本文主要是介绍Paper小计:AUTOREGRESSIVE ENTITY RETRIEVAL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.A BSTRACT :
实体是我们如何表示和聚合知识的中心。(entity很重要。)
检索给定查询的这些实体的能力是知识密集型任务的基础,如实体链接和开放领域的问题回答。(检索给定查询的实体的能力很重要,以及其实际运用。)
该方法导致三个缺点:
1.上下文和实体亲和性主要通过 向量点积捕获,可能 缺少两者之间的 细粒度交互。
2.在考虑 大型实体集时,需 要较大的内存占用来存储密集的表示。
3.在训练时必须对适当的 硬负数据集进行 下采样。
propose:GENRE:通过生成实体的唯一名称,从左到右,以自回归的方式逐个标记,并以上下文为条件。
减轻上述缺点:
1.自回归公式允许我们 直接捕获上下文和实体名称之间的关系,有效地 交叉编码两者。
2. 内存占用大大 减少,因为我们的编解码器架构的 参数与词汇大小,而不是 实体数量。
3. 确切的soft最大损失可以有效地计算,而不需要对负数据进行子采样。
验证展示:实验了 20多个实体消歧数据集, 端到端实体链接和 文档检索任务,在使用竞争系统的 少量内存占用的同时,实现了新的最先进的或非常有竞争力的结果。最后,我们演示了可以通过 简单地指定它们的明确名称来添加新的实体。
I NTRODUCTION:
从给定文本输入的大型知识库(kb)中 检索正确实体的能力是多个应用程序的基本构建块。
目前大多数解决方案都有一个共同的设计选择: 实体与独特的原子标签相关联,检索问题可以解释为跨这些标签的 多类分类。输入和标签之间的匹配是通过 双编码器计算的:输入的密集向量编码与实体的元信息之间的点积。(对实体检测目前已有工作的总结和分析。)
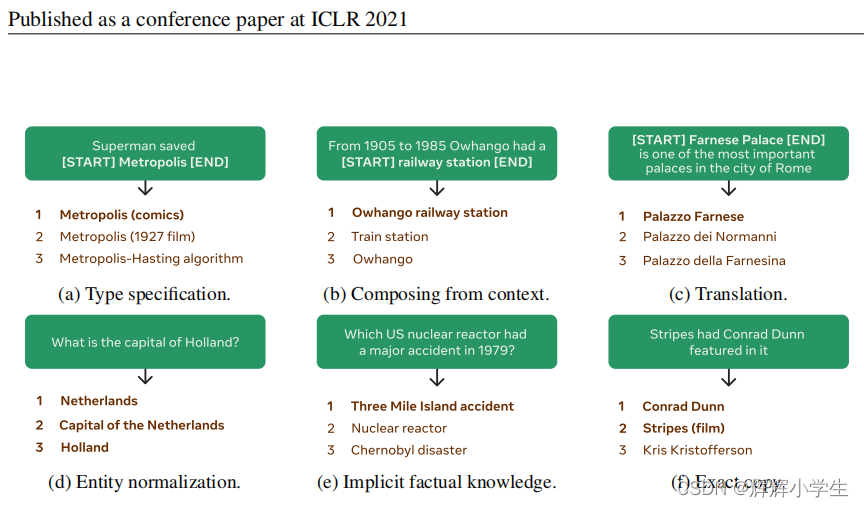
将实体标识符作为分类器中的原子标签进行处理,忽略了这样一个事实,即我们通常具有明确的、高度结构化的和组合的实体名称。例如,维基百科将独特的标题与文章联系起来,1可能是主题的名称或主题的描述,以及潜在的独特信息来消除歧义2(一些例子见图1)。这些实体名称通常以一种可预测的和有规律的方式与被提及的上下文进行交互。例如,实体名称通常与引用它们的提及字符串完全相同(例如,图1f)。当这是不可能的时,它们可能由上下文中的标记组成(例如,图1b),包括可以推断的类型规范(例如,图1a),是字符串提及的翻译(例如,图1c),需要“规范化”,例如引用提及的正确别名(例如,图1d),或者需要可能存储在模型参数中的事实知识(例如,图1e)。这些观察结果表明,输入可以被逐字转换为唯一的实体名称,而不是被归入一系列大型选项之中。
实体检索的分类器方法的缺点:除非使用昂贵的交叉编码器进行重新排序,否则点产品可能会错过输入和实体元信息之间的 细粒度交互;其次,为整个KB存储密集的向量需要 很大的内存占用;
对所有实体计算精确的softmax非常昂贵,因此当前的解决方案需要 对负数据进行子样本采样;现有系统可能会遇到 冷启动问题,因为它们不能表示尚未收集到足够信息的实体。
Generative ENtity REtrieval:
利用 序列到序列的体系结构,以 上下文为条件的 自回归方式生成实体名称的 实体检索器。具体地说,类型使用了基于transformer的架构,使用 语言建模目标进行 预训练,并进行微调以生成实体名称。除了其它的信息,在某种程度上该架构被证明保留了 事实知识与 语言翻译技巧。生成的输出可能并不总是一个有效的实体名,为了解决这个问题,类型采用了一种 约束解码策略,迫使每个生成的名称都在一个 预定义的候选集中。
