本文主要是介绍【数据开发】DW数仓分层设计架构与同步策略(ODS、DWD、DWS等字段含义),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、什么是数据仓库(DW)
- 2、DW分层设计架构(ODS,DWD,DWS)
- 3、数仓同步策略
1、什么是数据仓库(DW)
Data warehouse(可简写为DW或者DWH)数据仓库是什么?
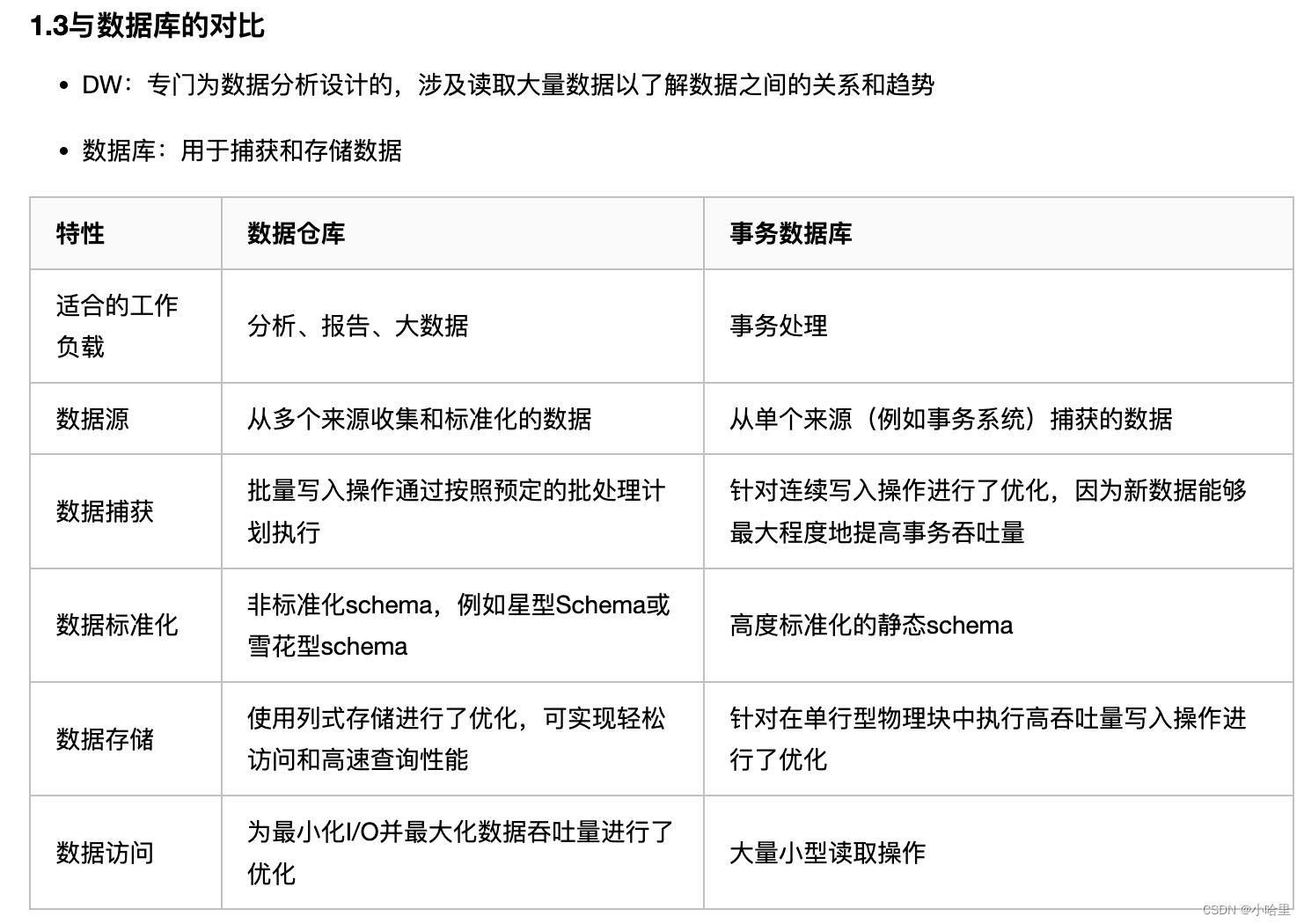
- 是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它是一整套包括了etl、调度、建模在内的完整的理论体系。