本文主要是介绍基于相关系数法的近红外光谱波长选择用于玉米数据集的含量检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在近红外光谱数据分析建模过程中,特征选择是其中关键的一步。特征选择的原因是全部样本信息(全波长)中存在冗余信息,使得有些有效信息被抵消同时也无法突出有用的信息,这样建立的分析模型准确度和可靠性不高且计算量较大,特征选择就是最大限度的筛选出光谱数据中的有效信息,使得筛选出来的这些信息可以代表全部的样本信息,这样筛选出来的就是特征波长。本文主要介绍采用相关系数法筛选玉米数据集的特征波长,并与全波长建模结果进行对比。
相关系数法

数据来源
对网上公开的玉米数据集进行分析,下载网址可参见博客玉米数据集
数据集中包含有 3台不同的光谱仪测量得到的近红外光谱,每台仪器测量的光谱数据波长范围为1100~2498nm,波长间隔为 2nm,共 700 个波长点。

图1 玉米数据光谱
基于PLS的的玉米数据集含量检测
clc
clearload('corn_m51.mat')
X; %光谱
y; %含量% figure
% plot(1101:2:2500, X(:, 1:length(X)));
% xlabel('Wavelength/nm','FontName','Times New Roman','FontSize',8);
% ylabel('Absorbance','FontName','Times New Roman','FontSize',8);
% set(gca,'FontName','Times New Roman','FontSize',8);% X = nirSNV(X);ratio = 0.7; % 训练集占70%
[mx, nx] = size(X);
mtrain = ceil(mx * ratio);
mtest = mx - mtrain;
[Xtrain, Xtest, Ytrain, Ytest] = ks(X,y,ceil(mx*ratio));[Rc,RMSEC,beta,yc] = fitaaa(Xtrain, Ytrain);
[Rp,RMSEP,yp] = fitbbb(Xtest,Ytest,beta);以上,Rc,Rp分别为校正相关系数和预测相关系数;RMSEC,RMSEP分别为校正均方根误差和校正均方根误差。
结果如下
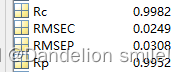
基于相关系数法的近红外光谱含量检测模型
运用相关系数法筛选光谱值和含量值之间相关性较大的样本,建立PLS含量检测模型。
代码如下:
load('corn_m51.mat')
X; %光谱
y; %含量% figure
% plot(1101:2:2500, X(:, 1:length(X)));
% xlabel('Wavelength/nm','FontName','Times New Roman','FontSize',8);
% ylabel('Absorbance','FontName','Times New Roman','FontSize',8);
% set(gca,'FontName','Times New Roman','FontSize',8);% X = nirSNV(X);ratio = 0.7; % 训练集占70%
[mx, nx] = size(X);
mtrain = ceil(mx * ratio);
mtest = mx - mtrain;
[Xtrain, Xtest, Ytrain, Ytest] = ks(X,y,ceil(mx*ratio));%% 采用相关系数选择特征波长再建模
rt = CA(Xtrain, Ytrain);
max_rt = max(rt);
min_rt = min(rt);[Rc_,RMSEC_,Rp_,RMSEP_,selectedBands] = CA_get_i(Xtrain, Ytrain, Xtest, Ytest,min_rt, max_rt, 0.001);以上,Rc_,Rp_分别为校正相关系数和预测相关系数;RMSEC_,RMSEP_分别为校正均方根误差和校正均方根误差。
结果如下:

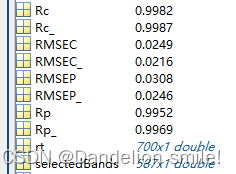
选用PLS建模和先进行相关系数法波长选择再PLS建模的结果对比
总结
本文选用的模型评价指标为校正相关系数(Rc,Rc_)、预测相关性数(Rp、Rp_)、校正均方根误差(RMSCE,RMSEC_)和预测均方根误差(RMSEP,RMSEP_)。相关系数用于反映变量直接相关系数密切程度的统计指标。RMSEP用于衡量预测值与真实值之间的偏差。RMSEP值越小,相关系数越大,则模型的预测能力越好。
相比于直接选用全波长进行建模,相关系数法选用波长后建模的Rp从0.9952上升到0.9969,RMSEP从0.0308下降到0.0246,选择的变量从全波长的700减少到587。说明相关系数法可有效选择光谱与含量之间相关性更好的样本,减少冗余变量,提高模型的精度。
完整代码可从GitHubhttps://github.com/cainnyk/CSDV_corPLS下载
参考文献【1】倪超,李振业,张雄,赵岭,朱婷婷,蒋雪松.基于短波近红外高光谱和深度学习的籽棉地膜分选算法[J].农业机械学报,2019,50(12):170-179.
这篇关于基于相关系数法的近红外光谱波长选择用于玉米数据集的含量检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





