本文主要是介绍StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video 译文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
链接:
https://arxiv.org/abs/2305.00942
摘要
人脸再现方法试图尽可能真实地恢复和再现人脸特征视频。现有的方法面临着质量与可控性的两难境地:与3D方法相比,基于2D GAN的方法实现了更高的图像质量,但在面部属性的细粒度控制方面受到影响。在本文中,我们提出了StyleAvatar,一种使用基于StyleGAN的网络的实时照片真实感人像头像重建方法,它可以生成具有忠实表情控制的高保真人像头像。我们通过引入组合表示和滑动窗口增强方法来扩展StyleGAN的功能,这使得能够更快地收敛并提高翻译泛化能力。具体来说,我们将人像场景分为三个部分进行自适应调整:面部区域、非面部前景区域和背景。此外,我们的网络充分利用了UNet、StyleGAN和time coding的优势来进行视频学习,从而实现高质量的视频生成。此外,还提出了滑动窗口增强方法和预训练策略,分别用于提高翻译泛化能力和训练性能。所提出的网络可以在两个小时内收敛,同时确保高图像质量和仅20毫秒的正向渲染时间。此外,我们还提出了一个实时直播系统,将研究进一步推向应用。结果和实验表明,与现有的人脸重建方法相比,我们的方法在图像质量、全人像视频生成和实时重新动画方面具有优越性。本文的训练和推理代码在https://github.com/LizhenWangT/StyleAvatar。
1. 介绍
真实感人像头像重建和重动画是计算机视觉和计算机图形学中的一个长期存在的主题,具有从视频编辑到混合现实的广泛应用。基于NeRF的肖像头像研究近况[Gafniet al. 2021; Gao et al. 2022; Zheng et al. 2023] 或者存在一些其他3D表示[Grassal et al. 2022a; Zheng et al. 2022a,b;Zielonka et al. 2022] 已经证明可以从单目视频中学习稳定的3D化身。然而,与基于2D GAN的方法相比,大多数3D方法仍然面临分辨率和图像质量的限制。此外,这些方法主要集中在僵硬的面部区域,忽略了长发、身体部位和背景元素。虽然可以直接覆盖背景,但执行得不好的覆盖通常会导致不真实的结果。理想的肖像头像应该优先考虑高保真、快速训练、细粒度控制和实时效率。
从单目视频中学习3D头部头像是近年来的热门话题。早期作品[Gafni et al. 2021; Grassalet al. 2022a; Zheng et al. 2022a] 将NeRF整合到头像中,实现有希望的视图一致性。最近的方法或者旨在实现更好的渲染真实感[Xu et al. 2023b;Zheng et al. 2022b] 或者更快的训练收敛和推理速度[Gao et al. 2022; Xu et al. 2023a; Zielonka et al. 2022] 通过利用更有效的3D表示[Fang et al. 2022; Mülleret al. 2022]. 一般来说,3D方法的核心思想是保持相对固定的特征空间,如拓扑一致的网格或规范空间,以使每个点或体素能够从视频中学习某些局部特征。这种策略导致更大的稳定性,但是由于跟踪不稳定性或其他因素,也会导致平滑的纹理。
另一方面,受益于强大的StyleGAN[Karras et al. 2021, 2019, 2020], 以下作品[Ab-dal et al. 2021; Chen et al. 2022; Deng et al. 2020; Härkönen et al.2020; Shen et al. 2020b; Tewari et al. 2020a,b; Wang et al. 2021b]极大地提高了语义编辑性能。一些方法[Doukas et al. 2021b; Drobyshev et al. 2022; Khakhulinet al. 2022] 可以从单一图像创建头像,而其他人[Sun et al. 2022, 2023; Xiang et al. 2022] 甚至可以用EG3D生成可控的3D人脸[Chan et al. 2022]. 然而,这些基于StyleGAN的方法主要依赖于高度对齐的高清人脸数据集,如FFHQ,它缺乏足够的面部表情变化。此外,它们不能在肖像视频中生成自然的头部运动。
我们提出了StyleAvatar,这是一个使用基于StyleGAN的网络进行照片真实感人像头像重建的实时系统。我们的系统能够在短短三个小时内生成一个高保真的肖像头像。为了解决全照片真实感人像视频重建的挑战,我们将人像场景分成三个部分:面部、可移动的身体部分(肩膀、脖子和头发)和背景。每个部分都有不同的属性:面部部分通过3DMM提供几乎所有的移动信息,而背景通常是静态的。可活动的身体部分可能包含无数不可控的动作,但我们还是可以从面部动作中了解到一些趋势。
为了克服这些挑战,我们提出了StyleAvatar,这是一个使用基于StyleGAN的网络进行照片级逼真肖像头像重建的实时系统。我们的系统可以在短短两个小时内生成一个高保真的人像头像。为了重建完整的人像视频,我们将视频分成三个部分:面部区域、非面部前景区域(肩膀、脖子、头发等)。)和背景。每个部分都有不同的属性:面部区域可以用3DMM来描述;非面部前景区域经常表现出不可控制的运动,但是趋势可以从面部运动中获知;并且背景保持静止。为了更好地表示这三个部分的不同特征,我们使用两个Style-GAN生成器来生成人脸区域和背景的两个静态特征图,并提出一个StyleUNet来从输入的3DMM渲染中生成非人脸前景特征图。为了加快训练和推理速度,我们使用了使用神经纹理[Thies et al. 2019] 在特征组合阶段用于面部区域。此外,我们还引入了滑动窗口增强方法来提高翻译泛化能力,并在一个小的视频数据集上对模型进行预训练,以进一步加快训练速度。最后,使用另一个StyleUNet从组合的特征图生成最终图像。我们的框架旨在通过TensorRT和OpenGL轻松加速,前向渲染时间仅为20毫秒,实现实时现场人像重现。结果和实验表明,我们的方法在图像质量、全人像视频生成和实时再现动画方面优于现有的人脸再现方法。我们的贡献可以总结为:
- 我们引入了一种有效分解人脸区域、非人脸前景区域和背景的合成表示法,这样我们可以根据不同区域的特征进行自适应调整,以提高稳定性和训练速度。
