adadelta专题

PyTorch的十个优化器(SGD,ASGD,Rprop,Adagrad,Adadelta,RMSprop,Adam(AMSGrad),Adamax,SparseAdam,LBFGS)
本文截取自《PyTorch 模型训练实用教程》,获取全文pdf请点击:https://github.com/tensor-yu/PyTorch_Tutorial 文章目录 1 torch.optim.SGD 2 torch.optim.ASGD 3 torch.optim.Rprop 4 torch.optim.Adagrad 5 torch.optim.Adadelta 6 torch.op

【深度学习笔记】7_7 AdaDelta算法
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 7.7 AdaDelta算法 除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进 [1]。有意思的是,AdaDelta算法没有学习率这一超参数。 Adadelta是一种自适应学习率的方法,用于神经网络的训练过程中。

自适应学习率调整:AdaDelta
自适应学习率调整:AdaDelta Reference:ADADELTA: An Adaptive Learning Rate Method 链接: http://www.cnblogs.com/neopenx/p/4768388.html 超参数 超参数(Hyper-Parameter)是困扰神经网络训练的问题之一,因为这些参数不可通过常规方法学习获得。 神经网络经典五大
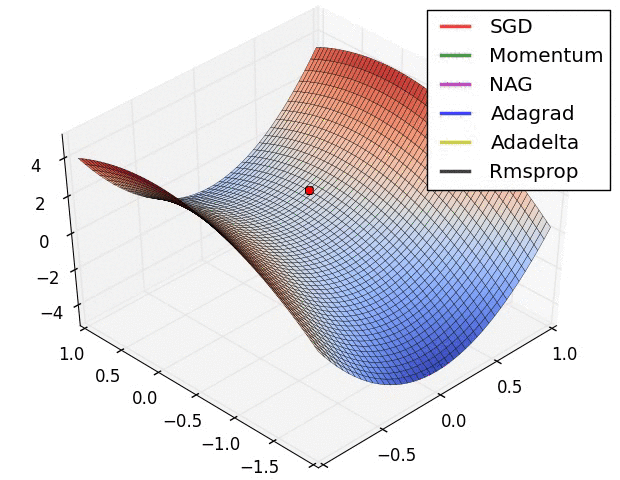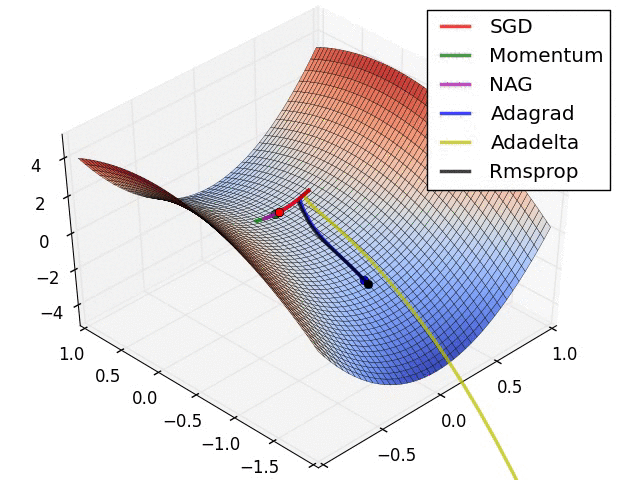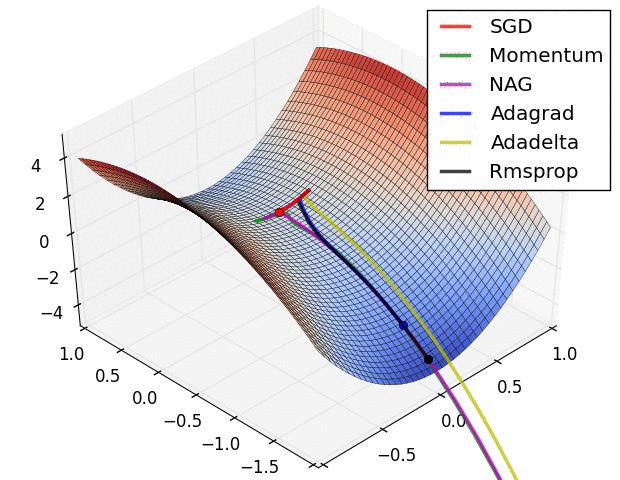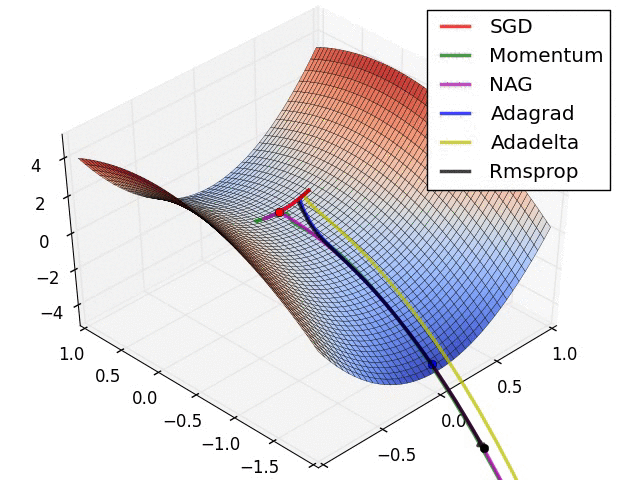
自适应学习速率SGD优化方法比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam) 前言 (标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。 SGD 此处的SGD指mini-batch gradient descent,关于batch gradient desc

