本文主要是介绍BEV(Bird’s-eye-view)三部曲之二:方法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Introdution
Why BEV
- 高度信息在自动驾驶中并不重要,BEV视角可以表达自动驾驶需要的大部分信息.
- BEV空间可以大致看作3D空间.
- BEV representation有利于多模态的融合
- 可解释性强,有助于对每一种传感器模态调试模型
- 扩展其它新的模态很方便
- BEV representation有助于下游的prediction和planning任务
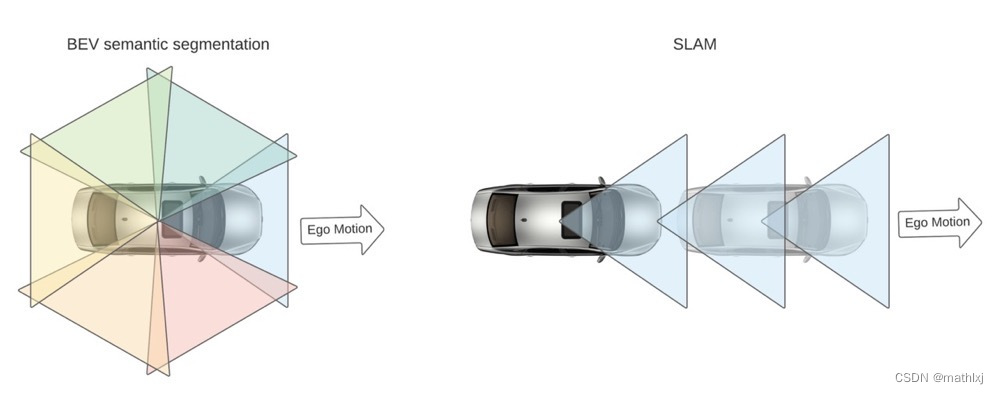
- BEV语义分割依赖于朝向不同的多摄像头,比SALM只朝一个方向获取语义更丰富;通知在ego运动速度慢的时候也能work.
- 在纯视觉系统(无雷达或激光雷达)中,几乎必须在BEV中执行感知任务,因为传感器融合时没有其它3D观测可用于视图转换
BEV的难点
- 视角变换。为了得到BEV representation,算法需要利用
- 先验的几何信息,包括相机的内参和外参(可能有噪声)
- soft priors:路面布局的信息库
- common sense:车在BEV视角下不会overlap.
- 数据获取与标注。
- 人手工标注
- 使用一些人造的数据
- 单目的相机获取图像上从3D到2D的映射图像,但是从2D提升到3D本身就是个ill-posed problem(解不唯一).
分类法
- 监督/indirect supervision
- 3D目标检测/扫图/预测/语义分割
- 输入: 单张图像/多张图像/仅雷达/图像+雷达/其它传感器融合
任务拓展
一些较新的数据集,例如(Lyft, Nuscenes, Argoverse),提供了
- 3D检测框
- HD map
- ego在每个时间戳时在HD map的位置
BEV的语义分割分为静态(道路布局)语义分割和动态实例分割,因此可以基于ego定位的结果,将静态的map映射到ego坐标系
视角变换的主要方法
- 逆透视变换(IPM, Inverse Perspective Mapping),例如Cam2BEV。假设地面上平的,一般只用在车道线检测或free space检测。
- Lift-splat。例如Lift, Splat, Shoot;BEV-Seg;CaDDN;FIERY。先估计深度信息,将图像提升到类似于3D点云,再splat得到BEV视角特征
- MLP。使用MLP直接对变换矩阵进行预测,例如VPN,HDMapNet
- Transformer。基于attention的transformer来建模视角的变换,最近论文比较多。
二、仅摄像头X语义分割
VPN (IROS 2020)
-
paper,github , 无速度汇报
-
输入:多模态,主要是多视角的图像
-
输出:语义分割
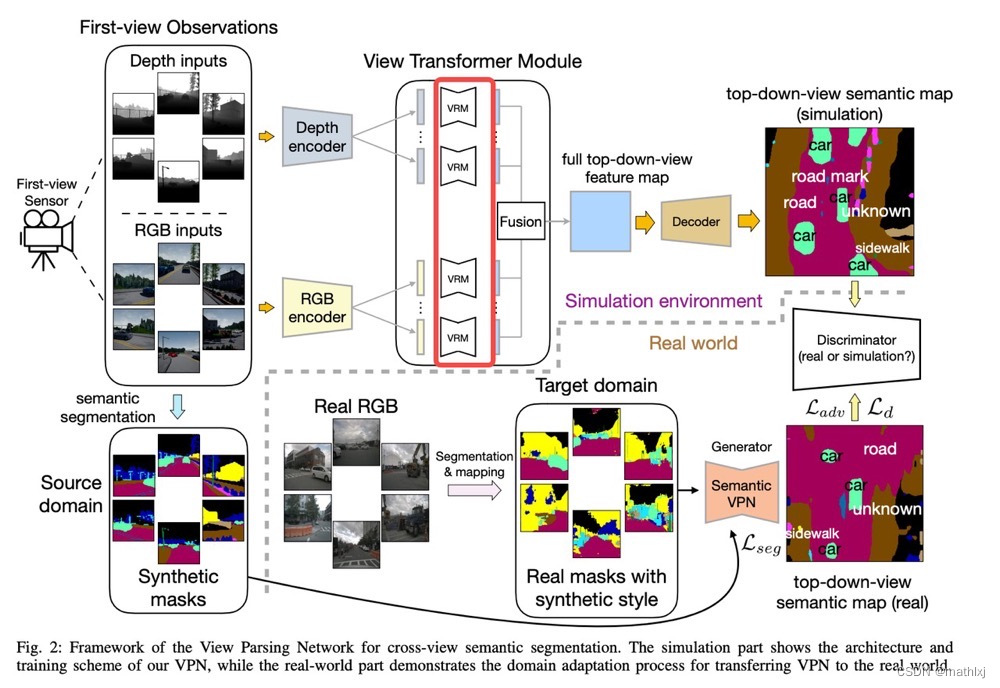
