本文主要是介绍论文浅尝|《Automated Phrase Mining from Massive Text Corpora》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读
这是一篇发表于2018年的IEEE文章,论文题目为《Automated Phrase Mining from Massive Text Corpora》,意为从大量语料中自动挖掘短语。
选题背景
1. 短语挖掘任务:
- 在语料中自动提取高质量短语(科学术语和通用实体等),举例:information extraction/retrieval, taxonomy construction, and topic modeling
2. 目前大多数文本识别方法存在问题:
- 依赖于复杂、经过训练的语言分析器,因此在没有额外且成本高昂的改写的情况下,在新领域、新体裁的文本语料库上分析器的表现很可能很差。
- 目前的模型没有完全自动化的,都需要领域专家设计规则或事先标注。
因此,本文提出了一个新的自动短语挖掘的框架AutoPhrase,它适用于通用知识库支持的所有语言,可以在极大程度上节省人工,并在多个语料库上测试结果表现优秀。
基础概念
1.自动短语挖掘: 输入语料是特定语言和特定领域中任意长度的文本词序列;输出是质量降序排列的的短语列表。
2. 短语(phrase): 连续出现在文本中的一系列单词,与实体相比更加通用。
3. 短语质量: 一个单词序列成为一个完整语义单元的概率,满足以下要求:
- 流行性: 优质短语应该在给定的文档集合中以足够高的频率出现。
- 一致性: 由于偶然性,限定短语中标记的搭配发生的概率明显高于预期。
- 信息性: 如果一个短语表示一个特定的主题或概念,那么它就是信息性的。
- 完整性: 长频短语及其子序列可能都满足上述3个标准,当一个短语在某些给定的文档上下文中可以被解释为一个完整的语义时,它就被认为是完整的。(示例如下图:)

4. 基本原则: 词性标注指导的短语切分需要一组短语质量分数;先根据初始频率估计分数;然后,一旦特征值被纠正,我们重新估计分数。只有满足上述所有要求的短语才被视为质量短语。(示例如下图:)

算法
图1为AutoPhrase的工作流程:

1. 正向远程训练:利用现有的通用知识库(如Wikipedia、Freebase等)进行训练。
优点: 不用手动标注;有助于减少负面标签的噪声
第一阶段:建立短语候选集。 包含n-grams(阈值及n的值都可以自行设定)。给定候选集w1w2…wn,短语质量为:

- 上述式子的右侧是一个条件概率,其中前半部分表示的是这些词构成了短语;Q是短语质量评价器,其计算独立于词性标注。
- 标签池:
(1)把公共知识库(如维基百科)的高质量短语放在正向池中;
(2)将基于n-gram的候选短语中不匹配任何知识库的高质量短语的短语放在负向池中。
第二阶段:去除噪声
