本文主要是介绍MATLAB数据预测程序。 人工智能算法:包括但不限于lstm神经网络,BP神经网络,RBF以及Elman等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MATLAB数据预测程序。
人工智能算法:包括但不限于lstm神经网络,BP神经网络,RBF以及Elman等。
传统经济学:ARIMA,GM灰色预测等均有。
学习研究均可,具体效果视实验数据好坏二轮。
部分有注释,有原始数据。
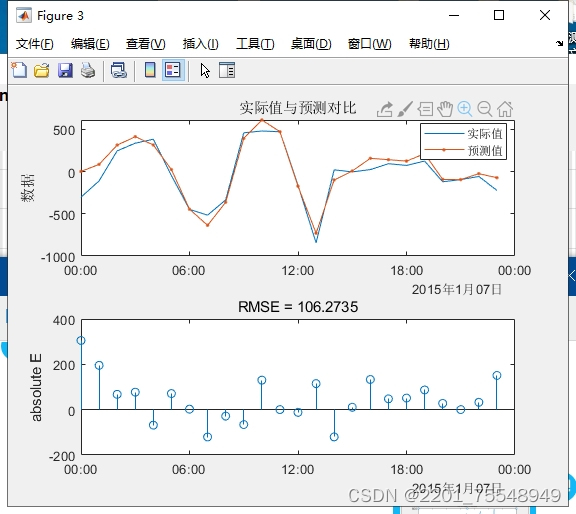
ID:14100638745449316
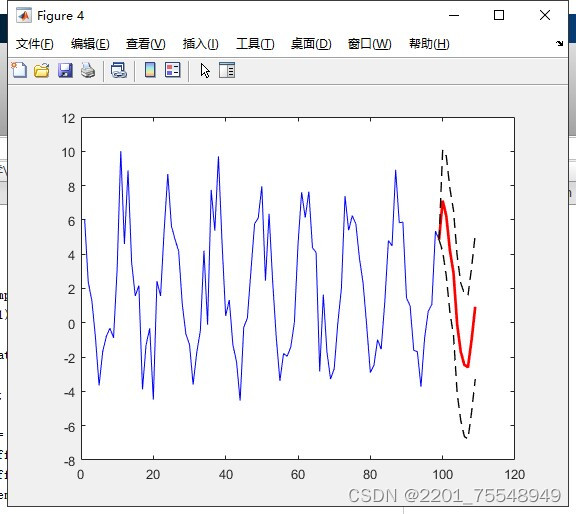
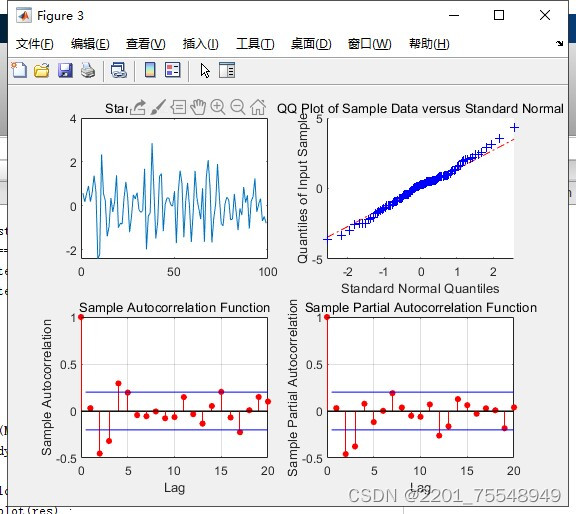
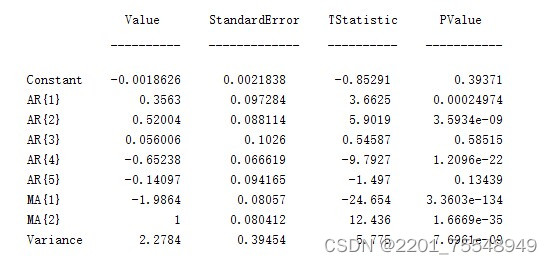
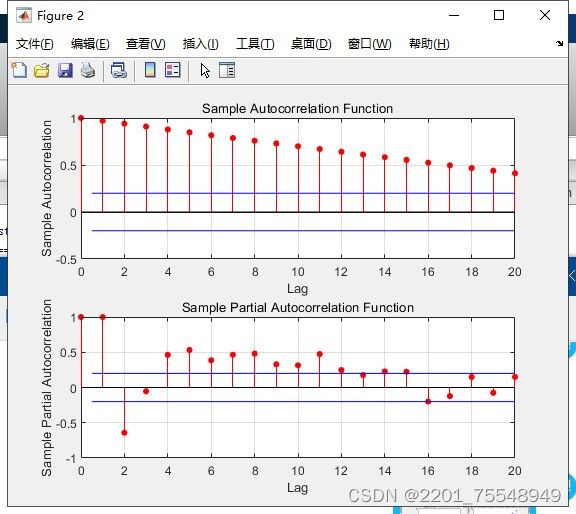
这篇关于MATLAB数据预测程序。 人工智能算法:包括但不限于lstm神经网络,BP神经网络,RBF以及Elman等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