自回归公式允许我们 直接捕获上述上下文和实体名称之间的关系,有效地 交叉编码两者。此外,所需的 内存占用比当前系统 小一个数量级,因为 序列到序列模型的 参数与词汇表大小成线性比例,而 不是实体计数。此外,可以对每个输出标记有效地计算出精确的softmax(即,所有非黄金标记都被认为是负的),从而 消除了对 负数据降采样的需要。最后,我们的模型 从不访问除其标题之外的任何关于实体的显式元信息,因此可以通过 简单地将其明确的名称添加到候选集来添加新的实体。
2.E NTITY R ETRIEVAL :
我们假设有一个实体E的集合(例如,维基百科的文章),其中每个实体都是一个知识库(KB)中的一个条目,比如维基百科。我们希望处理以下检索问题:给定一个文本输入源x(例如,问题),一个模型必须从E中返回关于x的最相关的实体。我们假设每个 e ∈ E i都被唯一地分配给一个文本表示(即它的名称):一个标记y序列(例如,维基百科页面由它们的标题标识)。
这个问题的一个特殊实例是实体消歧(ED)(参见图1的示例),其中输入x被注释,系统必须从E中选择相应的实体,或者预测知识库中没有相应的条目。另一个实例是页标文档检索(DR),其中输入x作为查询,E作为由其唯一标题(如维基百科文章)标识的文档的集合。
3.M ETHOD:
自回归公式:score( e | x ) = p θ ( y | x ) = 连乘符号i从1取到N p θ ( y i | y <i , x)
其中,y为e的标识符中N个标记的集合,θ为模型的参数。
利用BART微调、标准seq2seq、teacher forcing最大化输出序列可能性、dropout、标签平滑。

图2:使用“1503年,达芬奇开始画蒙娜丽莎”的动态约束标记解码的例子。作为输入。有3种情况:当我们在提到/实体(a)之外,在提到生成步骤(b)内,以及在实体链接生成步骤(c).内部该模型应该输出输入源,注释并指向各自的实体:“1503年,达芬奇)开始画《蒙娜丽莎》(蒙娜丽莎)。
3.1 I NFERENCE WITH C ONSTRAINED B EAM S EARCH :
使用BS(使用带有k个光束的BS从我们的模型中搜索E解码中的前k个实体。使用BS意味着我们的检索器的时间成本并不依赖于E的大小,而是只依赖于光束的大小和实体表示的平均长度,就像我们做自回归生成一样。)
受约束的BS (BS在解码过程中只考虑提前一步,所以我们只能限制基于前一个条件的下一个令牌的生成。)
我们使用的约束掩盖了无效标记的对数概率,而不是它们的对数概率。(也就是说,我们不在词汇表上重新规范化该概率。)
3.2 A UTOREGRESSIVE E ND - TO -E ND E NTITY L INKING:
扩展了自回归框架来解决端到端实体链接(EL) (我们训练模型再次预测源输入,但使用带注释的跨度。我们使用标记注释,其中跨边界用特殊标记标记,并伴随着它们相应的实体标识符。)
与输出空间相对较小的设置不同(例如,一个预定义的集合E),带注释的输出的空间呈指数级大。因此,很难预先计算解码,我们动态计算它。(在每个生成步骤中,解码器要么生成提及跨度,生成到提及的链接,要么从输入源继续。当在提到/实体步骤之外时,解码器只有两个选项:(i)继续从输入源复制下一个令牌,或者(ii)生成提及令牌的开始(即“[”),这使得解码器进入提及生成阶段。生成提及时,解码器必须继续使用输入源中的下一个令牌,或者生成提及令牌的结束(即“]”),这使解码器进入实体生成阶段。最后,当生成一个实体时,解码器使用实体测试,这样它只能输出一个有效的实体标识符,如上述约束光束搜索中所述。)