VPN (Cross-view Semantic Segmentation for Sensing Surroundings)几乎是第一个探索BEV语义分割的任务。
-
VPN 对每个模态的每个输入经encoder得到的feature map,经过不同的MLP回归从原始view到BEV视角的映射矩阵R_i(View transformer)。当然,不足之处是也忽略了feature点与点之间的位置关系。
-
使用人造的数据和对抗损失来训练。
-
View transformer:输入(原视角)与输出(BEV视角)尺寸相同。(实际上是没必要的)
Cam2BEV (ITSC 2020)
A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View
-
paper,github,无速度汇报
-
输入:4个摄像头
-
输出:语义分割
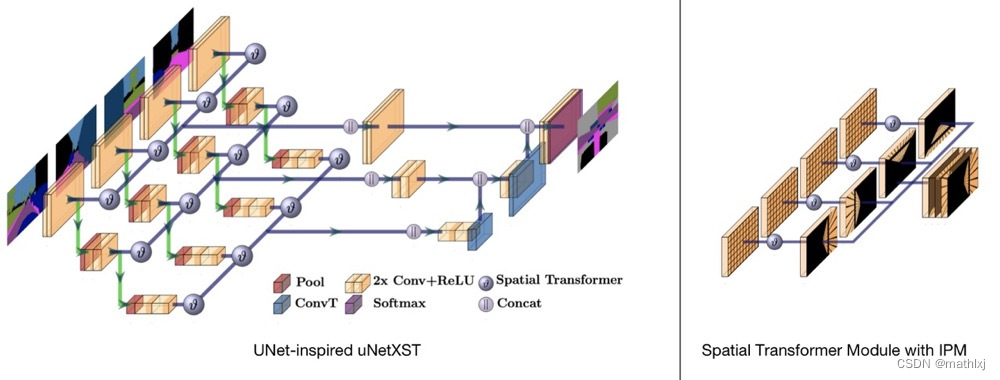
Cam2BEV 使用一个space trasnformer module with IPM(Inverse Perspective Mapping)来将原视角的feature映射到BEV空间。
-
主干网络借鉴了uNet的思想
-
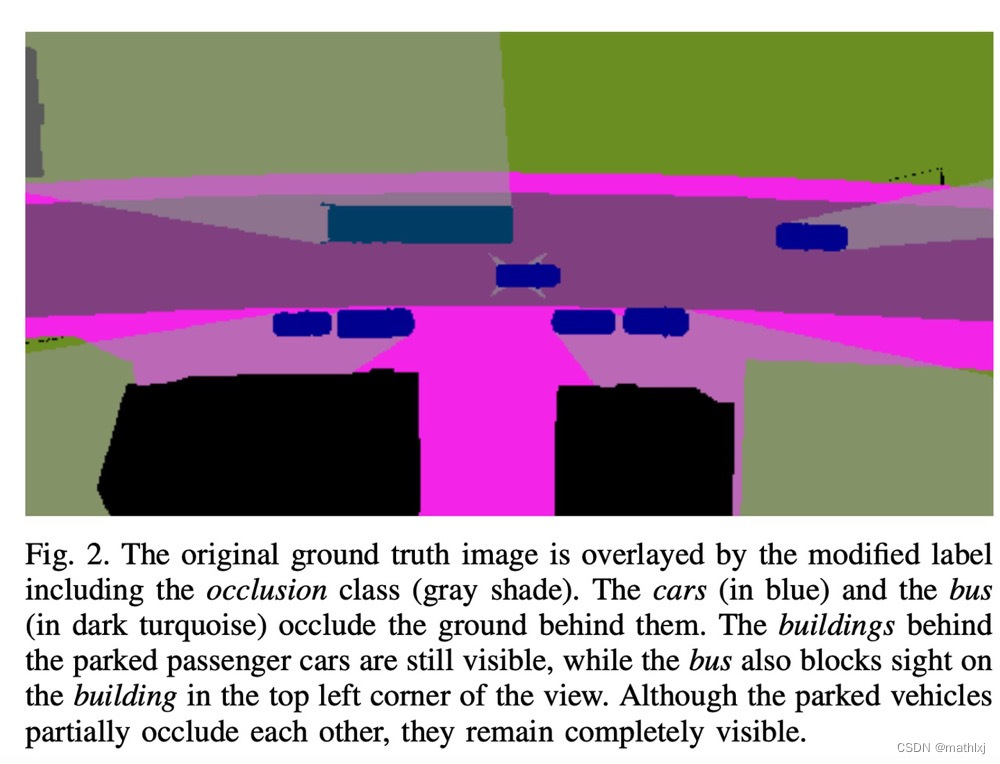
对ground truth做预处理,来生成被遮挡的部分为一类。
-
Spatial Transformer Module
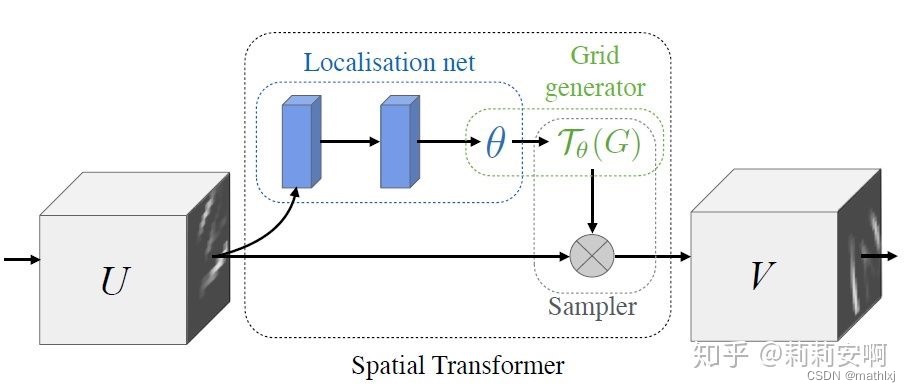
- Localisation Network-局部网络,由输入特征图回归变换矩阵
- Parameterised Sampling Grid-参数化网格采样,得到输出特征图的坐标点对应的输入特征图的坐标点的位置
- Differentiable Image Sampling-差分图像采样,利用插值方式来计算出对应点的灰度值
-
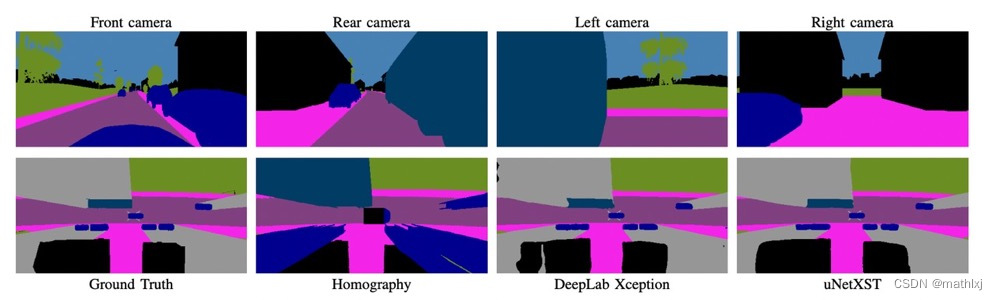
直接用四个相机的语义分割结果作为输入,类别有road, sidewalk, person, car, truck, bus,
bike, obstacle, vegetation.
MonoLayout(WACV 2020)
MonoLayout: Amodal scene layout from a single image
-
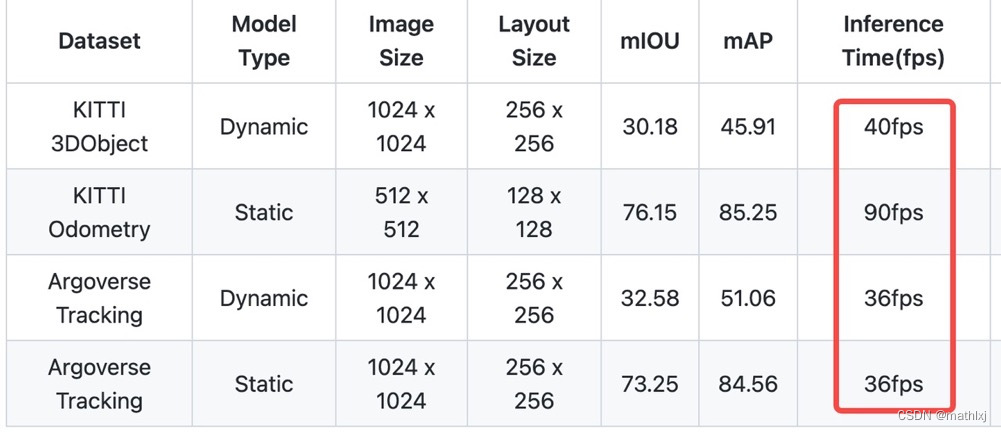
paper,github,video,在1080Ti上>32fps,具体见下图
-
输入:单个摄像头
-
输出:语义分割,道路和交通参与者
-
Shared encoder,分两个decoder,一个用来做静态语义分割,一个做动态语义分割
-
对KITTI数据集使用temporal sensor fusion生成一些weak groundtruth,通过结合2D语义分割结果和位置信息
-
对抗学习损失,静态分割head的先验数据分布来自公开数据集OpenStreetMap,属于unpaired fashion.