- 我们进一步提出了StyleUNet,它利用了UNet、StyleGAN和时间编码的优点来进行视频学习,从而实现了高质量的视频生成。
- 提出了滑动窗口增强方法和预训练策略,分别提高了翻译泛化能力和训练性能。
2. 相关工作
面部重现的方法。这些方法的目的是在给定另一个人的表现的情况下,生成目标人的照片般逼真的肖像图像(包括脸、头发、脖子甚至肩膀区域),这不同于人脸替换方法[Perov et al. 2020] 或者人脸表现捕捉和动画方法[Li et al. 2012; Weise et al. 2011]. 根据输入数据的不同,人脸再现方法大致可以分为三类:基于多视角系统的方法、基于单视频的方法和基于单图像的方法。基于多视图结构系统,最近的研究[Lombardi et al. 2018, 2019; Ma et al.2021; Raj et al. 2021; Wang et al. 2022a; Wei et al. 2019] 能够生成具有令人印象深刻的细微细节和高度灵活的可控性的面部化身,用于身临其境的度量远程呈现。然而,数据采集的困难限制了它的广泛应用。相反,基于单一图像的方法[Averbuch-Elor et al. 2017;Doukas et al. 2021b; Drobyshev et al. 2022; Geng et al. 2018; Honget al. 2022; Kowalski et al. 2020; Liu et al. 2001; Mallya et al. 2022;Nagano et al. 2018; Olszewski et al. 2017; Siarohin et al. 2019; Vlasicet al. 2005; Yin et al. 2022] 最容易捕捉,并能产生照片般逼真的面部重现效果。然而,当动画化到大的姿态和表情时,形状和细节可能不一致,尤其是对于那些在单个输入图像中没有被很好覆盖的区域,更不用说动态面部细节了。基于单一视频的方法[Doukas et al. 2021a; Garridoet al. 2014; Koujan et al. 2020; Suwajanakorn et al. 2017; Thies et al.2015, 2016] 显示了更稳定的面部重现结果。其中,[Kim et al. 2018] 基于based图像翻译框架,呈现令人印象深刻的完整头部再现和交互式编辑效果。最近的方法[Gafni et al. 2021;Gao et al. 2022;Wang et al. 2021a; Xu et al. 2023a,b; Zielonka et al. 2022] 显示了具有参数控制神经辐射场的最先进的再现结果。其他方法[Cao et al. 2022; Garbin et al.2022; Grassal et al. 2022b; Zheng et al. 2022a,b] 通过利用网格或点云等3D表示,提高了稳定性和纹理质量。然而,现有的基于单视频的面部重现方法在恢复精细细节方面仍然面临挑战,例如头发、雀斑甚至皮肤毛孔。
基于StyleGAN的人脸图像生成和编辑方法。这些方法可以产生高分辨率和照片般逼真的面部图像[Karras et al. 2021, 2019, 2020] 即使在语义编辑操作下[Abdal et al. 2021; Alaluf et al. 2021; Chen et al.2022; Deng et al. 2020; Ghosh et al. 2020; Härkönen et al. 2020;Jang et al. 2021;Ren et al. 2021;Richardson et al. 2021;Shen et al.2020a,b; Shi et al. 2022; Tewari et al. 2020a,b; Tov et al. 2021; Wang et al. 2021b]. 这些工作通过解耦输入潜在空间对StyleGAN生成的图像进行语义修改。此外,戈什等人。[Ghosh et al. 2020] 和肖山等人。[Shoshan et al. 2021] 将StyleGAN潜在空间与语义输入(如3DMM参数)相结合[Blanz and Vetter1999]. 索夫根[Chen et al. 2022] 使用语义分割图来调节图像生成器,并使用额外的3D扫描进行训练来实现3D感知生成。这些方法提供了对生成的照片般逼真的面部图像的形状、姿势、头发和风格的有意义的控制,但是诸如眨眼之类的细粒度表情修改仍然不可用。更重要的是,这些方法严重依赖于预先训练的风格和潜在空间,使得它们很难在编辑过程中保持时间稳定性和细节的一致性。
3. 方法
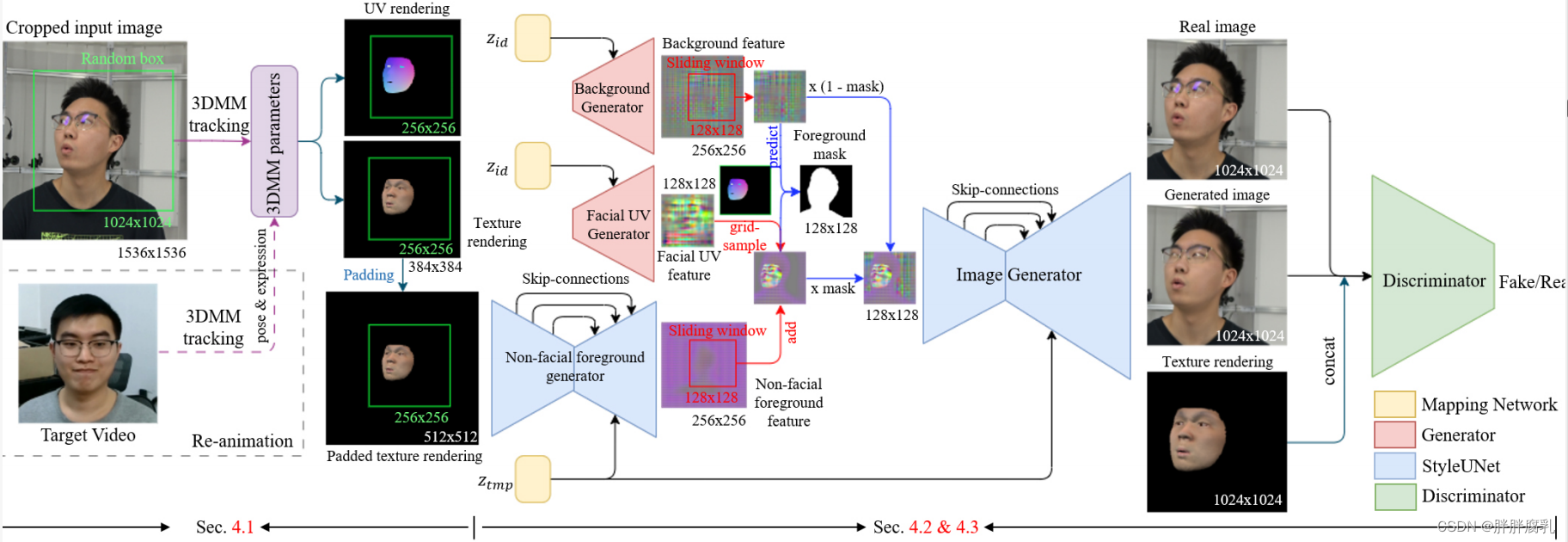
图2:我们的肖像头像重建和再动画流程包括三个主要步骤:3DMM跟踪和渲染,面部区域、非面部前景区域和背景的特征生成,以及组合特征映射的最终图像生成。为了实现这一点,我们使用两个StyleGAN生成器、一个StyleGAN鉴别器和两个styleunet。此外,我们结合了数据增强技术,在输入图像上使用随机框,在生成的特征图上使用滑动窗口,以提高翻译泛化。
如图2所示。 输入单目人像视频,我们首先执行3DMM跟踪(3.1) 使用预测纹理和UV坐标顶点颜色生成合成渲染。接下来,在特征生成阶段(3.2), 我们将人像特征图分成三个部分:由StyleGAN生成器生成的在UV空间中生成的静态人脸特征图;由StyleUNet从输入纹理渲染生成的非面部前景特征图;由另一个StyleGAN生成器生成的静态背景特征图。然后,我们使用神经纹理从UV空间提取人脸特征图,并在特征图的组合过程中引入滑动窗口数据增强,以更好地利用整个视频的信息。最后,使用另一个StyleUNet从组合的特征图生成图像,并引入StyleGAN鉴别器进行对抗学习。注意,在推断阶段仅计算两个StyleUNets,并且可以通过替换来自另一个视频的输入表情和姿态参数来实现重新动画。
3.1 数据处理
我们首先对输入的单目肖像视频进行3DMM跟踪,以生成像素对齐的3DMM渲染,用于后续训练。我们选择使用FaceVerse[Wang et al. 2022b] 因为它丰富的形状和表情基础,我们增加了单独的眼球。具有预测纹理的纹理渲染用于非面部前景特征生成,而具有UV坐标顶点颜色的另一UV渲染用于面部区域的神经纹理。为了在特征组合阶段监督掩模预测的训练,我们使用鲁棒的视频抠图来生成前景掩模[Lin et al. 2021].
