本文主要是介绍读论文:Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
标题: 卷积LSTM网络:一种用于降水临近预报的机器学习方法
作者: Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung,Wai-kin Wong, Wang-chun Woo
文章目录
- ==Abstract==
- ==Introduction==
- 前言
- 降水临近预报问题的建立
- LSTM
- ==综述==
- 一、模型
- 1.1 ConvLSTM
- 3.2 Encoding-Forecasting Structure
- 二、实验
- 2.1 Moving-MNIST Dataset
- 2.2 Radar Echo Dataset
- ==总结==
- ==未来展望==
Abstract
降水预报的目标是预测一个地区在较短时间内的降雨强度。以前很少有研究从机器学习的角度来研究这方面的问题。本文将降水临近预报定义为一个时空序列预测问题,其中的输入和输出结果都是时空序列。再通过扩展FC-LSTM(全连通LSTM)为ConvLSTM(卷积LSTM),使其在输入到状态和状态到状态的转换中都具有卷积结构。并利用它建立了降水临近预报问题的端到端可训练模型。实验表明,本文的ConvLSTM网络能够更好地捕捉时空相关性,且始终优于FC-LSTM和ROVER算法。
Index Term:ConvLSTM, precipitation nowcasting, spatiotemporal sequences
Introduction
- 现代的降水预报方法大致分为两类:
- 数值天气预报(NWP):指根据大气实况,在一定的初值和边界条件下,通过大型计算机作数值计算,求解描写天气演变过程的流体力学和热力学的方程组,预测未来一定时间段的大气运动状态和天气现象的方法。但是其对于即时预报需要十分复杂的过程;
- 雷达外推方法:主要是通过模型训练来预测云层的移动,可以充分的利用雷达回波图历史数据,有效的捕获时空相关性。但是由于流量估计步骤和雷达回波外推步骤是分开的,并且很难确定模型参数以提供良好的预测性能,从而限制了其发挥;
- 而上述的技术问题都可以从机器学习的角度来解决:本质上,降水临近预报是一个以输入过去雷达地图的序列,输出未来雷达地图的固定数(通常大于1)的序列的时空序列预测问题
前言
降水临近预报问题的建立
降水临近预报的目标是利用先前观测到的雷达回波序列来预测当地地区(如香港、纽约或东京)的未来雷达地图的固定长度。在实际应用中,雷达地图通常每6-10分钟从天气雷达上获取一次,并在接下来的1-6小时内进行临近预报,即预测前方的6-60帧。降水预报实际上是时空预测问题;
如果我们将地图划分为平铺的不重叠的小块,并将小块内部的像素作为其测量值,如下图所示。那么即时预报问题自然就变成了一个时空序列预测问题
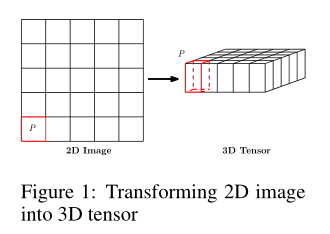
每个正方形小格点代表1×1公里,可以看做一个地区。p值为降雨量/雷达反射率(它和降雨量之间有关系可以转换)
时空序列预报问题就是通过之前的J个观测信息去预测未来最可能的K长序列:
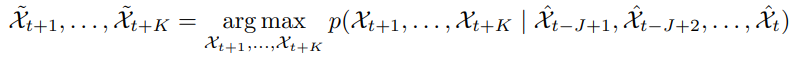
LSTM
LSTM模型,是循环神经网络的一种变体,可以很有效的解决简单循环神经网络的梯度爆炸或消失问题,其公式如下:
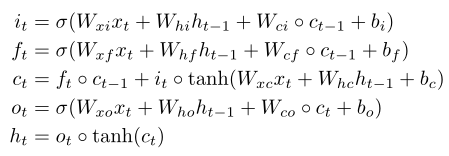
遗忘门ft,控制上一时刻的内部状态ct-1需要遗忘多少信息;
输入门it,控制当前时刻的候选状态有多少信息需要保存;
ct:非线性函数得到的候选状态
输出门ot,控制当前时刻的内部状态ct有多少信息需要输出给外部状态ht;
LSTM网络中的门是一种软门,取值在(0,1)之间,表示以一定的比例运行信息通过;
LSTM网络引入一个新的内部状态Ct专门进行线性的循环信息传递,同时(非线性)输出信息给隐藏层的外部状态ht;
综述
一、模型
1.1 ConvLSTM
FC-LSTM在处理时空数据方面的主要缺点是它在没有进行空间信息编码的输入到状态和状态到状态的转换中使用了完全连接,缺乏空间信息的提取;
为此 ,本文设计了ConvLSTM,其中的:

均为都是三维张量(另外两个维度是空间信息,行与列)。为了得到更好的输入和状态的照片,我们可以想象他们是向量在一个空间网格上.Conv-LSTM来决定网格中确定位置的cell的特征状态(通过输入和这个cell局部的过去状态),而这件事可以通过卷积来完成:
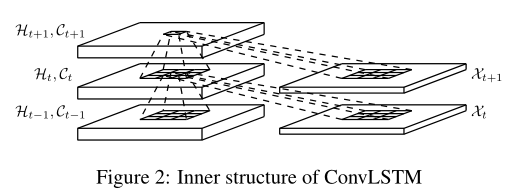
该过程的方程如下所示:

*表示卷积,⭕是hadamard积。公式其实就是把input-to-state, state-to-state 的正常乘积运算,用术语叫做hadamard乘积,改为卷积运算
本质上没有变化,做的事情基本上是将向量与权重的乘积,换成了卷积,这样能大大减少参数量
3.2 Encoding-Forecasting Structure
和FC-LSTM一样,Conv-LSTM可以作为一个模块被更多复杂结构使用。对于时空序列问题,我们使用的结构如下,一个编码网络和一个预测网络:
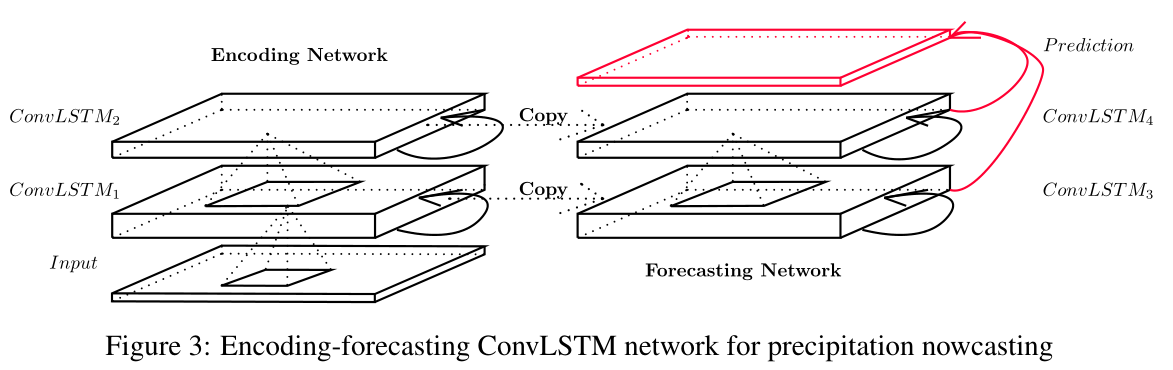
预测网络的初试的状态和cell输出从encoding网络最后状态直接复制过来。网络都是由几个ConvLSTM层堆叠而成。因为我们预测的target与输入维数是相同的,我们在预测网络中拼接所有的状态(隐层状态),然后将他们丢入1*1卷积层来生成最终的预测
encodingLSTM压缩了整个输入序列为一个隐层层状态张量,然后forecatsingLSTM展开这个隐层状态,给出最终预测:
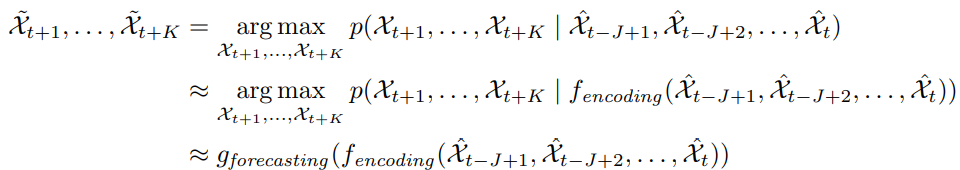
二、实验
- 作者用当前的模型用在Mnist-Moving数据集上,并且尝试不同的stacking的层数,kernel的大小以及前面说到的out-of-domain,来查看模型的效果;
- 为了说明所提出的模型在比较难的问题上有一定的提升作用,文中主要提到的是降水预测这个方面,相当于做了一个baseline的工作,并且与降水预测的传统算法做了个对比
2.1 Moving-MNIST Dataset
数据集为图中 有两个数字的时空序列的移动。 大小为64乘以64, 整个序列为20,前十个为输入数据,后十个为预测数据。结果如下表和图所示:

’ -5x5 ‘和’ -1x1 ‘表示相应的状态对状态内核大小,即5×5或1×1。“256”、“128”和“64”表示ConvLSTM层中隐藏状态的数量。’ (5x5) ‘和’ (9x9) '表示输入到状态的内核大小;
每个模型不管是多少层的,input-to-state的kernel size都为一致的,只有每层的state-to-state的kernel size在变,以及 hidden state的大小在变

从上到下分别是:输入帧;真实值;FC-LSTM;ConvLSTM-5X5-5X51-layer;ConvLSTM-5X5-5X5-2-layer;ConvLSTM-5X5-5X5-3-layer;ConvLSTM-9X9-1X1-2layer;ConvLSTM-9X9-1X1-3-layer。

上图是作者做的一个附加的实验,这个图主要是针对前面所说的out-of-domain来说的,就是说作者用两个数字的数据集去训练模型,最后来预测图片中带有三个数字的图片序列,来测试模型的泛化性
- 结论:
- ConvLSTM的效果比FC-LSTM的效果好;
- 更深的网络会更好,但是两层和三层差的不多;
- 1×1的state-to-state kernel size很难抓住时空移动的特征,所以效果差很多,所以更大的size更能够获取时空的联系;
2.2 Radar Echo Dataset
这里就是把LSTM用在雷达回波图上,做一个降水预测的应用。
由于不是每天都下雨,而本文的预报目标是降水,于是就选择前97个雨天所形成的数据集,因为如果无雨样本太多训练出来效果会出现全黑的图片,我们至少要保证每张图大于百分20的降雨量。和这张图差不多,不然预测效果会不理想:

实验结果如结果如表2,图5以及图6所示:
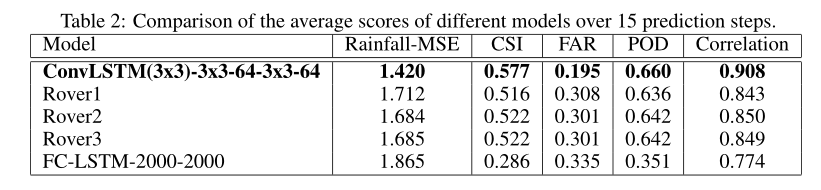
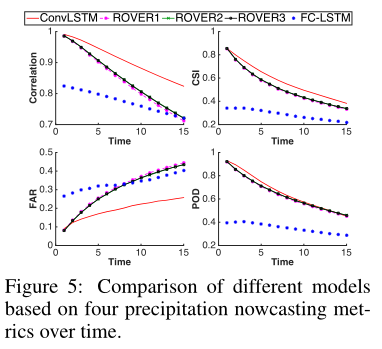

我们可以发现,FC-LSTM网络的性能并不好地完成这个任务,这主要是由于雷达地图上的强空间相关性,即云的运动在一个局部区域是高度一致的;
此外,还可以看出,ConvLSTM的性能优于基于光流的漫游者算法,这主要有两个原因。首先,ConvLSTM能够很好地处理边界条件。在现实生活中,有很多情况下,边界处突然聚集的云,这表明有些云是从外部来自的。如果ConvLSTM网络在训练过程中看到了类似的模式,它可以发现编码网络中这种类型的突然变化,并在预测网络中给出合理的预测。然而,这一点很难用基于光流和基于半拉格朗日平流的方法来实现。另一个原因是,ConvLSTM被端到端训练为该任务和数据中的一些复杂的时空模式
总结
本文已经成功地将机器学习方法,特别是深度学习,应用到具有挑战性的降水临近预报问题上。研究人员将降水临近预报定义为一个时空序列预测问题,并提出了ConvLSTM来解决这一问题;
未来展望
以后将研究如何将ConvLSTM应用于基于视频的动作识别。一种想法是在卷积神经网络生成的空间特征图上添加ConvLSTM,并使用ConvLSTM的隐藏状态进行最终的分类。
这篇关于读论文:Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