theano中对adadelta的实现
最开始不太会写,后来发现自己给写错了。先给出adadelta的伪代码 egs(t+1) = rho*egs(t) + (1-rho)*grad(t+1)**2 delta(t+1) =sqrt(exs(t)**2 + epsilon)/sqrt(egs(t+1)**2 + epsilon)*(-grad(t+1)) exs(t+1) = rho*esx(t) + (1-rho)*delta(
![[work] 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)](https://pic1.zhimg.com/80/4a3b4a39ab8e5c556359147b882b4788_hd.jpg)
[work] 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
前言 (标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。 SGD 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent
【深度学习实验】网络优化与正则化(二):基于自适应学习率的优化算法详解:Adagrad、Adadelta、RMSprop
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 随机梯度下降SGD算法a. PyTorch中的SGD优化器b. 使用SGD优化器的前馈神经网络 2.随机梯度下降的改进方法a. 学习率调整b. 梯度估计修正 3. 梯度估计修正:动量法Momentum4. 自适应学习率Adagrad算法Adadelta算法RMSprop算法算法测试 5.

深度学习中所使用的优化方法综述,包括SGD,Adagrad,Momentum,Adadelta等
前言: 本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式可以去认真啃论文了。话不多说,直接上图!!! 本文转载自:https://zhuanlan.zhihu.com/p/22252270 SGD SGD英文全称为mini-batch gradient descent,关于batch gradient descent, stochastic gradi

SGD BGD Adadelta等优化算法比较
在腾讯的笔试题中,作者遇到了这样一道题: 下面哪种方法对超参数不敏感: 1、SGD2、BGD3、Adadelta4、Momentum神经网络经典五大超参数:学习率(Learning Rate)、权值初始化(Weight Initialization)、网络层数(Layers)单层神经元数(Units)、正则惩罚项(Regularizer|Normalization)显然在这里超参数指的是事先指

Tensorflow入门教程(三十三)优化器算法简介(Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
# #作者:韦访 #博客:https://blog.csdn.net/rookie_wei #微信:1007895847 #添加微信的备注一下是CSDN的 #欢迎大家一起学习 # ------韦访 20181227 1、概述 上一讲中,我们发现,虽然都是梯度下降法,但是不同算法之间还是有区别的,所以,这一讲,我们就来看看它们有什么不同。 2、梯度下降常用的三种方法 为了博客的完整性,这里