PyrOccNet (CVPR 2020)
Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
-
paper,github,video,无测速结果
-
输入:多个摄像头
-
输出:语义分割,道路、交通参与者、障碍物
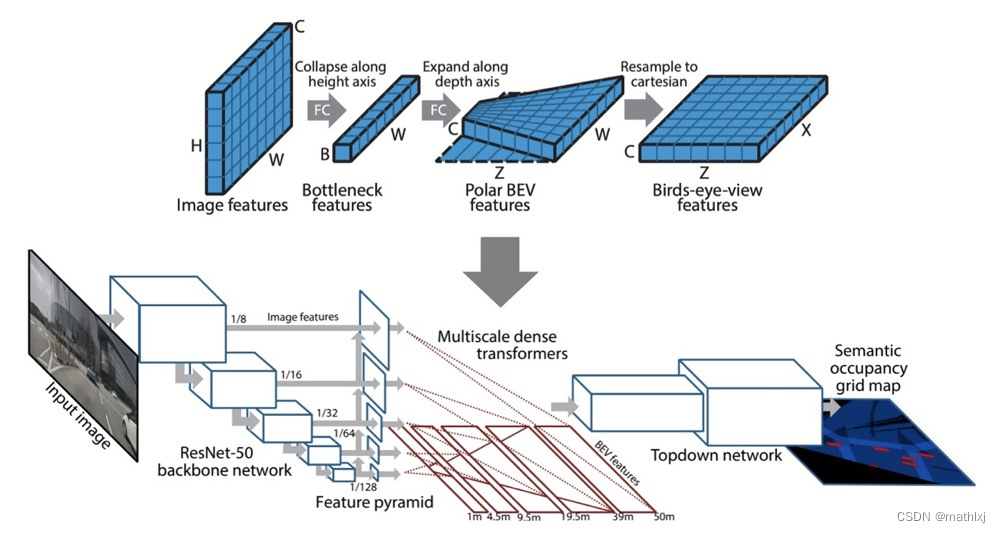
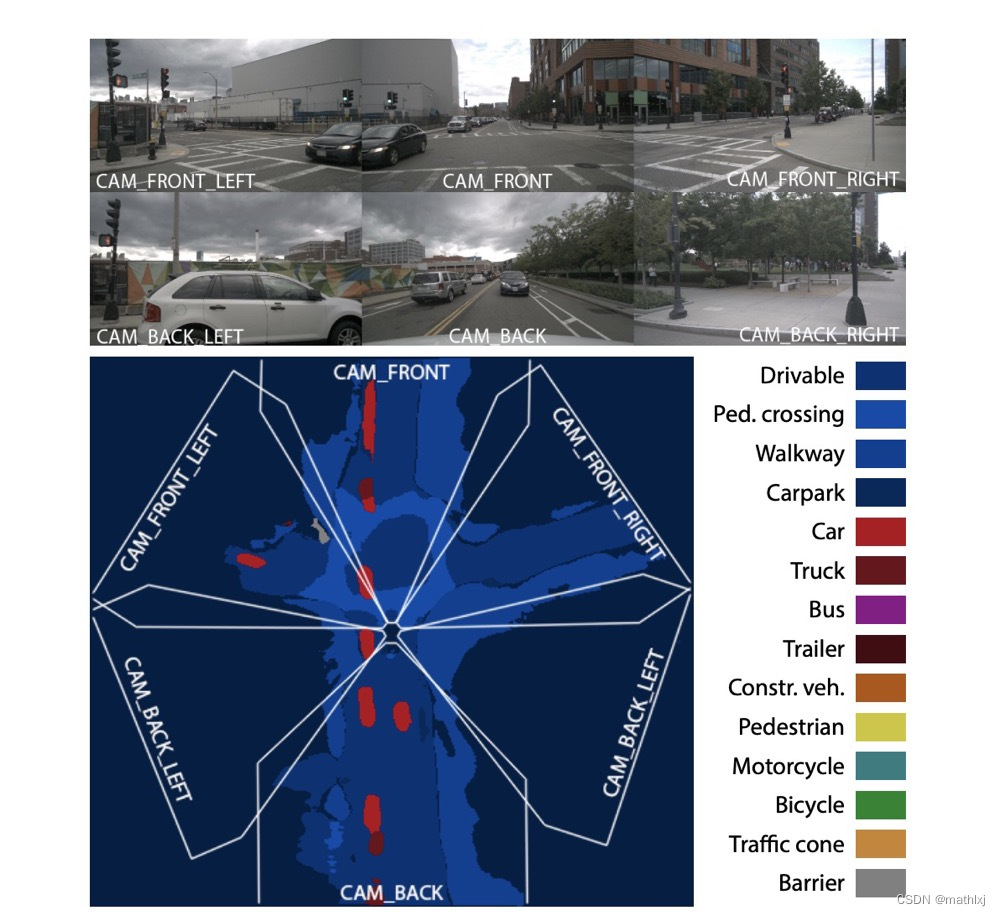
-
Semantic occupancy grid prediction:与2D图像的语义分割类似,预测 m i c m_i^c mic,即第c类占据第i个grid的概率
-
dense transformer module,use of both camera geometry and fully-connected reasoning to map features from the image to the BEV space。这里feature map的size不一定一致了,输入为
H × W × C H\times W \times C H×W×C, 输出为 Z × X × C Z\times X \times C Z×X×C。- 水平方向的变换只需要用相机的参数即可获得;竖直方向的变换需要更多信息,因为常有很多遮挡、缺少深度信息和路面拓扑的不可知。
- 为了最大化保留水平方向信息,将水平方向保留,拉平竖直和channel维度B,将输入reshape为 B × W B\times W B×W, 沿着水平维度做1D卷积,得到维度为 Z × W × C Z\times W \times C Z×W×C的输出
- 使用相机的焦距、水平位移等参数, 对输出特征做resampling到BEV维度
-
Multiscale transformer pyramid
-
使用Bayesian Filtering融合跨相机和扩时间的信息。
Lift, Splat, Shoot (ECCV 2020,NVIDIA)
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
-
paper,github,主页, 35 hz on a Titan V
-
输入:多个摄像头
-
输出:语义分割,道路和交通参与者
-
第一篇对每个角度的摄像头作用于不同的CNN,对像素点的深度进行估计,根据深度将感知的图像提升大3D点云,然后使用相机外参(已知)映射到BEV空间,最后使用一个BEV CNN来精修这些预测。

-
流程
-
Lift: Latent Depth Distribution:无训练参数地将2D图像(H,W)等深度间距地提升到(D,H,W),神经网络预测该深度的置信度,对生成的feature乘以该深度的概率。
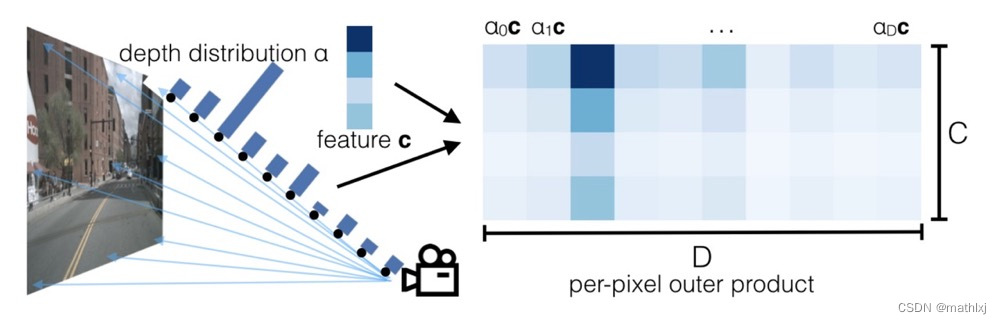
-
Splat: Pillar Pooling:借鉴pointpillars,得到(C,H,W)的feature,可被CNN处理
-
Shoot: Motion Planning:为ego预测K条轨迹模板的分布