对于3DMM系数跟踪算法,我们需要求解形状系数 θ s h a p e \theta_{shape} θshape ,表达式系数 θ e x p r e s s i o n \theta_{expression} θexpression,纹理系数 θ t e x t u r e \theta_{texture} θtexture,平移系数 t t t, 缩放系数 s s s,头部旋转以及眼球和旋转头和两个眼球 R 1 , R 2 , R 3 R_1,R_2,R_3 R1,R2,R3。为了提高效率,我们直接从MediaPipe检测到的人脸关键点坐标𝐾𝑡𝑔𝑡中求解这些参数的解析解。具体来说,我们使用了以下能量函数:
arg min R x , t , s ∥ R x K src + t − K t g t / s ∥ 2 \begin{array}{cc} \underset{R_{x}, t, s}{\arg \min }\left\|R_{x} K_{\text {src }}+t-K_{t g t} / s\right\|_{2} \end{array} Rx,t,sargmin∥RxKsrc +t−Ktgt/s∥2
arg min δ θ shape , δ θ exp ∥ R 1 ( K src + B shape δ θ shape + B exp δ θ exp ) + t − K t g t / s ∥ 2 \begin{array}{cc} \underset{\delta \theta_{\text {shape }}, \delta \theta_{\text {exp }}}{\arg \min } & \left\|R_{1}\left(K_{\text {src }}+B_{\text {shape }} \delta \theta_{\text {shape }}+B_{\text {exp }} \delta \theta_{\text {exp }}\right)+t-K_{t g t} / s\right\|_{2} \end{array} δθshape ,δθexp argmin∥R1(Ksrc +Bshape δθshape +Bexp δθexp )+t−Ktgt/s∥2
arg min δ θ tex ∥ T src + B tex δ θ tex − T tgt ∥ 2 \begin{array}{cc} \underset{\delta \theta_{\text {tex }}}{\arg \min }\left\|T_{\text {src }}+B_{\text {tex }} \delta \theta_{\text {tex }}-T_{\text {tgt }}\right\|_{2} \end{array} δθtex argmin∥Tsrc +Btex δθtex −Ttgt ∥2
在FaceVerse中 K s r c K_{src} Ksrc 代表相应的地标,而 B s h a p e B_{shape} Bshape, B e x p , B tex B_{exp}, B_{\text {tex }} Bexp,Btex 代表形状,表情,和纹理基底。为了得到最终参数,我们迭代求解1式和2式。1式为我们提供了旋转、平移和缩放参数,而2式为我们提供了FaceVerse的形状和表达式系数。此外,我们使用3 式来求解纹理系数。2式和3式可以用LDLT分解求解,而1式可以使用SVD分解求解。因为我们要求预测的形状对同一个人是一致的,并且预测的纹理对我们的框架来说不是关键的,所以我们只在第一帧中求解形状和纹理系数。
为了生成UV渲染,我们使用UV坐标顶点颜色,其中红色和绿色通道像素值对应于UV坐标中的x和y位置。为了生成纹理渲染,我们利用预测的纹理并用预定义的固定照明来渲染它,以便强调面部表情的变化。此外,为了更好地利用来自整个视频的信息,我们提出了一种滑动窗口数据增强方法。具体来说,我们将人像区域的裁剪框放大1.5倍,以保留更多的上半身和背景信息,如图2所示。
3.2 特征生成与组合
在特征生成阶段,为了创建高质量的头像,我们将人像区域划分为三个部分,并使用基于stylegan的网络生成相应的特征映射。具体来说,我们使用两个StyleGAN生成器生成面部区域和背景的静态特征映射。在UV空间中生成人脸特征图,并设计输入身份潜码 Z i d Z_{id} Zid 进行预训练,使我们能够针对不同的视频生成不同的特征图。对于非面部前景区域,我们提出一个StyleUNet从输入的3DMM渲染生成像素对齐的特征映射。我们认为可以通过3DMM的运动来预测该部件的合理运动。为了适应不可控的变化,如头发运动,我们使用输入时间潜在代码(𝑡𝑚𝑝)作为额外的输入。我们遵循Bahmani et al [Bahmani et al 2022]使用位置嵌入将人的身份和时间戳映射到更高的维度,以便它们可以输入到我们的网络中。
在特征组合阶段,我们将三个特征映射组合起来生成最终的图像。对于面部区域,3DMM已经提供了基本的几何形状,因此我们采用递延神经渲染(DNR) [Thies等]中提出的神经纹理[2019]通过对人脸UV特征图进行采样,生成人脸特征图。对于背景和非人脸前景区域,我们使用滑动窗口对生成的特征图进行裁剪,以确保输入特征图与输出图像之间的像素对齐关系。为了生成动态的面部变化和突出的形状,如眼镜,我们直接添加了面部特征图和非面部前景特征图。为了保证前景特征映射在背景特征映射的前面,我们首先使用监督卷积层从前景和背景特征映射中预测前景掩码,然后使用预测的掩码将这两个特征映射组合起来。最后,我们使用另一个StyleUNet从组合的特征映射中生成最终图像,并使用StyleGAN鉴别器对网络进行对抗式训练。我们还将时态潜在代码(𝑡𝑚𝑝)合并为StyleUNet的附加输入。如图3所示,不同的𝑡𝑚𝑝值会导致与时间相关的变化,例如头发运动。映射网络和𝑡𝑚𝑝的使用通过将与时间相关但不可控的变化合并到潜在空间中,有助于防止过度平滑的细节。注意,在推理阶段只计算两个styleunet。
