本文主要是介绍ElasticSearch 文档分值 score 计算聚合搜索案例分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、ElasticSearch 文档分值_score 计算底层原理
Lucene(或 Elasticsearch)使用 布尔模型(Boolean model) 查找匹配文档,并用一个名为 实用评分函数(practical scoring function) 的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率(term frequency/inverse document frequency) 和 向量空间模型(vector space model),同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
布尔模型
布尔模型(Boolean Model) 只是在查询中使用 AND 、 OR 和 NOT (与、或和非)这样的条件来查找匹配的文档,以下查询:
full AND text AND search AND (elasticsearch OR lucene)会将所有包括词 full 、 text 和 search ,以及 elasticsearch 或 lucene 的文档作为结果集。
这个过程简单且快速,它将所有可能不匹配的文档排除在外。
词频/逆向文档频率(TF/IDF)
当匹配到一组文档后,需要根据相关度排序这些文档,不是所有的文档都包含所有词,有些词比其他的词更重要。一个文档的相关度评分部分取决于每个查询词在文档中的 权重 。
词频
词在文档中出现的频度是多少?频度越高,权重 越高 。 5 次提到同一词的字段比只提到 1 次的更相关。词频的计算方式如下:
tf(t in d) = √frequency 词 t 在文档 d 的词频( tf )是该词在文档中出现次数的平方根。
如果不在意词在某个字段中出现的频次,而只在意是否出现过,则可以在字段映射中禁用词频统计:
PUT /my_index
{"mappings": {"doc": {"properties": {"text": {"type": "string","index_options": "docs" }}}}
}
将参数 index_options 设置为 docs 可以禁用词频统计及词频位置,这个映射的字段不会计算词的出现次数,对于短语或近似查询也不可用。要求精确查询的 not_analyzed 字符串字段会默认使用该设置。
逆向文档频率
词在集合所有文档里出现的频率是多少?频次越高,权重 越低 。常用词如 and 或 the 对相关度贡献很少,因为它们在多数文档中都会出现,一些不常见词如 elastic 或 hippopotamus 可以帮助我们快速缩小范围找到感兴趣的文档。逆向文档频率的计算公式如下:
idf(t) = 1 + log ( numDocs / (docFreq + 1)) 词 t 的逆向文档频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。
字段长度归一值
字段的长度是多少?字段越短,字段的权重 越高 。如果词出现在类似标题 title 这样的字段,要比它出现在内容 body 这样的字段中的相关度更高。字段长度的归一值公式如下:
norm(d) = 1 / √numTerms 字段长度归一值( norm )是字段中词数平方根的倒数。
字段长度的归一值对全文搜索非常重要,许多其他字段不需要有归一值。无论文档是否包括这个字段,索引中每个文档的每个 string 字段都大约占用 1 个 byte 的空间。对于 not_analyzed 字符串字段的归一值默认是禁用的,而对于 analyzed 字段也可以通过修改字段映射禁用归一值:
PUT /my_index
{"mappings": {"doc": {"properties": {"text": {"type": "string","norms": { "enabled": false } }}}}
}
这个字段不会将字段长度归一值考虑在内,长字段和短字段会以相同长度计算评分。
对于有些应用场景如日志,归一值不是很有用,要关心的只是字段是否包含特殊的错误码或者特定的浏览器唯一标识符。字段的长度对结果没有影响,禁用归一值可以节省大量内存空间。
结合使用
以下三个因素——词频(term frequency)、逆向文档频率(inverse document frequency)和字段长度归一值(field-length norm)——是在索引时计算并存储的。最后将它们结合在一起计算单个词在特定文档中的 权重 。
前面公式中提到的 文档 实际上是指文档里的某个字段,每个字段都有它自己的倒排索引,因此字段的 TF/IDF 值就是文档的 TF/IDF 值。
当用 explain 查看一个简单的 term 查询时(参见 explain ),可以发现与计算相关度评分的因子就是前面章节介绍的这些:
