本文主要是介绍基于YOLOv7的课堂行为检测,内涵BiFormer注意力和多种loss源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK
学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研;
目录
1.课堂行为检测介绍
2.BiFormer原理介绍
3.源码获取
1.课堂行为检测介绍

论文: https://arxiv.org/pdf/2310.02522.pdf
摘要:利用深度学习方法自动检测学生的课堂行为是分析学生课堂表现和提高教学效果的一种有前途的方法。 然而,缺乏关于学生行为的公开数据集给该领域的研究人员带来了挑战。 为了解决这个问题,我们提出了学生课堂行为数据集(SCB-dataset3),它代表了现实生活中的场景。 我们的数据集包含 5686 张图像和 45578 个标签,重点关注六种行为:举手、阅读、写作、使用手机、低头和靠在桌子上。 我们使用 YOLOv5、YOLOv7 和 YOLOv8 算法评估数据集,实现高达 80.3% 的平均精度(地图)。 我们相信,我们的数据集可以为学生行为检测的未来研究奠定坚实的基础,并为该领域的进步做出贡献。
智慧课堂学生行为检测评估算法通过yolo系列图像识别和行为分析,智慧课堂学生行为检测评估算法评估学生的表情、是否交头接耳行为、课堂参与度以及互动质量,并提供相应的反馈和建议。智慧课堂学生行为检测评估算法能够实时监测学生的上课行为,及时掌握学生的表情和参与度,为教师提供及时的反馈。智慧课堂学生行为检测评估算法中Yolo模型采用一个单独的CNN模型实现end-to-end的目标检测。


源码关注后获取:

2.BiFormer原理介绍
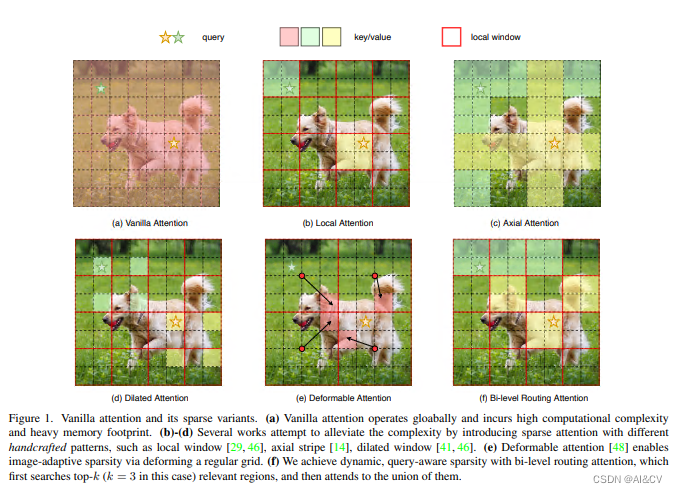
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
YOLOv8改进:注意力系列篇 | 动态稀疏注意力(BiLevelRoutingAttention) | CVPR2023-CSDN博客
源码:
from typing import Tupleimport torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from torch import Tensorclass TopkRouting(nn.Module):"""differentiable topk routing with scalingArgs:qk_dim: int, feature dimension of query and keytopk: int, the 'topk'qk_scale: int or None, temperature (multiply) of softmax activationwith_param: bool, wether inorporate learnable params in routing unitdiff_routing: bool, wether make routing differentiablesoft_routing: bool, wether make output value multiplied by routing weights"""def __init__(self, qk_dim, topk=4, qk_scale=None, param_routing=False, diff_routing=False):super().__init__()self.topk = topkself.qk_dim = qk_dimself.scale = qk_scale or qk_dim ** -0.5self.diff_routing = diff_routing# TODO: norm layer before/after linear?self.emb = nn.Linear(qk_dim, qk_dim) if param_routing else nn.Identity()# routing activationself.routing_act = nn.Softmax(dim=-1)def forward(self, query:Tensor, key:Tensor)->Tuple[Tensor]:"""Args:q, k: (n, p^2, c) tensorReturn:r_weight, topk_index: (n, p^2, topk) tensor"""if not self.diff_routing:query, key = query.detach(), key.detach()query_hat, key_hat = self.emb(query), self.emb(key) # per-window pooling -> (n, p^2, c) attn_logit = (query_hat*self.scale) @ key_hat.transpose(-2, -1) # (n, p^2, p^2)topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1) # (n, p^2, k), (n, p^2, k)r_weight = self.routing_act(topk_attn_logit) # (n, p^2, k)return r_weight, topk_indexclass KVGather(nn.Module):def __init__(self, mul_weight='none'):super().__init__()assert mul_weight in ['none', 'soft', 'hard']self.mul_weight = mul_weightdef forward(self, r_idx:Tensor, r_weight:Tensor, kv:Tensor):"""r_idx: (n, p^2, topk) tensorr_weight: (n, p^2, topk) tensorkv: (n, p^2, w^2, c_kq+c_v)Return:(n, p^2, topk, w^2, c_kq+c_v) tensor"""# select kv according to routing indexn, p2, w2, c_kv = kv.size()topk = r_idx.size(-1)# print(r_idx.size(), r_weight.size())# FIXME: gather consumes much memory (topk times redundancy), write cuda kernel? topk_kv = torch.gather(kv.view(n, 1, p2, w2, c_kv).expand(-1, p2, -1, -1, -1), # (n, p^2, p^2, w^2, c_kv) without mem cpydim=2,index=r_idx.view(n, p2, topk, 1, 1).expand(-1, -1, -1, w2, c_kv) # (n, p^2, k, w^2, c_kv))if self.mul_weight == 'soft':topk_kv = r_weight.view(n, p2, topk, 1, 1) * topk_kv # (n, p^2, k, w^2, c_kv)elif self.mul_weight == 'hard':raise NotImplementedError('differentiable hard routing TBA')# else: #'none'# topk_kv = topk_kv # do nothingreturn topk_kvclass QKVLinear(nn.Module):def __init__(self, dim, qk_dim, bias=True):super().