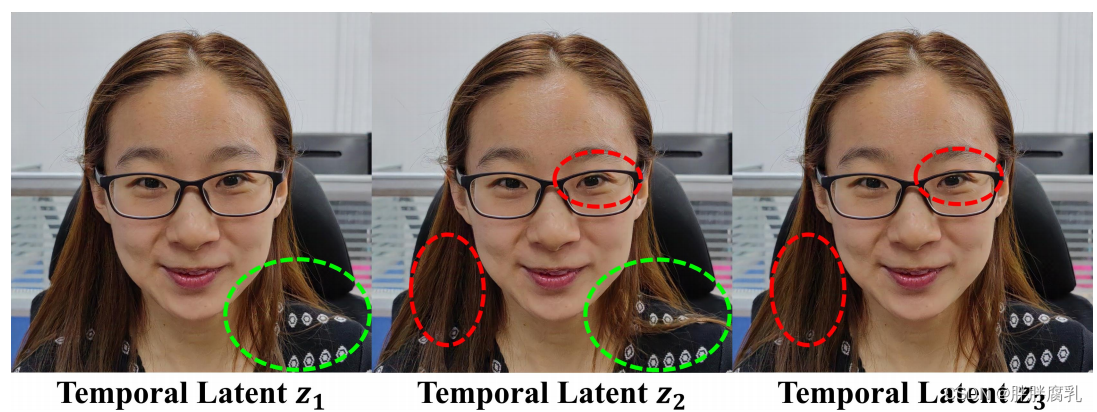
图3:存储在我们的时间潜空间中的信息允许在使用不同的时间潜代码 Z t m p Z_{tmp} Ztmp输入相同的渲染时更改细节,例如头发变化。

图4:使用简单UNet生成的图像在大范围内的自由移动可能会撕裂。通过引入滑动窗口,我们的角色可以在更大的范围内移动。
为了克服在二维角色中处理自由平移运动的挑战,我们提出了一种滑动窗口数据增强方法,以更好地利用来自整个输入视频的信息。如图4a所示,使用简单的基于unet的2D虚拟形象通常会导致明显的视觉伪影,例如图像撕裂,特别是在过度头部平移的情况下。这可以归因于两个因素:首先,众所周知UNets对图像翻译非常敏感;其次,输入人像视频的中心区域往往有更明显的姿势和表情变化,而边界区域变化较少,导致翻译的泛化能力降低。为了增强平移泛化能力,我们首先对输入图像及其对应的3DMM渲染图使用随机样本。为了确保非面部前景区域的像素对齐特征,我们将采样的输入渲染填充到更高的分辨率(256到512)。然后,我们利用两个滑动窗口从生成的特征图中提取像素对齐的背景和非面部前景区域。这些滑动窗口的位置由输入的随机样本盒决定。最后,我们将像素对齐的纹理渲染图与生成的图像连接起来,为我们的鉴别器创建假的输入图像,并将纹理渲染图与样本框中的输入图像连接起来,为我们的鉴别器创建真实的输入图像。如图4b所示,在提出的数据增强方法的帮助下,我们的方法能够解决大的头部平移问题,并且可以通过在特征组合过程中使用不同的滑动窗口来生成前景和背景运动。
3.3网络结构与损失函数
如图2所示,我们的框架由五个网络组成:两个特征生成器、两个styleunet和一个鉴别器。为了满足实时性要求和加快训练速度,我们在类似于SWAGAN [Gal et al . 2021]的所有网络中使用小波变换,这使我们能够将1024×1024×3图像替换为512×512×12表示。除此之外,我们的生成器和鉴别器的其余部分遵循StyleGAN2架构。StyleUNet使用编码器-解码器结构,设计用于图像到图像的转换,具有额外的输入潜在代码和噪声。与UNet类似[Ronneberger等人2015],我们的编码器提取多尺度特征,通过跳跃连接发送给解码器。我们使用映射网络,调制卷积和时间潜在代码为网络引入额外的变化可能性,防止它平滑某些特征。例如,不受控制的毛发运动可以通过与时间相关的潜在代码进行调节。然而,这种方法不能保证头发的完全稳定性。我们在styleunet和生成器中使用64维潜在代码作为映射网络的输入。如[Karras等人2021]所述,StyleGAN2的噪声注入层会导致纹理粘附伪影。为了减轻这种影响,我们使用UV渲染将噪声从UV空间映射到人脸区域,并将固定噪声用于静态背景。为了将面部先验合并到鉴别器中,我们将纹理渲染与输出图像连接起来,作为鉴别器的输入。
在损失函数方面,由于直接监督对于我们的任务是可行的,我们在训练过程中使用了常见的L1损失和感知损失 VGG19。此外,我们将L1损耗纳入前景mask。我们还包括对抗学习的GAN损失。损失函数可以表示为:
L = L 1 + L percep + L mask + L G A N \mathcal{L}=\mathcal{L}_{1}+\mathcal{L}_{\text {percep }}+\mathcal{L}_{\text {mask }}+\mathcal{L}_{G A N} L=L1+Lpercep +Lmask +LGAN
3.4 预训练和现场系统
为了加速训练收敛,我们使用从4K视频中裁剪的6个视频进行预训练。如第3.2节所讨论的,我们对每个视频使用不同的身份潜码( z i d z_{id} zid)。尽管数据集有限,预训练已被证明是有效的,如第4.2节所示。注意,我们假设每个视频的 z t m p z_{t m p} ztmp 的视频长度是固定的,并在推理阶段选择一个固定的 z t m p z_{t m p} ztmp。
为了使我们的工作更接近实际应用,我们提出了一个由三个主要步骤组成的实时实时系统:3DMM跟踪,3DMM渲染使用OpenGL加速,以及两个已转换为TensorRT模型的styleunet。我们的系统可以在带有一个RTX 3090 GPU的PC上使用16位TensorRT模型以35 fps(每帧28毫秒)的速度运行,并且在推理阶段需要大约4 GB的GPU内存。16位模型平均需要20毫秒的GPU时间,而原始PyTorch模型平均需要31毫秒。为了生成一个逼真的面部化身,我们需要大约两分钟的视频片段,其中包括一系列头部姿势和面部表情。本文使用的视频包括白宫提供的奥巴马视频(公共领域),IMAvatar提供的视频,以及MEAD数据集的视频[Wang et al 2020]。我们得到了在剩余视频中出现的所有演员的同意。
4. 实验
4.1 比较

图5:自驱动动画和再现与一次性肖像化身方法的对比
表2:与基于视频的化身方法的定量比较。
我们首先将我们的方法与基于GAN结构的最先进的一次性面部方法进行比较,以证明我们的网络能够实现对表情和面部细节的细粒度控制。为了进行比较,我们选择了两种具有代表性的方法:DaGAN [Hong et al . 2022]作为2D一次性角色的表示 和 Next3D [Sun et al . 2023]作为3D一次性方法的表示。为了保证实验的公平性,我们对用于对比的单目视频进行了24小时的Next3D微调,表示为“Next3D-refine”,而“Next3D-single”为原始预训练模型。如图5和表1所示,我们的方法在图像质量和面部属性控制方面都优于DaGAN和两个版本的Next3D。Next3D-refine在对视频进行微调后,虽然提高了保真度,但仍然无法实现对面部表情的细粒度控制。这些结果表明,基于视频的训练仍然是高保真肖像的必要条件,并且我们的网络结构在基于视频的训练中表现出更好的性能。请注意,为了获得表1中显示的值,我们首先对齐了面,裁剪了图像,删除了背景,并将它们调整为512 × 512的分辨率。表1所示的值是根据MEAD数据集中的另一个视频测试集生成的自动驾驶图像和相应的ground-truth图像计算得出的。