PUT /my_index/doc/1
{ "text" : "quick brown fox" }GET /my_index/doc/_search?explain
{"query": {"term": {"text": "fox"}}
}以上请求(简化)的 explanation 解释如下:
weight(text:fox in 0) [PerFieldSimilarity]: 0.15342641
result of:
fieldWeight in 0 0.15342641
product of:
tf(freq=1.0), with freq of 1: 1.0
idf(docFreq=1, maxDocs=1): 0.30685282
fieldNorm(doc=0): 0.5
词 fox 在文档的内部 Lucene doc ID 为 0 ,字段是 text 里的最终评分。 | |
|---|---|
词 fox 在该文档 text 字段中只出现了一次。 | |
fox 在所有文档 text 字段索引的逆向文档频率。 | |
| 该字段的字段长度归一值。 |
当然,查询通常不止一个词,所以需要一种合并多词权重的方式——向量空间模型(vector space model)。
向量空间模型
向量空间模型(vector space model) 提供一种比较多词查询的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文档和查询都以 向量(vectors) 的形式表示:
向量实际上就是包含多个数的一维数组,例如:
[1,2,5,22,3,8]
在向量空间模型里,向量空间模型里的每个数字都代表一个词的 权重 ,与 词频/逆向文档频率(term frequency/inverse document frequency) 计算方式类似。
尽管 TF/IDF 是向量空间模型计算词权重的默认方式,但不是唯一方式。Elasticsearch 还有其他模型如 Okapi-BM25 。TF/IDF 是默认的因为它是个经检验过的简单又高效的算法,可以提供高质量的搜索结果。
设想如果查询 “happy hippopotamus” ,常见词 happy 的权重较低,不常见词 hippopotamus 权重较高,假设 happy 的权重是 2 , hippopotamus 的权重是 5 ,可以将这个二维向量—— [2,5] ——在坐标系下作条直线,线的起点是 (0,0) 终点是 (2,5) ,如图 Figure 27, “表示 “happy hippopotamus” 的二维查询向量” 。
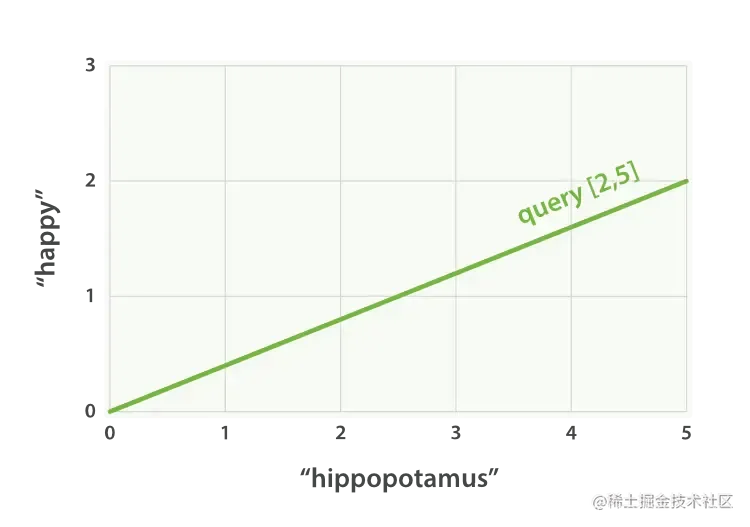
Figure 27. 表示 “happy hippopotamus” 的二维查询向量
现在,设想我们有三个文档:
- I am happy in summer 。
- After Christmas I’m a hippopotamus 。
- The happy hippopotamus helped Harry 。
可以为每个文档都创建包括每个查询词—— happy 和 hippopotamus ——权重的向量,然后将这些向量置入同一个坐标系中,如图 Figure 28, ““happy hippopotamus” 查询及文档向量” :
- 文档 1:
(happy,____________)——[2,0] - 文档 2:
( ___ ,hippopotamus)——[0,5] - 文档 3:
(happy,hippopotamus)——[2,5]
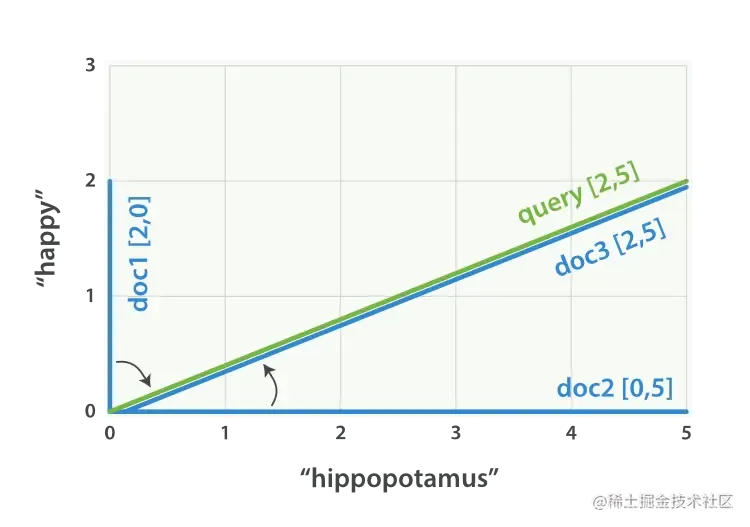
Figure 28. “happy hippopotamus” 查询及文档向量
向量之间是可以比较的,只要测量查询向量和文档向量之间的角度就可以得到每个文档的相关度,文档 1 与查询之间的角度最大,所以相关度低;文档 2 与查询间的角度较小,所以更相关;文档 3 与查询的角度正好吻合,完全匹配。
评分计算公式 score(q,d) =
queryNorm(q) //归一化因子 · coord(q,d) //协调因子 · ∑ (
tf(t in d) //词频 · idf(t)² //逆向文档频率 · t.getBoost() //权重 · norm(t,d) //字段长度归一值 ) (t in q)
下面简要介绍公式中新提及的三个参数:
queryNorm 查询归化因子:会被应用到每个文档,不能被更改,总而言之,可以被忽略。
coord 协调因子: 可以为那些查询词包含度高的文档提供奖励,文档里出现的查询词越多,它越有机会成为好的匹配结果。
协调因子将评分与文档里匹配词的数量相乘,然后除以查询里所有词的数量,如果使用协调因子,评分会变成:
文档里有 fox → 评分: 1.5 * 1 / 3 = 0.5 文档里有 quick fox → 评分: 3.0 * 2 / 3 = 2.0 文档里有 quick brown fox → 评分: 4.5 * 3 / 3 = 4.5 协调因子能使包含所有三个词的文档比只包含两个词的文档评分要高出很多。