__init__()self.dim = dimself.qk_dim = qk_dimself.qkv = nn.Linear(dim, qk_dim + qk_dim + dim, bias=bias)def forward(self, x):q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim+self.dim], dim=-1)return q, kv# q, k, v = self.qkv(x).split([self.qk_dim, self.qk_dim, self.dim], dim=-1)# return q, k, vclass BiLevelRoutingAttention(nn.Module):"""n_win: number of windows in one side (so the actual number of windows is n_win*n_win)kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.topk: topk for window filteringparam_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attentionparam_routing: extra linear for routingdiff_routing: wether to set routing differentiablesoft_routing: wether to multiply soft routing weights """def __init__(self, dim, n_win=7, num_heads=8, qk_dim=None, qk_scale=None,kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False, side_dwconv=3,auto_pad=True):super().__init__()# local attention settingself.dim = dimself.n_win = n_win # Wh, Wwself.num_heads = num_headsself.qk_dim = qk_dim or dimassert self.qk_dim % num_heads == 0 and self.dim % num_heads==0, 'qk_dim and dim must be divisible by num_heads!'self.scale = qk_scale or self.qk_dim ** -0.5################side_dwconv (i.e. LCE in ShuntedTransformer)###########self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \lambda x: torch.zeros_like(x)################ global routing setting #################self.topk = topkself.param_routing = param_routingself.diff_routing = diff_routingself.soft_routing = soft_routing# routerassert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=Falseself.router = TopkRouting(qk_dim=self.qk_dim,qk_scale=self.scale,topk=self.topk,diff_routing=self.diff_routing,param_routing=self.param_routing)if self.soft_routing: # soft routing, always diffrentiable (if no detach)mul_weight = 'soft'elif self.diff_routing: # hard differentiable routingmul_weight = 'hard'else: # hard non-differentiable routingmul_weight = 'none'self.kv_gather = KVGather(mul_weight=mul_weight)# qkv mapping (shared by both global routing and local attention)self.param_attention = param_attentionif self.param_attention == 'qkvo':self.qkv = QKVLinear(self.dim, self.qk_dim)self.wo = nn.Linear(dim, dim)elif self.param_attention == 'qkv':self.qkv = QKVLinear(self.dim, self.qk_dim)self.wo = nn.Identity()else:raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')self.kv_downsample_mode = kv_downsample_modeself.kv_per_win = kv_per_winself.kv_downsample_ratio = kv_downsample_ratioself.kv_downsample_kenel = kv_downsample_kernelif self.kv_downsample_mode == 'ada_avgpool':assert self.kv_per_win is not Noneself.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)elif self.kv_downsample_mode == 'ada_maxpool':assert self.kv_per_win is not Noneself.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)elif self.kv_downsample_mode == 'maxpool':assert self.kv_downsample_ratio is not Noneself.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()elif self.kv_downsample_mode == 'avgpool':assert self.kv_downsample_ratio is not Noneself.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()elif self.kv_downsample_mode == 'identity': # no kv downsamplingself.kv_down = nn.Identity()elif self.kv_downsample_mode == 'fracpool':# assert self.kv_downsample_ratio is not None# assert self.kv_downsample_kenel is not None# TODO: fracpool# 1. kernel size should be input size dependent# 2. there is a random factor, need to avoid independent sampling for k and v raise NotImplementedError('fracpool policy is not implemented yet!')elif kv_downsample_mode == 'conv':# TODO: need to consider the case where k != v so that need two downsample modulesraise NotImplementedError('conv policy is not implemented yet!')else:raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')# softmax for local attentionself.attn_act = nn.Softmax(dim=-1)self.auto_pad=auto_paddef forward(self, x, ret_attn_mask=False):"""x: NHWC