本文主要是介绍【带你上手云原生体系】第三部分:Docker从入门到上天【非物质文化遗产宝藏篇!白话文精讲Namespace、Cgroup、OverlayFS、layer、Network】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【带你上手云原生体系】第一部分:文章简介 及 云原生思维概览
【带你上手云原生体系】第二部分:Go语言从入门到精通
【带你上手云原生体系】第三部分:Docker从入门到精通
【带你上手云原生体系】第四部分:Kubernetes从入门到精通
文章目录
- 1、引言
- 1.1、环境介绍
- 1.2、传统分层架构 vs 微服务
- 1.3、微服务改造
- 1.4、微服务间通讯
- 点对点
- API网关
- 1.5、Docker技术是什么
- 1.6、为什么要用Docker
- 1.7、虚拟机和容器运行态的对比
- 1.8、性能对比
- 1.9、容器标准
- 1.10、Docker优势
- 2、docker的安装、卸载、设置
- 2.1、安装docker
- 使用存储库安装
- 从包安装
- 使用便捷脚本安装
- 使用Vagrant file方式在virtualbox安装ubuntu、docker、k8s
- 2.2、卸载docker
- 2.3、为K8S做准备
- 设置docker的cgroup driver为systemd
- 关闭系统交换区(swap area)
- 3、Dockerfile讲解
- 3.1、重申12 Factor - Docker管理和构建应用的原则
- 3.2、理解构建上下文(Build Context)
- 3.3、Dockerfile文件示例
- docker build:把Dockerfile文件build成docker镜像
- 3.4、镜像构建日志解析
- 3.5、Build Cache
- 3.6、多段构建(Multi-stage build)
- 3.7、Dockerfile常用指令
- FROM:选择基础镜像
- LABELS:按标签组织项目
- RUN:运行命令
- CMD、ENTRYPOINT:容器启动时默认执行的命令
- EXPOSE:发布端口
- ENV、ARG:设置变量构建参数和设置环境变量
- ENV
- ARG
- ADD、COPY:文件复制
- WORKDIR:切换工作目录
- VOLUME:将指定目录定义为外挂存储卷
- USER:切换运行镜像的用户和用户组
- 不常用指令
- 3.8、Dockerfile最佳实践
- 3.9、多进程的容器镜像
- tini
- 4、docker的原理及技术实现
- 4.1、容器主要特性
- 4.2、Linux-Namespace技术
- Linux内核代码中Namespace的实现
- Linux对Namespace操作方法
- Linux Namespace种类
- 理解多个Namespace的关系和区别
- Namespace详解
- 关于namespace的常用操作
- 查看docker容器的网络配置信息
- 4.3、Linux-Cgroups
- 简介
- Linux内核代码中Cgroups的实现
- 可配额/可度量 - Control Groups (cgroups)
- CPU子系统
- cpuacct子系统
- memory子系统
- CPU子系统练习
- Memory子系统练习
- Cgroup driver
- 4.4、Linux进程调度策略
- CFS调度器
- vruntime红黑树
- CFS进程调度
- 4.5、文件系统 Union FS(联合文件系统)
- 文件系统是如何工作的?
- 典型的Linux文件系统组成
- Docker启动是如何加载文件系统的
- 写操作
- 容器存储驱动
- OverlayFS
- 4.6、Docker引擎架构
- shim
- 4.7、Docker网络
- Null模式
- 手动模拟Docker为容器建立bridge网络
- 默认模式 - 网桥和NAT
- 用命令去深度理解
- 4.8、解决跨主机的网络问题 - Underlay模式、Overlay模式
- 方法一:Underlay模式
- 方法二:Docker Libnetwork Overlay模式
- Flannel工具
- Docker命令手册
- Docker程序相关
- image相关
- 从registry拉取image
- 查看现有镜像image
- 删除镜像image
- 显示image更多详细信息
- 保存镜像到本地
- 载入本地镜像
- build dockerfile
- 镜像重命名
- 根据一个已经存在的image去创建一个新的image并使用新的tag
- 显示镜像分层
- 把镜像推送到仓库中
- container相关
- 查看容器
- 创建容器
- 进入容器内部
- 启动容器
- 停止容器
- 删除容器
- 查看容器ip地址
- 查看容器产生的log
- 查看容器内运行的进程
- 通过容器创建新的image
- 更新容器启动参数
- 获取容器/镜像的元数据
- 拷贝文件至容器内
1、引言
1.1、环境介绍
建议所有人使用Ubuntu虚拟机,防止后面因为一些网络配置或其他操作失误,导致你的电脑出现一些未知问题!!!
- MacOS 10.14.6
- VirtualBox 6.1.34
- ubuntu-20.04.4-live-server-amd64.iso
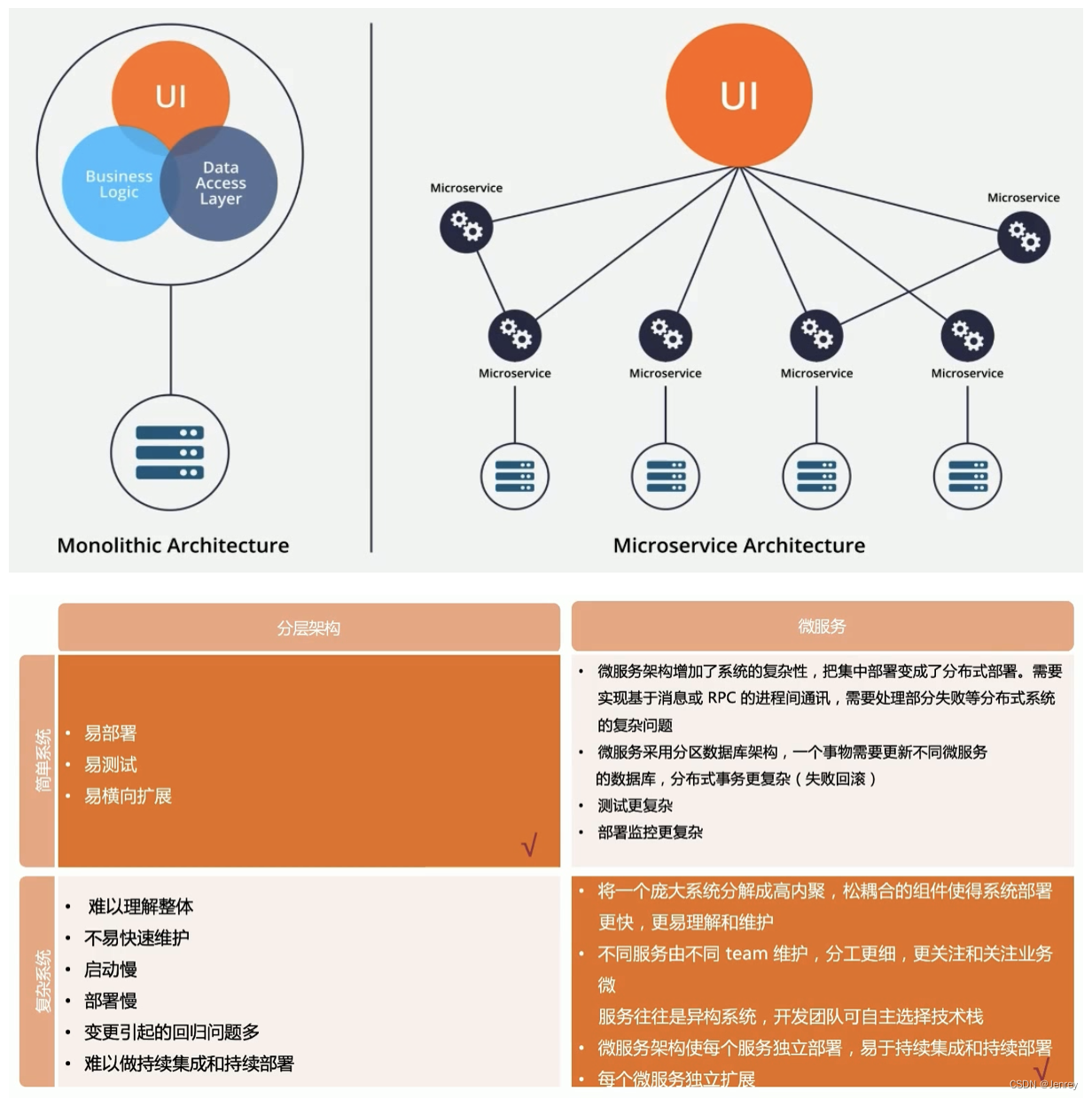
1.2、传统分层架构 vs 微服务
1.3、微服务改造
分离微服务的方法建议:
- 审视并发现可以分离的业务逻辑
- 寻找天生隔离的代码模块,可以借助于静态代码分析工具
- 不同并发规模,不同内存需求的模块都可以分离出不同的微服务,此方法可提高资源利用率,节省成本
一些常用的可微服务化的组件:
- 用户和账户管理
- 授权和会话管理
- 系统配置
- 通知和通讯服务
- 照片、多媒体、元数据等
分解原则:基于Size,scope and capabilities
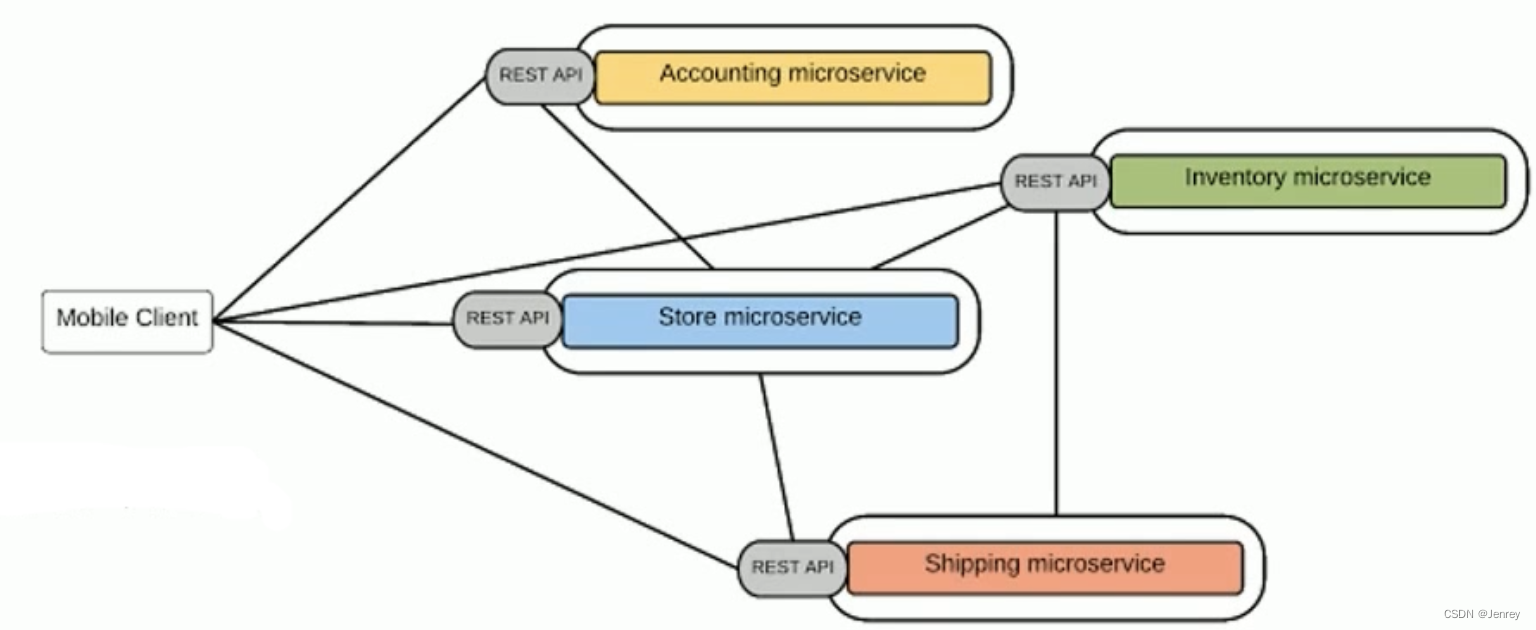
1.4、微服务间通讯
点对点
- 多用于系统内部多组件之间通讯
- 有大量的重复模块如认证授权
- 缺少统一规范,如监控、审计等功能
- 后期维护成本高,服务和服务的依赖关系错综复杂难以管理
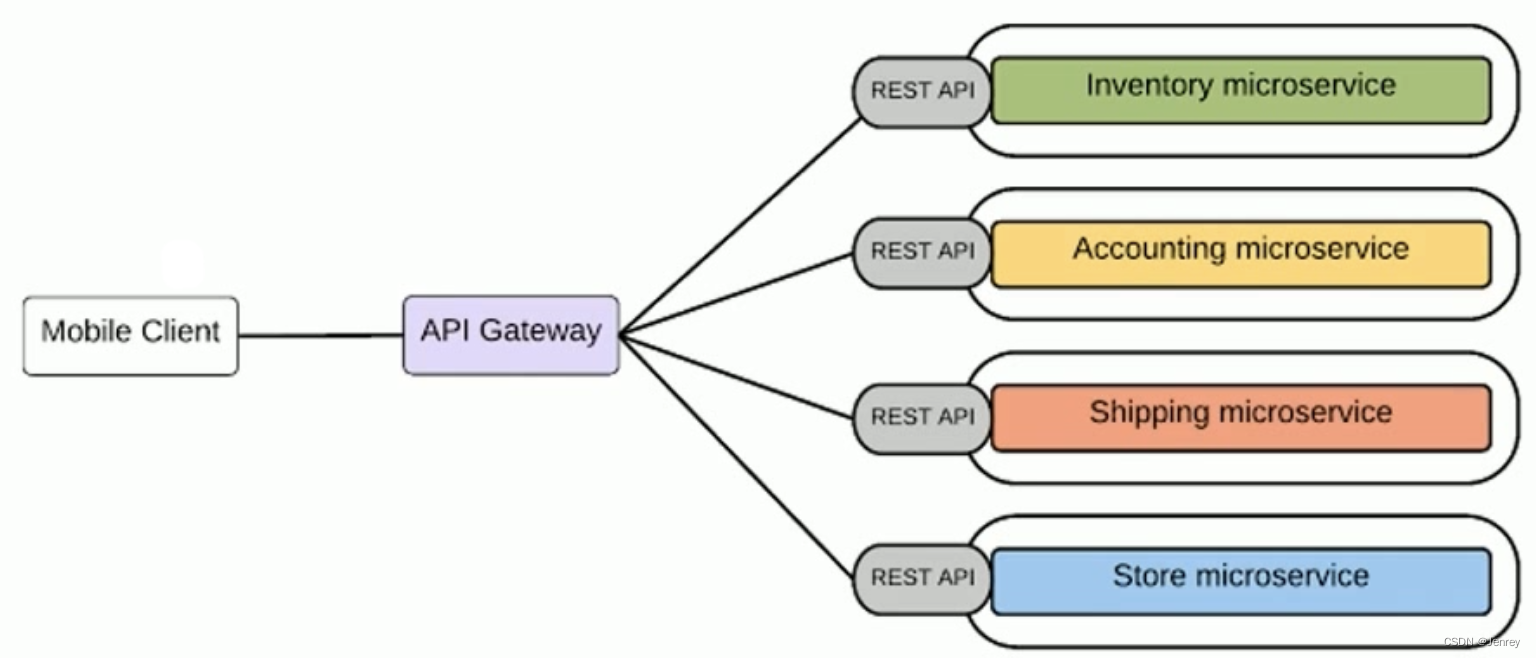
API网关
- 基于一个轻量级的message gateway
- 新API通过注册至Gateway实现
- 整合实现Common function
1.5、Docker技术是什么
- 基于Linux内核的Cgroup、Namespace 以及Union FS等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
- 最初实现是基于LXC,从0.7以后开始去除LXC,转而使用自行开发的Libcontainer,从1.11开始,则进一步演进为使用runC和Containerd。
- Docker在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护,使得Docker技术比虚拟机技术更为轻便、快捷。
1.6、为什么要用Docker
-
更高效地利用系统资源
-
更快速的启动时间
-
一致的运行环境
-
持续交付和部署
-
更轻松地迁移
-
更轻松地维护和扩展
-
…
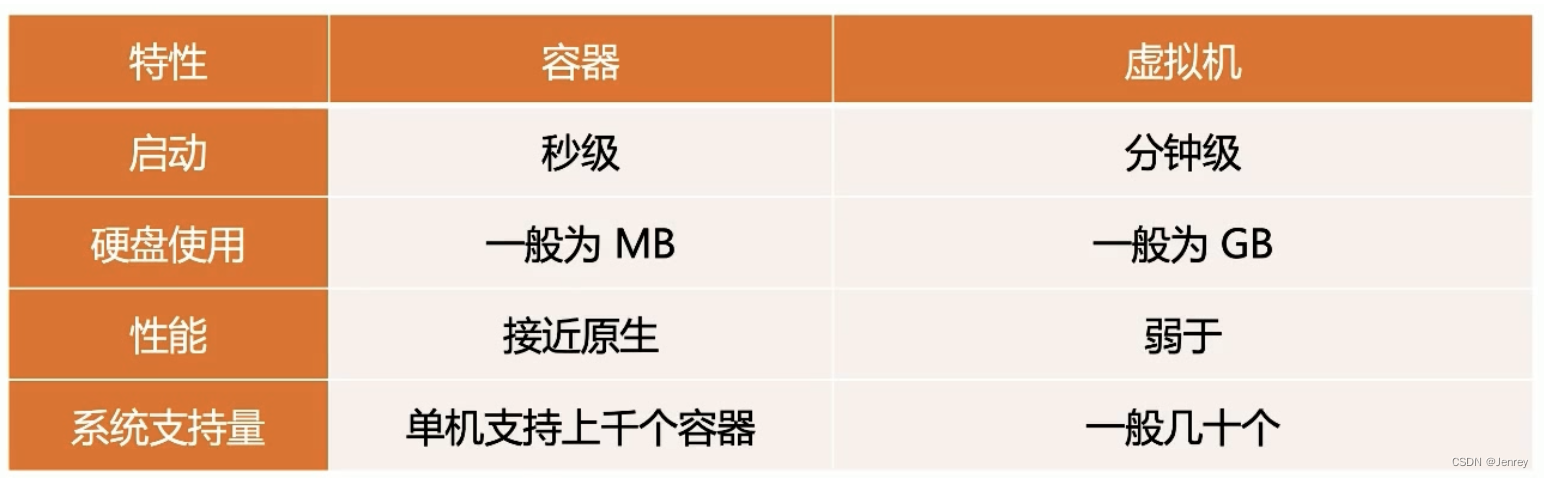
1.7、虚拟机和容器运行态的对比

Docker Engine就是一个docker进程(docker daemon),当我们要跑一个容器的时候,就是docker daemon fork一个新进程,仅此而已。
1.8、性能对比
1.9、容器标准
Docker是容器技术的一种实现方案(一种产品、一家公司),但是因为容器技术是docker带火的,所以在早期我们谈容器都是指docker,由于当时docker如日中天有自己的标准,但是后来因为历史原因docker最终还是实现了OCI标准。
- Open Container Initiative(OCI)
- 轻量级开放式管理组织(项目)
- OCI主要定义两个规范
- Runtime Specification:运行时标准
- 文件系统包如何解压至硬盘,供运行时运行。
- Image Specification:镜像标准
- 如何通过构建系统打包,生成镜像清单(Manifest)、文件系统系列化文件、镜像配置。
- Runtime Specification:运行时标准
1.10、Docker优势
- 封装性:
- 不需要再启动内核,所以应用缩扩容时可以秒速启动。
- 资源利用率高,直接使用宿主机内核调度资源,性能损失小。
- 方便的CPU、内存资源调整。
- 能实现秒级快速回滚。
- 一键启动所有依赖服务,测试不用为搭建环境犯愁,PE也不用为建站复杂担心。
- 镜像一次编译,随处可用。
- 测试、生产环境高度一致(数据除外)。
- 镜像增量分发:
- 由于采用Union FS,简单来说就是支持将不同的目录挂载到同一个虚拟文件系统下,并实现一种layer的概念,每次发布只传输变化的部分,节约带宽。
- 隔离性:
- 应用的运行环境和宿主机环境无关,完全由镜像控制,一台物理机上部署多种环境的镜像测试。
- 多个应用版本可以并存在机器上。
- 社区活跃:
- Docker命令简单、易用,社区十分活跃,且周边组件丰富。
2、docker的安装、卸载、设置
2.1、安装docker
官方安装手册
有三种安装方式:
- 使用存储库安装
- 推荐的方法
- 下载DEB 包并手动安装
- 适合在无法访问Internet的系统上安装 Docker
- 自动化便利脚本来安装
- 适合测试和开发环境
使用存储库安装
# 更新apt包索引并安装包以允许apt通过 HTTPS 使用存储库
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
# 添加 Docker 的官方 GPG 密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
# 使用以下命令设置存储库
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 更新apt包索引,安装最新版本的 Docker Engine、containerd 和 Docker Compose
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
# 或者列出可用版本,并指定版本安装
apt-cache madison docker-ce
sudo apt-get install docker-ce=<VERSION_STRING> docker-ce-cli=<VERSION_STRING> containerd.io docker-compose-plugin
从包安装
# 转到https://download.docker.com/linux/ubuntu/dists/,选择您的 Ubuntu 版本,然后浏览到pool/stable/、选择amd64、 armhf、arm64或s390x,然后下载.deb您要安装的 Docker 引擎版本的文件。# 安装 Docker Engine,将下面的路径更改为您下载 Docker 包的路径。
sudo dpkg -i /path/to/package.deb
使用便捷脚本安装
- 使用安装脚本安装
# 从get.docker.com下载安装脚本
curl -fsSL get.docker.com -o get-docker.sh
- -o:在当前目录下生成一个get-docker.sh文件
# 执行安装脚本(脚本里面需要一些sudo的权限)
sh get-docker.sh
- 查看是否安装成功
docker version
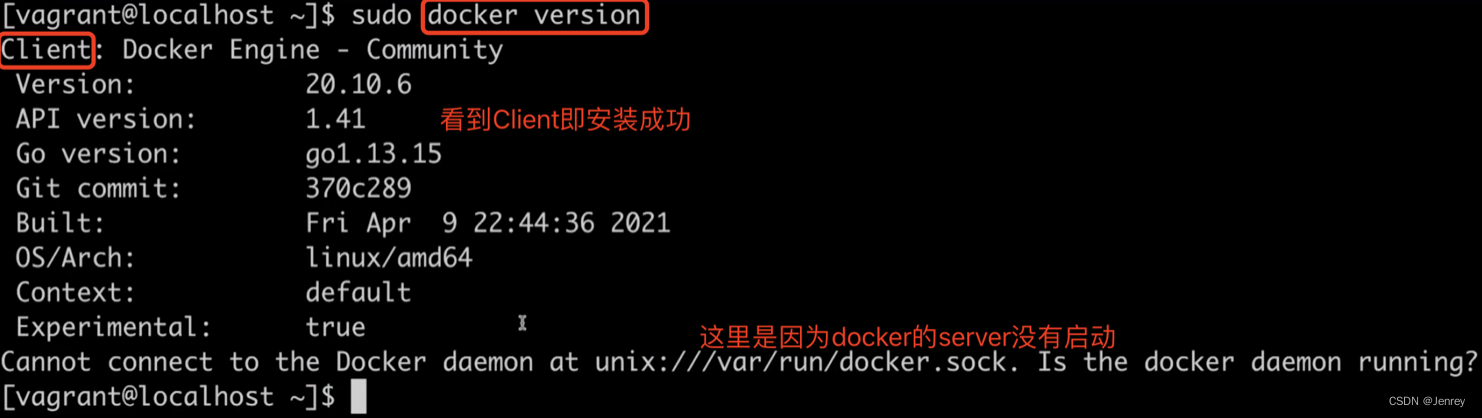
- 启动docker server
systemctl start docker
# 启动docker server后即会看到Server也出现了
docker version
使用Vagrant file方式在virtualbox安装ubuntu、docker、k8s
# -*- mode: ruby -*-
# vi: set ft=ruby :# 使用方法
# 1. 安装 virtualbox
# 2. 安装 vagrant
# 3. 添加镜像(可选,适用于网络不好的状况)
# 4. vagrant up
# 5. vagrant ssh 即可(默认用户名 vagrant,有 sudo 执行权限)Vagrant.configure("2") do |config|config.vm.box = "ubuntu/focal64"config.vm.box_check_update = falseconfig.vm.network "private_network", ip: "192.168.34.2", name: "vboxnet0"config.vm.provider "virtualbox" do |vb|# 配置虚拟机为 4 个核心,6GB 内存vb.cpus = 4vb.memory = "6144"endconfig.vm.provision "shell", inline: <<-SHELLsed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.listapt-get updateapt-get -y install \apt-transport-https \ca-certificates \curl \gnupg-agent \software-properties-commoncurl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | apt-key add -add-apt-repository \"deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu \$(lsb_release -cs) \stable"echo "deb https://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main" > /etc/apt/sources.list.d/kubernetes.listcurl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key addapt-get updateapt-get install -y docker-ce docker-ce-cli containerd.ioapt-get install -y kubelet=1.19.15-00 kubeadm=1.19.15-00 kubectl=1.19.15-00apt-mark hold kubelet kubeadm kubectladduser vagrant dockerSHELL
end
2.2、卸载docker
# 卸载 Docker Engine、CLI、Containerd 和 Docker Compose 软件包
sudo apt-get remove docker docker-engine docker.io containerd runc
# 主机上的映像、容器、卷或自定义配置文件不会自动删除。要删除所有映像、容器和卷:
sudo rm -rf /var/lib/docker
sudo rm -rf /var/lib/containerd
2.3、为K8S做准备
设置docker的cgroup driver为systemd
- docker默认用cgroupfs作为cgroup驱动。
存在问题:
- 在systemd作为init system的系统中,默认并存着两套groupdriver
- 这会使得系统中docker和kubelet管理的 进程被cgroupfs驱动管,而systemd拉起的服务由systemd驱动管,让cgroup管理混乱且容易在资源紧张时引发问题。
因此kubelet会默认--cgroup-driver=systemd,若运行时cgroup不一致时,kubelet会报错
# 默认是没有的,需要我们手动创建
vi /etc/docker/daemon.json
{"exec-opts": ["native.cgroupdriver=systemd"]
}systemctl daemon-reload
systemctl restart docker# 查看是否成功
docker info | grep Cgroup
关闭系统交换区(swap area)
K8S现在版本要求是要关闭。
swapoff -a
vi /etc/fstab
# remove the line with "swap" keyword
3、Dockerfile讲解
Dockerfile官方语法说明文档
- Dockerfile是用于构建docker镜像的文本文件
- Dockerfile里包含了构建镜像所需的“指令”