数据仓库的方案建设的目的,是为前端查询和分析作为基础,主要应用于OLAP(on-line Analytical Processing),支持复杂的分析操作,侧重决策支持,听且提供直观易懂的查询结果。比较流行的有:AWS Redshift,Greenplum,Hive等。
数据仓库(ETL)的四个操作
- ETL(extractiontransformation loading)负责将分散的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中。ETL 是实施数据仓库的核心和灵魂,ETL规则的设计和实施约占整个数据仓库搭建工作量的 60%~80%。
- 1)数据抽取(extraction)包括初始化数据装载和数据刷新:初始化数据装载主要关注的是如何建立维表、事实表,并把相应的数据放到这些数据表中;而数据刷新关注的是当源数据发生变化时如何对数据仓库中的相应数据进行追加和更新等维护(比如可以创建定时任务,或者触发器的形式进行数据的定时刷新)。
- 2)数据清洗主要是针对源数据库中出现的二义性、重复、不完整、违反业务或逻辑规则等问题的数据进行统一的处理。即清洗掉不符合业务或者没用的的数据。比如通过编写hive或者MR清洗字段中长度不符合要求的数据。
- 3)数据转换(transformation)主要是为了将数据清洗后的数据转换成数据仓库所需要的数据:来源于不同源系统的同一数据字段的数