tensorReturn:NHWC tensor"""x = rearrange(x, "n c h w -> n h w c")# NOTE: use padding for semantic segmentation###################################################if self.auto_pad:N, H_in, W_in, C = x.size()pad_l = pad_t = 0pad_r = (self.n_win - W_in % self.n_win) % self.n_winpad_b = (self.n_win - H_in % self.n_win) % self.n_winx = F.pad(x, (0, 0, # dim=-1pad_l, pad_r, # dim=-2pad_t, pad_b)) # dim=-3_, H, W, _ = x.size() # padded sizeelse:N, H, W, C = x.size()assert H%self.n_win == 0 and W%self.n_win == 0 ##################################################### patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv sizex = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)#################qkv projection#################### q: (n, p^2, w, w, c_qk)# kv: (n, p^2, w, w, c_qk+c_v)# NOTE: separte kv if there were memory leak issue caused by gatherq, kv = self.qkv(x) # pixel-wise qkv# q_pix: (n, p^2, w^2, c_qk)# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean([2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)##################side_dwconv(lepe)################### NOTE: call contiguous to avoid gradient warning when using ddplepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win, i=self.n_win).contiguous())lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)############ gather q dependent k/v #################r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensorskv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) #(n, p^2, topk, h_kv*w_kv, c_qk+c_v)k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)######### do attention as normal ####################k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c', m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)# param-free multihead attentionattn_weight = (q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)attn_weight = self.attn_act(attn_weight)out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,h=H//self.n_win, w=W//self.n_win)out = out + lepe# output linearout = self.wo(out)# NOTE: use padding for semantic segmentation# crop padded regionif self.auto_pad and (pad_r > 0 or pad_b > 0):out = out[:, :H_in, :W_in, :].contiguous()if ret_attn_mask:return out, r_weight, r_idx, attn_weightelse:return rearrange(out, "n h w c -> n c h w")class Attention(nn.Module):"""vanilla attention"""def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weightsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):"""args:x: NCHW tensorreturn:NCHW tensor"""_, _, H, W = x.size()x = rearrange(x, 'n c h w -> n (h w) c')#######################################B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)#######################################x = rearrange(x, 'n (h w) c -> n c h w', h=H, w=W)return xclass AttentionLePE(nn.Module):"""vanilla attention"""def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., side_dwconv=5):super().__init__()self.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weightsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \lambda x: torch.zeros_like(x)def forward(self, x):"""args:x: NCHW tensorreturn:NCHW tensor"""_, _, H, W = x.size()x = rearrange(x, 'n c h w -> n (h w) c')#######################################B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)lepe = self.lepe(rearrange(x, 'n (h w) c -> n c h w', h=H, w=W))lepe = rearrange(lepe, 'n c h w -> n (h w) c')attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = x + lepex = self.proj(x)x = self.proj_drop(x)#######################################x = rearrange(x, 'n (h w) c -> n c h w', h=H, w=W)return x3.源码获取
若无法找到源码工程,关注我私信免费获取!!!
若无法找到源码工程,关注我私信免费获取!!!
若无法找到源码工程,关注我私信免费获取!!!
这篇关于基于YOLOv7的课堂行为检测,内涵BiFormer注意力和多种loss源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