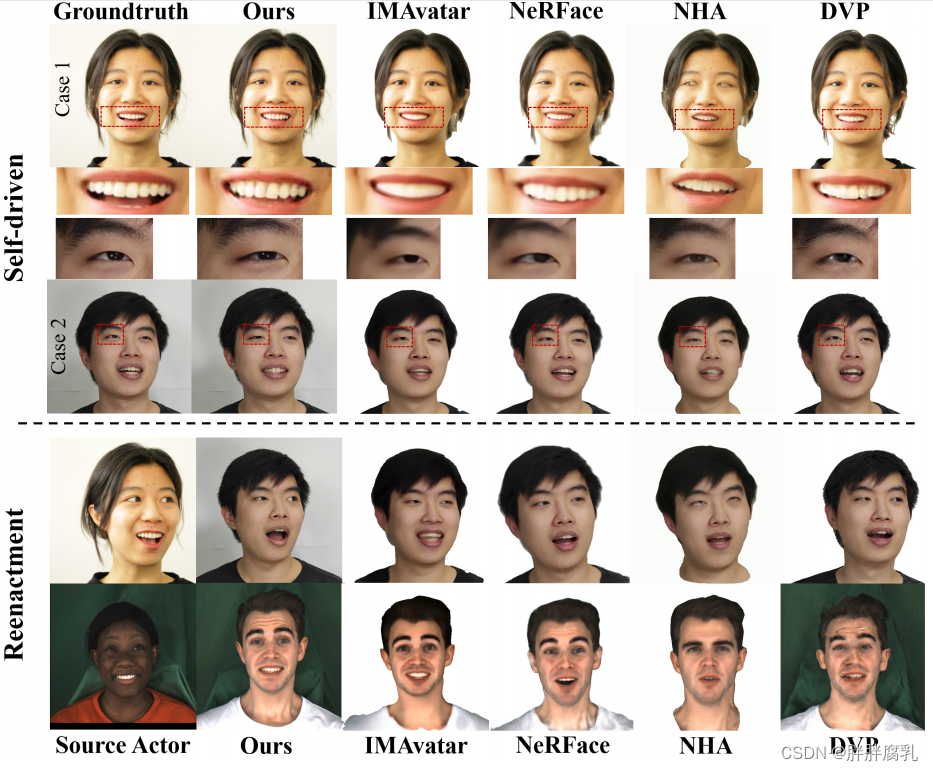
图6:基于视频的面部再现方法与自驱动再现和面部再现的对比。我们的方法可以生成更真实的细节(例如:牙齿,眼睛里的光点。)
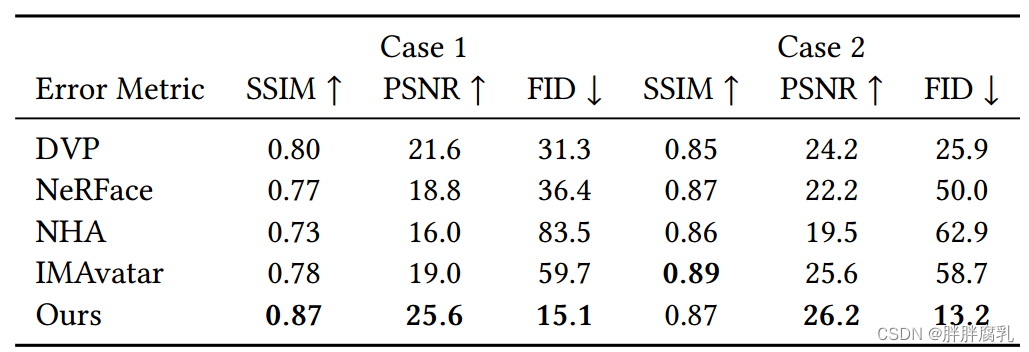
我们将我们的方法与最先进的基于视频的面部再现方法进行了比较,包括深度视频肖像(DVP) [Kim等人2018],NeRFace [Gafni等人2021],IMAvatar [Zheng等人2022a]和神经头部头像(NHA) [Grassal等人2022a],所有这些方法都是在单目视频上训练的。我们把80%的视频分成了训练集剩下的20%分成了用于评估的测试集。此外,我们已经删除了背景,并将图像的大小调整为512×512的分辨率。表2所示值是基于测试集中的自动驾驶图像及其对应的真值图像计算得出的。我们还对这些方法进行了自驱动的再动画和再现,如图6所示。虽然3D方法显示稳定的头部几何形状,但它们无法在输出渲染中产生高保真的纹理细节,如头发、牙齿和瞳孔。通过结合基于stylegan的网络和使用我们的数据增强,我们的方法获得了比现有方法更高的图像质量,并且可以保留更多的细节,例如眼睛中的光点。如表2所示,我们的方法获得了明显更好的定量结果,特别是在FID度量中,这表明我们的方法产生了更高质量的图像。
4.2 消融研究
表3:消融研究的定量比较
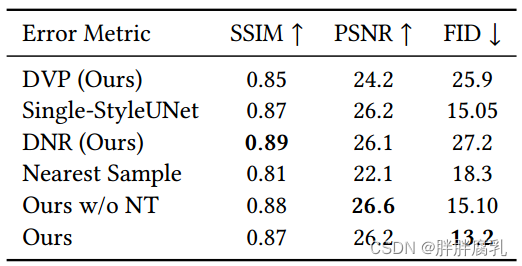

图7:消融研究DVP、DNR、我们的“singleStyleUNet”、“最近样本”、“w/o NT”和我们的完整方法。该方法在图像质量和翻译泛化方面具有优势。
在我们的比较中,我们已经展示了我们的网络强大的图像生成能力,这得益于基于stylegan的StyleUNet结构。但是,需要注意的是,简单的StyleUNet可能无法实现翻译泛化,并且可能需要很长时间才能收敛。在消融研究中,我们使用术语“DVP(我们的)”指的是带有3DMM纹理渲染的简单UNet输入,类似于DVP结构,“Single-StyleUNet”指的是带有3DMM纹理渲染的StyleUNet输入。“DNR(我们的)”代表了与延迟神经渲染的比较[Thies等人2019],后者仅使用面部区域的神经纹理作为UNet的输入。此外,我们在我们的训练集中包括“最接近的样本”和“我们的w/o NT”,这是指我们的方法没有神经纹理。如图7和表3所示,在没有我们的数据增强和视频分解的情况下,即使“Single-StyleUNet”仍然可以生成高保真的图像,但是它无法防止在显著的头部运动的图像撕裂。“DVP(我们的)”和“DNR(我们的)”都显示出图像质量的明显下降,突出了StyleUNet在生成高保真图像方面的重要性。“我们的w/o NT”仍然可以产生高质量的图像,这表明神经纹理主要有助于加速训练收敛。请注意,表3所示的情况1和2已标记在图7的自驱动部分。
为了验证我们方法的泛化能力,我们在图7中给出了“最近样本”,并计算了自驱动和重演案例的平均最近平移、旋转和表达参数,如表4所示。应该注意的是,我们首先使用从训练集计算的标准差对所有参数进行归一化。选择图7中的图像,平移、旋转和表达参数权重相等,但表4中的值是针对每个参数分别计算的。结果表明,我们的方法可以在翻译上实现更大的外推,同时在表达和旋转上的表现与其他最先进的方法相似。此外,我们的方法只能处理大约30度的旋转,因为大旋转对人脸跟踪来说是一个挑战。

图8:训练阶段生成的不同网络结构的图像。我们的方法可以实现更快的训练速度。
如图8所示,由于视频分解和Neural Textures,我们的方法在没有预训练的情况下,训练速度明显更快。“我们的w/o预训练”的第四列可以比第三列更快地学习背景和面部区域的基本信息。只有肩膀、头发和眼镜、牙齿等小部位需要进一步训练。将“我们的”与“我们的”进行比较,证明了预训练的有效性。注意,图8中的视频没有用于预训练。
4.3 训练和渲染效率
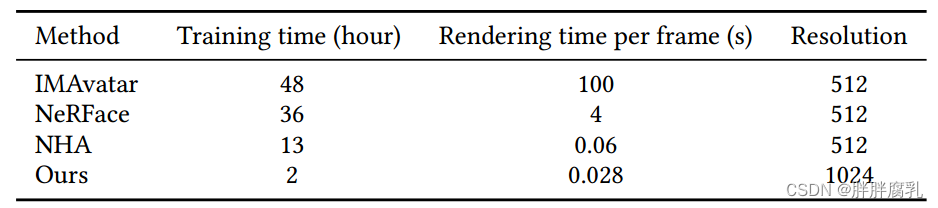
如表5所示,我们的方法在训练和渲染方面明显更快,同时生成的图像分辨率也更高。这可以归因于我们使用的视频分解,预训练和简单的网络结构,可以很容易地通过TensorRT加速。此外,我们使用3DMM点的顶点颜色来表示它们对应的UV坐标,允许使用OpenGL进行实时渲染。值得注意的是,经过仅仅两个小时的训练,我们的模型已经取得了视觉上令人满意的结果,只有牙齿区域需要进一步的训练(大约另外4个小时)才能达到收敛。
表5:各方法的训练时间、渲染时间和图像分辨率。与现有方法相比,我们的方法在训练中明显更快,并且能够以更高的分辨率实时渲染图像。
5. 讨论与结论

图9:由于训练数据集之外的姿势、参数化模型无法建模的表达式、嘴巴内部不可控等原因导致的失败案例。
局限性。所提出的StyleAvatar优于最先进的面部再现方法,但仍有一些局限性。首先,我们的图像到图像的翻译网络受到质量的限制。首先,我们的图像到图像翻译网络受到训练数据集的质量和变化的限制。因此,我们无法生成与训练数据集有明显差异的旋转和表达式,如图9第一列所示。其次,通过3DMM跟踪算法生成输入效果图。然而,跟踪的3DMM无法准确描述细节表达式,导致表达式控制不准确,如图9第二列所示。此外,嘴巴内部没有受到约束,导致在重演阶段缺乏真实感,嘴巴内部有时会出现模糊。
潜在的社会影响。我们的方法使数字人像复制可以由另一个人像视频再现。因此,给定一个特定的人的人像视频,它可以用来生成假人像视频,这需要在部署该技术之前仔细解决。