- 存在问题: 直接使用负向池训练分类器可能遗漏给定语料库中的高质量短语,因为它们可能不存在于知识库中。
- 解决方案: 使用一个集成分类器来平均独立训练的基本分类器的结果。
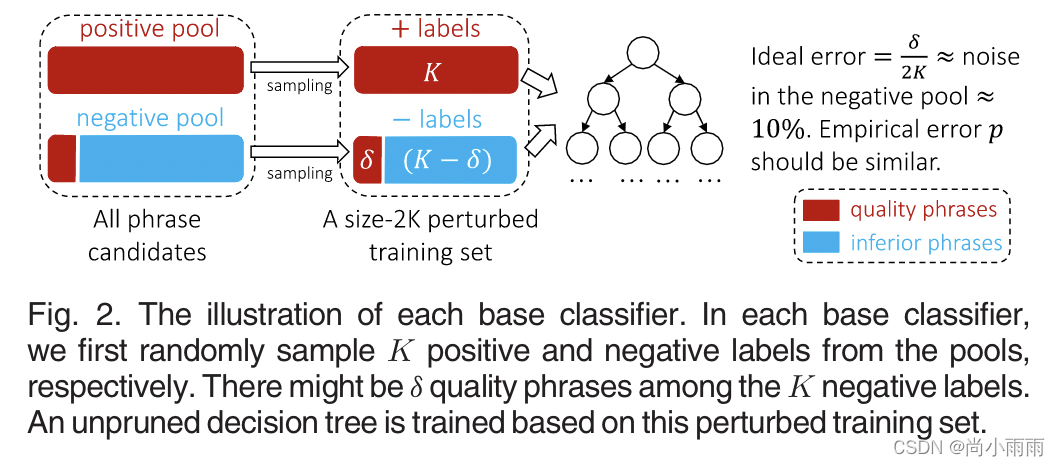
(1)对于每个基分类器,从正池和负池中分别随机抽取K个有替换项的候选短语,即总共2K个短语构成一个扰动训练集,因为一些(图中为δ)质量短语被错误标记了。
(2)在扰动数据集上构建了一个未经修剪的决策树分离所有短语来训练。当扰动训练集中没有两个正、负短语具有相同的特征值时,该决策树的训练精度就会达到100%。(由于δ是噪音,所以最理想的准确率是1-δ/2K(论文中δ/2K约等于10%,所以最佳准确率为90%,就是每个基分类器完全过拟合的情况下准确率是90%)
(3)随机森林中的决策树判断比例作为分数(投票比例)。
2. 利用词性信息进行短语分割:在文档集合中加入预先训练好的词性标注,帮助定位短语边界,提高性能。
- 原因: 在领域独立性上,没有语言知识,准确率会受限;而在准确率上,使用语言特征进行训练会对领域独立性产生影响。
- 过程: 先把语料库处理为带有词性的单词序列Ω=Ω1Ω2…Ωn;然后使用边界序列B将这个单词序列Ω划分为m份;并评估划分结果。
分词质量T:

- 词性分割模型: 使用最大似然估计进行计算。

实验设计
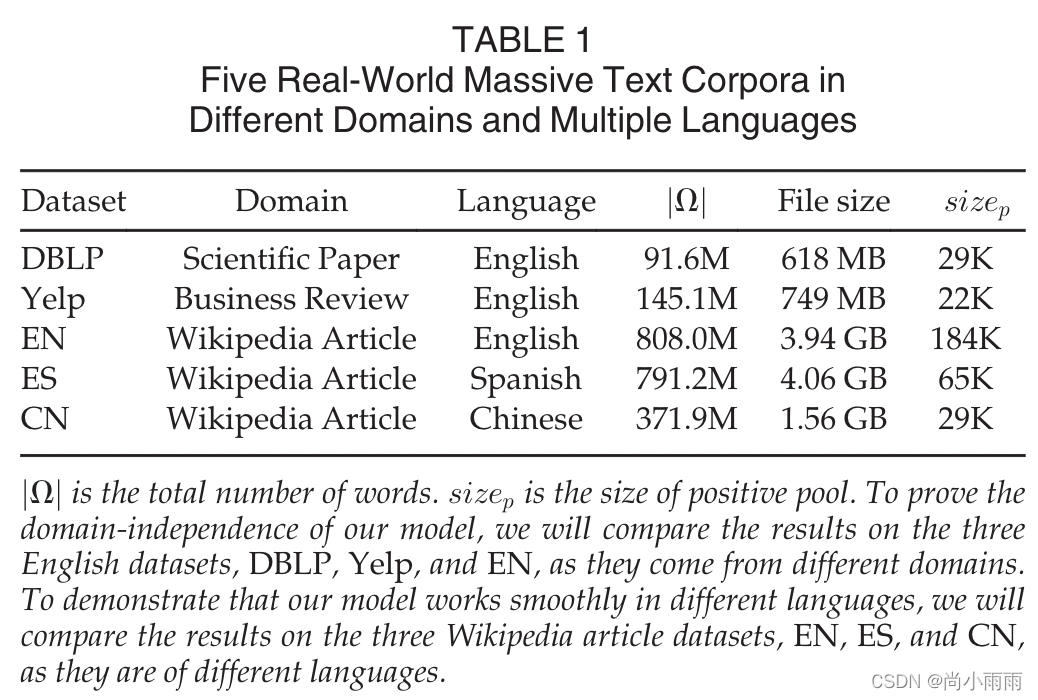