4 EXPERIMENTS:
我们对跨3个任务的20多个数据集进行了广泛的类型评估:实体消除歧义、端到端实体链接(EL)和页面级文档检索。
4.1 S ETTINGS
Entity Disambiguation (ED)
使用相同的候选集、域内和域外数据集重现了Le&Titov的设置,使用InKBmicro-f1进行评估;训练类型输入每个文档,其中一个提到被标记为两个特殊的开始和结束标记,而目标输出是相应实体的文本表示;测试时,约束bs解码,用提供的候选集解码;GENRE在BLINK上预训练;对于域内场景,使用AIDA-CoNLL数据集进行微调;域外场景,对五个测试集进行评估: MSNBC, AQUAINT,ACE2004, WNED-CWEB (CWEB) and WNED-WIKI (WIKI) (Gabrilovich et al., 2013; Guo & Barbosa, 2018). End-to-End Entity Linking (EL)
使用相同的域内和域外数据集重现了Kolitsas等人的设置,并在 the GERBIL benchmark platform上评估了InKBmicro-f1;在维基百科4的所有抽象部分上通过字符串匹配启发式来解决共引用;域内场景,我们使用AIDACoNLL数据集进行微调。我们评估7个域外测试集: MSNBC, Derczynski (Der) (Derczynski et al., 2015), KORE 50 (K50) (Hoffart et al., 2012), N3-Reuters-128 (R128), N3-RSS-500 (R500) (R oder et al., 2014), and OKE challenge 2015 and 2016 (OKE15 and OKE16) (Nuzzolese et al., 2015).
Page-level Document Retrieval (DR)
在所有的KILT基准测试任务上测试类型;使用整个维基百科作为候选集,我们使用r-精度进行评估;KILT包括五个使用相同的维基百科转储作为知识来源的任务:略; We train GENRE on
BLINK and all KILT data simultaneously with a single model. 5
4.2 RESULTS 略
5 R ELATED WORKS :
6 CONCLUSIONS:在这项工作中,我们提出了GENRE,一个新的范式来解决实体检索:生成实体名称自动回归。实体名有几个属性,可以帮助(甚至是人类)检索它们,包括一个组合结构和与上下文的可预测的交互。自回归公式允许我们直接捕获这些属性,导致几个优势对当前的解决方案,包括一个有效的方式交叉编码提到上下文和实体候选人,一个小得多的内存占用,能够计算一个精确的softmax不需要子样本负数据。我们的经验表明,这些特征,结合约束解码策略,导致最先进的性能过多的实体检索数据集,跨越实体消除歧义,端到端实体链接,和页面级文档检索,同时导致系统显著包含内存占用,一个平均空间减少了20倍。此外,我们还证明了通过简单地向候选集添加它们明确的名称,可以在我们的系统中有效地考虑新的实体。
这篇关于Paper小计:AUTOREGRESSIVE ENTITY RETRIEVAL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)