据字典或者数据格式可能不一样(比如A表中叫id,B表中叫ids),在数据仓库中需要给它们提供统一的数据字典和格式,对数据内容进行归一化;另一方面,数据仓库所需要的某些字段的内容可能是源系统所不具备的,而是需要根据源系统中多个字段的内容共同确定。
- 4)数据加载(loading)是将最后上面处理完的数据导入到对应的存储空间里(hbase,mysql等)以方便给数据集市提供,进而可视化。
数据库设计三范式
- 为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式时符合某一种设计要求的总结。
- 第一范式:确保每列保持原子性,即要求数据库表中的所有字段值都是不可分解的原子值。
- 第二范式:确保表中的每列都和主键相关。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
作用:减少了数据库的冗余 - 第三范式:确保每列都和主键列直接相关,而不是间接相关。
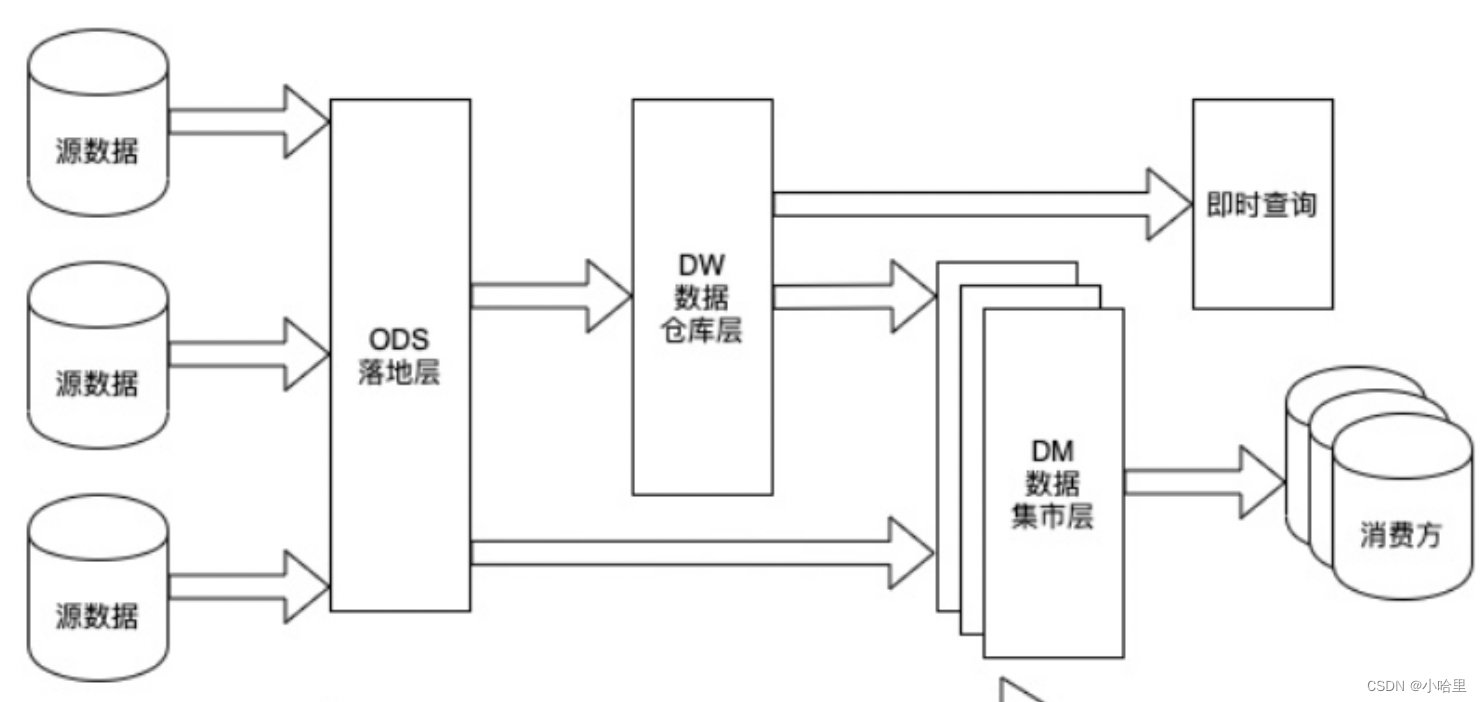
2、DW分层设计架构(ODS,DWD,DWS)
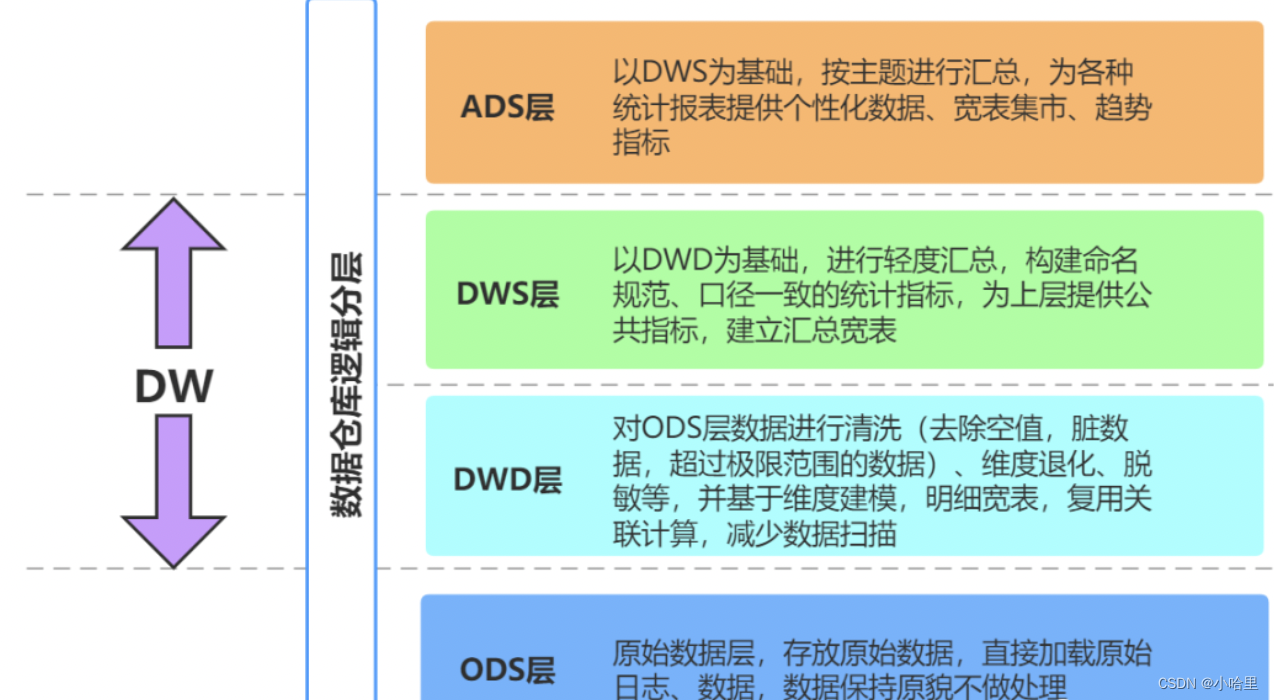
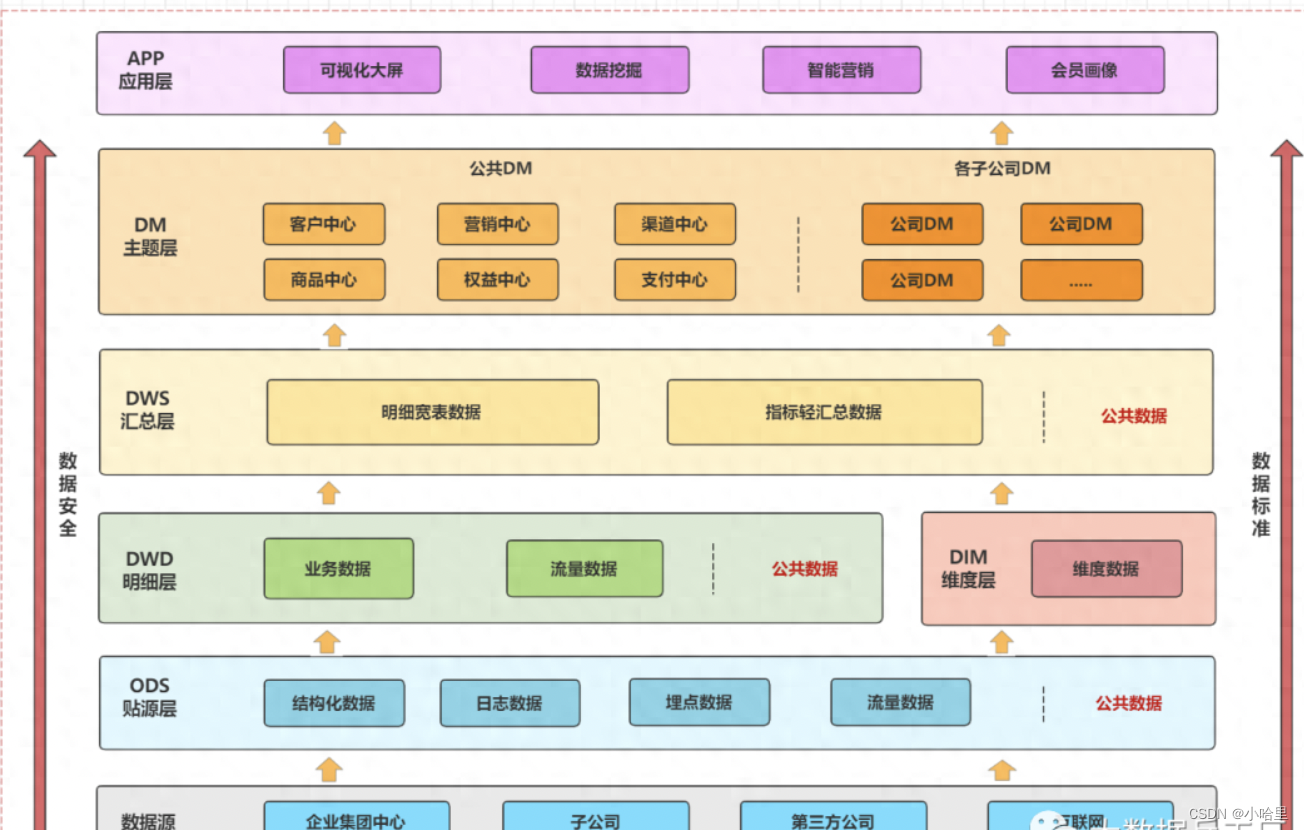
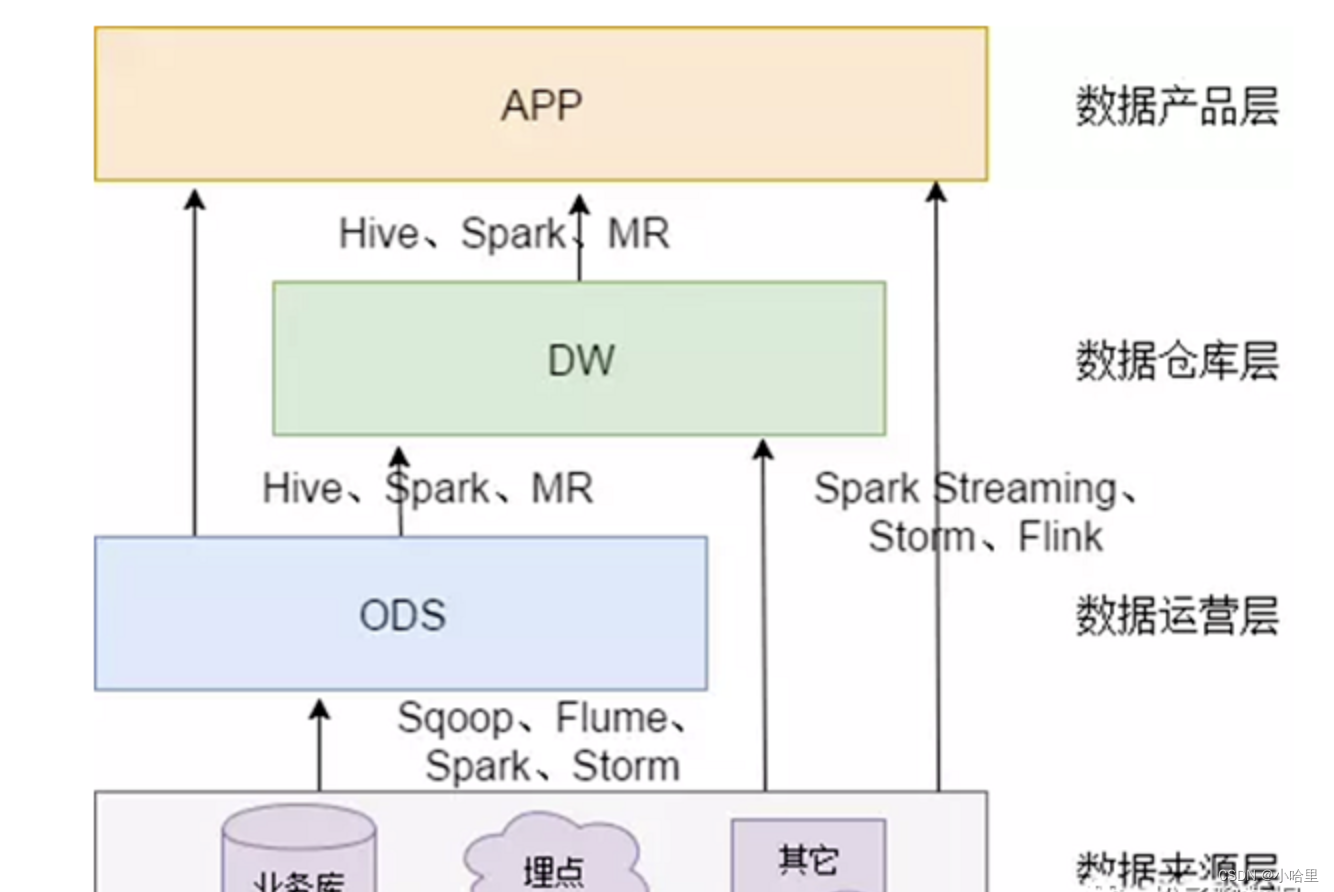
为什么要分层?