- Dockerfile有其特定的语法规则
3.1、重申12 Factor - Docker管理和构建应用的原则
- 运行环境中,应用程序通常是以一个或多个进程运行的。
- 12-Factor应用的进程必须无状态(Stateless)且无共享(Share nothing)
- 任何需要持久化的数据都要存储在后端服务内,比如数据库
- 应用构建阶段将源代码编译成待执行应用
- Session Sticky是12-Factor极力反对的
- Session中的数据应该保存在诸如Memcached或Redis这样的带有过期时间的缓存中
3.2、理解构建上下文(Build Context)
- 当运行
docker build命令时,当前工作目录被称为构建上下文。 docker build默认查找当前目录的Dockerfile作为构建输入,也可以通过-f指定Dockerfile。docker build -f ./Dockerfile
- 当
docker build运行时,首先会把构建上下文传输给docker daemon,把没用的文件包含在构建上下文时,会导致传输时间长,构建需要的资源多,构建出的镜像大等问题。- 试着到一个包含文件很多的目录运行docker build命令,会感受到差异。
- 可以通过 .dockerignore 文件从编译上下文排除某些文件。
- 因此需要确保构建上下文清晰,比如创建一个专门的目录放置Dockerfile,并在目录中运行
docker build。
举例说明:
$ cd /tmp
$ docker build .
# 可以看到执行完命令后第一句日志提示就是把build context发送给Docker daemon
Sending build context to Docker daemon 9.728kB$ cd /
$ docker build .
# 这里会卡很久,因为根目录文件太多了
所以我们要保证执行docker build命令的目录要尽可能干净,排除一些不必要的文件。
3.3、Dockerfile文件示例
Dockerfile:
# 从docker hub去拉Ubuntu镜像
From ubuntu
# 设置环境变量
ENV MY_SERVICE_PORT=80
ENV MY_SERVICE_PORT1=80
ENV MY_SERVICE_PORT2=80
ENV MY_SERVICE_PORT3=80
# 打一些LABEL,可以通过docker ps去查打某个LABEL的镜像
LABEL multi.label1="value1" multi.label2="value2" other="value3"
# 添加主机文件到镜像中
ADD bin/amd64/httpserver /httpserver
# 容器要打开的端口
EXPOSE 80
# 容器在运行的时候要跑哪条命令
ENTRYPOINT /httpserver
docker build:把Dockerfile文件build成docker镜像
# build当前目录的Dockerfile
$ docker build .# -f:指定要使用的Dockerfile路径
$ docker build -f ./Dockerfile_terraformexec .# -t:就是tag,代表镜像的名字,名字后可以使用:来打一个版本号
$ docker image build -t hello:1.0 .
3.4、镜像构建日志解析
# 这里build的就是上面3.3章节的Dockerfile文件
$ docker build .
Sending build context to Docker daemon 14.57MB
Step 1/9 : FROM ubuntu---> 27941809078c
Step 2/9 : ENV MY_SERVICE_PORT=80---> Using cache---> 054288d7d037
Step 3/9 : ENV MY_SERVICE_PORT1=80---> Using cache---> 8bce1c2fb020
Step 4/9 : ENV MY_SERVICE_PORT2=80---> Using cache---> 9e8e9021cf78
Step 5/9 : ENV MY_SERVICE_PORT3=80---> Using cache---> e8a4a34fe650
Step 6/9 : LABEL multi.label1="value1" multi.label2="value2" other="value3"---> Using cache---> fedeb7ed2081
Step 7/9 : ADD bin/amd64/httpserver /httpserver---> 31743efc0c55
Step 8/9 : EXPOSE 80---> Running in df89116684e2
Removing intermediate container df89116684e2---> 5365008d10cc
Step 9/9 : ENTRYPOINT /httpserver---> Running in 44aa0fe65377
Removing intermediate container 44aa0fe65377---> 0090532f9e62
Successfully built 0090532f9e62
- 把 构建上下文 传输给docker daemon,一共14.57MB大小。
- 每一个Step对应Dockerfile中的一条指令
- 每一条指令都是对应一个镜像层,并为每个层去计算一个checksum([后文中有详解](#4.5、文件系统 Union FS(联合文件系统)))即“校验和”,如果校验和一致的时候,就认为这个层和刚才的层是一致的,就会用原来的缓存,即“Using cache”。
3.5、Build Cache
构建容器镜像时,Docker依次读取Dockerfile中的指令,并按顺序依次执行构建指令。
Docker读取指令后,会先判断缓存中是否有可用的已知镜像,只有已存镜像不存在时才会重新构建。
- 通常Docker简单判断Dockerfile中的指令与镜像。
- 针对ADD和COPY指令,Docker判断该镜像层每一个文件的内容并生成一个checksum,与现存镜像比较时,Docker比较的是二者的checksum。
- 其他指令,比如RUN、apt-get -y update ,Docker不会去checksum,只是简单比较与现存镜像中的指令字串是否一致。
- 当某一层cache失效以后,上面所有层级的cache均一并失效,后续指令都重新构建镜像。
所以我们应该把变动不频繁的层放在下面(即在写Dockerfile时应该把那些趋于稳定的命令写在前面,变动比较多的应该放在后面),这样的话可以最大利用缓存。
3.6、多段构建(Multi-stage build)
较晚版本的Docker才支持。
什么是多段构建?有时候我们构建一个应用,这个应用需要很多的依赖包,正常情况来讲,如果我们不用多段构建方式的话,首先要先有一个Base Image,然后拉依赖包,然后去构建,构建完了可能我们只需要最后的一个文件,那么中间这些下载的依赖包、配置,我有可能就留在那了,那么最后build出来的镜像就会很大,而且会有安全隐患,要么我就得去清理,可是有些时候我都不知道这些依赖包装在哪了,可能有好几个地方。那么这样的话,就会导致中间出现了一些不必要的依赖包,我们有什么方式去解决这个问题吗?Docker提供了多段构建的概念。
多段构建的概念:在同一Dockerfile里面,指定FROM多个部分,目的就是为了达到一个干净产线的docker image,可以把一些临时过渡的文件都放在多段构建早期的镜像里面。
- 有效减少镜像层级的方式
# AS:给镜像起个别名,别名叫tmpbuild
FROM golang:1.16-alpine AS tmpbuild
# 装git插件
RUN apk add --no-cache git
# 通过go get命令把代码下载下来
RUN go get github.com/golang/dep/cmd/depCOPY Gopkg.lock Gopkg.toml /go/src/project/
WORKDIR /go/src/project/
# dep是Go语言依赖管理的软件
RUN dep ensure -vendor-only#把源代码COPY到镜像里
COPY . /go/src/project/# go build -o 把我们的源代码构建成二进制文件,我们最后就需要这个在/bin目录下的名为project的二进制文件,其他的都是waste
RUN go build -o /bin/project# ========上面这些都是为了build出我们要想的二进制文件========
# 构建新的镜像,FROM scratch不指定任何镜像为基础
FROM scratch
# 从别名为tmpbuild的镜像中COPY /bin/project二进制文件到当前新镜像中
COPY --from=tmpbuild /bin/project /bin/project
ENTRYPOINT ["/bin/project"]
CMD ["--help"]
- 所以,所谓的多段构建就是通过上面的方式先把我们想要的二进制文件给build出来,接下来我们去构建新的镜像,从新FROM,然后把之前需要的二进制文件COPY到新镜像中,这样我们新镜像是干干净净的,只有这个二进制可执行文件,所有原来的那些依赖都是不存在的。
- 多段构建的目的就是为了达到一个干净产线的docker image,把一些临时过渡的文件都放在多段构建早期的镜像里面。
3.7、Dockerfile常用指令
FROM:选择基础镜像
推荐alpine
-
FROM [--platform=<platform>] <image>[@<digest>][AS <name>] FROM golang:1.16.5-alpine3.13 AS tmpbuild
- FROM scratch:不指定任何镜像为基础,是一个空的Docker镜像
- 官方镜像优于非官方的镜像,如果没有官方镜像,则尽量选择Dockerfile开源的
- 固定版本tag而不是每次都使用latest
- 尽量选择体积小的镜像
LABELS:按标签组织项目
- 方便管理
LABEL multi.label1="value1" multi.label2="value2" other="value3"
- 配合label filter可过滤镜像查询结果
docker images -f label=multi.label1="value1"
RUN:运行命令
最常用的,比如使用命令安装软件,下载文件等。
RUN apt-get install -y wgetRUN wget https://github.com/ipinfo/cli/releases/download/ipinfo-2.0.1/ipinfo_2.0.1_linux_amd64.tar.gzRUN tar zxf ipinfo_2.0.1_linux_amd64.tar.gz && \mv ipinfo_2.0.1_linux_amd64 /usr/bin/ipinfo && \rm -rf ipinfo_2.0.1_linux_amd64.tar.gz
- 最常见的用法是
RUN apt-get update && apt-get install,这两条命令应该永远用&&连接,如果分开执行,RUN apt-get update构建层被缓存,可能会导致新package无法安装。 - 每一行的RUN命令都会产生一层image layer,会导致镜像的臃肿。
- 建议用&&连接多个命令,这样docker就会把多条命令变成一条命令来执行,有效减少了镜像的层级,镜像层级越少,OverlayFS里面的层数越少([后文中有详解](#4.5、文件系统 Union FS(联合文件系统))),效率上会越高的。
CMD、ENTRYPOINT:容器启动时默认执行的命令
CMD和ENTRYPOINT同时支持shell格式和Exec格式。更多的是使用Exec格式。
Shell格式:
ENTRYPOINT echo "hello docker" CMD echo "hello docker"Exec格式:
ENTRYPOINT ["echo", "hello docker"] CMD ["echo", "hello docker"]
-
CMD:容器启动时默认执行的命令。 -
容器镜像中应用的运行命令,需要带参数。
-
如果docker run启动容器时指定了其它命令,则CMD命令会被忽略。
FROM ubuntu CMD ["echo", "hello docker"]$ docker run -it --rm 9ea0677b6d32 hello docker $ docker run -it --rm 9ea0677b6d32 echo "hello world" hello world
- 如果定义了多个CMD,只有最后一个会被执行。
- 需要注意的是CMD不是必写的,因为有些基础镜像自己有CMD,例如在ubuntu:21.04就会有CMD [“/bin/bash”],但是如果我们自己写了CMD就会覆盖基础镜像自带的,因为我们定义的会比基础镜像定义的CMD靠后。即使我们写CMD []也会把ubuntu基础镜像里面的CMD给覆盖掉。
-
ENTRYPOINT:容器启动时默认执行的命令。- ENTRYPOINT的最佳实践是用ENTRYPOINT定义镜像主命令,并通过CMD定义主要参数
FROM ubuntu ENTRYPOINT ["echo"] CMD ["hello", "docker","jenrey"]$ docker run -it --rm 2e6 hello docker jenrey
- ENTRYPOINT是使得容器镜像和虚拟机镜像有一个本质区别的点,容器镜像是面向容器内应用的,容器镜像在启动的时候不仅仅起了一个虚的OS运行环境壳子,最重要的是用ENTRYPOINT指定要起哪个应用的,所有的docker image其实都是为了某一个固定应用而构建的,容器的运维是面向应用的运维而不是面向操作系统的运维,ENTRYPOINT就使得这一切有了意义。
- 与CMD略有不同,ENTRYPOINT所设置的命令是 一定会被执行的。
-
FROM ubuntu:21.04ENTRYPOINT ["echo", "hello docker"]$ docker run -it --rm demo-entrypoint hello docker $ docker run -it --rm demo-entrypoint echo "hello world" # 这里注意echo也打印出来了。这是因为我们把创建容器时指定命令的echo "hello world"作为参数传给了dockerfile的ENTRYPOINT的echo。这是因为ENTRYPOINT所定义的echo一定会被执行的。 hello docker echo hello world $ -
FROM ubuntu:21.04ENTRYPOINT ["echo"]CMD []# 我们什么都不加直接创建容器,不会打印出任何内容,这是因为ENTRYPOINT的echo参数为空。 $ docker container run --rm -it demo-both# 如果我们加一些内容,就会把test通过CMD作为参数传给了ENTRYPOINT的echo $ docker container run --rm -it demo-both test test $
EXPOSE:发布端口
EXPOSE <prot> [<port>/<protocol>...]EXPOSE 8080
- 是镜像创建者和使用者的 约定,所以不定义也没事,EXPOSE其实只是一个声明,因为从容器提供的应用服务本身是看不到开了哪个端口的,声明一下别人就知道你的镜像是开了哪个端口。
- 并不会直接将端口自动和宿主机某个端口建立映射关系
- 容器的端口映射,还是要使用docker run -p去指定容器端口映射到主机哪个端口上的,一般来说我们不会直接用docker,都使用K8S,所以也不是很常用
- 在docker run -P时,docker会自动映射所有EXPOSE定义的端口到主机随机大端口(比较大的端口号),如0.0.0.0:32768->80/tcp
- 通过docker inspect 命令,查看“Ports”字段可以看到容器端口的信息
ENV、ARG:设置变量构建参数和设置环境变量
- 区别:

ENV
ENV <key>=<value>...ENV MY_SERVICE_PORT=80
- ENV设置的变量可以Dockerfile中保持,也在Image中保持,也会永久的保存到容器的系统环境变量里面。
ARG
-
ARG设置的变量只在Dockerfile中保持。
-
ARG 可以在镜像build的时候动态修改value, 通过
--build-arg$ docker build -f .\Dockerfile-arg -t ipinfo-arg-2.0.0 --build-arg VERSION=2.0.0 .
