本文主要是介绍深度学习中所使用的优化方法综述,包括SGD,Adagrad,Momentum,Adadelta等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式可以去认真啃论文了。话不多说,直接上图!!!
本文转载自:https://zhuanlan.zhihu.com/p/22252270

SGD
SGD英文全称为mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具体区别就不细说了。现在的SGD一般都指mini-batch gradient descent。
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
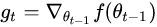
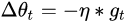

Momentum
momentum是模拟物理里动量的概念,积累之前的动量来替代真正的梯度。公式如下:

Nesterov
nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。将上一节中的公式展开可得:

momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)
其实,momentum项和nesterov项都是为了使梯度更新更加灵活,对不同情况有针对性。但是,人工设置一些学习率总还是有些生硬,接下来介绍几种自适应学习率的方法


特点:
- 训练初中期,加速效果不错,很快
- 训练后期,反复在局部最小值附近抖动


特点:
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率
也适用于大多非凸优化 - 适用于大数据集和高维空间
Adamax
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。公式上的变化如下:

经验之谈
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
最后展示两张可厉害的图,一切尽在图中啊!

损失平面等高线

在鞍点处的比较
引用
[1]Adagrad
[2]RMSprop[Lecture 6e]
[3]Adadelta
[4]Adam
[5]Nadam
[6]On the importance of initialization and momentum in deep learning
[7]Keras中文文档
[8]Alec Radford
[9]An overview of gradient descent optimization algorithms
[10]Gradient Descent Only Converges to Minimizers
[11] Deep Learning:Nature
这篇关于深度学习中所使用的优化方法综述,包括SGD,Adagrad,Momentum,Adadelta等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