Boost 权重:在查询中设置关键字的权重可以灵活的找到更匹配的文档。
测试准备
PUT /demo
PUT /demo/_mapping { "properties":{ "content":{ "type":"text" } } }
GET demo
POST demo/_doc { "content": "测试语句 3,字段长度不同" } POST /demo/_search{"query":{"match":{"content":"测"}}}
{"took" : 792,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 0.15120466,"hits" : [{"_index" : "demo","_type" : "_doc","_id" : "narolH0Byb0W9gti_JAl","_score" : 0.15120466,"_source" : {"content" : "测试语句 1"}},{"_index" : "demo","_type" : "_doc","_id" : "nqrplH0Byb0W9gtiaZA_","_score" : 0.15120466,"_source" : {"content" : "测试语句 2"}},{"_index" : "demo","_type" : "_doc","_id" : "n6rplH0Byb0W9gti2pCm","_score" : 0.108230695,"_source" : {"content" : "测试语句 3,字段长度不同"}}]}
}
可以看到,评分如我们所想得,文档 1 和 2 分数相同,而文档 3 因为长度更长,导致分数更低。
继续测试查询时权重的影响
POST /demo/_search?search_type=dfs_query_then_fetch
{"query": {"bool": {"should": [{"match": {"content": { "query": "1", "boost": 2 } }},{"match": { "content": "2" }}]}}
}
结果
{"took" : 109,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 2.2212896,"hits" : [{"_index" : "demo","_type" : "_doc","_id" : "narolH0Byb0W9gti_JAl","_score" : 2.2212896,"_source" : {"content" : "测试语句 1"}},{"_index" : "demo","_type" : "_doc","_id" : "nqrplH0Byb0W9gtiaZA_","_score" : 1.1106448,"_source" : {"content" : "测试语句 2"}}]}
}可以看到,由于给予搜索关键字1更高的权重,因此文档 1 的分数比文档 2 分数要高
二、聚合搜索技术深入
1.bucket 和 metric 概念简介
bucket 就是一个聚合搜索时的数据分组。如:销售部门有员工张三和李四,开发部门有员工王五和赵六。那么根据部门分组聚合得到结果就是两个 bucket。销售部门 bucket 中有张三和李四,
开发部门 bucket 中有王五和赵六。
metric 就是对一个 bucket 数据执行的统计分析。如上述案例中,开发部门有 2 个员工,销售部门有 2 个员工,这就是 metric。
metric 有多种统计,如:求和,最大值,最小值,平均值等。
用一个大家容易理解的 SQL 语法来解释,如:select count() from table group by column。那么 group by column 分组后的每组数据就是 bucket。对每个分组执行的 count()就是 metric。
2.准备案例数据
PUT /cars { "mappings": { "properties": { "price": { "type": "long" }, "color": { "type": "keyword" }, "brand": { "type": "keyword" }, "model": { "type": "keyword" }, "sold_date": { "type": "date" }, "remark" : { "type" : "text", "analyzer" : "ik_max_word" } } } }