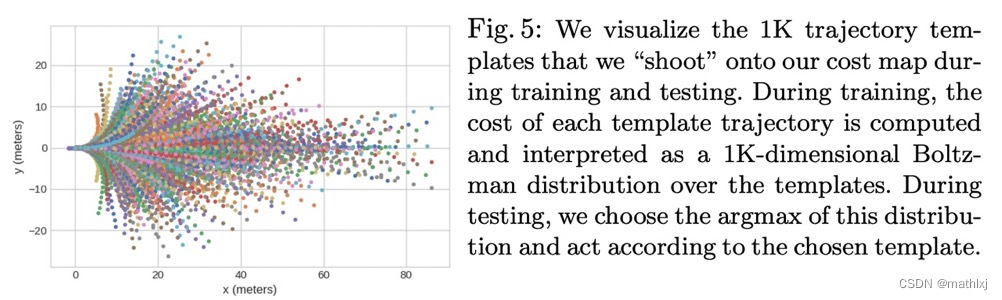
-
结果展示(其实是个动画,可以进主页看)

-
BEV Feature Stitching (RAL/ICRA 2022)
Understanding Bird’s-Eye View Semantic HD-Maps Using an Onboard Monocular Camera
-
paper,github,21FPS on a RTX 2080Ti
-
输入:单个摄像头的多帧+估计的ego pose
-
输出:静态/动态目标的分割
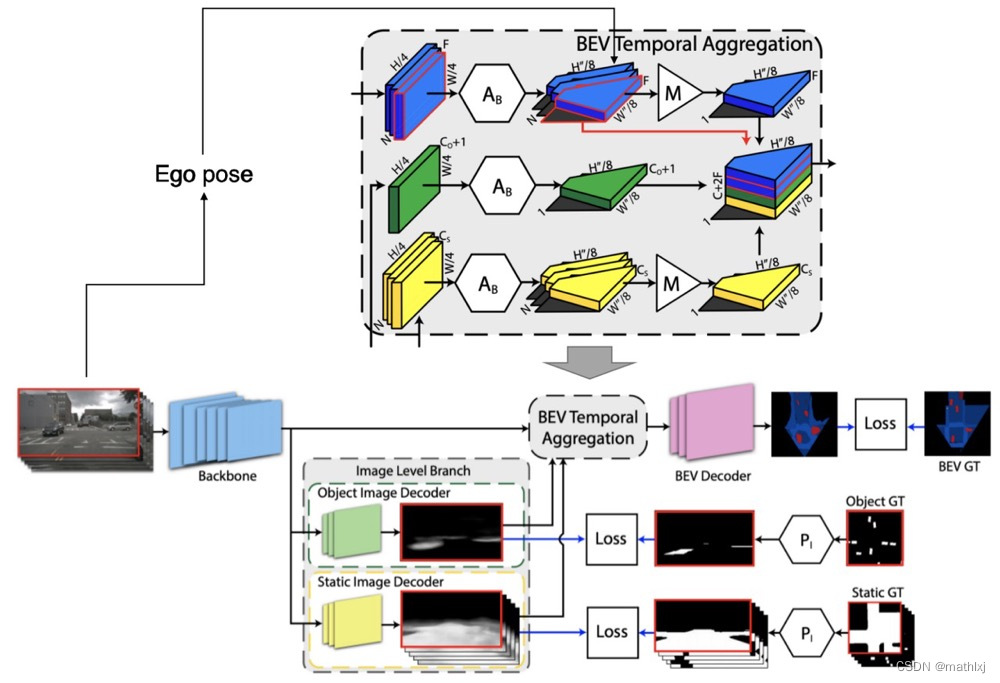
-
输入: N × H × W × 3 N\times H\times W \times 3 N×H×W×3,输出 1 × H ′ × W ′ × C 1\times H'\times W' \times C 1×H′×W′×C,C为静态目标(HD map)类别+动态目标类别+1个背景类别
-
object image decoder:仅对当前一帧进行分割;static image decoder 对输入的所以帧分割。两者皆输出heatmap
-
Temporal Aggregation
- Temporal warping: 已知相机的内参和外参(车辆的运动通过vehicles’ odometry pipeline获取,例如vSLAM),将相机平面变换到ego为参照的BEV空间,假设地面上平的
- symmetric aggregation:the object heatmap, the aggregated static heatmap, and the aggregated image features聚合。
-
BEV Decoder

GKT(arvix 22.06)
Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer
- paper,github待更新,3090 GPU上的72.3 FPS/2080ti GPU上的45.6 FPS
- 输入:多摄像头图像
- 输出:语义分割
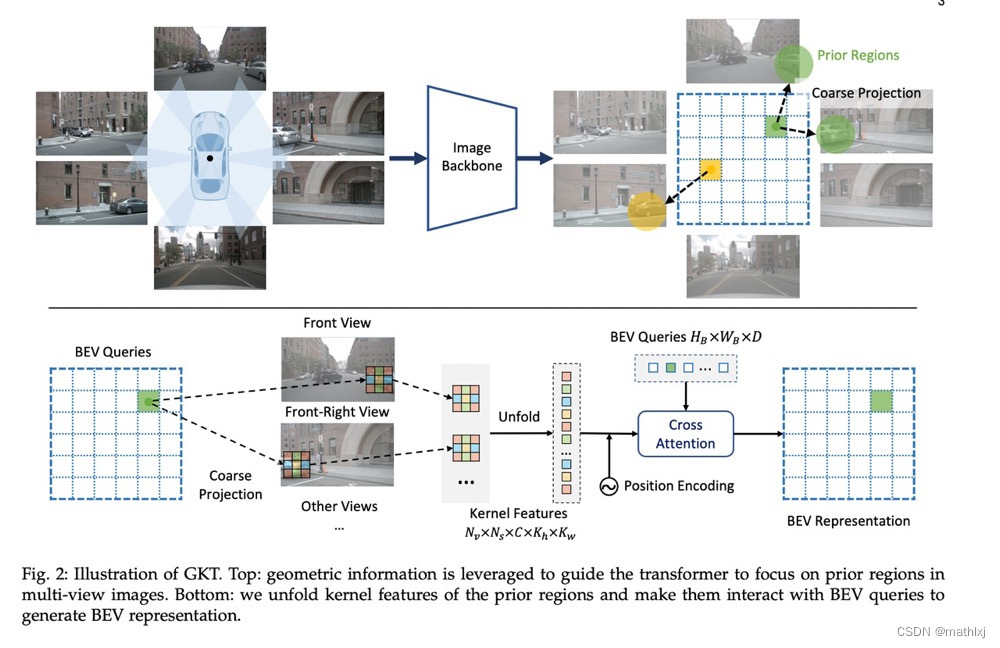
三、仅摄像头X语义分割(Tranformers)
PYVA: Projecting Your View Attentively (CVPR 2021)
Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation
-
paper,github,35 FPS
-
输入:单张摄像头前向图
-
输出:road layout estimation and vehicle occupancy estimation
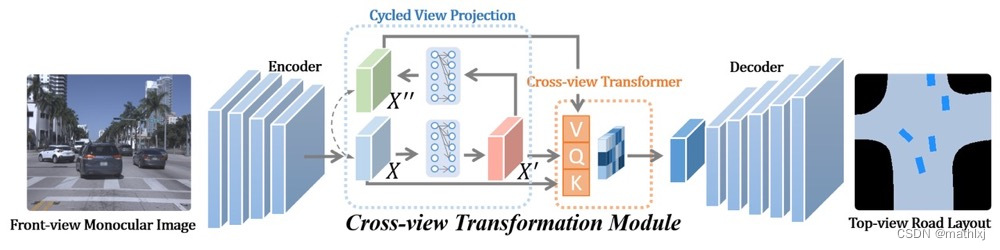
-
a cross-view transformation module:
- Cycled View Projection (CVP):使用MLP将前向相机的feature( X X X)映射到BEV视角( X ′ X' X′),但这种方法太多navie,提出cycled self-supervision scheme将BEV视角的feature( X ′ X' X′)用MLP映射回前向相机视角( X ′ ′ X'' X′′),使用 L 1 L_1 L1 loss做自监督训练。
- Cross-View Transformer (CVT):目的是使的 X ′ X' X′和 X X X加强关联,同时利用 X ′ ′ X'' X′′的信息。
K= X X X,Q= X ’ X’ X’,V= X ′ ′ X'' X′′,但不是用transformer那一套,而是计算 X ′ X' X′和 X X X的相关矩阵,根据相关矩阵提取每一行中最大的相关性组成的矩阵W 和 X ′ ′ X'' X′′最重要的信息 T T T
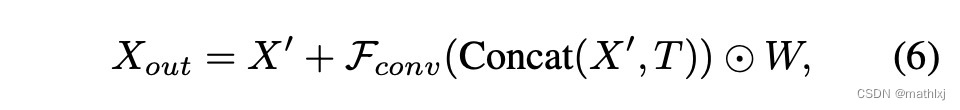
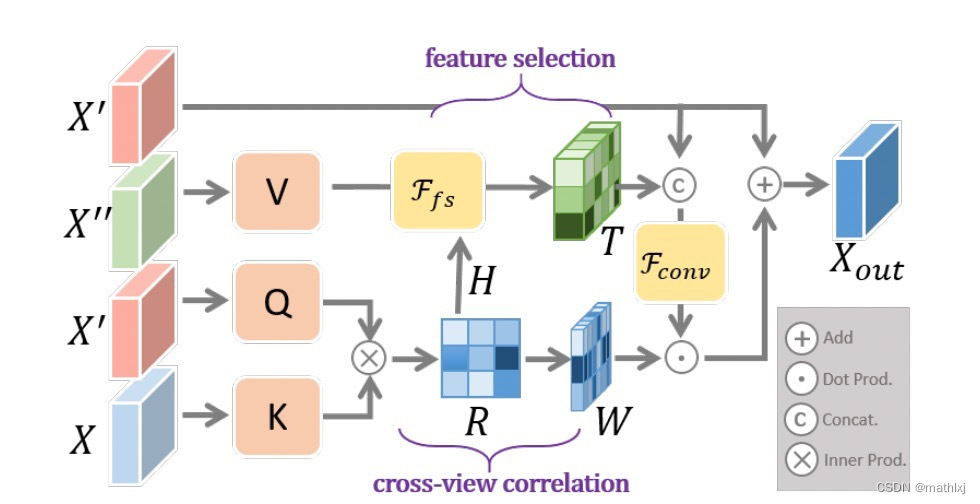
-
如果将 X ′ ′ X'' X′′和 X X X看作同一种特征表达,该方法更类似于cross-attention
-
损失函数:对抗损失
BEVFormer (CVPR 2022 Workshop)
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
-
paper,github,中文blog,测速V100上,R101-DCN,input size 900X1600,大约2FPS
-
输入:多视角相机图像
-
输出:语义分割/3D目标检测
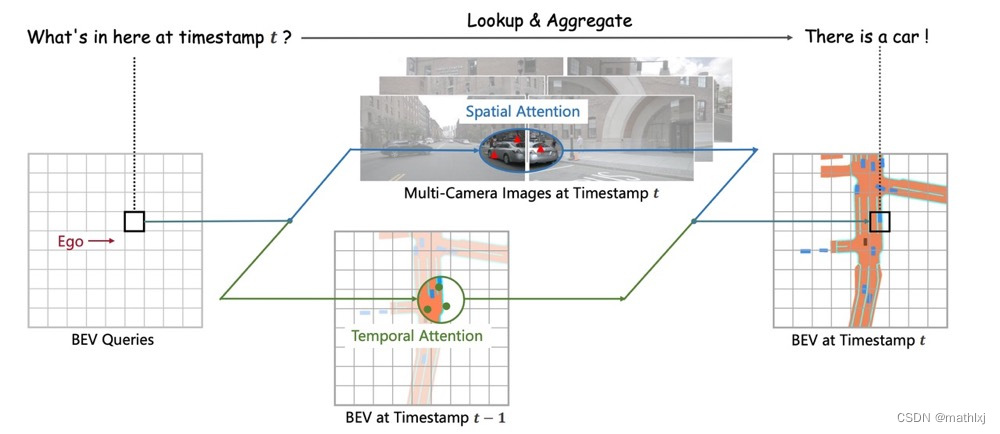
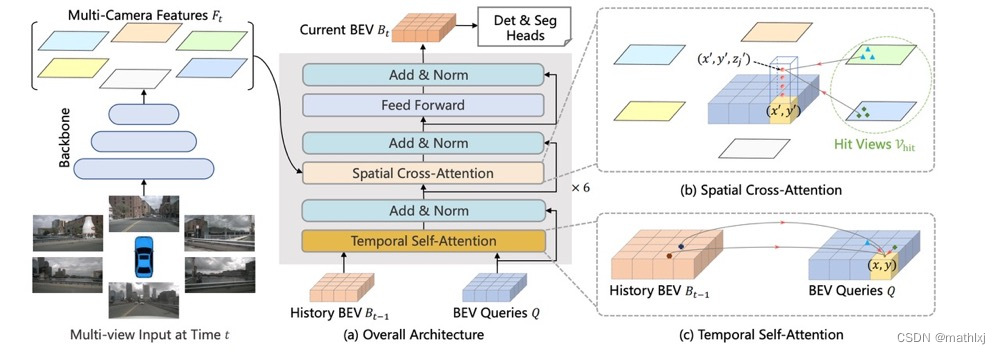
-
使用Transformer在BEV空间下进行时空信息融合,通过生成显式的BEV特征,用来融合时序信息或者来自其他模态的特征,并且能够同时支撑更多的感知任务
-
定义BEV queries:BEV queries 每个位于(x, y)位置的query都仅负责表征其对应的小范围区域。BEV queries 通过对spatial space 和 tempoal space 轮番查询从而能够将时空信息聚合在BEV query特征中。最终我们将BEV queries 提取的到的特征视为BEV 特征,该BEV特征能够支持包括3D 目标检测和地图语义分割在内的多种自动驾驶感知任务。
-
Spatial Cross-Attention:使用了一种基于deformable attention 的稀疏注意力机制时每个BEV query之和部分图像区域进行交互。 对于每个位于(x, y)位置的BEV特征,我们可以计算其对应现实世界的坐标x’,y’。 然后我们将BEV query进行lift 操作,获取在z轴上的多个3D points。 有了3D points, 就能够通过相机内外参获取3D points 在view 平面上的投影点。受到相机参数的限制,每个BEV query 一般只会在1-2个view上有有效的投影点。基于Deformable Attention, 我们以这些投影点作为参考点,在周围进行特征采样,BEV query使用加权的采样特征进行更新,从而完成了spatial 空间的特征聚合。