数据集
使用五个不同语言不同领域的数据集。
基线方法
使用三个方法与文章提出的AutoPhrase进行对比。
- SegPhrase / WrapSegPhrase:邀请领域专家预先标注300个质量短语。
- Parser-Based Phrase Extraction:包括TF-IDF(基于词频)和TextRank(基于无监督图)两种启发式排序算法。
- Pre-trained Chinese Segmentation Models:包括AnsjSeg和JiebaPSeg。
- 还引入了融合AutoPhrase和SegPhrase的AutoSegPhrase以验证词性标注的作用。
实验设置
- 参数设置: 出现频率设置为30;短语最大词数为6。
- 人工标注: 由人工判断短语抽取是否成功。在每个数据集随机抽取500个实验生成的短语交由三个人进行判断,有两票及以上赞成的即为高质量短语。
- 一致性: 五个数据集的类内相关性(ICC)均大于0.9。
- 评价指标: 精度(Precision)-召回(Recall)曲线。此外,曲线下面积(AUC)也被用作另一个质量评估手段。
结果
整体表现
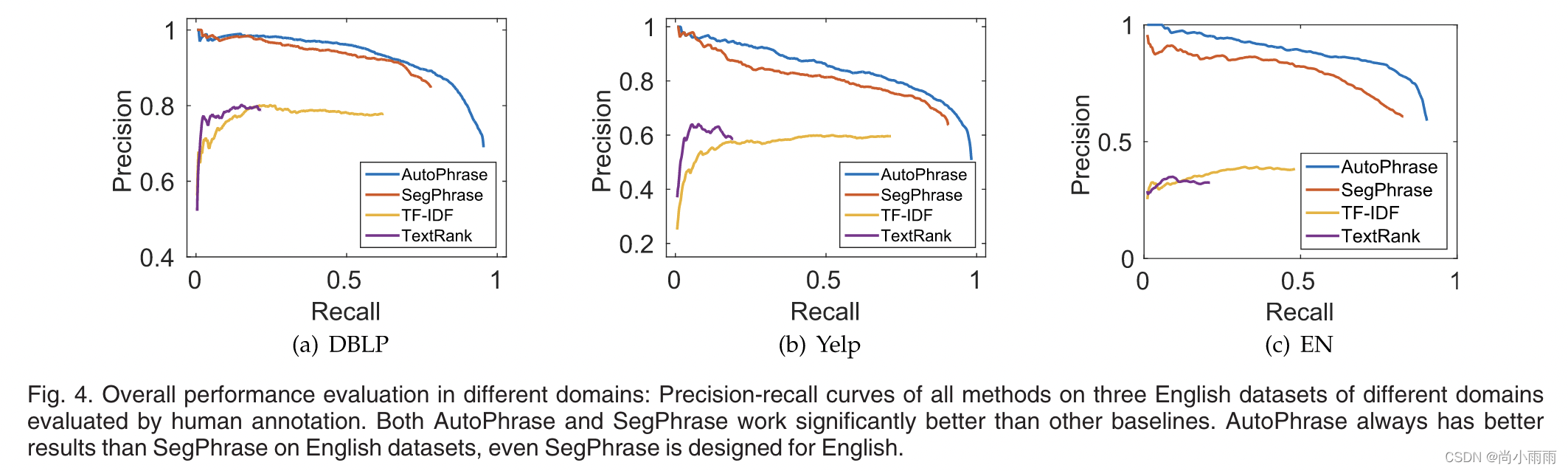
1. 不同领域数据集的性能评估: AutoPhrase和SegPhrase表现好于其他基线方法,AutoPhrase的表现较SegPhrase也更好。