ADD、COPY:文件复制
-
ADD:从源地址(文件、目录或者URL)复制文件到目标路径
ADD [--chown=<user>:<group>]<src>...<dest>ADD [--chown=<user>:<group>]"<src>",..."<dest>"路径中有空格时使用- ADD支持Go语言风格的通配符,如ADD check* /testdir/
- src如果是文件,则必须包含在编译上下文中(Build context),ADD指令无法添加编译上下文之外的文件
- src如果是URL,如果dest结尾没有/,那么dest是目标文件名;如果dest结尾有/,那么dest是目标目录名
- 如果src是一个目录,则所有文件都会被复制至dest
- 如果src是一个本地压缩文件,则在ADD的同时完成解压操作
- 如果dest不存在,则ADD指令会创建目标目录
- 尽量减少通过ADD URL添加remote文件,建议使用curl或wget && untar
-
COPY:从源地址(文件、目录)复制文件到目标路径
-
COPY [--chown=<user>:<group>]<src>...<dest> -
COPY [--chown=<user>:<group>]"<src>",..."<dest>"路径中有空格时使用 -
COPY requirements.txt . COPY Gopkg.lock Gopkg.toml /go/src/project/ -
只支持本地文件的复制,不支持URL
-
如果目标目录不存在,则和ADD一样,会自动创建。
-
COPY只会单纯的去复制,不会自动解压。
-
建议所有的本地文件复制均使用 COPY 指令,仅在需要自动解压缩的场合使用 ADD。
-
COPY可以用于多阶段编译场景,可以从前一个临时镜像中拷贝文件
COPY --from=tmpbuild /bin/project /bin/project
-
WORKDIR:切换工作目录
- 等价于cd命令,切换工作目录
VOLUME:将指定目录定义为外挂存储卷
-
Dockerfile中在该指令之后所有对同一目录的修改都无效
-
FROM ubuntu # 将容器内的/test目录(不存在会自动创建)定义为外挂存储卷 VOLUME ["/test"]使用
docker inspect 容器id查看“Mounts”-“Source”和“Destination”即可以看到- Source:为该容器的外挂存储卷在宿主机上的存储地址
- Linux为:
/var/lib/docker/<卷名>/_data
- Linux为:
- Destination:为容器内的映射到外部存储卷的目录,即Dockerfile的VOLUME指令所指定的目录
- Source:为该容器的外挂存储卷在宿主机上的存储地址
-
等价于使用
docker run -it -d -v="/test" -
不管是用Dockerfile VOLUME指令还是docker run -v,均不会覆盖,即同时使用会挂载两个外部存储卷。
USER:切换运行镜像的用户和用户组
-
因安全性要求,越来越多的场景要求容器应用要以non-root身份运行
-
USER <user>[:<group>] -
一般如果不指定USER的话,在容器里面就是root用户
-
# 用户和用户组必须提前已经存在 USER user1
不常用指令
- ONBUILD指令可以为镜像添加触发器。其参数是任意一个Dockerfile 指令。
当我们在一个Dockerfile文件中加上ONBUILD指令,该指令对利用该Dockerfile构建镜像(比如为A镜像)不会产生实质性影响。
但是当我们编写一个新的Dockerfile文件来基于A镜像构建一个镜像(比如为B镜像)时,这时构造A镜像的Dockerfile文件中的ONBUILD指令就生效了,在构建B镜像的过程中,首先会执行ONBUILD指令指定的指令,然后才会执行其它指令。
需要注意的是,如果是再利用B镜像构造新的镜像时,那个ONBUILD指令就无效了,也就是说只能再构建子镜像中执行,对孙子镜像构建无效。其实想想是合理的,因为在构建子镜像中已经执行了,如果孙子镜像构建还要执行,相当于重复执行,这就有问题了。
利用ONBUILD指令,实际上就是相当于创建一个模板镜像,后续可以根据该模板镜像创建特定的子镜像,需要在子镜像构建过程中执行的一些通用操作就可以在模板镜像对应的dockerfile文件中用ONBUILD指令指定。 从而减少dockerfile文件的重复内容编写。
- STOPSIGNAL
- HEALTHCHECK
- SHELL
3.8、Dockerfile最佳实践
目标:易管理、少漏洞、镜像小、层级少、利用缓存
- 不要安装无效软件包。
- 应简化镜像中同时运行的进程数,理想状况下,每个镜像应该只有一个进程。
- 当无法避免同一镜像运行多进程时,应选择合理的初始化进程(init process)。
- 最小化层级数:
- 最新的docker只有RUN、COPY、ADD创建新层,其他指令创建临时层,不会增加镜像大小,比如EXPOSE指令就不会生成新层。
- 多条RUN命令可通过&&连接符连接成一条指令集以减少层数。
- 通过多段构建减少镜像层数。
- 把多行参数按字母排序,可以减少可能出现的重复参数,并且提高可读性。
- 编写Dockerfile的时候,应该把变更频率低的编译指令优先构建以便放在镜像底层以有效利用build cache。
- 复制文件时,每个文件应独立复制,这确保某个文件变更时,只影响改文件对应的缓存。
3.9、多进程的容器镜像
对于任何的容器,它的PID=1的进程就是它的entrypoint进程,这个容器里的所有其他进程都是entrypoint进程fork出来的,如果entrypoint进程没有去管理子进程的能力,那么很可能就出现各种的问题。
- 选择适当的init进程
- 需要捕获SIGTERM 信号并完成子进程的优雅终止
- 负责清理退出的子进程以避免僵尸进程
tini
开源项目:https://github.com/krallin/tini
如果我们一个容器里面需要多个进程并行的时候,可以用tini作为初始化进程。
4、docker的原理及技术实现
4.1、容器主要特性
- 安全性
- 隔离性
- Namespace
- 便携性
- Union FS
- 可配额
- Cgroup
4.2、Linux-Namespace技术
这里讲的Namespace是Linux里面的进程隔离技术,主要目的是两个进程互相不干扰,不要和K8S里面的Namespace混淆。
K8S里面的Namespace是一个对象,可以理解为一个个的文件目录,然后把k8s内嵌对象组织起来,然后可以通过权限控制说你可以访问这个目录,他不可以访问这个目录。
并不是新的方案,在docker出现之前就有Namespace方案。
- Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案;
- 系统可以为进程分配不同的Namespace;
- 并保证不同的Namespace资源独立分配、进程彼此隔离,即不同的Namespace下的进程互不干扰;
Linux内核代码中Namespace的实现
Namespace名空间一般就是用来做隔离的,在Linux里面,任何一个进程在运行的时候都是需要放在Namespace下的。Namespace是进程的一个属性。
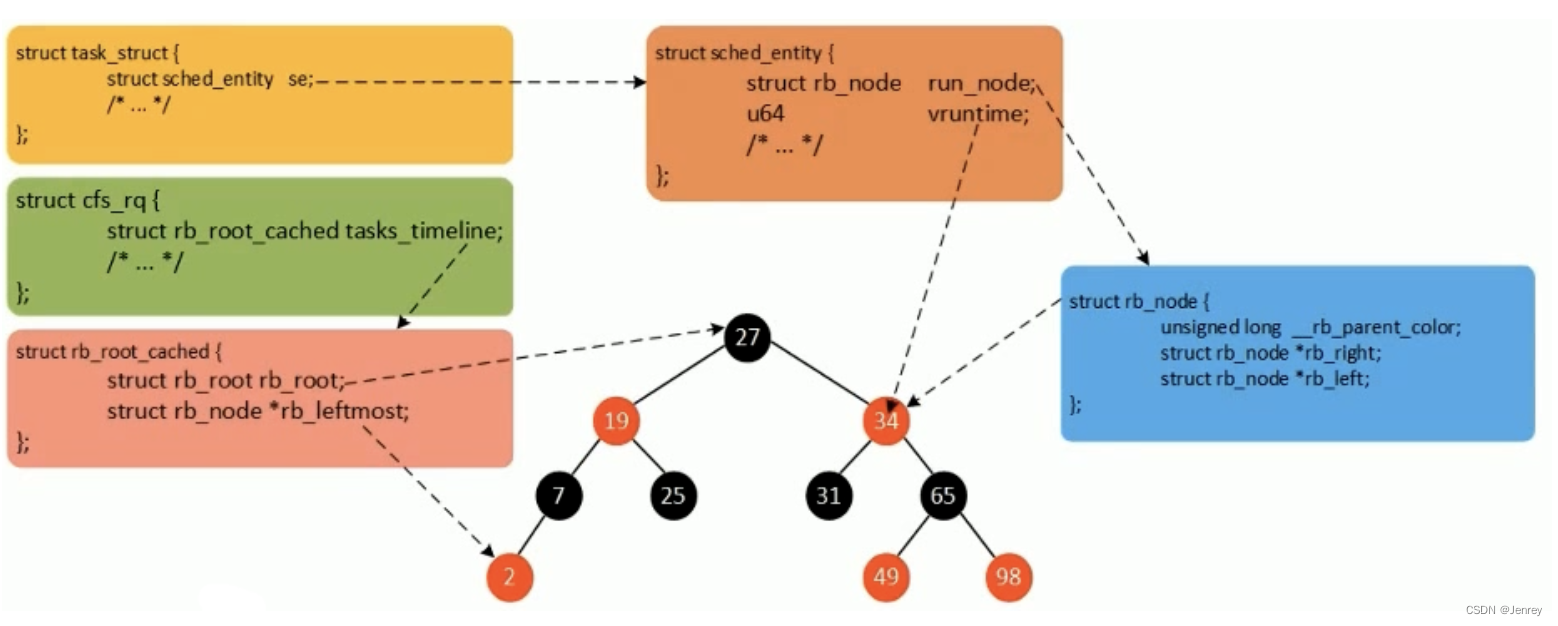
在Linux Kernel里面无论是线程还是进程,从Linux Kernel来看都是task,在Kernel里面用来描述task的数据结构就叫task_struct,里面有一个属性叫nsproxy,即任何的task都有自己的属性nsproxy。
nsproxy里面有uts_namespace、ipc_namespace、mnt_namespace、pid_namespace、net。
-
进程数据结构
struct task_struct{.../* Namespace */struct nsproxy *nsproxy;... } -
Namespace数据结构
struct nsproxy{atomic_t count;struct uts_namespace *uts_ns;struct ipc_namespace *ipc_ns;struct mnt_namespace *mnt_ns;struct pid_namespace *pid_ns_for_children;struct net *net_ns; }
Linux对Namespace操作方法
一个进程是如何分namespace的?
系统的第一个进程是init PID=1(较新的Linux系统上都使用了systemd取代了init成功系统的第一个进程即PID=1,字母d是守护进程daemon的缩写;systemctl是 systemd 的主命令,用于管理系统),其本身会分一个默认的namespace,当要起其它进程的时候,比如clone()的时候是可以指定新的namespace、通过setns()可以把进程加到某个已经存在namespace中、通过unshare()把一个进程移动到新的namespace里。
-
clone():在创建新进程的系统调用时,可以通过flags参数指定需要新建的Namespace类型。/*CLONE_NEWCGROUP / CLONE_NEWIPC / CLONE_NEWNET / CLONE_NEWNS / CLONE_NEWPID / CLONE_NEWUSER / CLONE_NEWUTS */ int clone(int (*fn)(void *), void *child_stack, int flags, void *arg) -
setns():该系统调用 可以让调用进程加入某个已经存在的Namespace中int setns(int fd, int nstype) -
unshare():该系统调用 可以将调用进程移动到新的Namespace下int unshare(int flags)
Linux Namespace种类
Namespace有多种。

理解多个Namespace的关系和区别
主机即系统本身有一个namespace,一般来讲用户的进程都是run在主机namespace上的,当主机fork一个新的进程,可以让新进程去新的namespace。
我们可以创建很多namespace,把不同进程塞到不同的namespace里。
多个Namespace彼此之间是隔离的,所以不同的Namespace里看到的pid是不一样的。
net namespace:在不同的namespace里,网络的配置是不一样的,是完全独立的,可以有自己独立的网卡,独立的ip。
但是pid namespace:相当于是继承的,Namespace A的pid在主机上是能看得到的,但是是有一个映射关系,但是里面的pid号不一样。
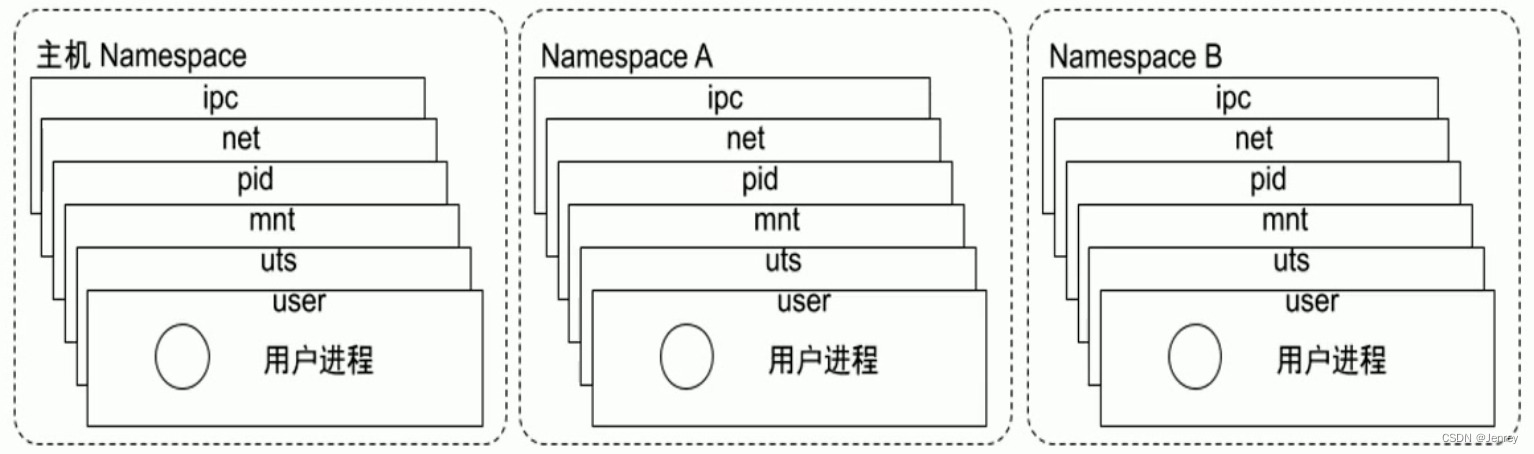
Namespace详解
- Pid namespace
- 不同用户的进程就是通过 Pid namespace 隔离开的,且不同 namespace中可以有相同Pid。
- 有了Pid namespcae,每个 namespace 中的Pid能够互相隔离。
- 应用场景:容器技术是没有虚拟化层的,即没有从操作系统做隔离,任何的进程其实都是主机上开辟的进程,如果不做隔离,可能一个机器上开几百几千个进程,ps命令一执行就弹出几千个进程,不方便管理。有了Pid namespace,这一组进程放在A namespace,这一组进程放在B namespace,我们只需要进到namespace里,就很容易管理当前这一组进程了。而且不同的namespace彼此看不到,当我们在另外一个namespace中想杀其他namespace的进程是杀不到的,因为看不到pid。
- net namespcae
- 网络隔离是通过 net namespace 实现的,每个net namespace 有独立的 network device、IP address、IP routing tables、/proc/net 目录。
- Docker默认采用veth的方式将container中的虚拟网卡同host上的一个docker bridge:docker0连接在一起;这里后面有详细讲解。
- 应用场景:每个net namespace里面可以有独立的网络设备、独立的ip路由表等,回到微服务架构,服务A去调服务B时,B是要有一个独立的IP网络地址、独立的端口,那就意味着我这一个tomact进程放到一个独立的net namespace下,就可以分配一个独立的IP、端口,那么只需要我这个IP能和外面世界连通,相当于就是虚拟了一台主机出来,微服务架构就实现了,实现微服务架构就是为了让服务跑在某一个IP加端口上。
- ipc namespace
- Container中进程交互还是采用Linux常见的进程间交互方法(interprocess communication - IPC),包括常见的信号量、消息队列和共享内存。
- container的进程间交互实际上还是host上具有相同Pid namespace中的进程间交互,因此需要在IPC资源申请时加入namespace信息 - 每个IPC资源有一个唯一的32位ID。
- 应用场景:当我们要进程间通信的时候,它们要放在同一个ipc namespace里。
- mnt namespace
- mnt namespace允许不同 namespace的进程看到的文件结构不同,这样每个namespcae中的进程所看到的文件目录就被隔离开了。
- UST namespace(“UNIX Time-sharing System”)
- 允许每个container拥有独立的hostname和domain name,使其在网络上可以被视作一个独立的节点而非host上的一个进程。
- user namespace
- 每个container可以有不同的user和group id,也就是说可以在container内部用container内部的用户执行程序而非Host上的用户。
/proc/[pid]/ns/cgroup 进程cgroup命名空间句柄
/proc/[pid]/ns/ipc 进程IPC命名空间句柄
/proc/[pid]/ns/mnt 进程mount命名空间句柄
/proc/[pid]/ns/net 进程网络命名空间句柄
/proc/[pid]/ns/pid 进程PID命名空间句柄
/proc/[pid]/ns/pid_for_children 该进程的子进程的PID命名空间句柄
/proc/[pid]/ns/time 进程time命名空间句柄
/proc/[pid]/ns/user 进程user命名空间句柄
/proc/[pid]/ns/uts 进程UTS命名空间句柄
关于namespace的常用操作
- 查看当前系统的所有namespace的list
lsns
- 查看当前系统的所有<tpye> namespace,例如net
lsns -t <tpye>
- 查看当前系统指定pid的namespace,例如642
lsns -p <pid>
- 查看某进程的namespace,例如ls -la /proc/642/ns
ls -la /proc/<pid>/ns//proc:是用来描述进程状态的文件系统
- 进入某namespace运行命令,例如nsenter -t 642 -n ip addr
nsenter -t <pid> -n ip addr- -n:表示net,上面的命令代表 查看某进程的网络配置,常用语 查看docker容器进程的网络配置
查看docker容器的网络配置信息
# 查看当前系统的所有net namespace
lsns -t net# 进入pid为4118(docker容器的pid)的进程的net namespace查看此容器的网络配置
nsenter -t 4118 -n ip addr
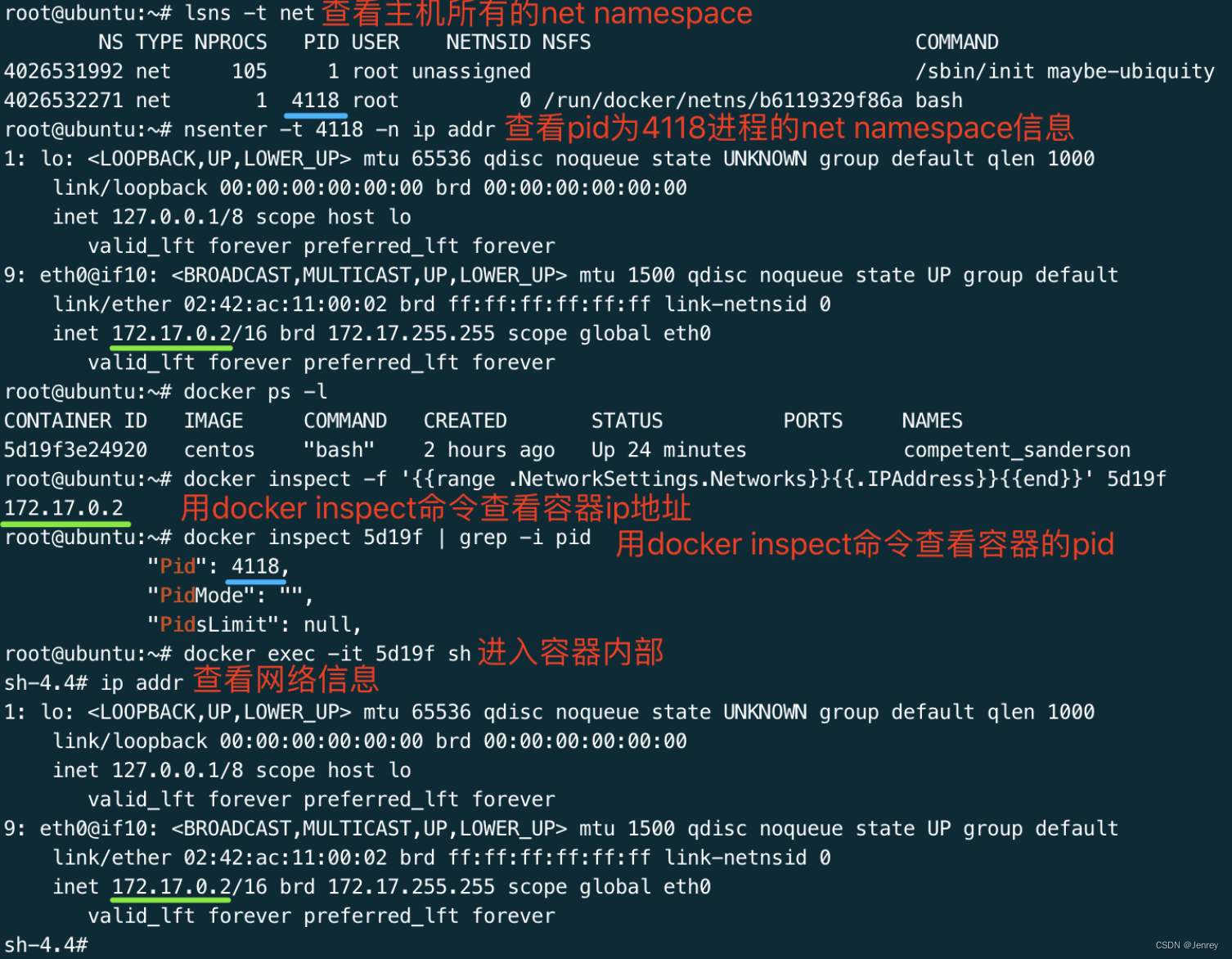
这里引深一下,在linux中namespace不可以嵌套,在k8s里可以嵌套。
4.3、Linux-Cgroups
是Google内部一个系统去做资源管控的,后来被应用到Linux系统中,可以理解为一种机制或者Linux系统内的子系统。
光有namespace是不行的,namespace是把一个进程塞到一个隔离环境去运行,我们要完全模拟一个操作系统,还有一个东西没有实现,这个东西就是资源管控,当我们要搭建虚拟机的时候我们要指定多少CPU、内存、disk等等,然后要启动虚机才能帮我们分配ip才有了这些隔离环境,对于进程也是一样的,一个进程启动后也是需要指定多少CPU、内存等等,这个技术就是Control Group即Cgroup。
简介
- Cgroups(Control Groups)是Linux下用于对一个或一组进程进行资源控制和监控的机制;
- 可以对诸如CPU使用时间、内存、磁盘I/O等进程所需的资源进行限制;
- 不同资源的具体管理工作由相应的Cgroup子系统(Subsystem)来实现;
- 针对不同类型的资源限制,只要将限制策略在不同的的子系统上进行关联即可;
- Cgroups在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理:每个Cgroup都可以包含其它的子Cgroup,因此子Cgroup能使用的资源除了受本Cgroup配置的资源参数限制,还受到父Cgroup设置的资源限制。
- 和namespace一样,在task_struct里有css_set属性,css_set本身就是Cgroup。
Linux内核代码中Cgroups的实现
