入到自己D:\sd-webui-aki\sd-webui-aki-v4.1\extensions\SadTalker\checkpoints里边,很有可能,你没有checkpoints这个目录,自己新建一个就行了。
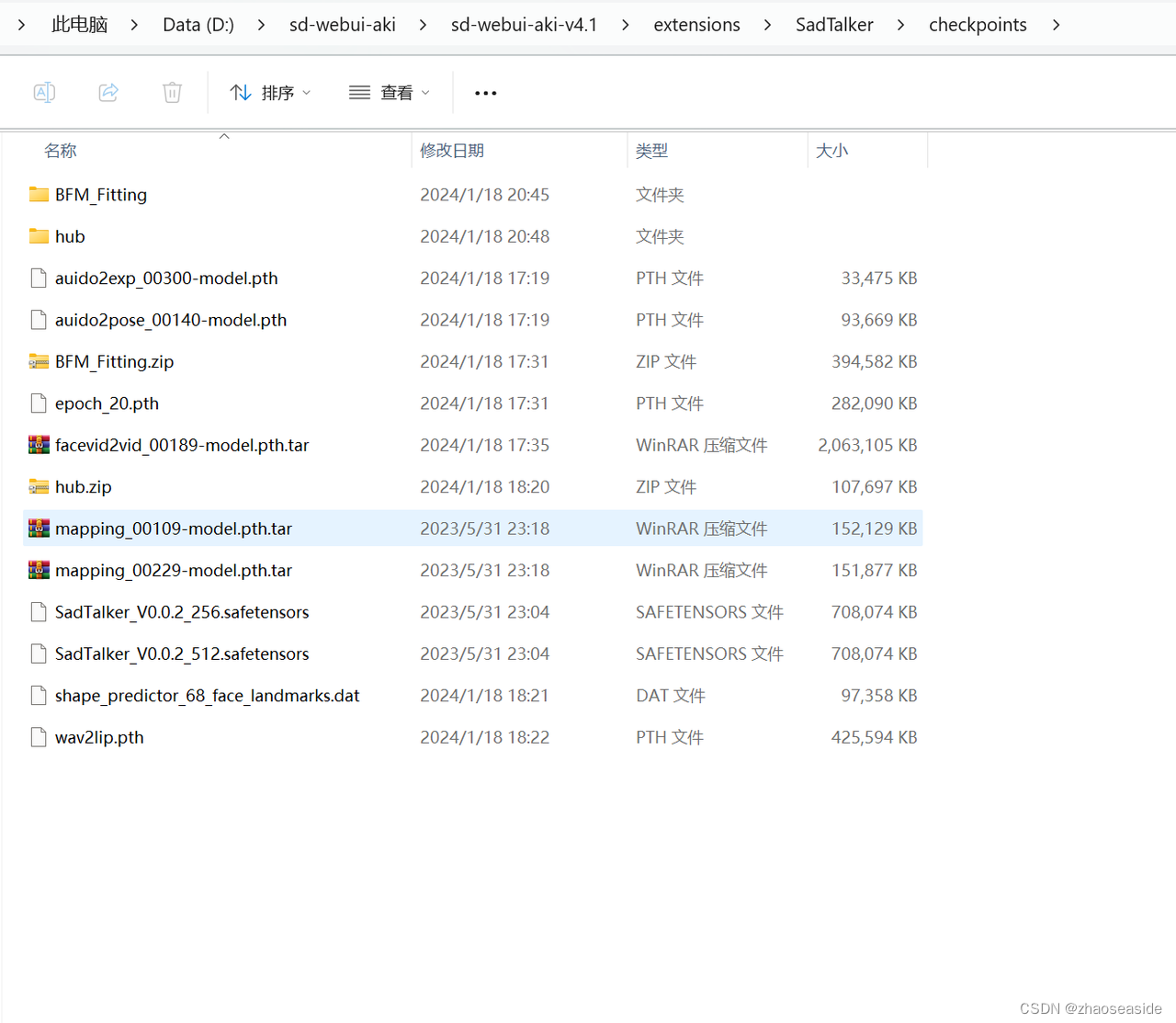
另外hub.zip需要解压。
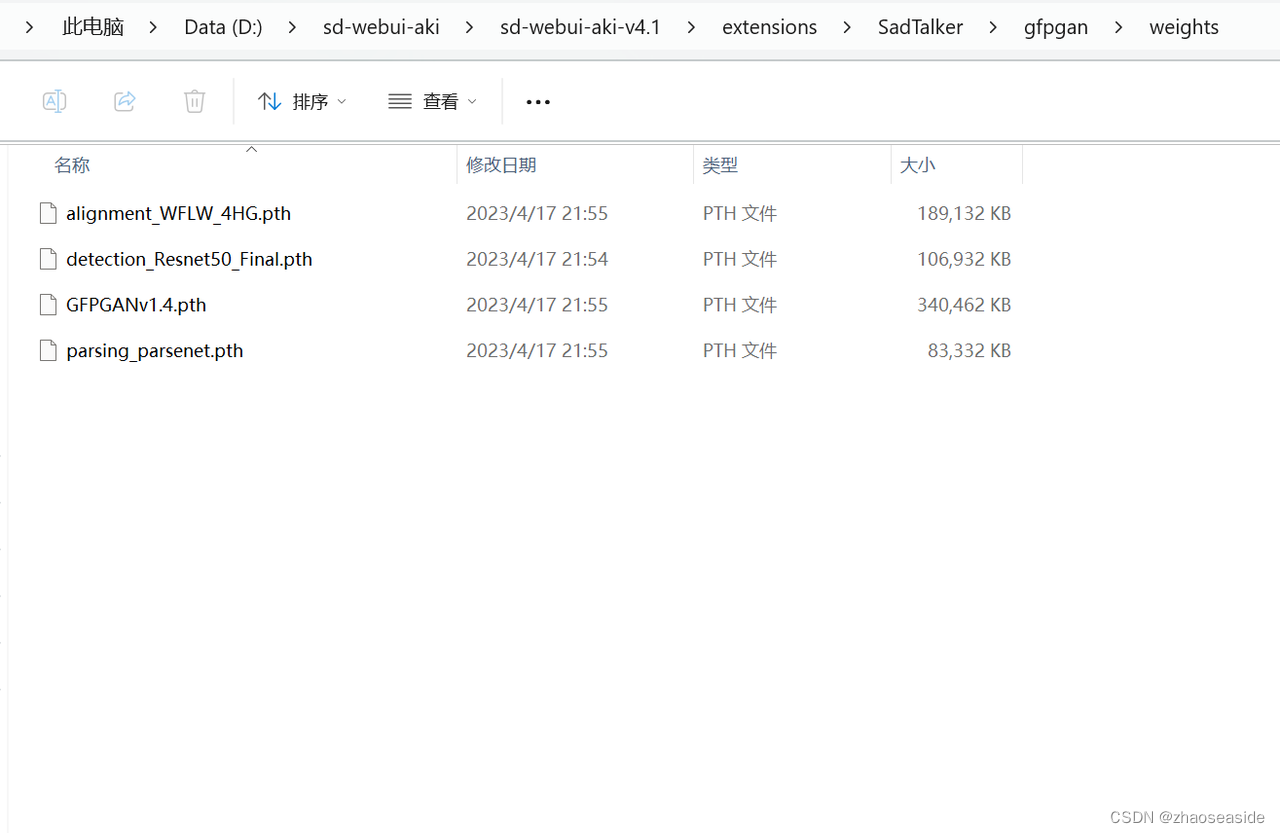