-
Temporal Self-Attention:从经典的RNN网络获得启发,我们将BEV 特征视为类似能够传递序列信息的memory。对于当前时刻位于(x, y)出的BEV query, 它表征的物体可能静态或者动态,但是我们知道它表征的物体在上一时刻会出现在(x, y)周围一定范围内,因此我们再次利用deformable attention 来以(x, y)作为参考点进行特征采样
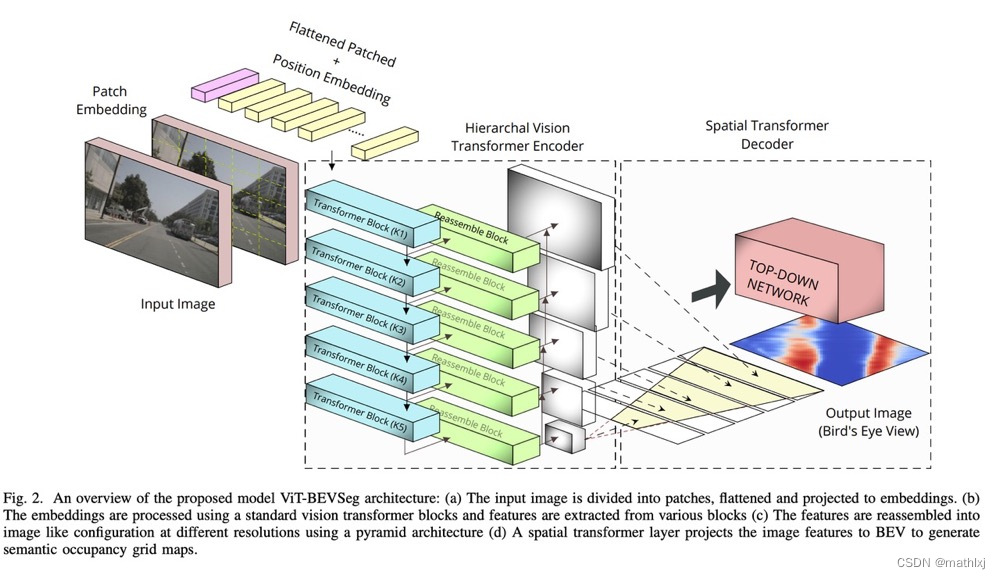
ViT-BEVSeg (arxiv 2205)
ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation
- paper,github待更新,
- 输入:单摄像头
- 输出:语义分割
使用vision transformers (ViT)作为backbone来生成BEV maps

四、3D目标检测等其它任务
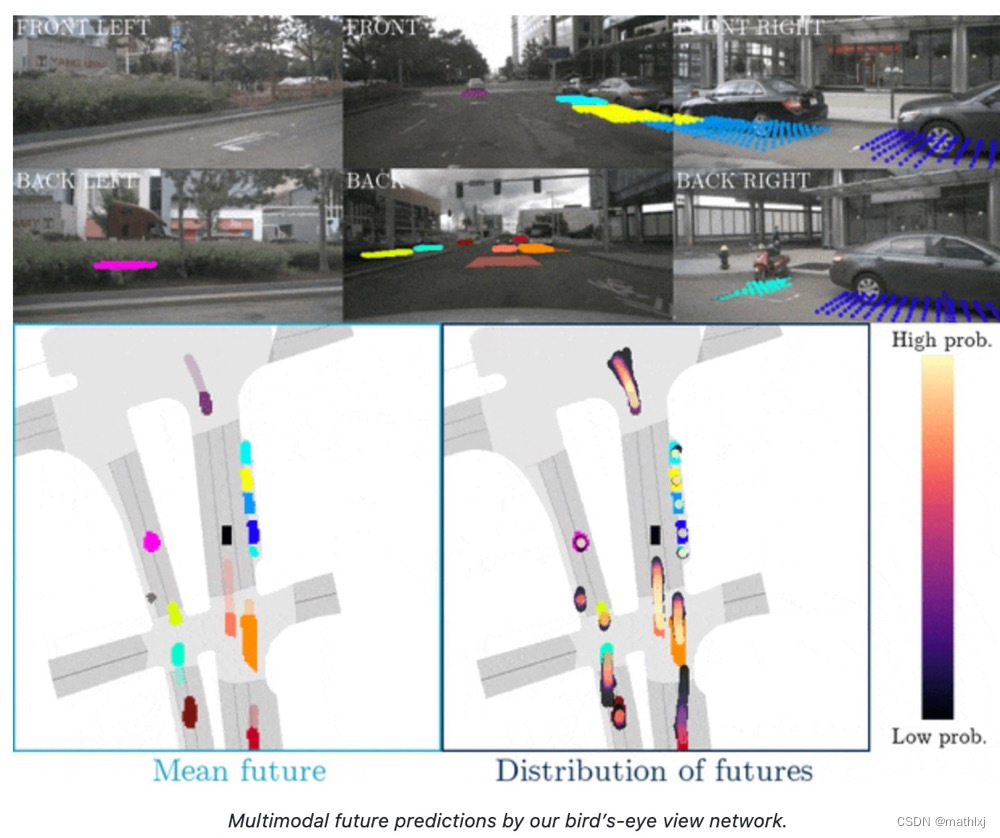
FIERY (ICCV 2021)
Predicting the Future from Monocular Cameras in Bird’s-Eye View
- paper,github,主页
- 输入:6个角度相机图像
- 输出:分割+交通参与者行为预测(十字路口、超车、U-turn)
-
对交通参与者进行轨迹预测
- 十字路口:continuing straight, turning left, turning right, changing lane
- 超车,对于静态车
- U-turn
-
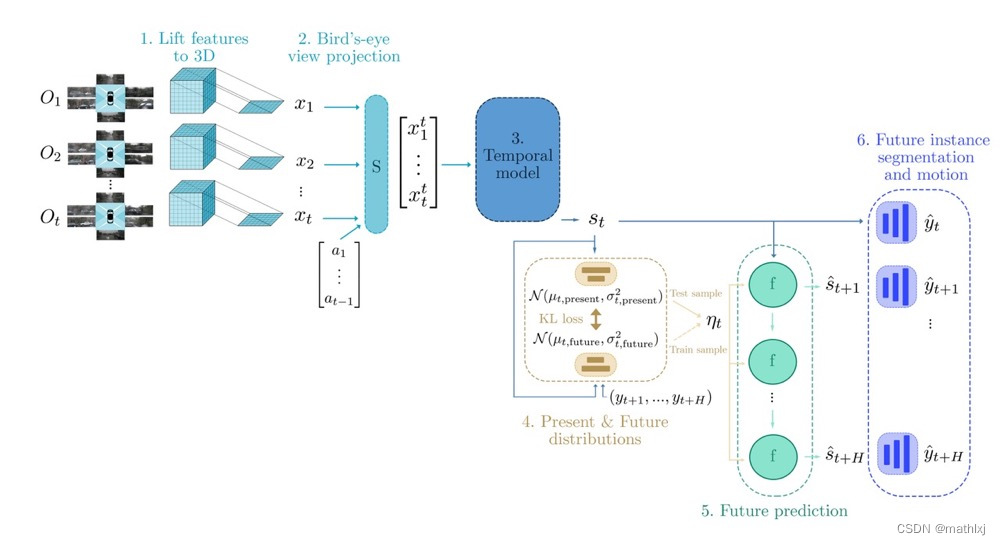
Pipeline
- 在过去的时间{1, 2, …,t},将图像的2D输入提升到3D,按照等间距(步长为1m)设置深度的方法,结合相机参数得到深度的概率分布
- 将其投影到BEV视角
- Temporal model通过3D卷积,学习一个时空状态s_t
- 分两个预测任务:当前状态和未来的状态,均由高斯分布的参数表达。
- 未来预测模型是一个卷积GRU网络,将当前状态 st 和训练中未来分布 F 或当前分布 P 采样的潜代码 ηt 作为输入,进行推理,递归地预测未来状态 (s(t+1,…,s)t+H)。
- Decoder : 状态被解码为BEV未来实例分割和未来运动(yˆt,…,yˆt+H)。与真实未来标签(yt+1 , …, yt+H )进行比较调整网络参数。y包含centerness, offset, segmentation, and flow.

DETR3D (CoRL 2021)
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
- paper,github,无测速
- 输入:多相机图像
- 输出:3D检测框
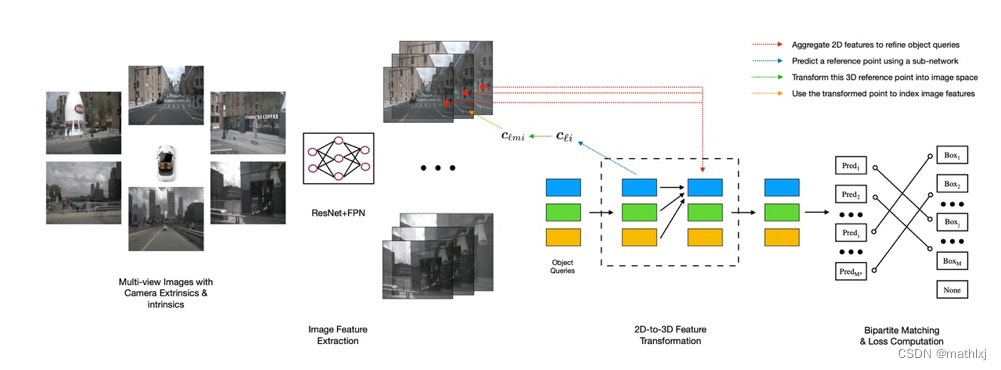

- 将DETR用于3D目标框检测
- 无nms.