POST /cars/_bulk { "index": {}} { "price" : 258000, "color" : "金色", "brand":"大众", "model" : "大众迈腾", "sold_date" : "2021-10-28","remark" : "大众中档车" } { "index": {}} { "price" : 123000, "color" : "金色", "brand":"大众", "model" : "大众速腾", "sold_date" : "2021-11-05","remark" : "大众神车" } { "index": {}} { "price" : 239800, "color" : "白色", "brand":"标志", "model" : "标志 508", "sold_date" : "2021-05-18","remark" : "标志品牌全球上市车型" } { "index": {}} { "price" : 148800, "color" : "白色", "brand":"标志", "model" : "标志 408", "sold_date" : "2021-07-02","remark" : "比较大的紧凑型车" } { "index": {}} { "price" : 1998000, "color" : "黑色", "brand":"大众", "model" : "大众辉腾", "sold_date" : "2021-08-19","remark" : "大众最让人肝疼的车" } { "index": {}} { "price" : 218000, "color" : "红色", "brand":"奥迪", "model" : "奥迪 A4", "sold_date" : "2021-11-05","remark" : "小资车型" } { "index": {}} { "price" : 489000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪 A6", "sold_date" : "2022-01-01","remark" : "政府专用?" } { "index": {}} { "price" : 1899000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪 A 8", "sold_date" : "2022-02-12","remark" : "很贵的大 A6。。。" } 3.聚合操作案例
3.1 根据 color 分组统计销售数量
只执行聚合分组,不做复杂的聚合统计。在 ES 中最基础的聚合为 terms,相当于 SQL 中的 count。
在 ES 中默认为分组数据做排序,使用的是 doc_count 数据执行降序排列。可以使用_key 元数据,根据分组后的字段数据执行不同的排序方案,也可以根据_count 元数据,根据分组后的统计值执行不同的排序方案。
GET /cars/_search
{"aggs":{"group_by_color":{"terms":{"field":"color","order":{"_count":"desc"}}}}
}3.2 统计不同 color 车辆的平均价格
本案例先根据 color 执行聚合分组,在此分组的基础上,对组内数据执行聚合统计,这个组内数据的聚合统计就是 metric。同样可以执行排序,因为组内有聚合统计,且对统计数据给予了命名 avg_by_price,所以可以根据这个聚合统计数据字段名执行排序逻辑。
GET /cars/_search
{"aggs":{"group_by_color":{"terms":{"field":"color","order":{"avg_by_price":"asc"}},"aggs":{"avg_by_price":{"avg":{"field":"price"}}}}}
}
size 可以设置为 0,表示不返回 ES 中的文档,只返回 ES 聚合之后的数据,提高查询速度,当然如果你需要这些文档的话,也可以按照实际情况进行设置
GET /cars/_search
{"size":0,"aggs":{"group_by_color":{"terms":{"field":"color"},"aggs":{"group_by_brand":{"terms":{"field":"brand","order":{"avg_by_price":"desc"}},"aggs":{"avg_by_price":{"avg":{"field":"price"}}}}}}}
}
3.3 统计不同 color 不同 brand 中车辆的平均价格
先根据 color 聚合分组,在组内根据 brand 再次聚合分组,这种操作可以称为下钻分析。
Aggs 如果定义比较多,则会感觉语法格式混乱,aggs 语法格式,有一个相对固定的结构,简单定义:aggs 可以嵌套定义,可以水平定义。
嵌套定义称为下钻分析。水平定义就是平铺多个分组方式。
GET /index_name/type_name/_search
{"aggs" : {"定义分组名称(最外层)": {"分组策略如:terms、avg、sum" : {"field" : "根据哪一个字段分组","其他参数" : ""},"aggs" : {"分组名称 1" : {},"分组名称 2" : {}}}}