结论。在本文中,我们介绍了StyleAvatar,这是一个从单个视频生成的实时逼真的肖像头像。我们提出了一种新颖的基于stylegan的框架,可以生成包括肩部和背景在内的全人像视频,图像质量高。独特的视频分解和滑动窗口数据增强,使我们能够实现更快的收敛和更自然的运动。此外,我们提出的实时系统允许学习的面部头像被其他对象实时地重新激活。我们的广泛结果和综合实验表明,我们的方法优于基于单视频的面部化身重建和再现的最先进方法。我们相信我们的框架将激发未来对面部再现的研究,我们的实时现场系统在相关任务中具有很好的潜在应用前景。
参考文献
Rameen Abdal, Peihao Zhu, Niloy J Mitra, and Peter Wonka. 2021. StyleFlow: Attribute- conditioned exploration of StyleGAN-generated images using conditional continu- ous normalizing flows. ACM Transactions on Graphics (TOG) 40, 3 (2021), 1–21.
Yuval Alaluf, Or Patashnik, and Daniel Cohen-Or. 2021. Restyle: A residual-based StyleGAN encoder via iterative refinement. In IEEE/CVF International Conference on Computer Vision (ICCV). 6711–6720.
Hadar Averbuch-Elor, Daniel Cohen-Or, Johannes Kopf, and Michael F Cohen. 2017. Bringing portraits to life. ACM transactions on graphics (TOG) 36, 6 (2017), 1–13.
Sherwin Bahmani, Jeong Joon Park, Despoina Paschalidou, Hao Tang, Gordon Wet- zstein, Leonidas Guibas, Luc Van Gool, and Radu Timofte. 2022. 3d-aware video generation. arXiv preprint arXiv:2206.14797 (2022).
Volker Blanz and Thomas Vetter. 1999. A Morphable Model for the Synthesis of 3D Faces. In ACM SIGGRAPH. ACM, 187–194.
Chen Cao, Tomas Simon, Jin Kyu Kim, Gabe Schwartz, Michael Zollhoefer, Shun-Suke Saito, Stephen Lombardi, Shih-En Wei, Danielle Belko, Shoou-I Yu, et al. 2022. Authentic volumetric avatars from a phone scan. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–19.
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. 2022. Efficient geometry-aware 3D generative adversarial networks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 16123–16133.
Anpei Chen, Ruiyang Liu, Ling Xie, Zhang Chen, Hao Su, and Jingyi Yu. 2022. SofGAN: A portrait image generator with dynamic styling. ACM Transactions on Graphics (TOG) 41, 1 (2022), 1–26.
Yu Deng, Jiaolong Yang, Dong Chen, Fang Wen, and Xin Tong. 2020. Disentangled and controllable face image generation via 3D imitative-contrastive learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5154– 5163.
Michail Christos Doukas, Mohammad Rami Koujan, Viktoriia Sharmanska, Anastasios Roussos, and Stefanos Zafeiriou. 2021a. Head2Head++: Deep facial attributes re- targeting. IEEE Transactions on Biometrics, Behavior, and Identity Science 3, 1 (2021), 31–43.
Michail Christos Doukas, Stefanos Zafeiriou, and Viktoriia Sharmanska. 2021b. HeadGAN: One-shot neural head synthesis and editing. In IEEE/CVF International Conference on Computer Vision (ICCV). 14398–14407.