- 只有数据模型将数据有序的组织和存储起来之后,大数据才能得到高性能、低成本、高效率、高质量的使用。
- 1)清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
- 2)数据血缘追踪
- 3)数据复用,减少重复开发
- 4)把复杂问题简单化。讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤
- 5)屏蔽原始数据的(影响) ,屏蔽业务的影响。


3、数仓同步策略
数据同步过程按照供数的方式可以分为全量和增量两种形式。
按照存储的话又可分为覆盖、交易、快照和拉链等四种形式。
其中,根据数据量大小,可以粗略的制定分层内数据同步加载策略:
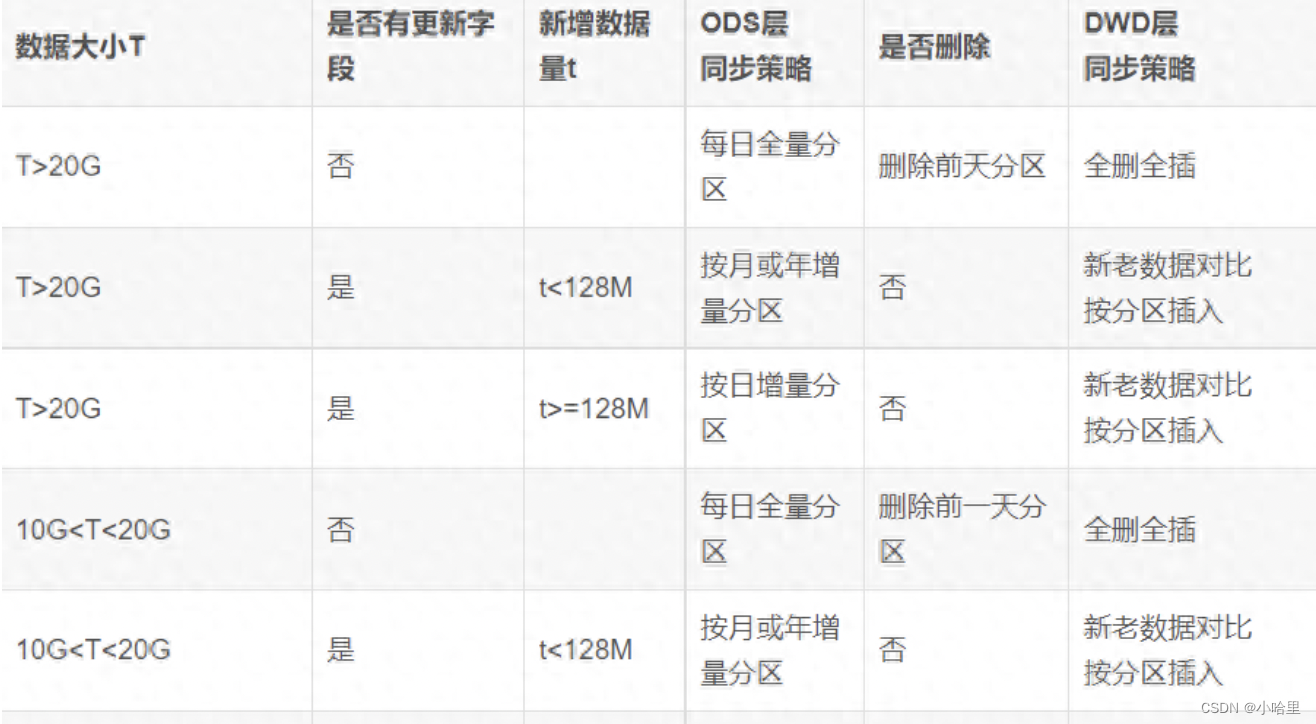
1) 全量
全量是从源表中抽取数据的方式之一,每次同步源表的所有数据进行后续处理。
2) 增量
增量是从源表中抽取数据的方式之一。首次抽取时(初始化)全量抽取,之后每次只同步变更的数据。
3) 覆盖
覆盖是指将数据存放到目标表时的一种同步方式。通过该方式存放数据时,每次先清除目标表中的所有数据,然后将要加载到目标表的数据全部插入到目标表中,即用最新的数据覆盖原来的旧数据。
一般和全量同步一起使用。
4) 交易
交易是指将数据保存到目标表数据的另一种同步方式。每次将最新的数据插入到目标表中。适用于源表数据不会发生修改,值会随着时间增加的表。
5) 快照
快照是指在目标表中添加一个数据的快照时间标识的字段,用于区分数据何时加载。为了介绍方便,后面简称为数据加载时间。
每次加载数据时,根据ETL程序的运行时间作为这一批次数据的加载时间,这样不同时间、不同批次的数据,目标表的数据加载时间也不同。
一般和全量同步配合使用,这样每一批数据的加载时间相同的数据,相当于目标表在该时间的一张照片,根据数据加载时间作为区分,将目标表历史上不同时间的不同版本都保存下来。
6) 拉链
拉链同步也称为历史拉链。通过该方式同步数据,仅当存放到目标表中的数据发生变更时,对应的记录才会发生变动。
通过目标表中记录的开始时间和结束时间来记录数据的历史变化轨迹。这样就能有效保留历史数据的变动信息,也不会浪费存储空间。
参考资料:1, 2 , 3,4,5,6
这篇关于【数据开发】DW数仓分层设计架构与同步策略(ODS、DWD、DWS等字段含义)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







