本文主要是介绍二、BurpSuite Decoder解码器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、编码解码
解释:BurpSuite 可以用这个模块来轻松进行编码解码,下面是支持的类型
URL HTML Base64 ASCIIhex Hex Octal Binary Gzip
注意:特别注意的是URL编码,一般的在线网站都无法对比如‘abc’的文本编码,burpsuite可以轻松编码
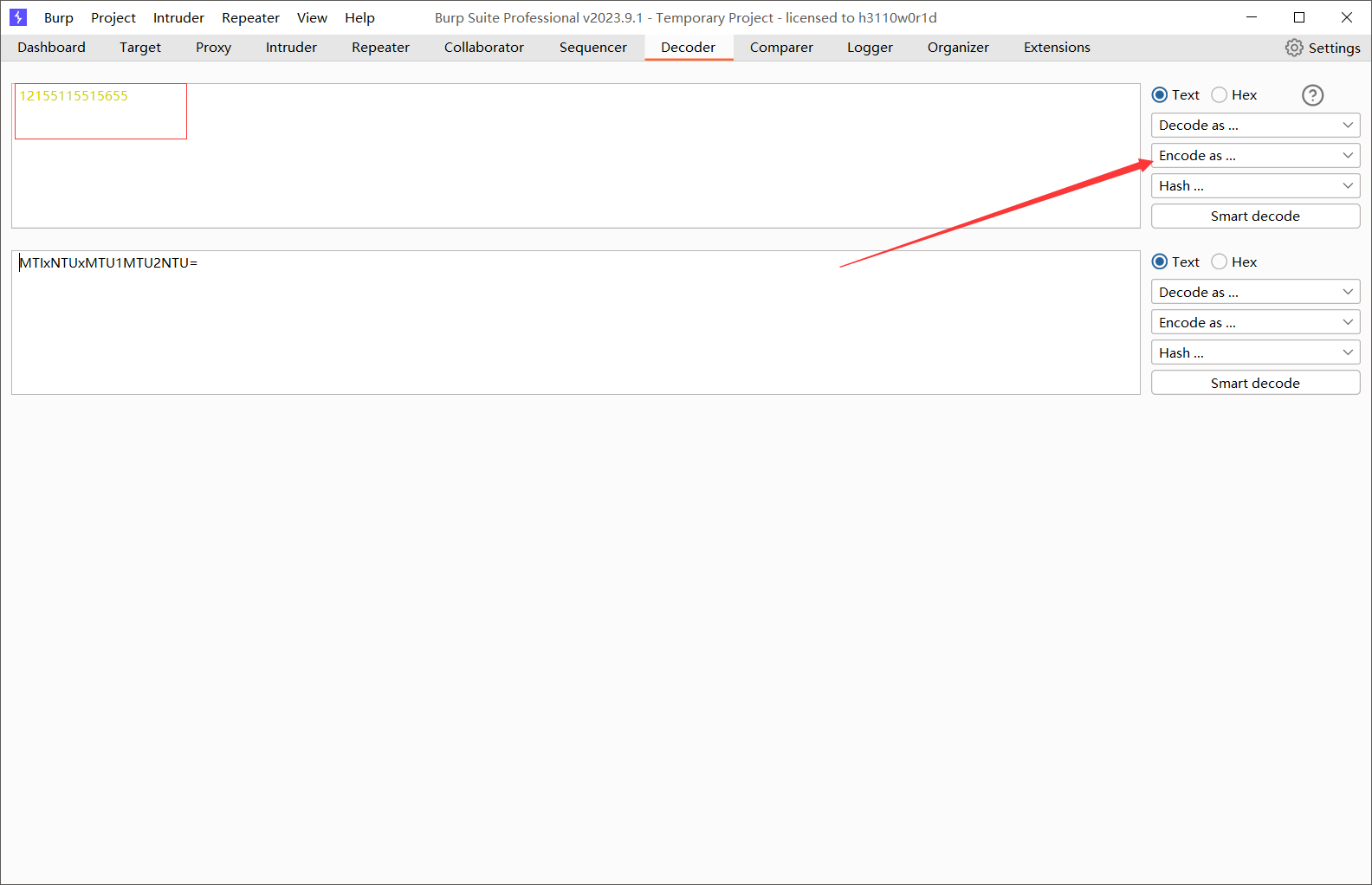
使用如下:
编码
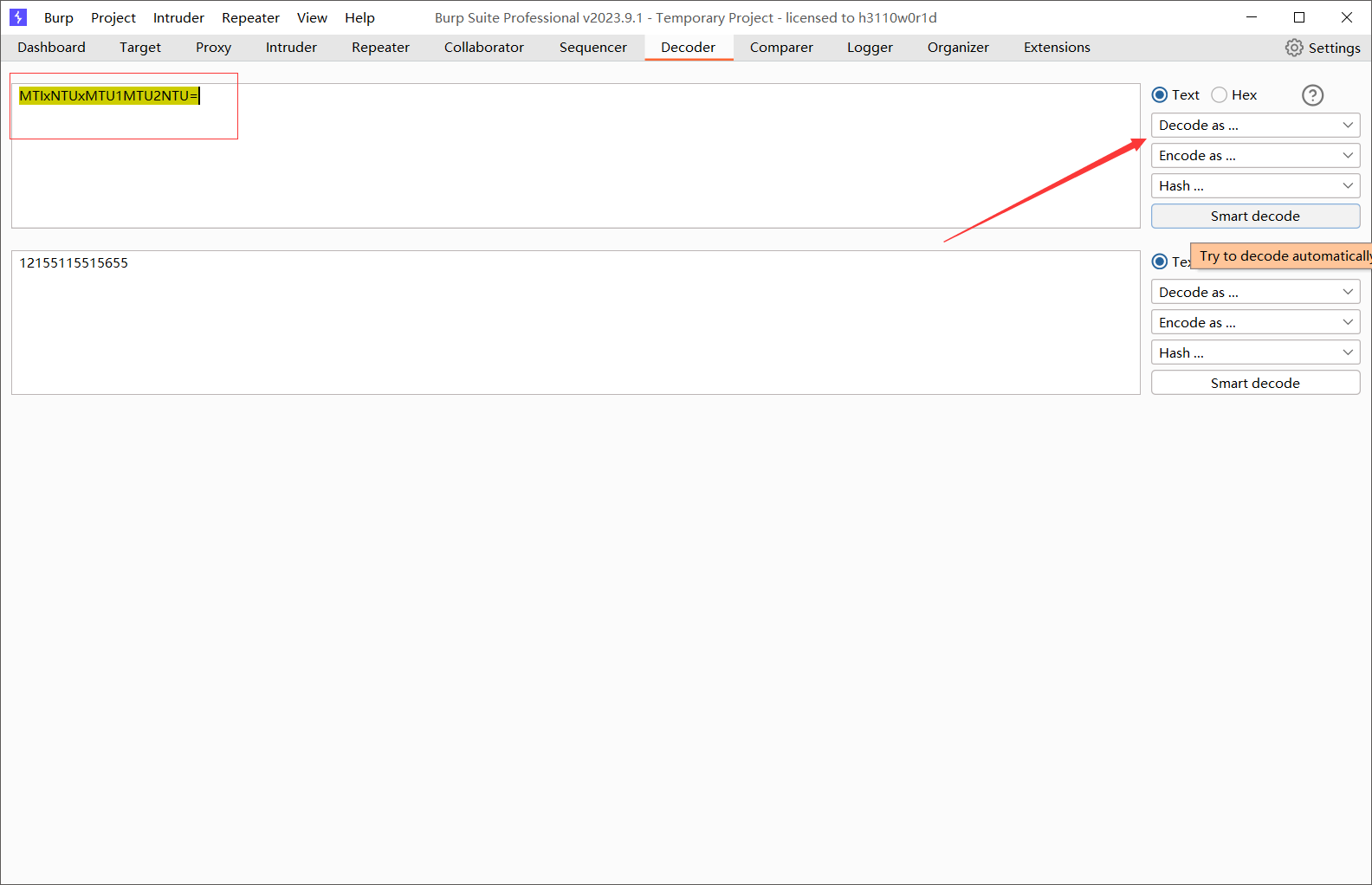
解码
二、加密
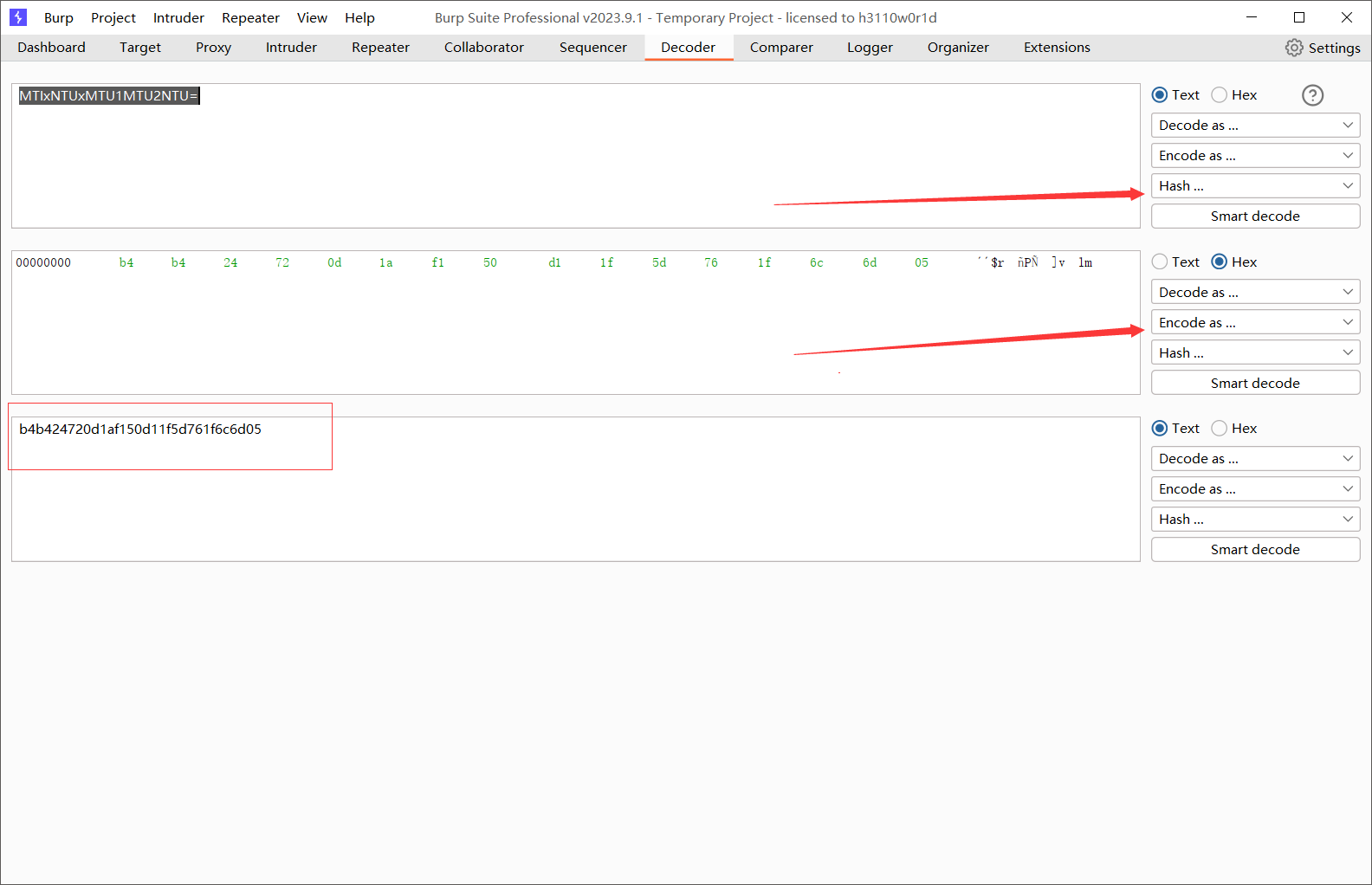
解释:特别说明,在burpsuite加密需要两部才能得到最后的结果
- 选择hash并在里面找到你想用来加密的算法
- 在下面的框框选择encode里面的Ascii hex才能看到加密后规整的结果
这篇关于二、BurpSuite Decoder解码器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!