Nikita Drobyshev, Jenya Chelishev, Taras Khakhulin, Aleksei Ivakhnenko, Victor Lempitsky, and Egor Zakharov. 2022. MegaPortraits: One-shot megapixel neural head avatars. arXiv preprint arXiv:2207.07621 (2022).
Jiemin Fang, Taoran Yi, Xinggang Wang, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Matthias Nießner, and Qi Tian. 2022. Fast dynamic radiance fields with time-aware neural voxels. In SIGGRAPH Asia 2022 Conference Papers. 1–9.
Guy Gafni, Justus Thies, Michael Zollhofer, and Matthias Nießner. 2021. Dynamic neural radiance fields for monocular 4D facial avatar reconstruction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 8649–8658.
Rinon Gal, Dana Cohen Hochberg, Amit Bermano, and Daniel Cohen-Or. 2021. SWA- GAN: A style-based wavelet-driven generative model. ACM Transactions on Graph- ics (TOG) 40, 4 (2021), 1–11.
Xuan Gao, Chenglai Zhong, Jun Xiang, Yang Hong, Yudong Guo, and Juyong Zhang. 2022. Reconstructing personalized semantic facial NeRF models from monocular video. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1–12.
Stephan J Garbin, Marek Kowalski, Virginia Estellers, Stanislaw Szymanowicz, Shideh Rezaeifar, Jingjing Shen, Matthew Johnson, and Julien Valentin. 2022. VolTeMorph: Realtime, Controllable and Generalisable Animation of Volumetric Representations. arXiv preprint arXiv:2208.00949 (2022).
Pablo Garrido, Levi Valgaerts, Ole Rehmsen, Thorsten Thormahlen, Patrick Perez, and Christian Theobalt. 2014. Automatic face reenactment. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4217–4224.
Jiahao Geng, Tianjia Shao, Youyi Zheng, Yanlin Weng, and Kun Zhou. 2018. Warp- guided GANs for single-photo facial animation. ACM Transactions on Graphics (TOG) 37, 6 (2018), 1–12.
Partha Ghosh, Pravir Singh Gupta, Roy Uziel, Anurag Ranjan, Michael J Black, and Timo Bolkart. 2020. GIF: Generative interpretable faces. In International Conference on 3D Vision (3DV). IEEE, 868–878.
Philip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother, Matthias Nießner, and Justus Thies. 2022a. Neural head avatars from monocular RGB videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18653– 18664.
Philip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother, Matthias Nießner, and Justus Thies. 2022b. Neural head avatars from monocular RGB videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18653– 18664.
Erik Härkönen, Aaron Hertzmann, Jaakko Lehtinen, and Sylvain Paris. 2020. GANSpace: Discovering interpretable GAN controls. Advances in Neural Informa- tion Processing Systems 33 (2020), 9841–9850.
Fa-Ting Hong, Longhao Zhang, Li Shen, and Dan Xu. 2022. Depth-aware generative adversarial network for talking head video generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3397–3406.
Wonjong Jang, Gwangjin Ju, Yucheol Jung, Jiaolong Yang, Xin Tong, and Seungy- ong Lee. 2021. StyleCariGAN: caricature generation via StyleGAN feature map modulation. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–16.
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehti- nen, and Timo Aila. 2021. Alias-free generative adversarial networks. Advances in Neural Information Processing Systems 34 (2021), 852–863.
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4401–4410.
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of StyleGAN. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 8110–8119.
Taras Khakhulin, Vanessa Sklyarova, Victor Lempitsky, and Egor Zakharov. 2022. Realistic one-shot mesh-based head avatars. In European Conference of Computer vision (ECCV). Springer, 345–362.
Hyeongwoo Kim, Pablo Garrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Pérez, Christian Richardt, Michael Zollhöfer, and Christian Theobalt. 2018. Deep video portraits. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–14.
Mohammad Rami Koujan, Michail Christos Doukas, Anastasios Roussos, and Ste- fanos Zafeiriou. 2020. Head2head: Video-based neural head synthesis. In IEEE International Conference on Automatic Face and Gesture Recognition. IEEE, 16–23.
Marek Kowalski, Stephan J Garbin, Virginia Estellers, Tadas Baltrušaitis, Matthew John- son, and Jamie Shotton. 2020. Config: Controllable neural face image generation. In European Conference on Computer Vision (ECCV). Springer, 299–315.
Kai Li, Feng Xu, Jue Wang, Qionghai Dai, and Yebin Liu. 2012. A data-driven approach for facial expression synthesis in video. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 57–64.
Shanchuan Lin, Linjie Yang, Imran Saleemi, and Soumyadip Sengupta. 2021. Ro- bust High-Resolution Video Matting with Temporal Guidance. arXiv preprint arXiv:2108.11515 (2021).
Zicheng Liu, Ying Shan, and Zhengyou Zhang. 2001. Expressive expression mapping with ratio images. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques. 271–276.
Stephen Lombardi, Jason Saragih, Tomas Simon, and Yaser Sheikh. 2018. Deep appear- ance models for face rendering. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–13.
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. 2019. Neural volumes: Learning dynamic renderable volumes from images. arXiv preprint arXiv:1906.07751 (2019).
Shugao Ma, Tomas Simon, Jason Saragih, Dawei Wang, Yuecheng Li, Fernando De La Torre, and Yaser Sheikh. 2021. Pixel codec avatars. In IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). 64–73.
Arun Mallya, Ting-Chun Wang, and Ming-Yu Liu. 2022. Implicit Warping for Animation with Image Sets. arXiv preprint arXiv:2210.01794 (2022).
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–15.
Koki Nagano, Jaewoo Seo, Jun Xing, Lingyu Wei, Zimo Li, Shunsuke Saito, Aviral Agarwal, Jens Fursund, Hao Li, Richard Roberts, et al. 2018. paGAN: real-time avatars using dynamic textures. ACM Transactions on Graphics (TOG) 37, 6 (2018), 258–1.
Kyle Olszewski, Zimo Li, Chao Yang, Yi Zhou, Ronald Yu, Zeng Huang, Sitao Xiang, Shunsuke Saito, Pushmeet Kohli, and Hao Li. 2017. Realistic dynamic facial textures from a single image using GANs. In IEEE International Conference on Computer Vision (ICCV). 5429–5438.
Ivan Perov, Daiheng Gao, Nikolay Chervoniy, Kunlin Liu, Sugasa Marangonda, Chris Umé, Mr Dpfks, Carl Shift Facenheim, Luis RP, Jian Jiang, et al. 2020. DeepFace- Lab: Integrated, flexible and extensible face-swapping framework. arXiv preprint arXiv:2005.05535 (2020).
Amit Raj, Michael Zollhoefer, Tomas Simon, Jason Saragih, Shunsuke Saito, James Hays, and Stephen Lombardi. 2021. PVA: Pixel-aligned volumetric avatars. arXiv preprint arXiv:2101.02697 (2021).
