corpora专题
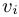
基于kbqa 的复旦大学论文解释 learning question answering over QA corpora and knowledge bases(二)
我们表示第i项其中,,所以,所以我们建立了QA与X的似然线性关系, (13) 最大似然估计QA就是等价最大似然估计X,(2)通过边际化联合概率,得到,基于总体的模板t和谓语p,似然如公式(14),我们阐述整个过程如图4,

论文学习Discovering Event Evolution Graphs From News Corpora
摘要 鉴于互联网技术的进步,我们现在可以很容易地从CNN.com等新闻网站上获取任何正在发生的事件的数百或数千条新闻报道,但信息量太大,我们无法捕捉到蓝图。信息检索技术,如主题检测和跟踪技术,能够将新闻故事组织成事件,在一个主题中以扁平的层次结构进行组织。然而,他们无法呈现事件之间复杂的进化关系。我们不仅有兴趣了解重大事件是什么,而且还想了解它们是如何在主题中发展的。它有利于鉴别开创性事件,中间

关于Reuters Corpora(路透社语料库)
首先在命令行窗口中进入python编辑环境,输入 >>import nltk>>nltk.download() 然后加载出: 在Corpora中所有的文件下载到C:\nltk_data中,大小在2.78G左右。 然后开始对其玩弄啦。 加载 from nltk.corpus import reutersfiles = reuters.fileids()#print(files)wo

论文浅尝|《Automated Phrase Mining from Massive Text Corpora》
导读 这是一篇发表于2018年的IEEE文章,论文题目为《Automated Phrase Mining from Massive Text Corpora》,意为从大量语料中自动挖掘短语。 选题背景 1. 短语挖掘任务: 在语料中自动提取高质量短语(科学术语和通用实体等),举例:information extraction/retrieval, taxonomy construction