本文主要是介绍【ARXIV2211】Efficient multi-order gated aggregation network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

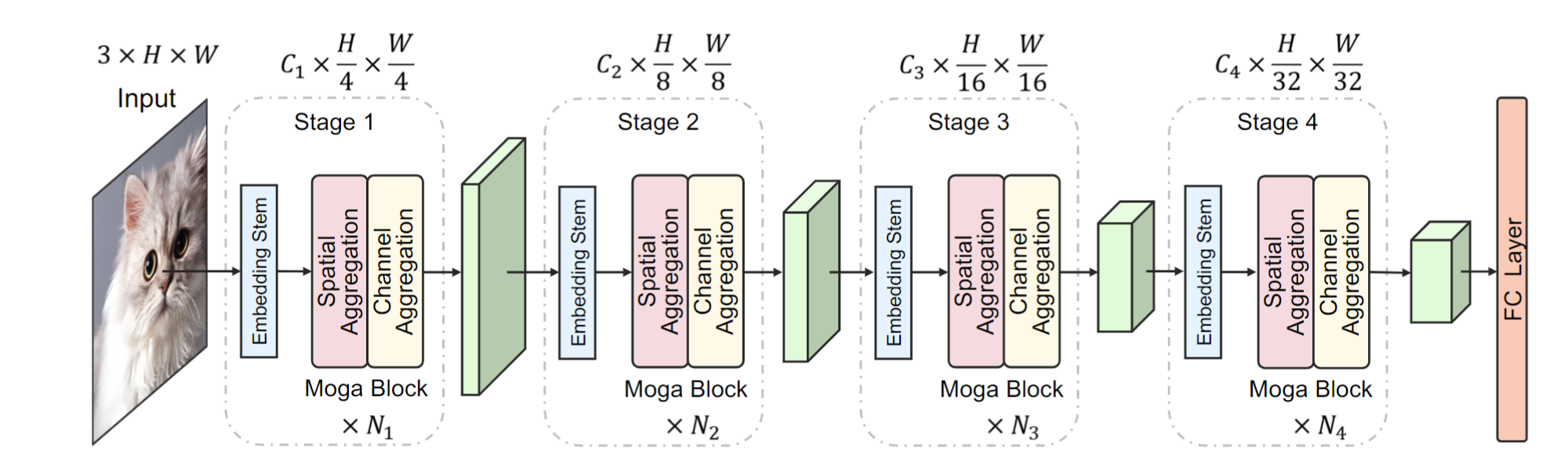
作者认为,交互复杂性是视觉识别一个重要特点。为此,作者通过复杂特征交互构建了一个纯卷积的网络 MogaNet 用于图像识别。MogaNet的整体框架如下图所示,架构和一般的 Transformer 网络非常类似,核心包括两个模块:spatial aggregation (取代注意力) 和 channel aggregation (取代FFN)。
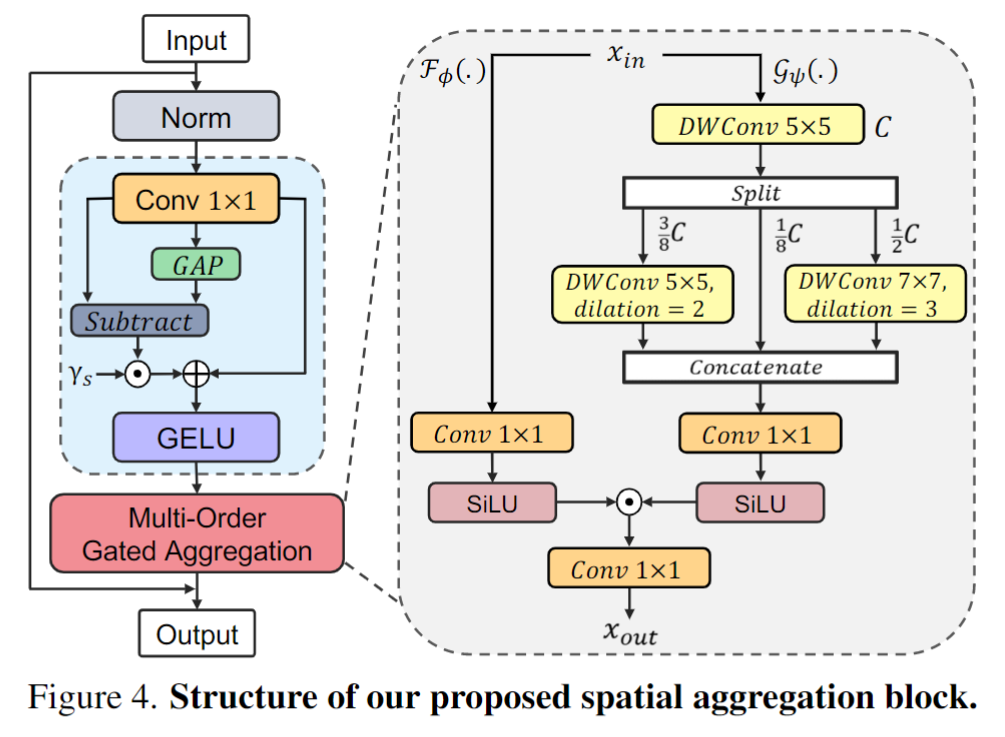
