本文主要是介绍【CVPR2019】Unsupervised Deep Tracking无监督目标跟踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
UDT是中科大、腾讯AI lab和上交的研究者提出的无监督目标跟踪算法。仔细阅读过这篇文章之后,写下一篇paper reading加深印象。
论文标题:Unsupervised Deep Tracking
论文地址:https://arxiv.org/pdf/1904.01828.pdf
Github(pytorch):https://github.com/594422814/UDT_pytorch
无监督目标跟踪的“无监督”体现在:无需标注的视频数据训练。当然,首帧(模板帧)是需要标注的,这是目标跟踪的底线-_-
论文最大的亮点是提出了“一致性损失”(consistency loss),这也是UDT能够实现无监督跟踪的根本。
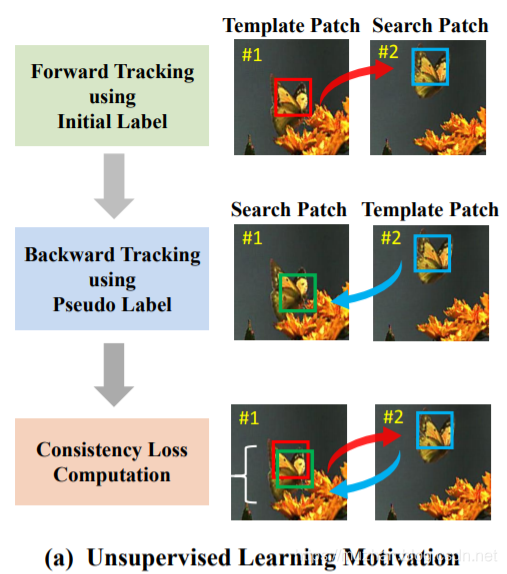
我们先观察图(a),#1表示的是模板帧,模板帧的红框是Ground Truth(就是label的意思)。为什么无监督tracking还有GT呢?前面已经说了,首帧标注是tracking的底线-_-,只有把目标框出来,模型才能进行“跟踪”。
第一步,根据模板帧#1推测出下(另)一帧#2的bounding box,一开始可能效果很差,但是我们不急,继续进行第二步;
第二步,把#2的bounding box当作模板帧,同时把#1当作需要推测的帧。即用#2反推#1;
第三步,#2反推出的#1的bounding box与#1的GT作比较,它俩必然有差别,可以根据这一差别构建一个损失函数,这个损失函数就是一致性损失;
以上就是UDT最大的创新点,使用反推构建一致性损失。这一操作在GAN模型中经常使用,CycleGAN,AugGAN,MUNIT等图像转换网络中都会构建“一致性损失”来优化。而将这一trick用到tracking领域,确实让人眼前一亮。
看一下细节实现:
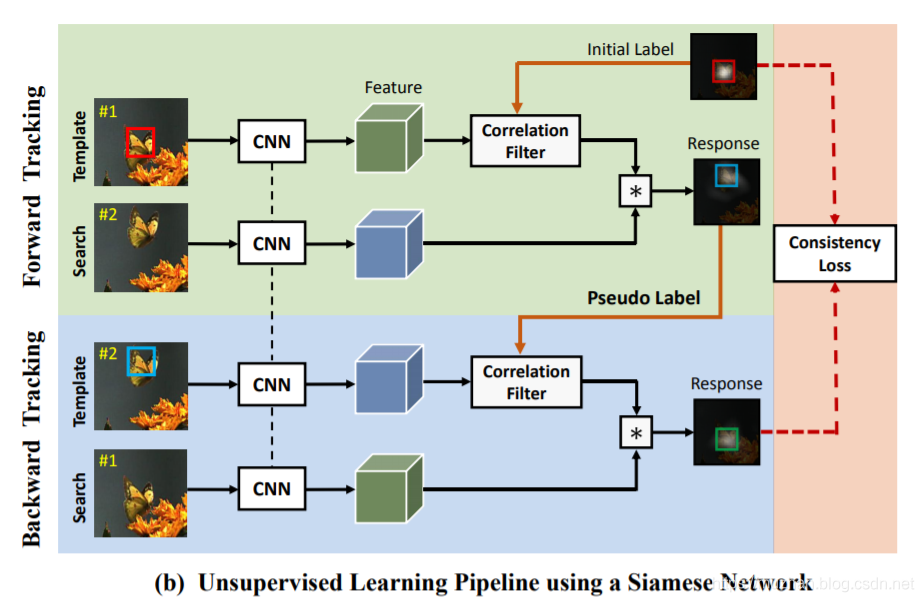
UDT的主体仍然采用经典的孪生网络(Siamese Network)。如图(b)所示,将训练过程分为两个部分,一个“前向跟踪”,一个“反向跟踪”。采用的思想与本文前面介绍的一致,在前向跟踪的过程中,使用GT模板帧对未来帧进行预测;在反向跟踪过程中,使用被推理出“伪标签”的未来帧作为模板帧来对GT模板帧进行预测。
结果
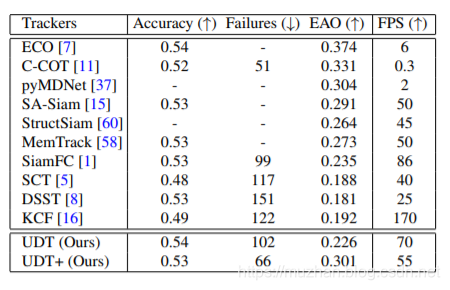
嗯,粗略瞄一下结果。无监督的UDT的准确率基本和第一代孪生跟踪网络SiamFC持平。感觉还是很promising的,毕竟视频单帧标注真的很费功夫。改日复现一下。
这篇关于【CVPR2019】Unsupervised Deep Tracking无监督目标跟踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)