- 2D-to-3D Feature Transformation:
- object queries是类似DETR那样,即先随机生成M个bounding box,类似先生成一堆anchor box
- (蓝线)然后通过一个子网络,来对query预测一个三维空间中的参考点(实际上就是3D bbox的中心)
- (绿线)利用相机参数,将这个3D参考点反投影回图像中,找到其在原始图像中对应的位置。
- (黄线)从图像中的位置出发,找到其在每个layer中对应的特征映射中的部分
- (红线)利用多头注意力机制,将找出的特征映射部分对queries进行refine
- (黑色虚线框之后)得到新的queries之后,再通过两个子网络分别预测bounding box和类别
PersFormer (ECCV 2022 Oral)
PersFormer: a New Baseline for 3D Laneline Detection
- paper,github,
- 输入:单摄像头
- 输出:3D车道线检测
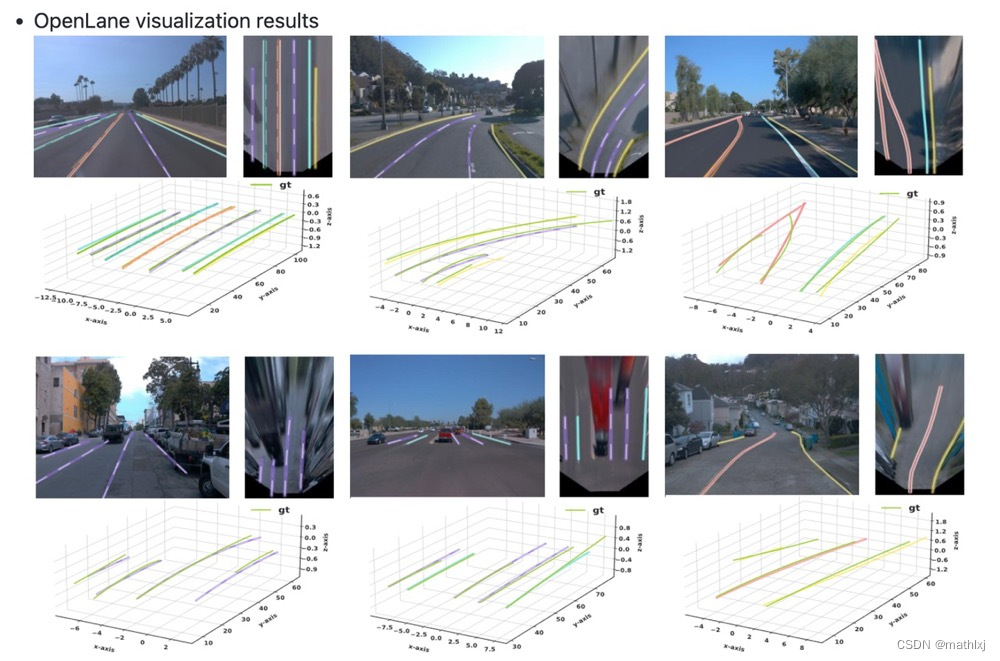
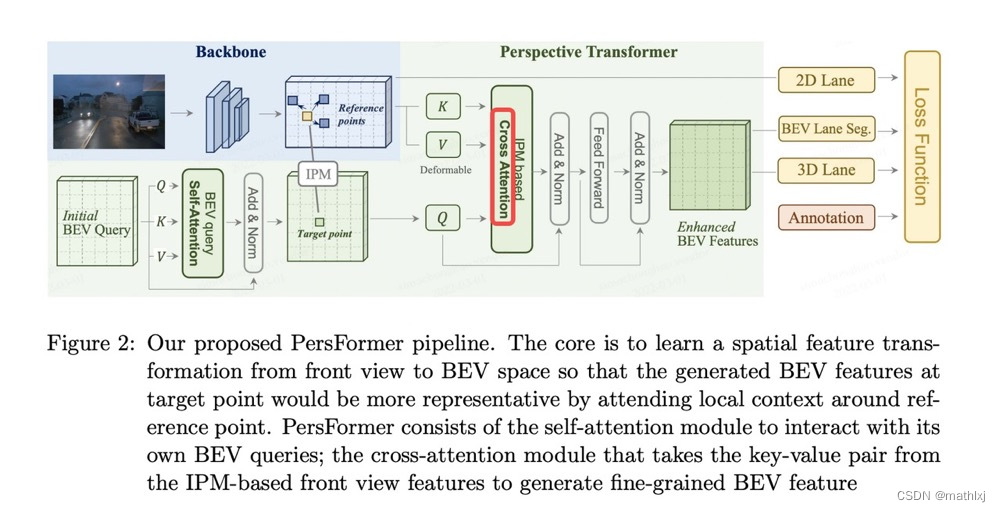
核心Proposed Perspective Transformer:
- 假设地面上平的,并且相机参数可知(IPM可用)
- 给出前向相机视角中的一个点,使用IPM将映射到BEV空间
- 给定一个BEV空间中的query点(target point),将其映射回前向相机视角,并找到其附近的一些reference points。
五、多模态融合
HDMapNET( ICRA 2022)
HDMapNet: An Online HD Map Construction and Evaluation Framework
- paper,github,主页,知乎
- 输入:多摄像头or/and 雷达
- 输出:HD语义地图分割

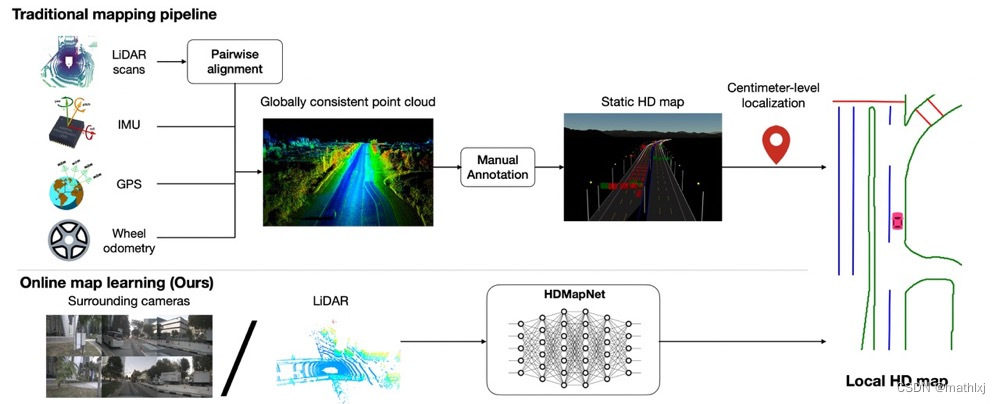
主要解决两个问题:道路预测向量化和从相机前视图到鸟瞰图的视角转换。
- 向量化(Vectorization)是指我们最终得到的地图信息不是图片形式的,而是用点、线、框等几何形状表示的,这种表示在地图的下游任务使用、存储等方面都有巨大优势。HDMapNet的decoder输出3个分支:语义分割semantic segmentation、实例分割instance embedding、方向预测direction prediction。然后通过后处理的手段来将这些信息处理成向量化的道路表达。
- 从相机前视图到鸟瞰图视角转换:参考VPN,直接全连接去学变换矩阵
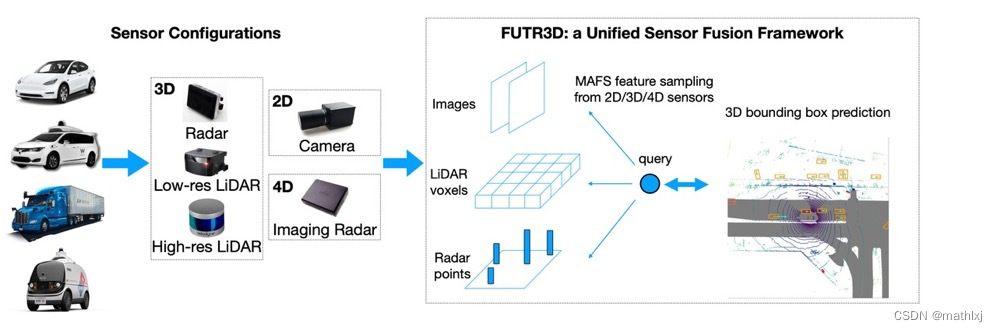
FUTR3D (arxiv 2022.03)
- paper,无代码
- 输入:相机,激光雷达,相机+激光雷达,相机+雷达
- 输出:3D目标检测
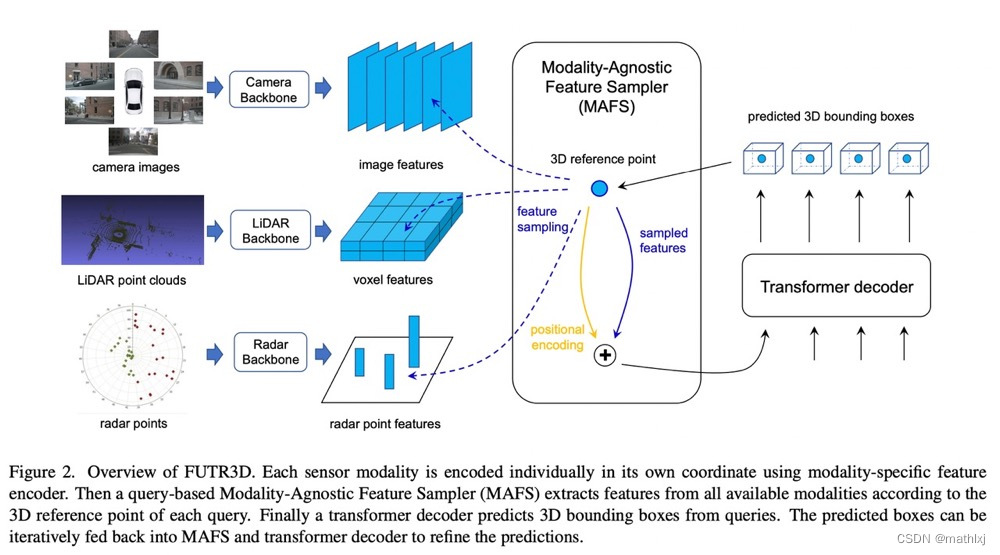
- Pipeline
- 每个模态单独通过backbone提取特征
- MAFS根据query的初始位置,从所有模态在采样和聚合特征
- decoder基于聚合的特征,精修检测框
- 预测和gt检测框而二部图匹配,计算loss
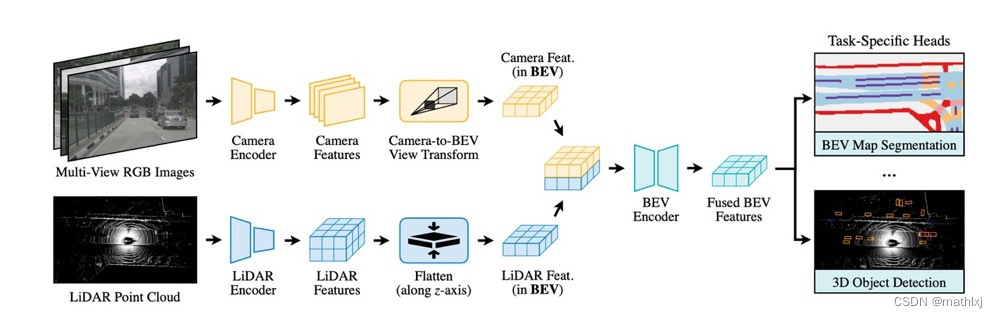
BEVFusion (arxiv 2022.05)
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
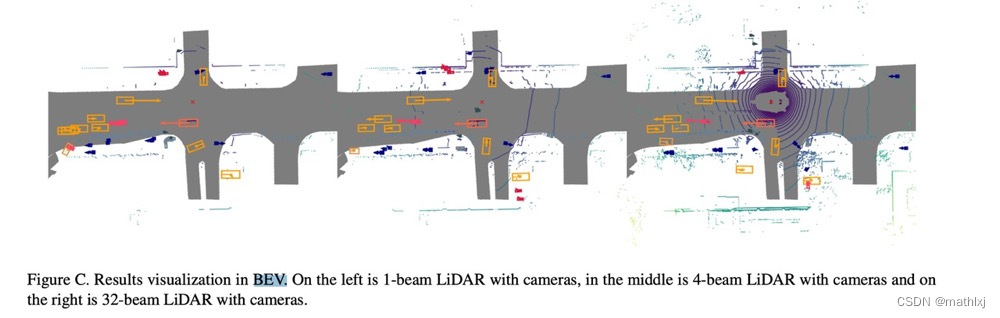
BEVFusion ranks first on nuScenes among all solutions.