(1)spatial aggregation 如下图所示,蓝色部分叫做 feature decomposition,用于 exclude trivial interactions. (我对这个模块的动机并不太理解,不过下面的 channel aggregation 也用到了这个) 。下面是 Moga模块,也就是多次 DWConv,作者认为是多阶门控。
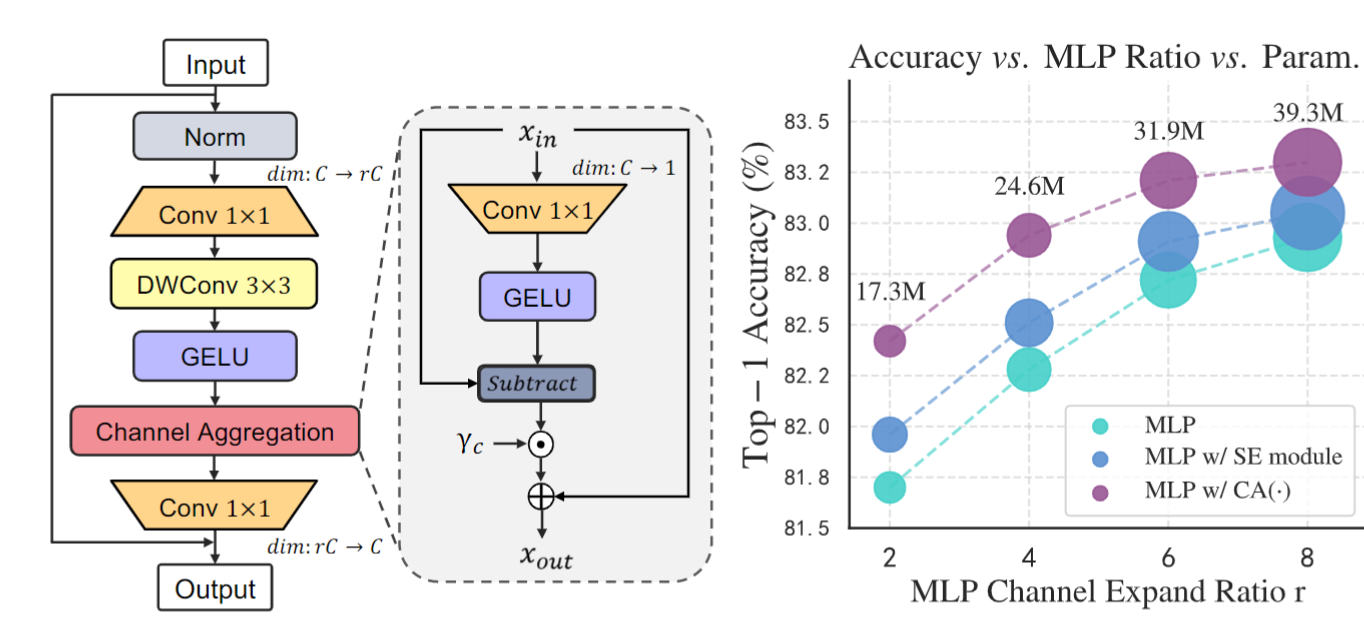
(2)channel aggregation 如下图所示。当前的主流方法FFN中仅包括两个FC层。因此,作者进行了如下改进。我理解这个操作类似于是一个空间位置的注意力,但貌似也并不很一样,不清楚在其它论文里有没有类似的操作。
这篇关于【ARXIV2211】Efficient multi-order gated aggregation network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