任何Linux启动的进程都是可以通过Cgroup去控制的,比如systemd在启动的时候,Cgroup本身是要有一个driver去实现的,什么是driver呢?Cgroup子系统是通过一个个控制文件去控制的,也就是说在操作系统上可以看到Cgroup的配置目录/sys/fs/cgroup,这个配置目录和我们日常看到的文件结构是一样的,Cgroup本身又有各种各样的子系统,有控制CPU的、有控制内存的、有控制disk IO的,在不同的子系统里面,在Cgroup下面就形成了不同的文件目录,我们叫hierarchy(等级制度),不同的文件目录里可以控制CPU的绝对值是什么、相对值是什么、控制哪些进程,都是通过一个个这样的配置文件去控制的,systemd在启动的时候就加载了这样的文件系统,这个driver就叫做systemd的driver;当systemd去启动任何其他进程的时候或者启动其他服务的时候,一样的会为这些子进程、子服务也去配置Cgroup。docker本身也用了Cgroup,docker有自己的driver,后面再介绍。
- 进程数据结构
struct task_struct{#idef CONFIG_CGROUPSstruct css_set__rcu *cgroups;struct list_head cg_list;#endif
}
- css_set是cgroup_subsys_state对象的集合数据结构
struct css_set{/*Set of subsystem states, one for each subsystem. This array is immutable after creation apart from the init_css_set during subsystem registration(at boot time). */struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
}
可配额/可度量 - Control Groups (cgroups)
我们先思考一下,对于一个进程,想实现资源的可配额,最重要的就是CPU、memory、disk IO等等这些,一般来说应用关注的就是这些,所以对Cgroup来讲,它就有了不同的子系统,不同的子系统会配置不同的资源。有些子系统实现的非常完善,有些子系统还是有些欠缺。
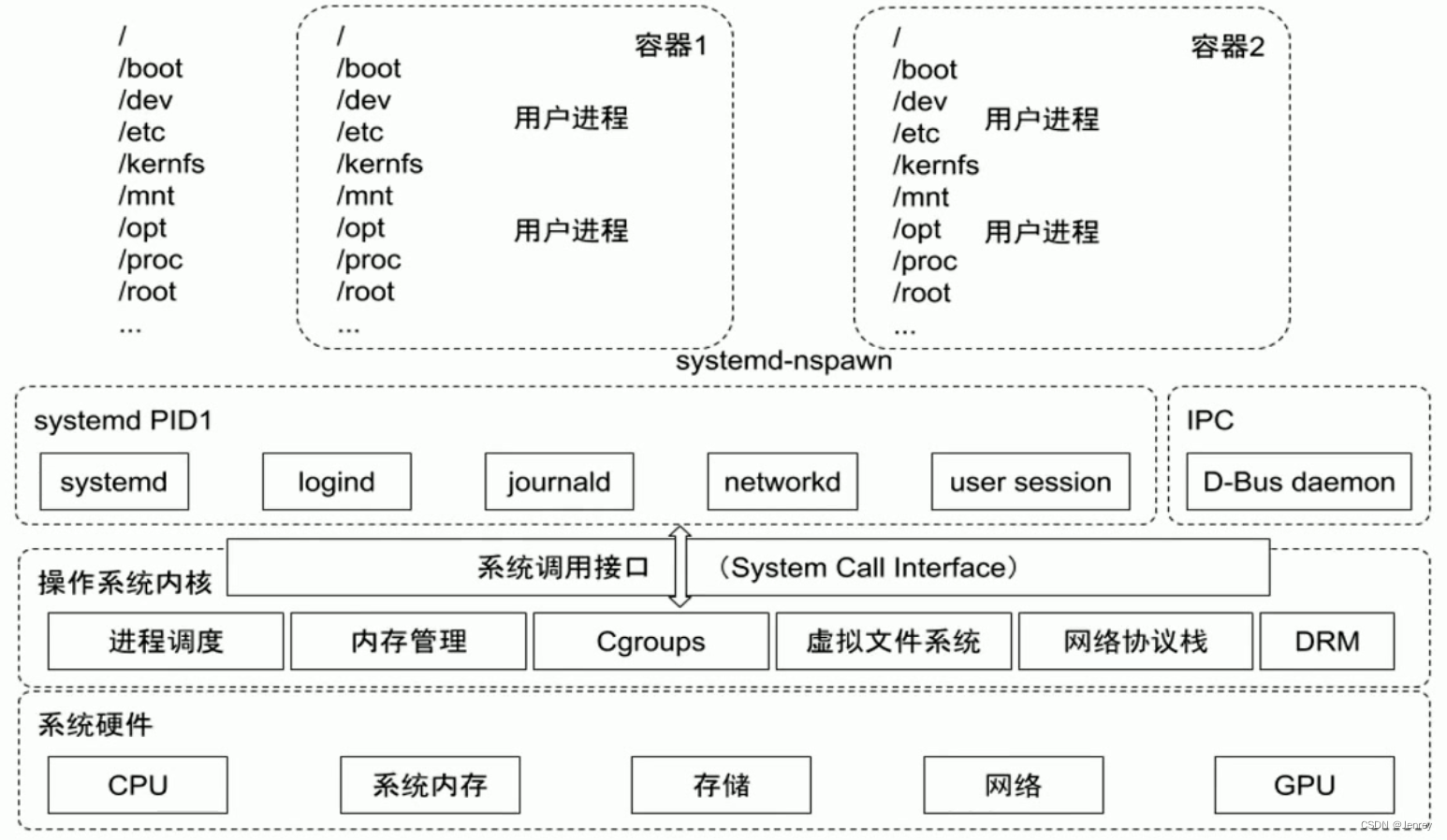
cgroups实现了对资源的配额和度量
- blkio:这个子系统设置限制每个块设备的输入输出控制。例如:磁盘、光盘以及USB等等
- cpu:这个子系统使用调度程序为cgroup任务提供CPU的访问
- cpuacct:产生cgroup任务的CPU资源报告
- cpuset:如果是多核心的CPU,这个子系统会为cgroup任务分配单独的CPU和内存
- devices:允许或拒绝cgroup任务对设备的访问
- freezer:暂停和恢复cgroup任务
- memory:设置每个cgroup的内存限制以及产生内存资源报告
- net_cls:标记每个网络包以供cgroup方便使用
- ns:名称空间子系统
- pid:进程标识子系统
CPU子系统
是用来配置一个进程可以获得多少CPU这样的一个子系统。
CPU的执行原理其实是通过时间片的方式来控制的,从人的直观感受上是并行来执行的,但其实不是这样的,实际上是把CPU的时间片分给不同的进程来实现的,即CPU时间片轮转。即CPU同时刻只能执行一个进程,因为CPU执行很快,所以我们感觉不到。单CPU中进程只能是并发,多CPU计算机中进程可以并行。
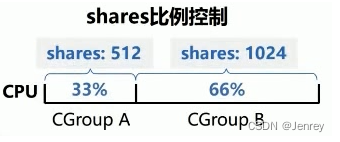
任何进程被Cgroup控制的时候,CPU子系统下面有一个控制文件叫CPU share,CPU share代表着你给这个Cgroup分配的CPU时间片权重。假如一个主机有3个CPU,建了两个Cgroup,第一个Cgroup1里面的CPU share写了512,第二个Cgroup2里面写1024,意味着这两个group可以按512:1024的比例去分摊CPU的时间,也就是按1:2的比例,这是一个相对值去分CPU的时间,也就是Agroup进程总共会拿到1个CPU,Bgroup进程总共会拿到2个CPU。如果把Cgroup1调成1024的话,就变成了1:1了。如果一个group里面没有进程,另外一个group里面可以用尽资源,即通过CPU share的这种情况只要一边没用,另外一边是可以挤压它的。
控制一个进程到底能拿多少CPU有两种方式,第一种share相对值方式,第二种period和quota绝对值方式。
-
cpu.shares:可出让的能获得CPU使用时间的相对值。
-
- cpu.cfs_period_us:用来配置时间周期长度,单位为us(微秒)。一般来说默认时间是10万。通过调节quota来定义我这个进程或者说Cgroup里面的进程能拿到多少个CPU,如果quota也配了10万,那就意味着能拿1个CPU;如果quota配置100万,那就能拿10个CPU;如果quota配置成1万,那就能拿0.1个CPU;这个是个绝对值,进程是超不过去的,如果quota配置成-1代表不控制绝对时间片,进程能吃多少CPU就吃多少。
-
- cpu.cfs_quota_us:用来配置当前Cgroup在cfs_period_us时间内最多能使用的CPU时间数,单位为us(微秒)。如果是-1代表不控制绝对时间片。

-
- cpu.stat:Cgroup内的进程使用的CPU时间统计。
- nr_periods:经过cpu.cfs_period_us的时间周期数量。
- nr_throttled:在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制。
- throttled_time:Cgroup中的进程被限制使用CPU的总用时,单位是ns(纳秒)
cpuacct子系统
用于统计Cgroup及其子Cgroup下进程的CPU的使用情况。
-
cpuacct.usage
包含该Cgroup及其子Cgroup下进程使用CPU的时间,单位是ns(纳秒)
-
cpuacct.stat
包含该Cgroup及其子Cgroup下进程使用的CPU时间,以及用户态和内核态的时间
memory子系统
-
memory.usage_in_bytes
Cgroup下进程使用的内存,包含Cgroup及其子Cgroup下的进程使用的内存
-
memory.max_usage_in_bytes
Cgroup下进程使用内存的最大值,包含子Cgroup的内存使用量。
-
memory.limit_in_bytes
设置Cgroup下进程最多能使用的内存。如果设置为-1,表示对该Cgroup的内存使用不做限制。如果进程超过了本设置,就会被OOM杀死。
-
memory.sort_limit_in_bytes
这个限制并不会阻止进程使用超过限额的内存,只是在系统内存足够时,会优先回收超过限额的内存,使之向限定值靠拢。
-
memory.oom_control
设置是否在Cgroup中使用OOM(Out of Memory)Killer,默认为使用。当属于该Cgroup的进程使用的内存超过最大的限定值时,会立刻被OOM Killer处理。
CPU子系统练习
因为我们练习的要点是cgroup对单一进程的控制,所以不能在/sys/fs/cgroup/cpu根目录去操作,根目录是控制当前系统所有进程的,如果在此改配置设置了一个0.1cpu的限制,会影响全局的,所以我们要在/sys/fs/cgroup/cpu/cpudemo下做操作。
首先准备一个名为busyloop的二进制文件:
/*使用Go语言编写如下代码,执行“GOOS=linux go build -o busyloop main.go”编译成名为busyloop的二进制文件
*/
package mainimport "fmt"func main() {go func() {fmt.Println("abc")}()for {fmt.Println("abc")}
}
命令行窗口1:
# 进入到cgroup目录
cd /sys/fs/cgroup/cpu
# 创建一个cpudemo目录,因为目录的特殊性,会自动在里面创建很多文件
mkdir cpudemo
cd cpudemo
cat cpu.shares # 1024
cat cpu.cfs_period_us # 100000
cat cpu.cfs_quota_us # -1
cat cgroup.procs # 文件为空
# 用top命令观察cpu使用情况
top
命令行窗口2:
chmod 777 busyloop
./busyloop
# 通过top命令,发现CPU占用200%
命令行窗口3:
cd /sys/fs/cgroup/cpu/cpudemo
# 把busyloop进程添加到cgroup进程配置组,-v过滤掉grep本身
echo `ps -ef | grep busyloop | grep -v grep |awk '{print $2}'` > cgroup.procs
# 设置cpu.cfs_quota_us,因为cpu.cfs_period_us=100000
echo 10000 > cpu.cfs_quota_us
# 最终通过命令行窗口1的top命令看到CPU占用变为10%
最后,如果想删除自己创建的cpudemo文件目录,有两种方式
- 执行
rmdir cpudemo/命令进行删除(可以删除,暂不知道有何影响) - 安装cgroup-tools,使用
cgdelete cpu:cpudemo命令进行删除
Memory子系统练习
Go语言是支持cgo的,可以通过一个c文件定义一个function
malloc.c文件:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>#define BLOCK_SIZE (100*1024*1024)
char* allocMemory() {char* out = (char*)malloc(BLOCK_SIZE);memset(out, 'A', BLOCK_SIZE);return out;
}
main.go文件:
package main//#cgo LDFLAGS:
//char* allocMemory();
import "C"
import ("fmt""time"
)func main() {// only loop 10 times to avoid exhausting the host memoryholder := []*C.char{}for i := 1; i <= 10; i++ {fmt.Printf("Allocating %dMb memory, raw memory is %d\n", i*100, i*100*1024*1025)// hold the memory, otherwise it will be freed by GCholder = append(holder, (*C.char)(C.allocMemory()))time.Sleep(time.Minute)}
}
makefile文件:
build:CGO_ENABLED=1 GOOS=linux CGO_LDFLAGS="-static" go build -o malloc
上面三个文件都准备完毕后,在 linux机器 执行make build命令
# 如果没有make命令,执行下面进行安装
apt install make
apt install gcc
到此为止,我们就拿到了可执行二进制文件malloc,下面实验正式开始:
命令行窗口1:
# 进入到cgroup目录
cd /sys/fs/cgroup/memory
# 在cgroup memory子系统目录中创建目录结构
mkdir memorydemo
cd memorydemo
cat memory.limit_in_bytes # 9223372036854771712
cat cgroup.procs # 文件为空
# 查看内存使用情况
watch 'ps -aux|grep malloc|grep -v grep'
命令行窗口2:
./malloc
命令行窗口3:
cd /sys/fs/cgroup/memory/memorydemo
# 把malloc进程添加到 cgroup 进程配置组
echo `ps -ef|grep malloc |grep -v grep|awk '{print $2}'` > cgroup.procs
# 设置 memory.limit_in_bytes
echo 104960000 > memory.limit_in_bytes
# 等待进程被 oom kill
最后,如果想删除自己创建的cpudemo文件目录,有两种方式
- 执行
rmdir memorydemo/命令进行删除(可以删除,暂不知道有何影响) - 安装cgroup-tools,使用
cgdelete memory:memorydemo命令进行删除
Cgroup driver
systemd:
- 当操作系统使用systemd作为init system时,初始化进程生成一个根Cgroup目录结构并作为Cgroup管理器。
- systemd与Cgroup紧密结合,并且为每个systemd unit分配Cgroup。
cgroupfs:
- docker默认用cgroupfs作为cgroup驱动。
存在问题:
-
因此,在systemd作为init system的系统中,默认并存着两套groupdriver
-
这会使得系统中docker和kubelet管理的 进程被cgroupfs驱动管,而systemd拉起的服务由systemd驱动管,让cgroup管理混乱且容易在资源紧张时引发问题。
因此kubelet会默认
--cgroup-driver=systemd,若运行时cgroup不一致时,kubelet会报错
4.4、Linux进程调度策略
4.4章节是对4.3章节原理的一个引申讲解,因为我们之前在做CPU子系统练习的时候配置了一些文件,本节主要讲讲其背后的调度策略。
内核默认提供了5个调度器,Linux内核使用struct sched_class来对调度器进行抽象:
- Stop调度器,stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占;
- Deadline调度器,dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行;
- RT调度器,rt_sched_class:实时调度器,为每个优先级维护一个队列;
- CFS调度器,cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念,kernel 2.6 以后使用这种;
- IDLE-Task调度器,idle_sched_class:空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程;
CFS调度器
CFS调度器里面维护了一个红黑树即二叉排序树,本身是平衡的,在系统运行的时候,会把所有的进程初始化,初始化的时候会为每个进程初始化vruntime,最小值的放在左边,最大值的放在右边,所以当调度的时候总是从最左边来拿进程,然后让这个进程去执行,每一次时钟周期会重新算一遍。
- CFS是Completely Fair Scheduler简称,即完全公平调度器。
- CFS实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应给进程分配相当数量的处理器。
- 分给某个任务的时间失去平衡时,应给失去平衡的任务分配时间,让其执行。
- CFS通过虚拟运行时间(vruntime)来实现平衡,维护提供给某个任务的时间量。
- vruntime = 实际运行时间*1024 / 进程权重
- 进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑的慢,但获得比较多的运行时间。
vruntime红黑树
CFS调度器没有将进程维护在运行队列中,而是维护了一个以虚拟运行时间为顺序的红黑树。红黑树的主要特点有:
- 自平衡,树上没有一条路径会比其他路径长出两倍。
- O(log n)时间复杂度,能够在树上进行快速高效地插入或删除进程。
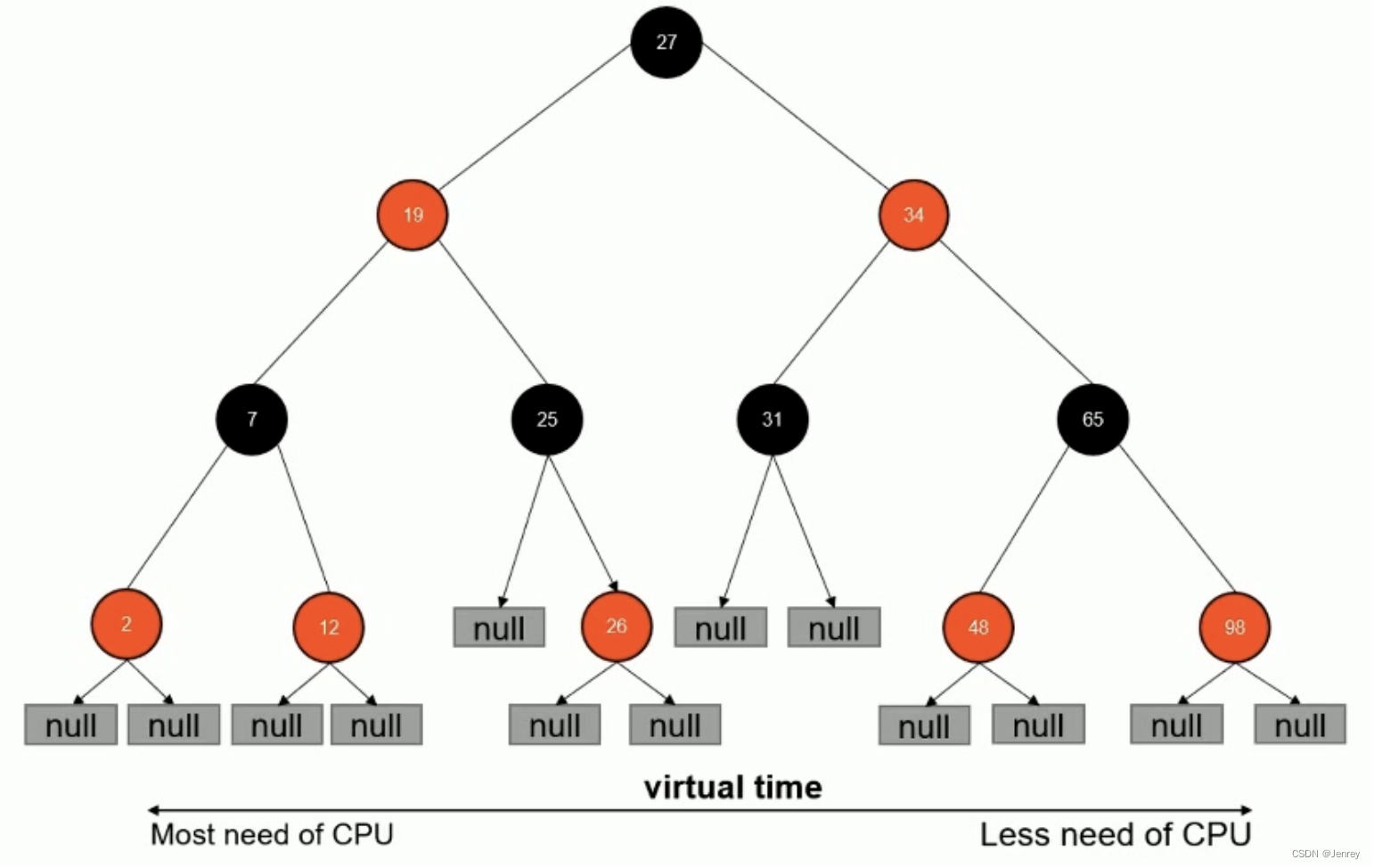
假如:某个Cgroup设置了权重1024,那么实际运行时间就是vruntime;
CFS进程调度
- 在时钟周期开始时,调度器调用
__schedule()函数来开始调度的运行。 __schedule()函数调用pick_next_task()让进程调度器从就绪队列中选择一个最合适的进程next,即红黑树最左边的节点。- 通过
context_switch()切换到新的地址空间,从而保证next进程运行。 - 在时钟周期结束时,调度器调用
entity_tick()函数来更新进程负载、进程状态以及vruntime(当前vruntime + 该时钟周期内运行的时间)。 - 最后,将该进程的虚拟时间与就绪队列红黑树中最左边的调度实体的虚拟时间做比较,如果小于左边的时间,则不用触发调度,继续调度当前调度实体。
4.5、文件系统 Union FS(联合文件系统)
docker就是把旧的技术整合在一起,namespace、Cgroup都不是新技术,docker的创新点就在于 所基于的文件系统。docker依赖于Union FS文件系统。
Union FS其实就是联合文件系统,本质是把多个文件目录mount成一个合并好的文件目录。
所有的进程跑在容器里,所谓的跑在容器里,其实就是使用namespace和cgroup技术做了一个隔离,所谓的联合文件系统就是为一个容器进程准备多个目录,你可以把多个目录联合到一起放到一个目录,那么这个目录你把它打包成容器进程的文件系统,那么对于容器来说就是rootfs。
- 将不同目录挂载到同一虚拟文件系统下(unite several directories into a single virtual filesystem)的文件系统
- 支持为每一个成员目录(类似Git Branch)设定 readonly、readwrite 和 whiteout-able权限。
- 文件系统分层,对readonly权限的branch可以逻辑上进行修改(增量地、不影响readonly部分的)。
- 通常Union FS有两个用途,一方面可以将多个disk挂到同一目录下,另一个更常用的就是将一个readonly的branch和一个writeable的branch联合在一起。
文件系统是如何工作的?