- paper,github,video
- 输入: 3d点云+camera融合/或单独
- 输出:3D目标检测/BEV map segmentation.
核心:在BEVrepresentation space里融合多模态的特征表达
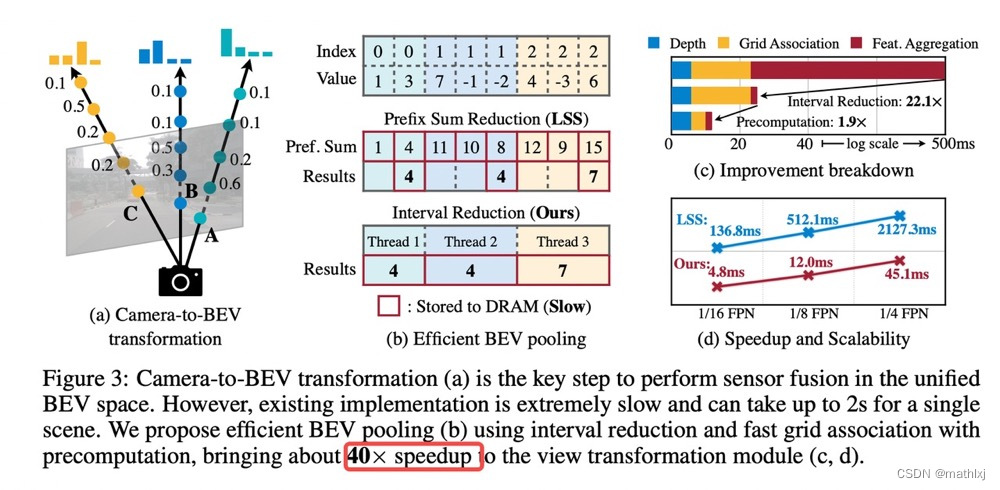
核心:对BEV pooling的操作做了加速,从500ms 缩减到 12ms

六、业界
Tesla’s Approach
参考:blog1 blog2 video
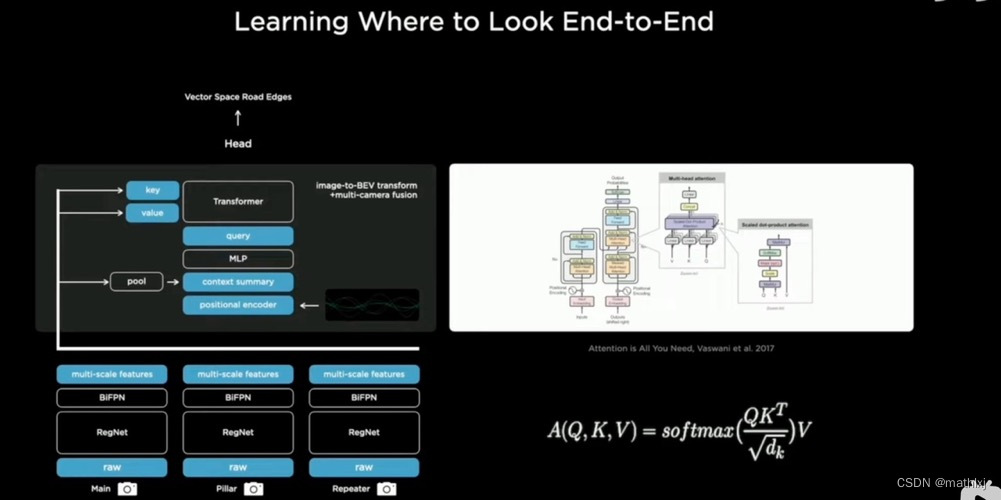
- 首先raw image进来;
- 通过rectify layer, 把图片转到virtual camera下
- 通过一个RegNet, 其实是一个ResNet的形式,然后给出不同尺度下的features.
- 通过BiFPN, 把不同尺度下的features, 从上到下,又从下到上,来来回回对不同尺度下的features 做一个融合。双向FPN
- 通过transformer的形式投到BEV视角下,得到一个俯视的feature
- 给到feature queue里面,加入时序信号,video module 实际是对时序信号的一次融合。之后得到一个多camera 融合并加入了时序信号的features
- 最后给到不同的detection head 里面去做检测;
Reference
- Monocular Bird’s-Eye-View Semantic Segmentation for Autonomous Driving
- Monocular BEV Perception with Transformers in Autonomous Driving
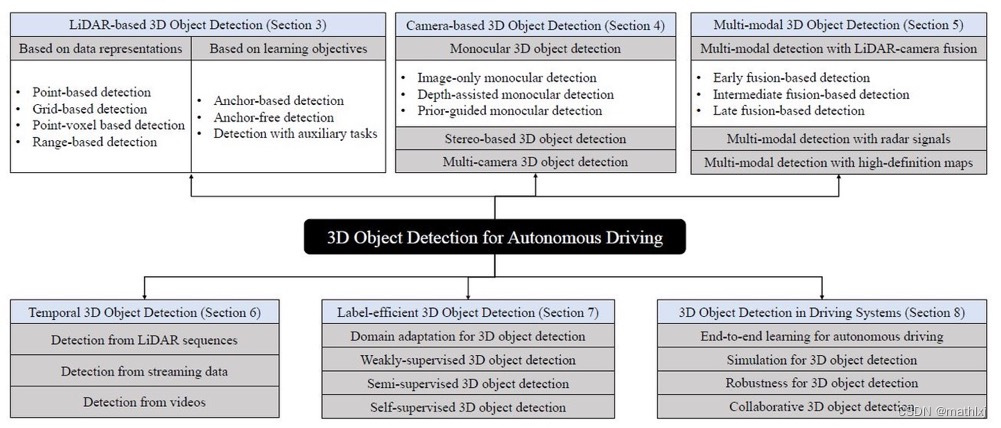
- 一个很全的3D目标检测in AD的综述:github paper
3D Object Detection for Autonomous Driving: A Review and New Outlooks
这篇关于BEV(Bird’s-eye-view)三部曲之二:方法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