}GET /cars/_search
{"aggs": {"group_by_color": {"terms": {"field": "color","order": {"avg_by_price_color": "asc"}},"aggs": {"avg_by_price_color": {"avg": {"field": "price"}},"group_by_brand": {"terms": {"field": "brand","order": {"avg_by_price_brand": "desc"}},"aggs": {"avg_by_price_brand": {"avg": {"field": "price"}}}}}}}
}
3.4 统计不同 color 中的最大和最小价格、总价
GET /cars/_search
{"aggs": {"group_by_color": {"terms": {"field": "color"},"aggs": {"max_price": {"max": {"field": "price"}},"min_price": {"min": {"field": "price"}},"sum_price": {"sum": {"field": "price"}}}}}
}在常见的业务常见中,聚合分析,最常用的种类就是统计数量,最大,最小,平均,总计等。通常占有聚合业务中的 60%以上的比例,小型项目中,甚至占比 85%以上。
3.5 统计不同品牌汽车中价格排名最高的车型
在分组后,可能需要对组内的数据进行排序,并选择其中排名高的数据。那么可以使用 s 来实现:top_top_hithits 中的属性 size 代表取组内多少条数据(默认为 10);sort 代表组内使用什么字段什么规则排序(默认使用_doc 的 asc 规则排序);_source 代表结果中包含 document 中的那些字段(默认包含全部字段)。
GET cars/_search
{"size": 0,"aggs": {"group_by_brand": {"terms": {"field": "brand"},"aggs": {"top_car": {"top_hits": {"size": 1,"sort": [{"price": {"order": "desc"}}],"_source": {"includes": ["model", "price"]}}}}}}
}3.6 histogram 区间统计
histogram 类似 terms,也是进行 bucket 分组操作的,是根据一个 field,实现数据区间分组。
如:以 100 万为一个范围,统计不同范围内车辆的销售量和平均价格。那么使用 histogram 的聚合的时候,field 指定价格字段 price。区间范围是 100 万-interval : 1000000。这个时候 ES 会将 price 价格区间划分为: [0, 1000000), [1000000, 2000000), [2000000, 3000000)等,依次类推。在划分区间的同时,histogram 会类似 terms 进行数据数量的统计(count),可以通过嵌套 aggs 对聚合分组后的组内数据做再次聚合分析。
GET /cars/_search
{"aggs": {"histogram_by_price": {"histogram": {"field": "price","interval": 1000000},"aggs": {"avg_by_price": {"avg": {"field": "price"}}}}}
}
3.7 date_histogram 区间分组
date_histogram 可以对 date 类型的 field 执行区间聚合分组,如每月销量,每年销量等。
如:以月为单位,统计不同月份汽车的销售数量及销售总金额。这个时候可以使用 date_histogram 实现聚合分组,其中 field 来指定用于聚合分组的字段,interval 指定区间范围(可选值有:year、quarter、month、week、day、hour、minute、second),format 指定日期格式化,min_doc_count 指定每个区间的最少 document(如果不指定,默认为 0,当区间范围内没有 document 时,也会显示 bucket 分组),extended_bounds 指定起始时间和结束时间(如果不指定,默认使用字段中日期最小值所在范围和最大值所在范围为起始和结束时间)。
7.X 之后
GET /cars/_search
{"aggs": {"histogram_by_date": {"date_histogram": {"field": "sold_date","calendar_interval": "month","format": "yyyy-MM-dd","min_doc_count": 1,"extended_bounds": {"min": "2021-01-01","max": "2022-12-31"}},"aggs": {"sum_by_price": {"sum": {"field": "price"}}}}}