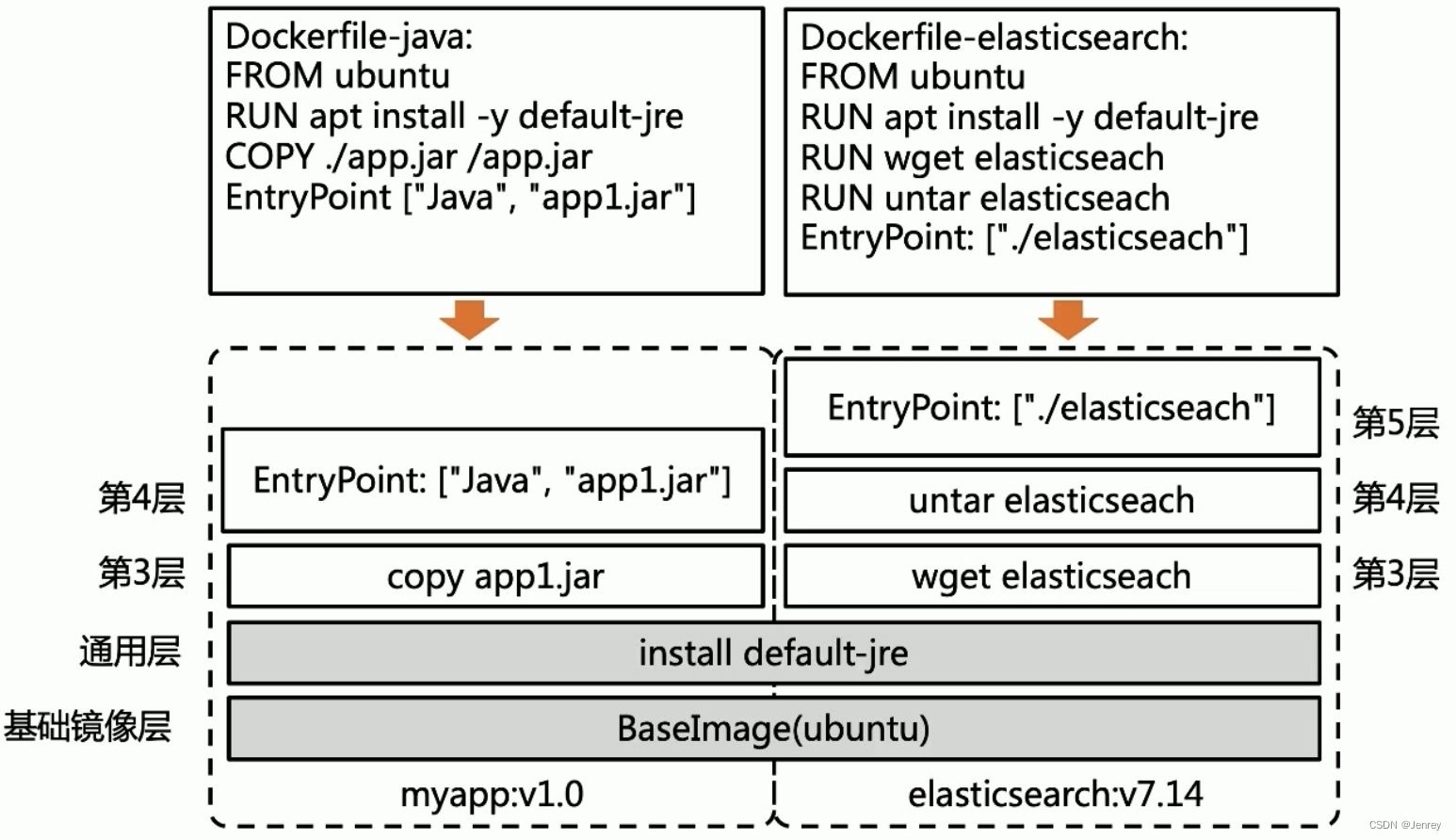
以容器镜像举例:容器镜像其实就是dockerfile build出来的。
下图中两个dockerfile文件的前两个指令是一样的,从容器镜像来说,这两层是完全一致的层,所以是通用层,这就是非常巧妙的地方,对于docker来说这是复用的,我们不管From多少个image ubuntu,在这个节点上真正拉取和构建的时候只有一个,不会有多份,这样的好处就是有了checksum机制,当我们只需要变更5M大小的文件时,虽然我们给docker的指令是重新拉1G的image,实际上只是做了一个5M的增量分发。白话就是“用一种通用的办法解决了所有应用的文件分发问题”。
典型的Linux文件系统组成
标准linux都是有两个fs:
- Bootfs(boot file system)
- 首先Bootfs里面有Bootloader,用来引导加载kernel
- 当kernel被加载到内存中后会把Bootfs umount掉,然后再去加载rootfs
- rootfs(root file system)
- rootfs也就是:/dev、/proc、/bin、/etc等标准目录和文件。
- 对于不同的linux发行版,bootfs基本是一致的,但rootfs会有差别。
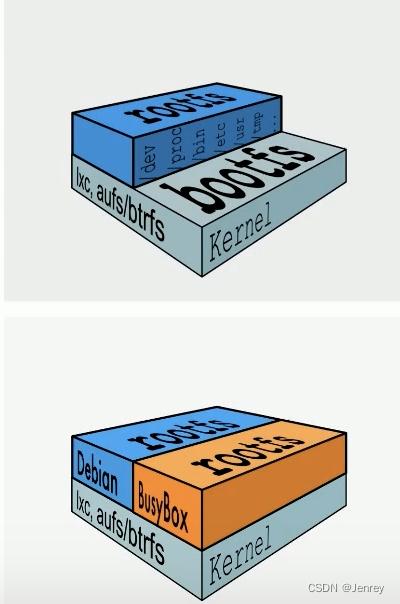
所以用ubuntu还是centos其实对容器来说我们关心的就是kernel,差异不是特别大。
容器只处理rootfs,因为kernel已经在宿主机上有了,所以所有的容器镜像最终只是把rootfs组装好,然后和容器进程产生关联。
Docker启动是如何加载文件系统的
docker本质是不模拟操作系统的,本质就是在主机上起了一个进程,所以这个进程本身是没有单独的kernel的,也就是说,对于容器进程来说它是没有Bootfs,但是每一个进程需要看到自己的文件系统,所以是有自己单独的rootfs。
总结,docker容器没有Bootfs,复用主机kernel。有自己的rootfs,这个rootfs通过容器驱动加载出来,并且mount给进程所拥有。
- Linux
- 在启动后,首先将rootfs设置为readonly,进行一系列检查,然后将其切换为“readwrite”供用户使用。
- Docker启动
- 初始化时也是将rootfs以readonly方式加载并检查,然后接下来利用union mount的方式将一个readwrite文件系统挂载在readonly的rootfs之上。
- 并且允许再次将下层的FS(file system)设定为readonly并且向上叠加。
- 这样一组readonly和一个writeable的结构构成一个container的运行时态,每一个FS被称作一个FS层。
写操作
由于镜像具有共享特性,所以对容器可写层的操作需要依赖 存储驱动 提供的写时复制和用时分配机制,以此来支持对容器可写层的修改,进而提高对存储和内存资源的利用率。
比如多个容器实例都是基于同一个镜像层出来的,那么在不同的容器实例中去改文件,实际上是改的增量的文件层,不是底层,底层是复用的。即多个容器共享同一个基础层,所有的变更都是在可写层完成的。
- 写时复制
- 写时复制,即Copy-on-Write。一个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多个拷贝。在需要对镜像提供的文件进行修改时,该文件会从镜像的文件系统被复制到容器的可写层的文件系统进行修改,而镜像里面的文件不会改变。不同容器对文件的修改都是互相独立、互不影响。
- 用时分配
- 按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间。
容器存储驱动
一个容器进程会有一个自己的mnt namespace(允许不同 namespace的进程看到的文件结构不同,这样每个namespcae中的进程所看到的文件目录就被隔离开了。),这个mnt namespace它的mount namespace也就是这个容器看到的文件系统和主机是不一样的,是隔离的空间,即容器内ls命令看到的和主机上ls看到的文件目录是独立的,是不同的。
容器本身是在主机上启动的一个进程,这个进程和其他的进程也没有差异,只不过放到了不同的namespace,如果我不给这个进程划mnt namespace,那么这个进程看到的文件是跟主机的一模一样的,所以这个容器就要去主机去读文件,没有一个很好的隔离;如果给这个容器进程分了一个独立的mnt namespace,那么对这个容器来说它可见的文件系统和主机是不一样的,这样的好处就是不需要对主机有任何的依赖,那么容器内应用进程所跑的runtime、所需依赖的中间件、所需要的配置都必须在容器的mnt namespace有效,这个的好处就是我打包一个容器镜像就自带环境了,我们在dev的环境把这个容器镜像打好,我挪到prod环境中无论这个主机上有什么文件,我都是不关心的,我这个容器镜像里面的mnt namespace所面对的文件系统是自带的,那么这样的话容器才有可移植性,这就是它的文件系统。
这部分要介绍的就是docker通过overlay这种技术实现了层叠的文件系统,所谓的overlayfs就是把不同的目录结构merge到同一个目录里去。然后把merge好的目录挂载到容器镜像里面,那么每一个容器进程看到的都是自己的独立的文件系统。
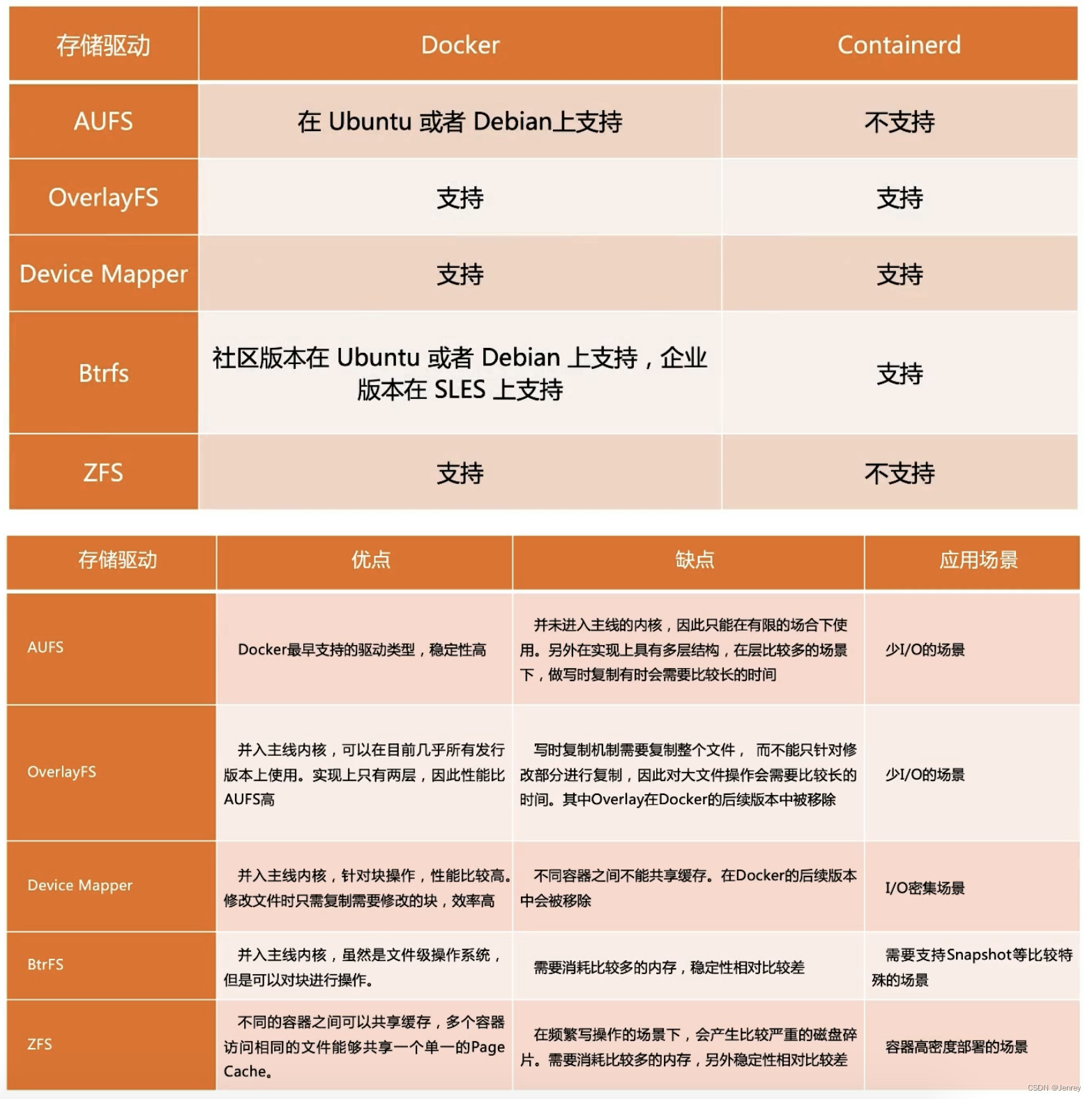
下面列出了从容器技术创立之初到现在所经历的各种文件驱动。
最早是AUFS、OverlayFS、Device Mapper,在较早以前Device Mapper是主流,原因就是OverlayFS不在kernel的主干版本上面,Device Mapper是相对成熟的,但是要比OverlayFS性能差一点。
现在我们提OverlayFS都是说overlay2了,而且也进入了kernel,所以现在主流基本上都是OverlayFS了。可以用docker info命令查看到Storage Driver这项是overlay2。
无论从可维护度和性能来说OverlayFS都是占优的,kernel自带,不用额外安装,需要装的就是docker本身或者containerd本身,因为自带所以就可以通过OverlayFS来为容器进程准备它的文件系统。
OverlayFS
OverlayFS也是一种与AUFS类似的联合文件系统,同样属于文件级的存储驱动,包含了最初的Overlay和更新更稳定的overlay2。
OverlayFS是Union FS联合文件系统的实现,Union FS有多种驱动,OverlayFS就是其中一种驱动。
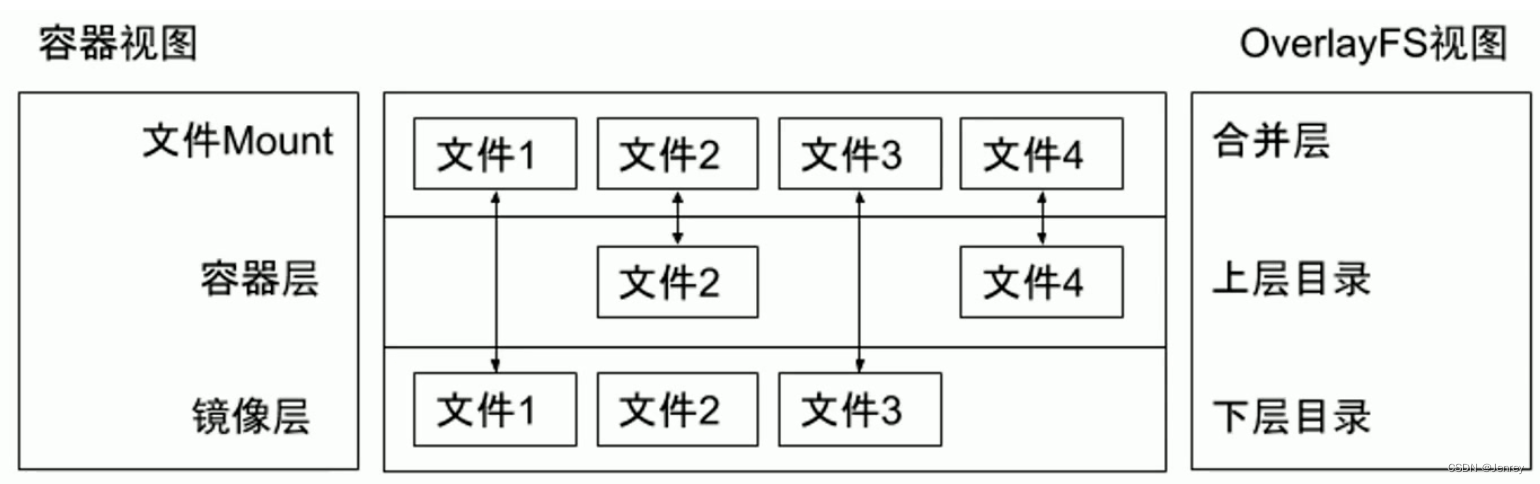
Overlay只有两层:
- upper层:代表容器可写层。
- lower层:代表镜像层。
通过mount命令可以构建Overlay的一个目录,在mount的时候可以指定upper层和lower层。
下面的代码可以证明,所谓的OverlayFS其实就是通过mount命令,指定-t也就是type=overlay,然后指定lowerdir参数和upperdir参数就可以把多个目录合并成一个目录,当upper层和lower层有同名文件以upper层为准。
而upper层和lower层最后会一起合并成一个合并层。
通过下图可以看出,如果一个文件存在于下层目录,在合并层是可见的;如果一个文件存在于上层目录,那么在合并层也是可见的;如果一个文件在上下层都存在,实际上在合并层中用的是上层的文件。所以我们可以得知,每一个镜像都是在下层目录中的,而dockerfile中的除From外每一条指令都是它的上层,一层一层往上叠的。
# OverlayFS 文件系统的原理验证cd /
# 创建4个目录
mkdir upper lower merged work# 创建4个文件
echo "from lower" > lower/in_lower.txt
echo "from upper" > upper/in_upper.txt
echo "from lower" > lower/in_both.txt
echo "from upper" > upper/in_both.txt# 查看/merged/下文件列表,是空的
ls /merged/# 通过mount命令指定type=overlay,同时指定lower点、upper点、merged点,进而实现把多个目录合并成一个目录
sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged# 再次查看/merged/下文件列表,发现有3个文件:in_both.txt in_lower.txt in_upper.txt
ls /merged/# “from upper”,证明了lower层和upper层有相同文件时,merged层的数据来自于upper层
cat merged/in_both.txt# 最后,我们即使删除了/upper/in_both.txt文件,结果也不会变。
那么真正在docker里是如何应用的呢?