下载GFPGAN模型
到https://drive.google.com/file/d/19AIBsmfcHW6BRJmeqSFlG5fL445Xmsyi下载文件解压到D:\sd-webui-aki\sd-webui-aki-v4.1\extensions\SadTalker里边。
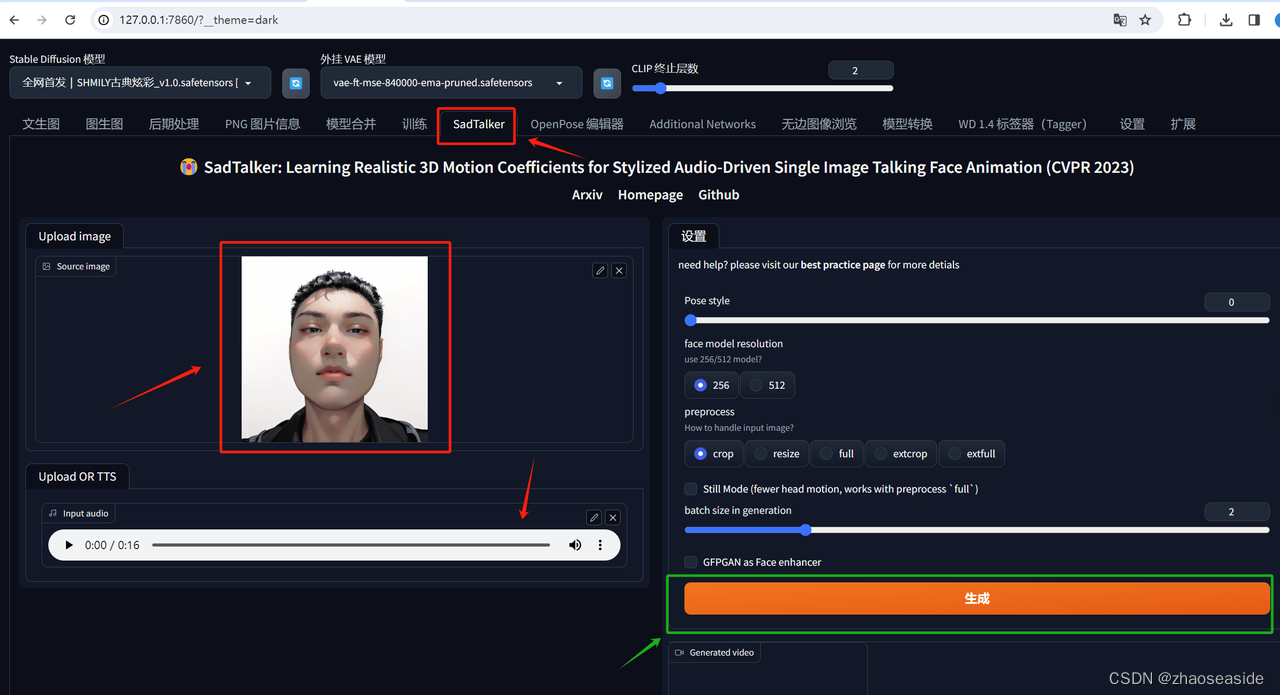