Yurui Ren, Ge Li, Yuanqi Chen, Thomas H Li, and Shan Liu. 2021. Pirenderer: Con- trollable portrait image generation via semantic neural rendering. In IEEE/CVF International Conference on Computer Vision (ICCV). 13759–13768.
Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro, and Daniel Cohen-Or. 2021. Encoding in style: a StyleGAN encoder for image-to- image translation. In IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). 2287–2296.
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI). Springer, 234–241.
Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. 2020a. Interpreting the latent space of GANs for semantic face editing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9243–9252.
Yujun Shen, Ceyuan Yang, Xiaoou Tang, and Bolei Zhou. 2020b. InterFaceGAN: Inter- preting the disentangled face representation learned by GANs. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 44, 4 (2020), 2004–2018.
Yichun Shi, Xiao Yang, Yangyue Wan, and Xiaohui Shen. 2022. SemanticStyleGAN: Learning compositional generative priors for controllable image synthesis and editing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11254–11264.
Alon Shoshan, Nadav Bhonker, Igor Kviatkovsky, and Gerard Medioni. 2021. GAN- Control: Explicitly controllable GANs. In IEEE/CVF International Conference on Computer Vision (ICCV). 14083–14093.
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019. First order motion model for image animation. Advances in Neural Information Processing Systems 32 (2019).
Jingxiang Sun, Xuan Wang, Yichun Shi, Lizhen Wang, Jue Wang, and Yebin Liu. 2022. IDE-3D: Interactive disentangled editing for High-Resolution 3D-Aware portrait synthesis. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1–10.
Jingxiang Sun, Xuan Wang, Lizhen Wang, Xiaoyu Li, Yong Zhang, Hongwen Zhang, and Yebin Liu. 2023. Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. 2017. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1–13.
Ayush Tewari, Mohamed Elgharib, Florian Bernard, Hans-Peter Seidel, Patrick Pérez, Michael Zollhöfer, and Christian Theobalt. 2020a. PIE: Portrait image embedding for semantic control. ACM Transactions on Graphics (TOG) 39, 6 (2020), 1–14.
Ayush Tewari, Mohamed Elgharib, Gaurav Bharaj, Florian Bernard, Hans-Peter Seidel, Patrick Pérez, Michael Zollhofer, and Christian Theobalt. 2020b. StyleRig: Rigging StyleGAN for 3D control over portrait images. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6142–6151.
Justus Thies, Michael Zollhöfer, and Matthias Nießner. 2019. Deferred neural rendering: Image synthesis using neural textures. Acm Transactions on Graphics (TOG) 38, 4 (2019), 1–12.
Justus Thies, Michael Zollhöfer, Matthias Nießner, Levi Valgaerts, Marc Stamminger, and Christian Theobalt. 2015. Real-time expression transfer for facial reenactment. ACM Transactions on Graphics (TOG) 34, 6 (2015), 183–1.
Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nießner. 2016. Face2Face: Real-time face capture and reenactment of RGB videos. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2387–2395.
Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. 2021. Designing an encoder for StyleGAN image manipulation. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–14.
Daniel Vlasic, Matthew Brand, Hanspeter Pfister, and Jovan Popović. 2005. Face transfer with multilinear models. ACM Transactions on Graphics (TOG) 24, 3 (2005), 426–433.
Daoye Wang, Prashanth Chandran, Gaspard Zoss, Derek Bradley, and Paulo Gotardo. 2022a. MoRF: Morphable radiance fields for multiview neural head modeling. In ACM SIGGRAPH 2022 Conference Proceedings. 1–9.
Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. 2020. MEAD: A large-scale audio-visual dataset for emotional talking-face generation. In European Conference on Computer Vision (ECCV). Springer, 700–717.
Lizhen Wang, Zhiyuan Chen, Tao Yu, Chenguang Ma, Liang Li, and Yebin Liu. 2022b. FaceVerse: a fine-grained and detail-controllable 3D face morphable model from a hybrid dataset. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 20333–20342.
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. 2021b. Towards Real-World blind face restoration with generative facial prior. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9168–9178.
Ziyan Wang, Timur Bagautdinov, Stephen Lombardi, Tomas Simon, Jason Saragih, Jessica Hodgins, and Michael Zollhofer. 2021a. Learning Compositional Radiance Fields of Dynamic Human Heads. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5704–5713.
Shih-En Wei, Jason Saragih, Tomas Simon, Adam W Harley, Stephen Lombardi, Michal Perdoch, Alexander Hypes, Dawei Wang, Hernan Badino, and Yaser Sheikh. 2019.
VR facial animation via multiview image translation. ACM Transactions on Graphics (TOG) 38, 4 (2019), 1–16.
Thibaut Weise, Sofien Bouaziz, Hao Li, and Mark Pauly. 2011. Realtime performance- based facial animation. ACM transactions on graphics (TOG) 30, 4 (2011), 1–10.
Jianfeng Xiang, Jiaolong Yang, Yu Deng, and Xin Tong. 2022. GRAM-HD: 3D-Consistent image generation at high resolution with generative radiance manifolds. arXiv preprint arXiv:2206.07255 (2022).
Yuelang Xu, Lizhen Wang, Xiaochen Zhao, Hongwen Zhang, and Yebin Liu. 2023a. AvatarMAV: Fast 3D Head Avatar Reconstruction Using Motion-Aware Neural Voxels. In ACM SIGGRAPH 2023 Conference Proceedings.
Yuelang Xu, Hongwen Zhang, Lizhen Wang, Xiaochen Zhao, Han Huang, Guojun Qi, and Yebin Liu. 2023b. LatentAvatar: Learning Latent Expression Code for Expressive Neural Head Avatar. In ACM SIGGRAPH 2023 Conference Proceedings.
Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Yujiu Yang. 2022. StyleHEAT: One-shot high- resolution editable talking face generation via pre-trained StyleGAN. In European Conference on Computer Vision (ECCV). Springer, 85–101.
Yufeng Zheng, Victoria Fernández Abrevaya, Marcel C Bühler, Xu Chen, Michael J Black, and Otmar Hilliges. 2022a. IM Avatar: Implicit morphable head avatars from videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13545–13555.
Yufeng Zheng, Wang Yifan, Gordon Wetzstein, Michael J Black, and Otmar Hilliges. 2022b. PointAvatar: Deformable Point-based Head Avatars from Videos. arXiv preprint arXiv:2212.08377 (2022).
Zerong Zheng, Xiaochen Zhao, Hongwen Zhang, Boning Liu, and Yebin Liu. 2023. AvatarReX: Real-time Expressive Full-body Avatars. ACM Transactions on Graphics (TOG) 42, 4 (2023), 1–19. https://doi.org/10.1145/3592101
Wojciech Zielonka, Timo Bolkart, and Justus Thies. 2022. Instant Volumetric Head Avatars. arXiv preprint arXiv:2211.12499 (2022).
这篇关于StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video 译文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