使用docker inspect命令查看细节,其中在“GraphDriver”就定义了文件系统,有LowerDir、MergedDir、UpperDir、WorkDir,其实就是通过OverlayFS去mount出来的一个目录,其中可以看到LowerDir有很多不同的目录,是用冒号分隔的,事实上,docker的每一层都做了一个mount,相当于最下面mount的就是整个操作系统,然后不断的向上mount叠加出来的。WorkDir只是临时的工作目录;最终是以MergedDir为主。
4.6、Docker引擎架构
Docker本身也整合了containerd。
containerd和docker最初有差异的时候,docker有一个很大的问题,在Linux里面任何的进程都是由父进程fork出来的,所以在Linux里面都是有一个进程树的,在docker设计的初期,架构不像下图所示那样,它是docker daemon是主进程,任何的容器进程都是docker daemon fork出来的,那么可想而知这样的有个问题的,docker本身如果要重启、升级的时候,相当于父进程是要销毁的,父进程销毁,这些子进程怎么办?就会出现主进程docker一升级所有的应用就出问题的情况,这是docker早期存在的一个问题。
所以后面containerd出来了,containerd就做了一个概念叫container shim,containerd只是一个单纯的daemon,所有containerd fork出来的子进程的父进程不会是containerd,它把这个关系解绑了,它为每一个容器进程构建了一个shim作为它的parent,然后shim的父进程是systemd,这样containerd在重启的时候,所有的应用进程是不受影响的,这是containerd最早很大的一个优势。
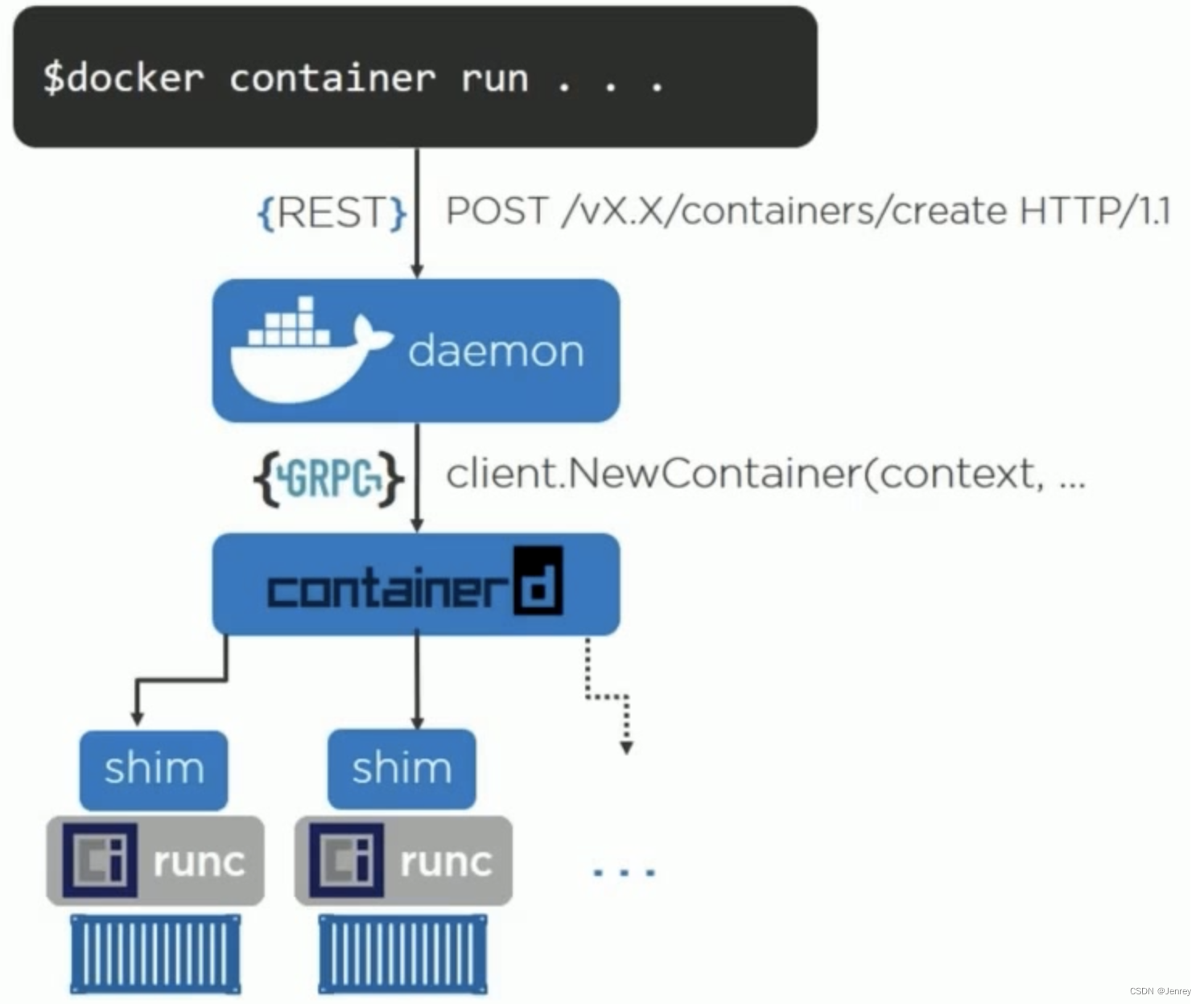
由上图我们可以看到:当用户去执行docker run的时候,它本身是一个REST方法发给docker daemon,docker daemon会通过GRPC的调用去调containerd,containerd会fork一个shim的进程出来,然后再通过runc去起真正的应用进程。所以,shim与容器是一对一的关系。
shim
# 查看所有正在运行的容器信息
docker ps
# 查看容器id为5d19f3e24920的元数据
docker inspect 5d19f3e24920
# 在“State”-“Pid”找到容器的Pid=4118,查看进程的父子结构
ps -ef |grep 4118
root 4118 4090 0 Jul16 ? 00:00:00 bash
root 18111 12476 0 11:07 pts/1 00:00:00 grep --color=auto 4118
可以看到此容器进程Pid为4118,它的父进程是Pid为4090,4090进程也就是shim。
# 查看Pid为4090的shim的父子结构
ps -ef |grep 4090
root 4090 1 0 Jul16 ? 00:00:06 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 5d19f3e249205d78e814d388885fd296bf0daa53e8bc167c0cfbd5fa392a3750 -address /run/containerd/containerd.sock
root 4118 4090 0 Jul16 ? 00:00:00 bash
root 18115 12476 0 11:10 pts/1 00:00:00 grep --color=auto 4090
可以看到Pid为4090的shim进程名字叫“containerd-shim-runc-v2”,其父进程是1也就是systemd。也就验证了和containerd daemon没关系了,所以containerd怎么升级对应用容器都是没影响的,而shim进程本身又是非常轻量级的,基本上不需要升级。
也就是说真正的用户态进程跟containerd daemon进程是没有任何关系的。这样不管containerd如何升级,我们的镜像是解绑的,是不受影响的。这是containerd的一个创举,当然现在docker也用了containerd,所以docker现在也没问题了,但是早期docker是有问题的。
shim不是容器的1号进程,我们进入到容器里面,容器里面的1号进程是它的entrypoint进程。shim进程是外面的在主机上的相当于host keeper这样的一个进程,它就是管其子进程的生命周期的。然后有些容器的运行时比如Podman后面就没有shim进程了,所以Podman和Containerd比起来这就是主要差异。
引申一下,在K8S的世界里大家在谈Containerd要替换掉docker,但是docker自己的架构本身后面真正去启容器的时候也是调了Containerd的。
这里,强调一下,我们用docker exec进入容器内部,执行ps -ef命令是能够看到pid=1的进程的,这个进程不要和容器外的进程混淆,我们之前讲过容器在独立的pid namespace里面的,那么这个容器内pid=1对应的是容器镜像里面的entrypoint进程。容器内pid=1的进程在主机上是有对应的进程的,容器的pid namespace在主机上也是能看得到的,如下图所示,是在主机上pid=8418的进程号,而8418的父进程8394就是这个docker容器进程所对应的shim进程,而shim进程的父进程就是主机上的pid=1也就是systemd进程。
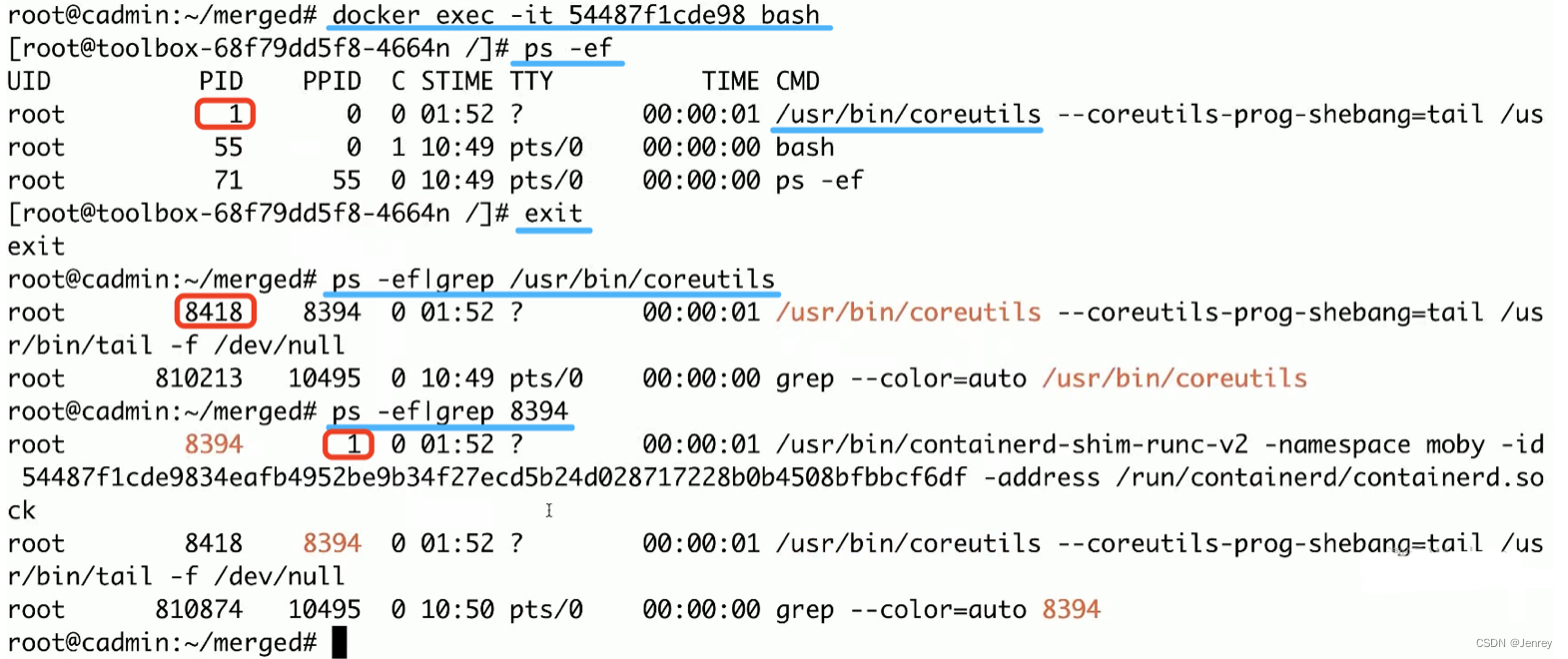
4.7、Docker网络
之前我们讲过,网络是可以有独立的namespace,意味着我们把一个进程放在独立的namespace里,就可以有独立的网络设备、网络配置,可以为其配置网卡、ip、路由、防火墙规则等等。
对于docker来说提供了多种网络模式:

- Null模式:可以为docker指定Null,意思就是不需要做任何的网络配置,只需要给我建一个网络namespace,在里面的网络不需要帮我来配,一般用于k8s。我要建一个容器,你帮我把namespace建出来,甚至k8s都不需要它来帮忙建namespace,即任何场景下我们需要自己去配网络的时候用。
- Host模式:复用主机的网络namespace,也就是说在此模式下告诉操作系统在fork这个进程的时候不新建网络namespace。
- Container模式:可以复用其他容器的网络,相当于我有一个A容器,已经建好网络了,在建B容器的时候我指定复用A容器的网络,相当于我的B容器网络namespace和A容器的网络namespace公用。
- Bridge模式:默认的形式。
上面主要是用来解决同一主机下面的容器的网络互通问题,即从主机如何访问到容器里面、同主机下不同容器的互相访问。
当我们的容器网络扩展到多个主机上面时,这个问题就变得复杂了。通常来说,容器网络和物理网络是隔离的,是两个不同的网络。假如我们有多台机器,这多台机器的网络是互通的,就好比办公室都有局域网,一般来说容器网络和物理网络是不一样的,除非我们用Host Network模式,皆大欢喜了,只要两台主机互通,那么其所属容器也就互通了,但是Hots Network就意味着端口是不能复用的,因为用的是主机网络,比如我们在主机启动了tomcat,再要起tomcat就起不来了,端口冲突了,所以一般来说我们的容器技术都是需要不同的网络namespace的。
容器网络一般来说都是不同的网段了,那么这个网段在物理网络上又是看不到的,所以这些网络包在物理网络是转不出去的,那么如何解决跨主机的网络问题呢?一般来说就是有Overlay通过网络封包的方式实现,还有Underlay复用底层网络来实现。
Underlay后面我们再说,就是复用底层网络,或者通过某种方式让底层网络知道这些ip段如何路由。

Null模式
强烈建议先看一下"默认模式 - 网桥和NAT",看看docker帮我们默认做了什么,再回过头自己来配置就比较容易了。
- Null模式是一个空实现、此模式下docker是不配置容器的网络的,只起一个容器,容器的net namespace也是不建的,所有的事情都是咱们自己去做;
- 可以通过Null模式启动容器并在宿主机上通过命令为容器配置网络。
# 手动模拟Docker为容器建立bridge网络流程命令总览
# $pid、$SETIP、$SETMASK、$GATEWAY 均为设置的临时环境变量,请自行设置
$ mkdir -p /var/run/netns
$ find -L /var/run/netns -type l -delete
$ ln -s /proc/$pid/ns/net /var/run/netns/$pid
$ ip link add A type veth peer name B
$ brctl addif br0 A
$ ip link set A up
$ ip link set B netns $pid
$ ip netns exec $pid ip link set dev B name eth0
$ ip netns exec $pid ip link set eth0 up
$ ip netns exec $pid ip addr add $SETIP/$SETMASK dev eth0
$ ip netns exec $pid ip route add default via $GATEWAY
手动模拟Docker为容器建立bridge网络
下面我们来动手自己配置一下:
-
我们要给容器set up一个网络,首先要把容器的network namespace手动创建出来(后面会把通过软连接的方式把/proc/$pid/ns/net和此手工创建的目录给link起来,这样的好处就是通过
ip netns list命令能看到当前的net namespace),下面就是创建net ns目录。# Create network ns $ mkdir -p /var/run/netns $ find -L /var/run/netns -type l -deletefind命令:在指定路径中搜索文件,并执行指定的操作
-
-L:用来处理符号连接,搜寻结果包括路径中的软连接下的结果
-
-type :按文件类型查找,l :链接文件
-
通过docker run --network=none的模式,创建一个nginx容器
# Start nginx docker container with non network mode $ docker run --network=none -d nginx -
–net或–network:指定容器的网络连接类型,支持 bridge/host/none/container:<name|id> 四种类型;
-
-d:让容器创建后并启动后,在后台运行
-
通过docker inspect命令找到我们上一步运行容器的pid
# Check corresponding pid,pid=20513 $ docker ps|grep nginx $ docker inspect 4e35d36bc919 | grep -i pid"Pid": 20513, "PidMode": "", "PidsLimit": null, -
通过nsenter命令进入pid=20513的net namespace并运行 ip a 命令来查看该容器的网络配置
# Check network config for the container $ nsenter -t 20513 -n ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever -
-n:表示net namespace,上面的命令代表 查看某进程的网络配置,常用语 查看docker容器进程的网络配置
发现,只有lo口,没有eth0,因为我们现在的模式是none,所以docker没有做额外的配置。
-
下面就开始手工配置此容器的网络配置。
首先,首先把pid=20513的net namespace link到/var/run/netns/文件下,这样就可以使用ip netns list命令来查看系统已存在的net namespace。# Link network namespace $ export pid=20513 $ ln -s /proc/$pid/ns/net /var/run/netns/$pid $ ip netns list20513 -
export:临时创建环境变量pid=20513,命令行窗口关闭后临时环境变量销毁。
-
ln:-s 创建软连接,语法格式为ln -s 源文件 目标文件;通过软连接的方式把/proc/$pid/ns/net和之前手工创建的network namespace目录给link起来,执行完此命令后,在手工创建的netns目录中就可以看到 20513 -> /proc/20513/ns/net 的信息了。这样的好处就是通过ip netns list命令就可以看到当前的net namespace。
-
ip netns list:列出系统中已存在的网络命名空间即net namespace。此命令显示的是 “/var/run/netns” 中的所有网络命名空间。
-
查看网桥和网卡信息
# Check docker bridge on the host $ brctl showbridge name bridge id STP enabled interfaces docker0 8000.0242b64436e9 no vethffffa8a$ ip a4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group defaultlink/ether 02:42:b6:44:36:e9 brd ff:ff:ff:ff:ff:ffinet 172.17.0.1/16 brd 172.17.255.255 scope global docker0valid_lft forever preferred_lft foreverinet6 fe80::42:b6ff:fe44:36e9/64 scope linkvalid_lft forever preferred_lft forever -
brctl show:使用bridge-utils的brctl命令,查询网桥信息,可以看到名字为docker0的网桥
-
ip a:查看所有网卡的接口信息。
-
