本文主要是介绍[论文阅读]Automatic Chinese Font Generation System Reflecting Emotions Based on Generative Adversarial..,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
该文提出了一种情感引导的中文字体自动生成框架:基于生成对抗网络的中文字体自动生成框架,使生成的字体能够反映人类的情感信息。主要两方面为其打基础,一方面,腾讯公司开发了一个详细的问卷系统,旨在定量地找出字体和情绪之间的关系。并基于训练好的模型设计了视觉表情识别部分,为字体生成模块提供条件信息。另一方面,提出了一种基于情感距离和梯度惩罚的情感引导方法,以及分类策略,用于生成由表情识别模块推断的多种风格组合的新字体,可用于不同场景。
使用瓦瑟斯坦距离(情感距离)的原因:由于Zi2Zi模型可以利用成双图像作为训练数据自动生成字体,但是因为模型崩溃以及不稳定,Zi2Zi模型很难训练,导致不知道模型训练的度量,生成器和鉴别器的性能很难平衡,所以一些生成的字体图像有些模糊。使用情感距离可以通过测量生成的图像和真实图像之间的差异来反映训练性能。
使用梯度惩罚的原因:可以增强模型的稳定性,并提高生成图像的质量。
自动字体生成系统的优势:允许不需要专业字体设计能力的普通用户改变字体来传达某种情绪,并在模型中加入了分类损失,以便获得准确的风格结果。
本文的主要贡献可以概括如下:
1、提出并设计了一个问卷系统来定量和定性地研究字体和面部表情之间的关系。数据分析表明,该系统具有较高的可信度,为进一步研究提供了数据集。
2、提出了一个情感引导算法;通过在字体生成模块上使用情绪引导操作,自动中文字体生成系统能够生成具有相应情绪的新风格的中文字体
3、结合了EM距离、梯度惩罚和分类策略,使字体生成模块能够生成高质量的字体图像,并确保每种字体都有一致的样式。
4、在各种中文字体数据集上进行各种实验策略。实验结果被用作建议分析的其他问卷的基础,并且表明生成的字体对于特定的情感是可信的。
基于Zi2Zi的情感引导GAN算法(EG-GAN):融合了地球动子距离和梯度惩罚以及分类损失,该算法从随机噪声向量z中学习映射,并观察到源字体图像x与两个条件单相结合,这两个条件单包含风格信息s 和分类信息f 到y, G{x,s,f,z}→y .生成器G被训练为产生域图像,该域图像不能通过相应的训练鉴别器D来区分生成的图像和真实图像,该鉴别器被训练为尽可能地识别生成器的输出。

在生成字体中,系统训练模块,直到鉴别器无法区分真实字体和生成字体,之后利用预先训练好的模型对输入图像的面部表情进行识别,从而引导生成器生成具有特定情绪的新字体。


面部信息提取模块:以面部图像(转换成48*48的灰度图像)作为输入,计算前两个概率,并进行数据调整过程,以指导具有特定风格的新字体生成。表情识别模块计算包括“愤怒”、“厌恶”、“恐惧”、“快乐”、“中性”、“悲伤”和“惊讶”在内的七种表情的概率。为了保证生成的汉字字体准确反映情感,作者选择表情识别模块结果的前两个概率(c1,c2)来保证两个数据c1,c2被调整为标准数据,![]() 和
和![]() 正则化用法作为字体生成过程的组合样式标签。
正则化用法作为字体生成过程的组合样式标签。
实验结果:
当输入具有特定情绪的面部图像时,通过组合情绪的前两个概率来生成新的字体。


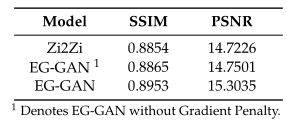
实验中使用了SSIM和PSNR度量来暗示与基线相比更低的数值差异。SSIM用于评估两幅图像之间的亮度、对比度和结构。SSIM分数越高,对图像失真的描述越清晰。PSNR是真实图像和重建图像之间的比率,用于测量图像的质量。
这篇关于[论文阅读]Automatic Chinese Font Generation System Reflecting Emotions Based on Generative Adversarial..的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