接下来就是重新启动Stable Diffusion进行画图了。点击SadTalker,然后上传图片,之后上传音频,然后点击生成。
需要等待。
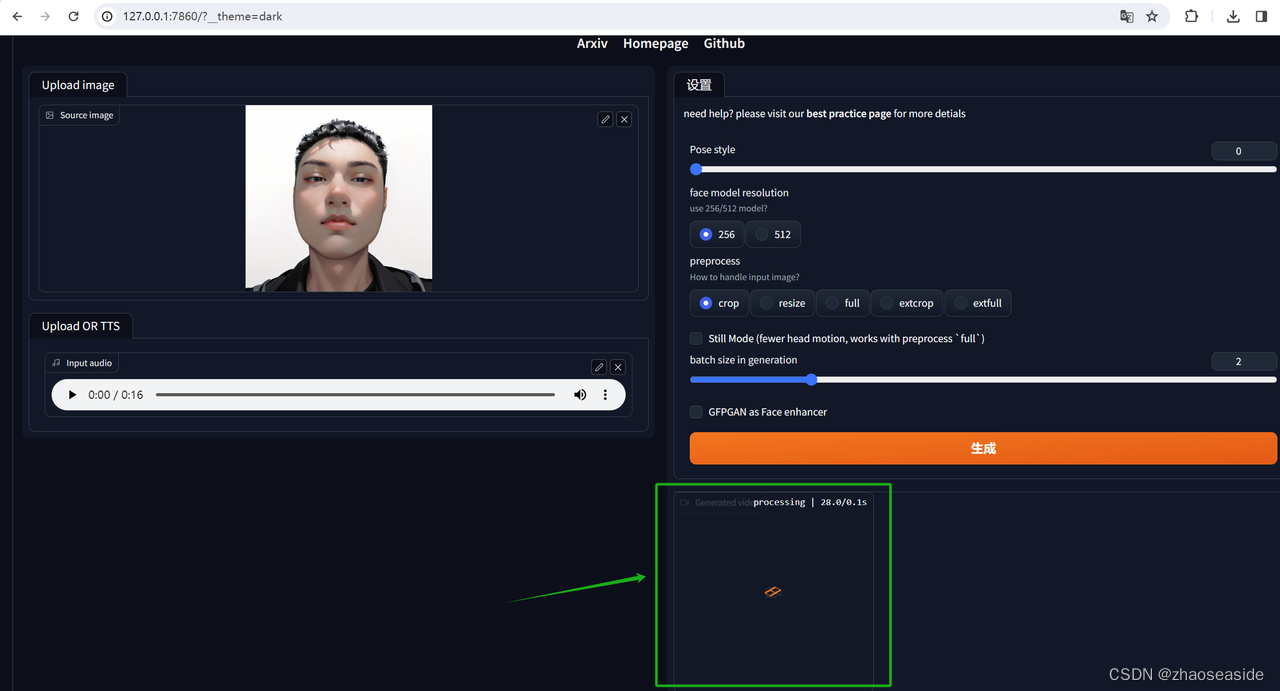
生成之后如下图:
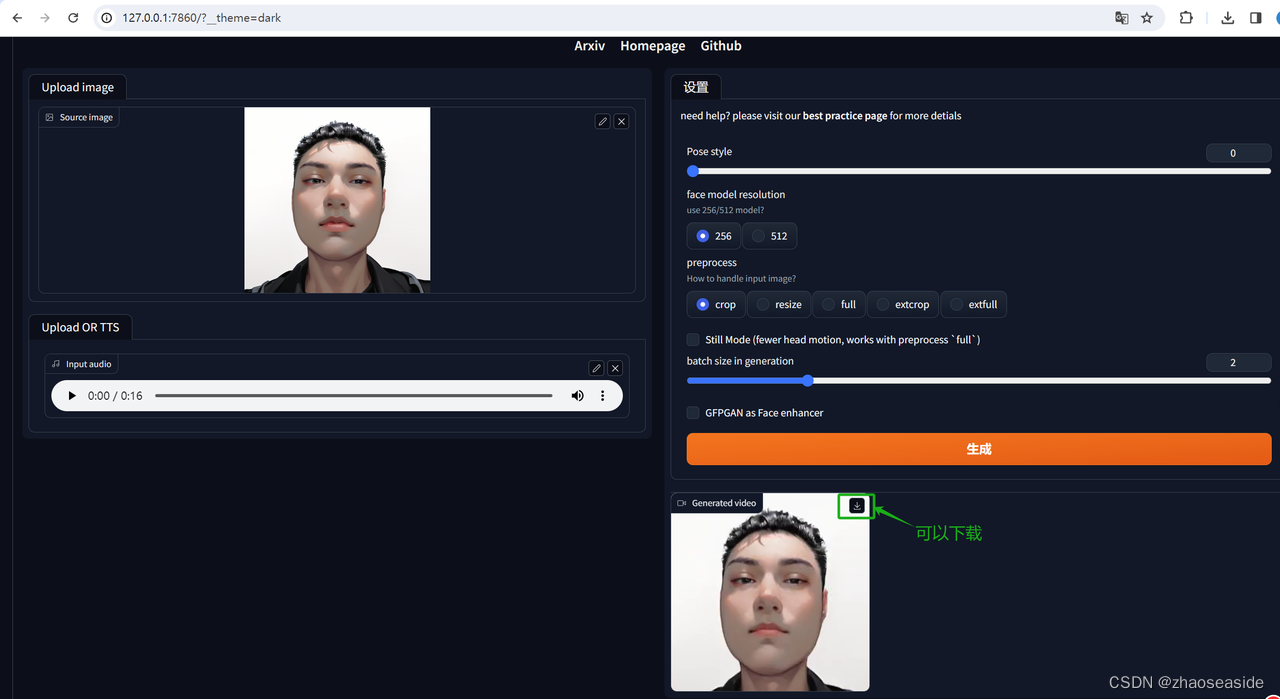
无法上传视频,没有办法展示效果了。
我是知识星球上约有3万人的AI破局俱乐部初创合伙人,我的微信号是zhaoseaside,欢迎大家加我,相互学习AI知识和个人IP知识,毕竟这是未来两大风口。
大家要是需要文档中的文件,可以加我备注SadTalker,我用百度网盘发给你。
这篇关于尝试着在Stable Diffusion里边使用SadTalker进行数字人制作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