通过ip link命令手工创建veth pair,这个veth pair一端叫A、一端叫B;即创建虚拟网络接口A,并为A创建一个映射端设备B;白话文就是在Linux主机上创建了一条虚拟的网线,网线上有两个口,一端叫A口、一端叫B口。
# Create veth pair $ ip link add A type veth peer name B -
ip link:link表示link layer的意思,即链路层。该命令用于管理和查看网络接口。
-
执行完上面命令后,如果你再执行ip a命令,你会发现多B@A和A@B
-
把A口插到docker0上面
# Config A# 往docker0这个Bridge上插A口 $ brctl addif docker0 A # 点亮A口,即设置为up状态 $ ip link set A up -
brctl addif docker0 A:将A端口加入网桥docker0
-
配置B口
# 因为我们想给容器分一个静态ip,所以我们要先看看待分配的ip有没有被占用,不通就是没被用。我们知道docker的网关是什么,我们就可以随便找个未使用的ip例如172.17.0.10给这个容器使用。 $ ping 172.17.0.10From 172.17.0.1 icmp_seq=1 Destination Host Unreachable# docker默认网关为172.17.0.1 $ SETIP=172.17.0.10 $ SETMASK=16 $ GATEWAY=172.17.0.1# 把B口放到容器pid的net namespace里面去 $ ip link set B netns $pid# 查看结果,发现已经把B口移到pid的net namespace里面来了,但是还没有配置ip配置 $ nsenter -t 20513 -n ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever 19: B@if20: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000link/ether 92:21:d7:5d:72:0b brd ff:ff:ff:ff:ff:ff link-netnsid 0# 下面:通过ip netns exec命令去pid的namespace里面去做一些事情: # 1、把B口rename为eth0 $ ip netns exec $pid ip link set dev B name eth0 # 2、把eth0点亮 $ ip netns exec $pid ip link set eth0 up # 3、给eth0配ip地址和掩码 $ ip netns exec $pid ip addr add $SETIP/$SETMASK dev eth0 # 4、配置路由 $ ip netns exec $pid ip route add default via $GATEWAY
ip netns:是基于 Linux Network Namespace 的一个实用工具
-
测试访问nginx
# Check connectivity curl 172.17.0.10
另外再强调一下:这个由B改名而来的 eth0@if20 和宿主机中的 A@if19 是成对的veth即veth pair;

默认模式 - 网桥和NAT
网桥:在Linux里面本身是有一个Bridge设备(网桥设备),是连接两个局域网的一种存储/转发设备,最简单的网桥有两个端口,复杂些的网桥可以有更多的端口。网桥的每个端口与一个网段相连。网桥可以是专门硬件设备,也可以由计算机加装的网桥软件来实现,这时计算机上会安装多个网络适配器(网卡)。
NAT(Network Address Translation):网络地址转换技术。
安装docker后会在主机Linux系统上创建一个Bridge设备(网桥设备,名字为docker0),而docker默认的网络地址段为172.17.0.1/16,而VirtualBox的Ubuntu虚拟主机为192.168.56.1/24,是在不同的网络地址段,本身是无法通信的,所以就需要docker0网桥结合NAT技术帮我们实现docker与宿主机Ubuntu的网络通信。
-
为主机eth0分配ip 192.168.0.101
-
启动docker daemon,查看主机iptables
-
# 查看NAT表的信息 iptables-save -t nat # 可以看到如下信息 -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-
-
在主机启动容器:
-
docker run -d --name ssh -p 2333:22 centos-ssh -
Docker会以标准模式配置网络;
- 创建 veth pair;
- 将 veth pair的一端连接到docker0网桥;
- veth pair 的另外一端设置为容器名空间的eth0;
- 为容器名空间的eth0分配ip;
- 主机上的Iptables 规则:
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 2333 -j DNAT --to-destination 172.17.0.3:22
-
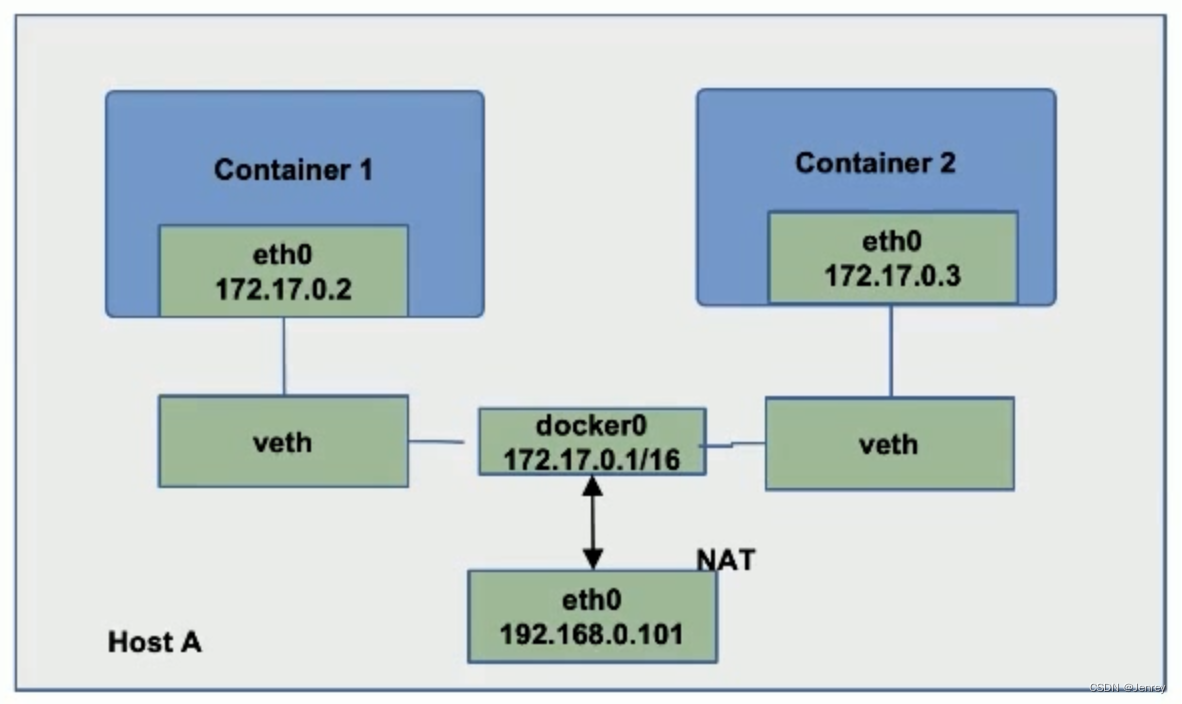
上图是标准的docker驱动所构建的网络,宿主机的ip是192.168.0.101,可以得出:安装docker后会在主机Linux系统里面创建一个Bridge设备(也叫做网桥设备,就是图中的docker0,如果不指定–network,创建的容器默认都会挂到 docker0上)的。
网桥设备一般是工作在OSI网络七层模型(最下面是链路层:主要工作在MAC地址上面,一个数据包传输出去的时候,它要去看当前的子网里面有没有对应的MAC地址,如果有对应的MAC地址直接就发过去了,那么其实网桥就工作在这个层面了)中的最下面的链路层。
图中起了两个容器,在容器配置里面可以配置说这台主机上会分配哪个网段,图中这台主机就分配了172.17.0.1/16这样的一个网段。那么,任何容器启动以后就会自动被分配一个ip(也就是图中的172.17.0.2和172.17.0.3),这就是docker的驱动,k8s叫**CNI(container network interface)定的是一个接口,docker里面叫CNM(container network manager)**它就是把自己的实现直接写进去了。
那么docker的驱动CNM会做什么呢?当启动一个docker容器的时候,它就会为你的容器分一个ip,然后接下来会去构建veth pair(是在Linux上虚拟的一个网络设备,可以理解为一根网线,一根网线有A、B两端,是双向的,从A端发的B端能收、从B端发的A端能收),所以对docker来说要配网络就很简单了,只需要创建一个veth,一端插在docker的网桥docker0上面,另外一端移到容器里面作为容器的虚拟网口(在容器内部叫eth0),并且把ip地址172.17.0.2配置在这个虚拟网口eth0上面,那么这样从主机到容器的网络就连通了。
如果在这个主机上启动了另外的容器,也是做同样的事情,也建一个veth pair,一端插在docker0的网桥上面,另外一端放到容器的network namespace里面(在宿主机和容器内我们执行lsns -t net命令都可以看到这个为容器分配的network namespace,注意如果容器关机就看不到此容器的net namespace了),veth pair是可以跨network namespace的。
所以,容器1和容器2它们是连接在同一个网桥上面的,所以它们的网络就连通了。
用命令去深度理解
# 通过docker run命令去起一个nginx的容器
docker run -itd -p 8888:80 nginx# 拿到nginx容器的id=d90a45507778
docker ps | grep nginx# 安装网桥管理工具包
apt install bridge-utils
# 使用bridge-utils的brctl命令,查询网桥信息,可以看到名字为docker0的网桥
brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242b64436e9 no veth8c808dd
# 使用docker inspect命令查询容器的进程pid=19547
docker inspect d90a45507778 |grep -i pid
# 进入pid为19547(docker容器的pid)的进程的net namespace查看此容器的网络配置
nsenter -t 19547 -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
17: eth0@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group defaultlink/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0valid_lft forever preferred_lft forever
可以看到这个容器本身有了自己的eth0并有了独立的ip地址 172.17.0.3,
# 查看路由表
nsenter -t 19547 -n ip r
也有自己的路由表,那么我在主机上就可以访问172.17.0.3这个ip地址了。
curl 172.17.0.3
到此所有的这些配置都是通过容器的驱动帮我们做的,接下来我们继续验证最开始我们执行的docker run命令的-p参数:-p是docker的port mapping概念,把主机的8888端口映射成容器的80端口,这样我们就可以通过主机ip的8888端口访问容器的80端口,因为我是MacOS上安装了VirtualBox,在VirtualBox里有一个虚拟机是ubuntu,ubuntu系统的静态IP是192.168.56.56,ubuntu里面安装了docker,所以我们要使用这个http://192.168.56.56:8888/来访问ubuntu安装的docker的nginx容器。使用docker logs -f --tail=200 d90a45507778可以看到我们刚才访问的请求记录。
其docker -p端口映射实现的原理就是通过iptable帮我们进行改写,我们查看NAT表信息:
# 查看NAT表的信息
iptables-save -t nat
# Generated by iptables-save v1.8.4 on Mon Jul 18 12:38:49 2022
*nat
:PREROUTING ACCEPT [2:174]
:INPUT ACCEPT [2:174]
:OUTPUT ACCEPT [59:4487]
:POSTROUTING ACCEPT [63:4743]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 172.17.0.3/32 -d 172.17.0.3/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 8888 -j DNAT --to-destination 172.17.0.3:80
COMMIT
# Completed on Mon Jul 18 12:38:49 2022
在13行日志中可以看到这条改写规则,如果你的协议是tcp,如果你访问的目标端口是8888,那么就会做DNAT,把这个请求转到172.17.0.3:80上面。
iptable是Linux kernel里面,在处理数据包的时候做包过滤和包修改这样的一个工具,你可以定义一些规则,Linux在处理这些数据包的时候,会来读这些规则按照你指定的规则去修改数据包的头,之前提过,任何的数据包在Linux kernel里面是有一个SKB的,SKB里面就会放这些数据包的请求的ip地址、请求的端口等,那么这条规则就是Linux kernel去处理数据包的时候发现你的请求协议和端口跟这条规则匹配,接下来就会把SKB的头改掉,把目标地址改成容器地址,然后把端口改成80,这样的话在协议栈处理完这个数据包以后,目标地址就变成了172.17.0.3:80,然后查本地路由表,发现172.17.0.3是应该走刚才那个容器建立的veth,那么这个包就会被转到容器里面去了。我们到此讲的都是容器的网络,k8s网络驱动放在后面再讲。
到此,我们就了解了容器的默认形式的网络是如何搭建的。
4.8、解决跨主机的网络问题 - Underlay模式、Overlay模式
比上面我们讲的 “Docker网络” 部分更复杂了来了,上面那些命令只是解决了容器和主机之间的网络连通,即从主机如何访问到容器里面、同主机下不同容器的互相访问。
那么,我们要跨主机连通怎么办呢?有好多种方法。
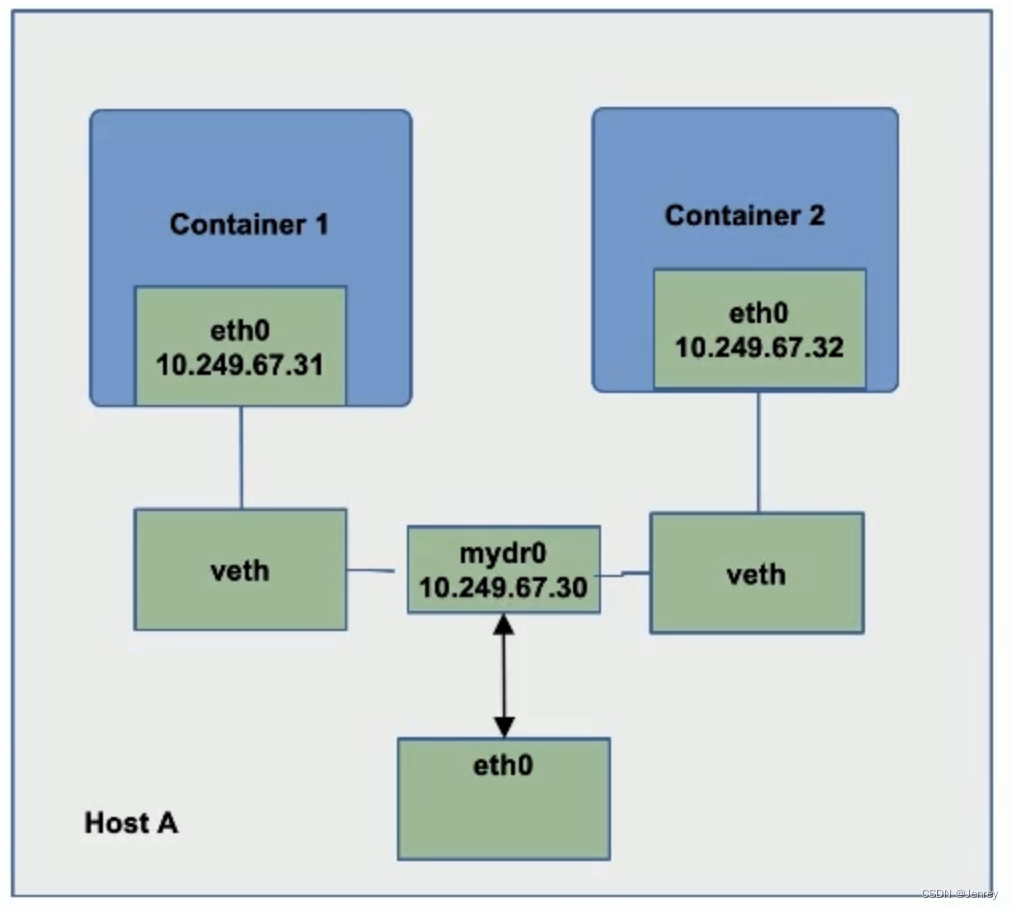
方法一:Underlay模式
比如10.249网络是物理网络所认可的ip段,那么我们能不能预留一个ip段给容器网络呢?如果这样可以的话,我是不是就可以通过ip分配的机制,把这些预留给容器的ip段分配给容器,然后在配置的时候直接把ip段配给容器,这样我跨主机的网络访问就直接互通了,因为这个ip段是下面底层物理网络所能清楚的认识到这些ip段的,它知道是怎么路由的,那么这种模式就叫Underlay,也就是容器网络依托于主机的物理网络。
- 采用Linux网桥设备(sbrctl),通过物理网络联通容器;
- 创建新的网桥设备mydr0;
- 将主机网卡假如网桥;
- 把主机网卡的地址配置到网桥,并把默认路由规则转移到网桥mydr0;
- 启动容器;
- 创建veth对,并且把一个peer添加到网桥mydr0;
- 配置容器把veth的另一个peer分配给容器网卡;
方法二:Docker Libnetwork Overlay模式
Overlay俗称隧道模式,Overlay就是容器A和容器B它是不互通的,但是主机A和主机B上面的底层网络是互通的。
Overlay就是在每一个主机上面会有一个设备,这个设备会去处理特定的数据包(容器网络的数据包),会在容器网络原始的数据包上面再加一层(在Linux里面,看到的任何数据包从Linux kernel层面看到的都是SKB,SKB会看到每一层的header,例如ip header、tcp header,它可以在不破坏原来这些header的基础之上再加一层header,就相当于在原始包上再加一层),加上的这一层原始地址就是主机A的地址,目标地址就是主机B的地址,这样这个包就能传输到对端了,传到对端之后,对端主机B的虚拟设备即图中的VTEP-2设备再把这一层剥掉,剥掉以后剩下的就是完整的内层数据包了,这样我们在主机B处理已经被剥掉的内层数据包的时候就知道目标地址是主机B上的容器B了,知道走哪个口了,这样数据包就发给容器B了。