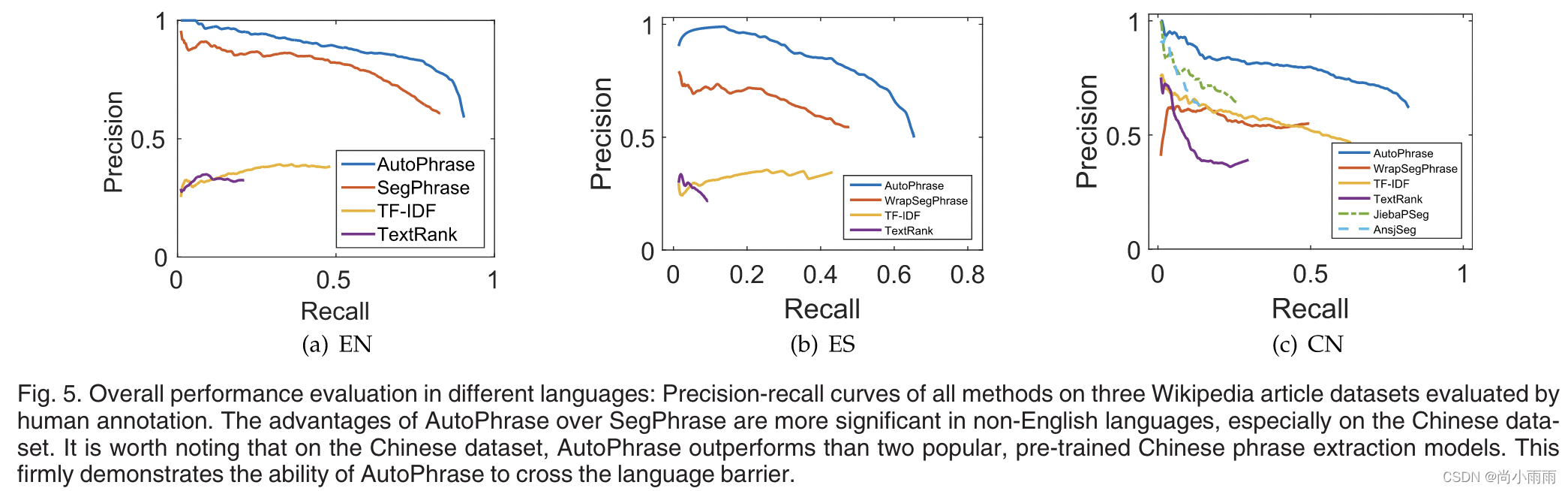
2. 不同语言数据集的性能评估: 在非英语语言,尤其是中文数据集上,AutoPhrase的表现好于SegPhrase。
远程训练发现
- 对特定领域的数据集DBLP和Yelp进行实验,提供了四个训练池:EP-领域专家标注为正向池;DP-现有通用知识构成的正向池的一个子集;EN-领域专家标注为负向池;DN-所有不在正向池的候选短语。
- 将上述正负池两两组合,得到四种变量池:EPEN(inSegPhrase),DPDN(inAutoPhrase),EPDN,和DPEN。
1. 人工标注效果最好,但从通用知识库中抽取的表现也较优。
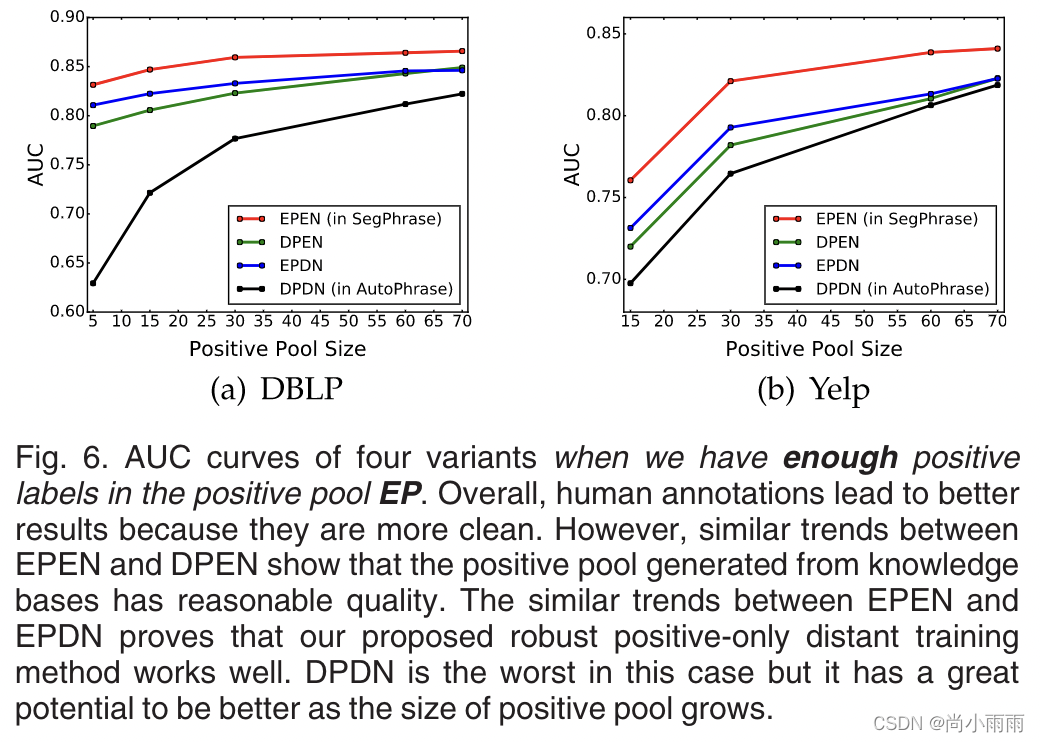
2. 当正向池足够大后,通用知识库抽取成为了表现最好的方法,也证明了其在实际应用中的实用性。
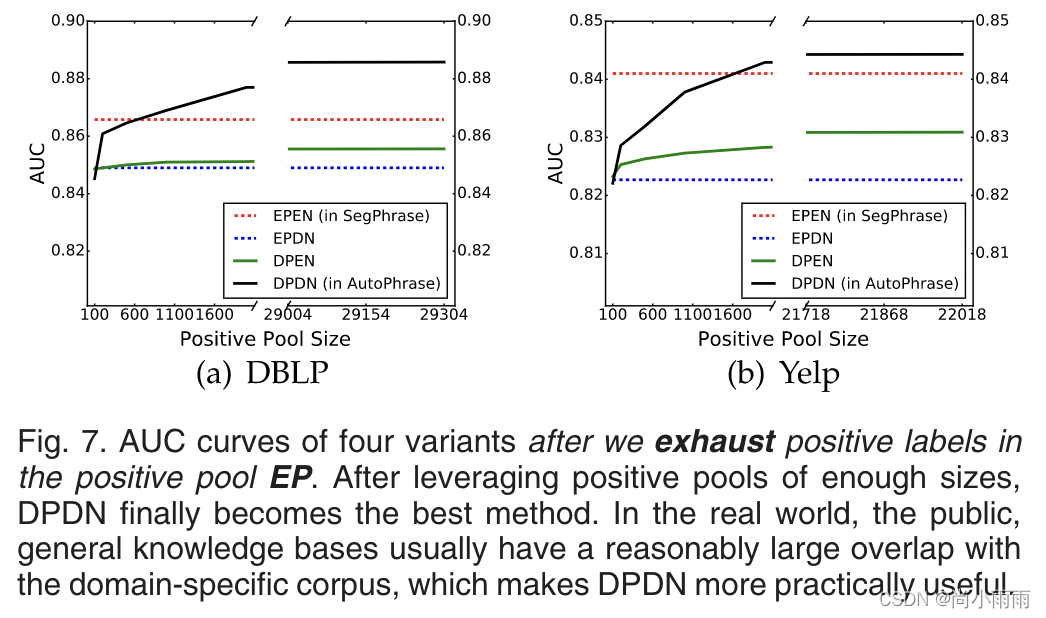
词性指导的短语分割
- 实验目的:验证加入词性特征会产生多大的性能增益。
- 实验数据:维基百科文章数据集(中文、西班牙文、英文)。
1. 在三种语言的数据集上,AutoPhrase的表现均优于AutoSegPhrase,中文数据集上尤为明显。
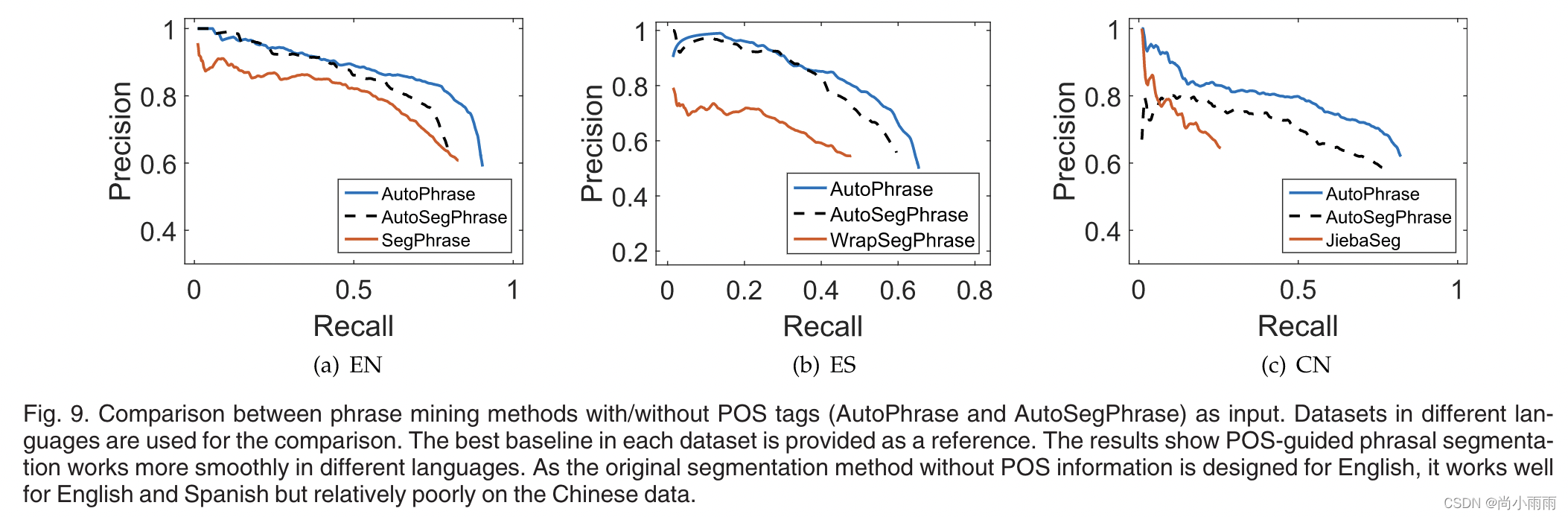