}3.8 _global bucket
在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。
如:统计某品牌车辆平均价格和所有车辆平均价格。global 是用于定义一个全局 bucket,这个 bucket 会忽略 query 的条件,检索所有 document 进行对应的聚合统计。
GET /cars/_search
{"size": 0,"query": {"match": {"brand": "大众"}},"aggs": {"volkswagen_of_avg_price": {"avg": {"field": "price"}},"all_avg_price": {"global": {},"aggs": {"all_of_price": {"avg": {"field": "price"}}}}}
}3.9 aggs+order
对聚合统计数据进行排序。
如:统计每个品牌的汽车销量和销售总额,按照销售总额的降序排列。
GET /cars/_search
{"aggs": {"group_of_brand": {"terms": {"field": "brand","order": {"sum_of_price": "desc"}},"aggs": {"sum_of_price": {"sum": {"field": "price"}}}}}
}
如果有多层 aggs,执行下钻聚合的时候,也可以根据最内层聚合数据执行排序。
如:统计每个品牌中每种颜色车辆的销售总额,并根据销售总额降序排列。这就像 SQL 中的分组排序一样,只能组内数据排序,而不能跨组实现排序。
GET /cars/_search
{"aggs": {"group_by_brand": {"terms": {"field": "brand"},"aggs": {"group_by_color": {"terms": {"field": "color","order": {"sum_of_price": "desc"}},"aggs": {"sum_of_price": {"sum": {"field": "price"}}}}}}}
}3.10 search+aggs
聚合类似 SQL 中的 group by 子句,search 类似 SQL 中的 where 子句。在 ES 中是完全可以将 search 和 aggregations 整合起来,执行相对更复杂的搜索统计。
如:统计某品牌车辆每个季度的销量和销售额。
GET /cars/_search
{"query": {"match": {"brand": "大众"}},"aggs": {"histogram_by_date": {"date_histogram": {"field": "sold_date","calendar_interval": "quarter","min_doc_count": 1},"aggs": {"sum_by_price": {"sum": {"field": "price"}}}}}
}3.11 filter+aggs
在 ES 中,filter 也可以和 aggs 组合使用,实现相对复杂的过滤聚合分析。
如:统计 10 万~50 万之间的车辆的平均价格。
GET /cars/_search
{"query": {"constant_score": {"filter": {"range": {"price": {"gte": 100000,"lte": 500000}}}}},"aggs": {"avg_by_price": {"avg": {"field": "price"}}}
}3.12 聚合中使用 filter
filter 也可以使用在 aggs 句法中,filter 的范围决定了其过滤的范围。
如:统计某品牌汽车最近一年的销售总额。将 filter 放在 aggs 内部,代表这个过滤器只对 query 搜索得到的结果执行 filter 过滤。如果 filter 放在 aggs 外部,过滤器则会过滤所有的数据。
-
12M/M 表示 12 个月。
-
1y/y 表示 1 年。
-
d 表示天
GET /cars/_search
{"query": {"match": {"brand": "大众"}},"aggs": {"count_last_year": {"filter": {"range": {"sold_date": {"gte": "now-12M"}}},"aggs": {"sum_of_price_last_year": {"sum": {"field": "price"}}}}}
}这篇关于ElasticSearch 文档分值 score 计算聚合搜索案例分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