所以,Overlay就是封包、解包的过程,会有一定的开销。
- Docker overlay 网络驱动原生支持多主机网络;
- Libnetwork 是一个内置的基于VXLAN的网络驱动。
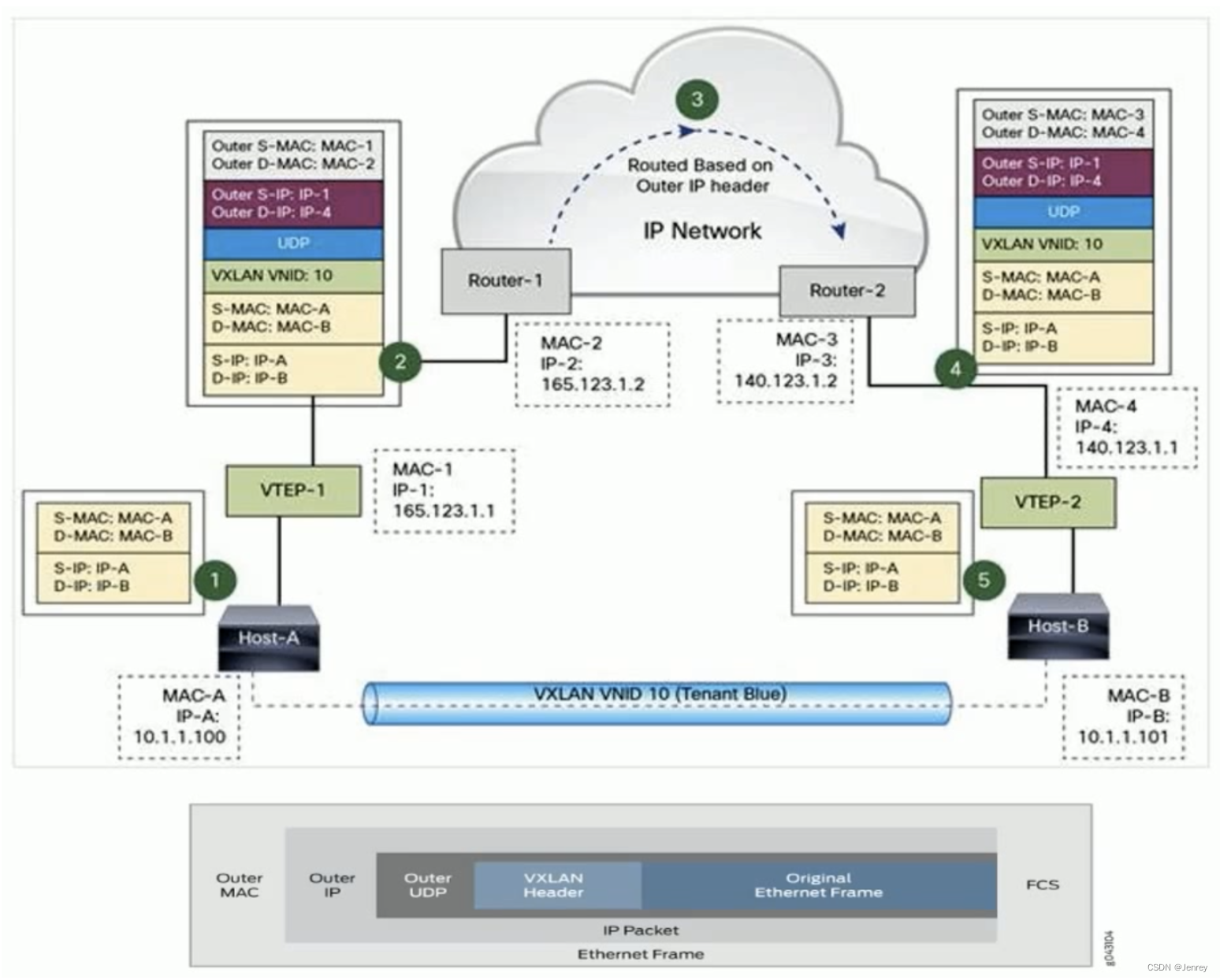
Flannel工具
Docker跨主机容器间网络通信实现的工具有Pipework、Flannel、Weave、Open vSwitch(虚拟交换机)、Calico
比较出名的 Flannel工具就是走Overlay,Calico工具也有Overlay模式。
Flannel工具会在每一个主机上有一个 flanneld 这样的设备,任何数据包在出去的时候会被flanneld封一层,这样这个包就能转到对端主机,在对端主机上的flanneld会把这个数据包解掉,这样就实现了跨主机容器的数据传输。
- 同一主机内的Pod可以使用网桥进行通信。
- 不同主机上的Pod将通过flanneld将其流量封装在UDP数据包中。
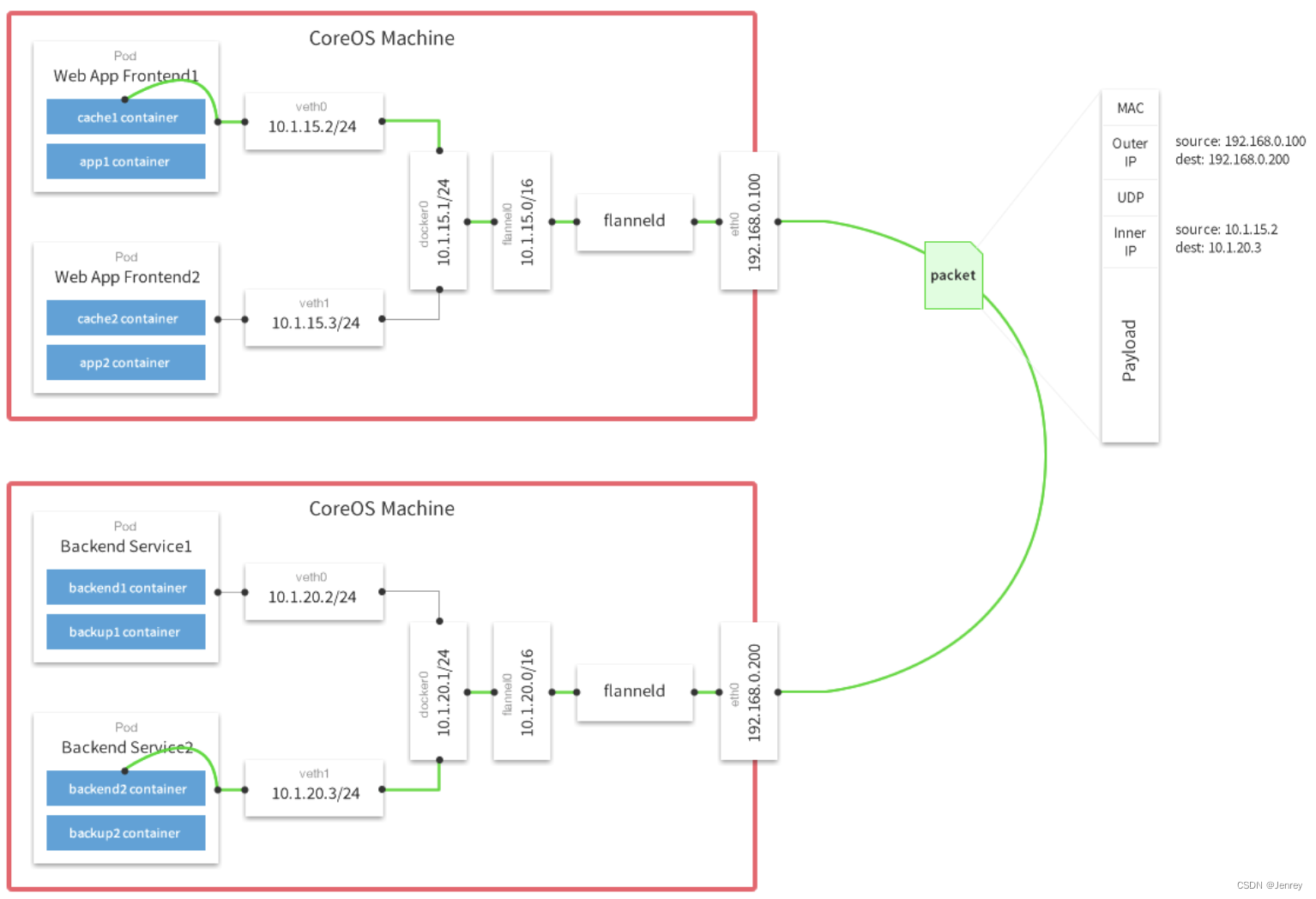
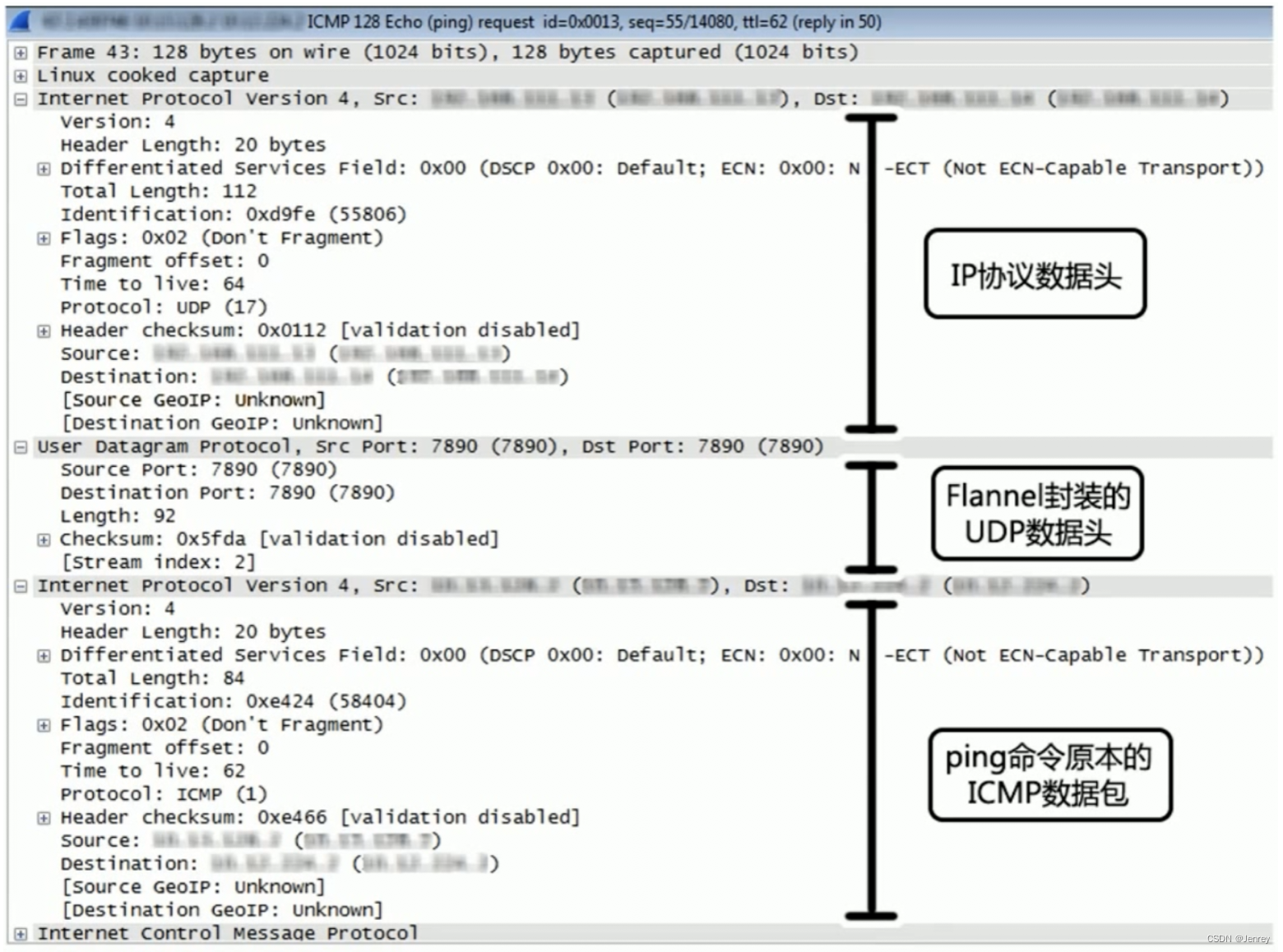
下图就是Flannel Overlay数据包的示例
Docker命令手册
Docker程序相关
# 查看docker版本信息
docker version# 启动docker server(宿主机为linux则在安装后需要执行该命令)
systemctl start docker# 重启docker服务
systemctl restart docker# 关闭docker服务
systemctl stop docker# 关闭docker并关闭被访问自动唤醒机制
# docker自带一个机制:“在关闭状态下被访问自动唤醒机制”,很人性化,即这时再执行任意docker命令会直接启动(例如docker ps等docker的命令)
systemctl stop docker.socket# 显示docker的一些状态
docker info# 显示docker帮助
docker# 显示container帮助
docker container --help# 登录dockerhub
docker login# 登录私有镜像仓库(例如:harbor),http需要先配置/etc/docker/daemon.json可信任
docker login 192.168.31.64# 查看Docker 磁盘使用情况
docker system df
image相关
从registry拉取image
# 默认从Docker Hub拉取,如果不指定版本,会拉取最新版
docker pull nginx# 指定版本拉取Image
docker pull nginx:1.20.0# 从Quay上拉取镜像
docker pull quay.io/bitnami/nginx# 拉取个人的镜像
docker pull jenrey/hello:1.0
查看现有镜像image
docker images
# 或者
docker image ls
删除镜像image
# 如果该镜像有一些正在使用的容器(不管容器是什么状态),那么是无法删除的
docker image rm 0922eabe1625# 删除目前没有使用的所有image
docker image prune -a# -f:强制删除镜像,即便有容器引用该镜像
docker image rm -f c15e4f843f01
显示image更多详细信息
docker image inspect f0b9a9a54136
# 关于详细信息的部分主键解释
# Os:代表image所跑在什么系统下
# Architecture:这个image可以用在什么样的CPU架构上
# RootFS:Layers:分层
保存镜像到本地
# -o:代表output,就是输出
docker save -o rocketmq.tar rocketmq
- -o:指定保存的镜像的名字;
- rocketmq.tar:保存到本地的镜像名称;
- rocketmq:镜像名字,通过
docker images查看
载入本地镜像
# --input:可以简写成-i
docker load --input rocketmq.tar
# 或
docker load < rocketmq.tar
build dockerfile
# build当前路径的Dockerfile
docker build .# -f:指定要使用的Dockerfile路径
docker build -f ./Dockerfile_terraformexec .# -t:就是tag,代表镜像的名字,名字后可以使用:来打一个版本号
docker image build -t hello:1.0 .
镜像重命名
# eaf68a497bbf为image ID
docker image tag eaf68a497bbf jenrey/alpine_tf:1.0
根据一个已经存在的image去创建一个新的image并使用新的tag
# hello:1.0是已经存在的image名字
# jenrey/hello:1.0是新的image名字,这里jenrey/是我的dockerhub用户名
docker image tag hello:1.0 jenrey/hello:1.0
显示镜像分层
docker image history hello
# 或
docker history hello
把镜像推送到仓库中
docker push jenrey/hello:1.0
container相关
查看容器
# 查看所有正在运行的容器信息
docker ps
# 或者
docker container ls# 查看所有容器信息
docker ps -a# 只列出正在运行的容器id
docker ps -q# 列出最新创建的容器
docker ps -l
创建容器
# 根据镜像nginx,创建后台运行容器
docker run -d nginx# 根据镜像3ee2430b7176,创建后台运行容器并进行交互式shell
docker run -it -d 3ee2430b7176 sh# 根据镜像3ee2430b7176,创建后台运行容器并进行交互式shell,并设置hostname为centos7、设置容器名为myCentos7
docker run -it -d --hostname centos7 --name myCentos7 3ee2430b7176 bash# 根据镜像python-demo创建容器并执行`python /hello.py`命令
docker run -it python-demo python3 /hello.py# 创建容器并在退出的时候自动删除
docker run --rm -it ipinfo ipinfo 8.8.8.8# Linux挂载数据卷
docker volume create wwwroot # 先创建数据卷名为wwwroot,才能挂载
# type:挂载方式的类型[volume | bind]
# src:指定数据卷名字,数据会持久化到这个卷里,数据卷存储在宿主机的/var/lib/docker/volumes路径下(macOS不同)
# dst:挂载到镜像中的哪个目录下(想把容器中哪个目录下的数据存储到宿主机就写哪个路径)
docker run -d --mount type=bind,src=wwwroot,dst=/usr/share/nginx/html 3ee2430b7176# macOS只能用Bind Mounts模式挂载
# /macOSFileSystem/xxx:MacOS路径或文件,如果没有存在,不会自动创建,会抛出一个错误。
# /containerFileSystem/yyy:容器内的路径或文件
docker run -d -it -p 8080:8080 --name=mycontainername -v /macOSFileSystem/xxx:/containerFileSystem/yyy 3ee2430b7176
-
--privileged=true:特权启动 -
--hostname mail.wq.com:设置hostname -
-a stdin: 指定标准输入输出内容类型,可选 STDIN/STDOUT/STDERR 三项;
-
-d: 后台运行容器,并返回容器ID;
-
-i: 以交互模式运行容器,通常与 -t 同时使用;
-
-P: 随机端口映射,容器内部端口随机映射到主机的高端口(比较大的端口号)
-
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
-
-t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
-
–name=“nginx-lb”: 为容器指定一个名称;
-
–dns 8.8.8.8: 指定容器使用的DNS服务器,默认和宿主一致;
-
–dns-search example.com: 指定容器DNS搜索域名,默认和宿主一致;
-
-h “mars”: 指定容器的hostname;
-
-e username=“ritchie”: 设置环境变量;
-
–env-file=[]: 从指定文件读入环境变量;
-
–cpuset=“0-2” or --cpuset=“0,1,2”: 绑定容器到指定CPU运行;
-
-m :设置容器使用内存最大值;
-
–net=“bridge”: 指定容器的网络连接类型,支持 bridge/host/none/container:<name|id> 四种类型;
-
–link=[]: 添加链接到另一个容器;
-
–expose=[]: 开放一个端口或一组端口;
-
–volume , -v: 例如-v=“/test”,即将容器内的/test目录(不存在会自动创建)定义为外挂存储卷(存储卷位置使用docker inspect 容器id查看),等价于Dockerfile的VOLUME指令。
-
–restart=
- always:无论退出状态是如何,都重启容器;
- on-failure:只有在非0状态退出时才从新启动容器;
- no:容器退出时,不重启容器;
- on-failure:10 指定Docker将尝试重新启动容器的最大次数。默认情况下,Docker将尝试永远重新启动容器。
-
3ee2430b7176是使用docker images查看的镜像id
进入容器内部
docker exec -it -u root 0b0e3c382334 sh
- -d : 分离模式: 在后台运行
- -i : 即使没有附加也保持STDIN 打开
- -t : 分配一个伪终端
- -u : 用什么用户登录
如果从这个容器执行exit命令退出,容器不会停止,这就是推荐使用 docker exec 的原因。
另一种:
# 后台模式转前台模式(退出会让容器stop)
docker attach 0b0e3c382334 # 不推荐
启动容器
docker start b750bbbcfd88
停止容器
# 停止指定容器
docker stop <容器 ID># 停止所有容器
docker stop $(docker ps -q)
删除容器
# 删除指定容器
docker rm b750bbbcfd88# 删除多个指定容器
docker rm cd3 269 34b 751# 强制删除一个正在运行的容器
docker rm a6d8f4b37ff0 -f# 删除所有容器
docker rm $(docker container ps -aq)# 删除所有已经退出的容器
docker system prune -f
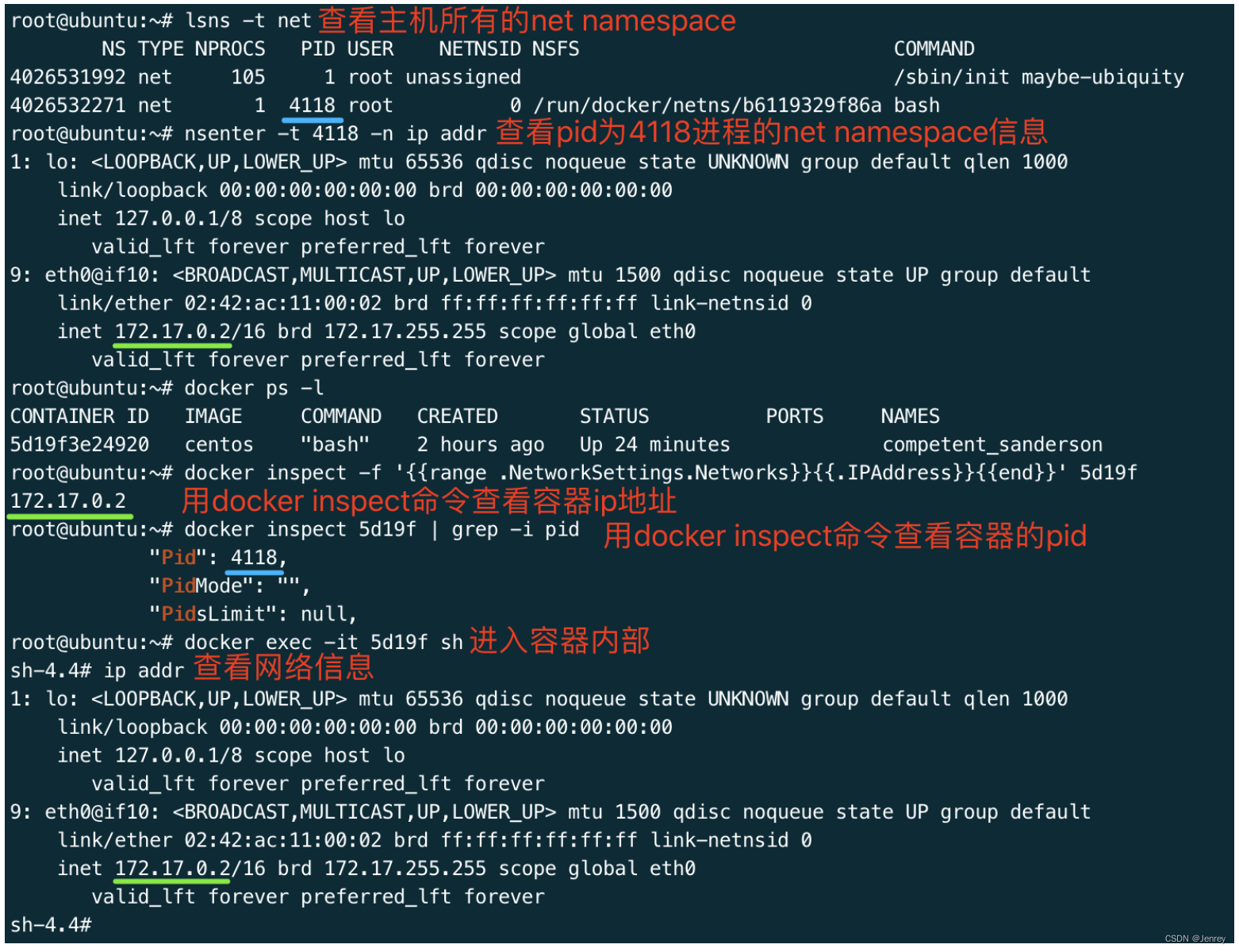
查看容器ip地址
# b750bbbcfd88为容器Id
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' b750bbbcfd88
也可以用Linux自带的命令查看
# 查看当前系统的所有net namespace
lsns -t net# 进入pid为4118的进程(docker容器的pid)的net namespace查看此容器的网络配置
nsenter -t 4118 -n ip addr
查看容器产生的log
# -f:动态跟踪容器产生的log
docker logs -f b750bbbcfd88# 查看容器最后200行日志
docker logs -f --tail=200 b750bbbcfd88
查看容器内运行的进程
docker top c03bef044e48
通过容器创建新的image
docker container commit b33db088cee0 mynginx:1.0
# 或者
docker commit b33db088cee0 mynginx:1.0
更新容器启动参数
# 更新 CPU 共享数量
docker update --cpu-shares 512 f361b7d8465
# 更新容器的重启策略
docker update --restart=always f361b7d8465
# 更新容器内存
docker update -m 500M f361b7d8465
获取容器/镜像的元数据
docker inspect b750bbbcfd88
拷贝文件至容器内
docker cp file1 <containerid>:/file-to-path
# 将主机/www/runoob目录拷贝到容器96f7f14e99ab的/www目录下。
docker cp /www/runoob 96f7f14e99ab:/www/
# 将容器96f7f14e99ab的/www目录拷贝到主机的/tmp目录中。
docker cp 96f7f14e99ab:/www /tmp/
这篇关于【带你上手云原生体系】第三部分:Docker从入门到上天【非物质文化遗产宝藏篇!白话文精讲Namespace、Cgroup、OverlayFS、layer、Network】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