2. 结论:特定语言有额外的上下文信息和语法信息,这使得在短语切分过程中加入词性标记更有效。
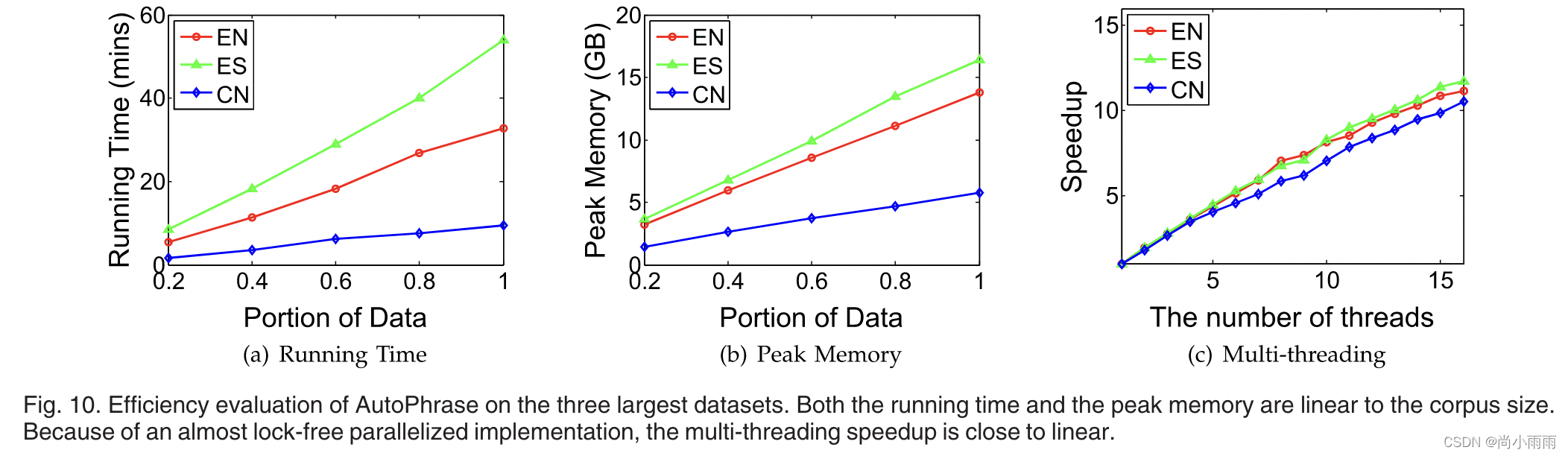
性能评价
AutoPhrase在用时和内存占用上都优于其他方法,因而效率更高。
扩展应用–单字短语分割
满足以下所有条件的为高质量单字短语(如“USA”等):
- 流行性: 在给定的文档集合中,高质量的短语应该以足够的频率出现。
- 信息性: 如果一个短语表示一个特定的主题或概念,那么它就是信息性的。
- 独立性: 高质量的单字短语更可能是给定文档中的完整语义单元。(代替AutoPhrase的一致性)
结果:
贡献
1.研究了自动短语挖掘问题,并分析了其面临的主要挑战。
2. 提出了一种鲁棒的正距离训练方法,用于短语质量评估,以最大限度地减少对于人工的需求。
3. 发展出一种新的短语分割模型,帮助改进词性标注。
4. 展示了模型的稳健性、准确性和效率,通过五个不同主题(科学论文、商业评论和维基百科文章)和不同语言的真实数据集上进行测试(英语、西班牙语和汉语)来证明这一点。
5. 将AutoPhrase模型扩展到单字短语,从而在不同的数据集上提高了10%到30%的召回率。
这篇关于论文浅尝|《Automated Phrase Mining from Massive Text Corpora》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)