本文主要是介绍一文理解全外显子家系和病例-对照参考基因组比对和变异检测全流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 遗传学名词解释
SNP: single nucleotide polymorphism, 单核苷酸多态性, 个体间基因组DNA序列同一位置单个核苷酸变异(替代、 插入或缺失)所引起的多态性。
InDel: Insertion/Deletion, 插入/缺失, 在基因组重测序进行mapping时, 进行容Gap的比对并检测可信的Short InDel, 如基因组上小片段>50bp的插入或缺失。在检测过程中, Gap的长度为1~5个碱基。
CNV:copy number variation, 基因组拷贝数变异, 是基因组变异的一种形式,通常使基因组中大片段的DNA形成非正常的拷贝数量。如人类正常染色体拷贝数是2, 有些染色体区域拷贝数变成1或3, 这样, 该区域发生拷贝数缺失或增加, 位于该区域内的基因表达量也会受到影响。
SV: structure variation, 基因组结构变异, 染色体结构变异是指在染色体上发生了大片段的变异。主要包括染色体大片段的插入和缺失( 引起 CNV 的变化) , 染色体内部的某块区域发生重复复制、 翻转颠换、 易位、 两条染色体之间发生重组( inter-chromosome trans-location) 等。
2. 配置软件和参考基因组
2.1 下载GATK最新版
| |
下载完后解压GATK文件,会发现有几个gatk程序,gatk-package-[version]-spark.jar是在spark集群上跑的,gatk-package-[version]-local.jar是在本地跑的。我们可以直接调用gatk来运行它。
| |
![]()
在当前文件夹下输入下面的命令,如果出现GATK的参数信息,说明GATK可以用了。
| R |
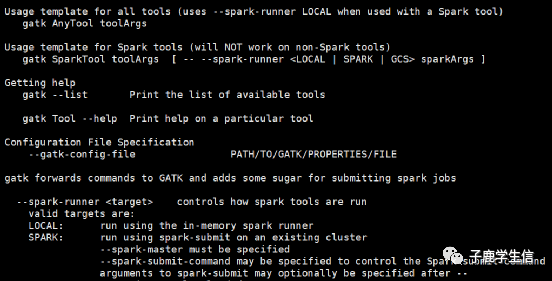
如果在其他文件夹下,想运行GATK,要么在前面加上全路径,要么把GATK这个软件加入到linux的环境变量里。
在任意文件夹下通过命令 vi ~/.bashrc 打开bashrc文件,输入:export PATH="/path/to/gatk-package/gatk-4.4.0.0/:$PATH",再source ~/.bashrc(加载一下)就可以在任意文件夹调用GATK了。
| R |
这个操作就是告诉linux系统,要去这个文件夹下找GATK软件,别再说找不到软件了!
2.2 下载参考基因组
可以直接通过ftp下载,把下面的ftp地址粘贴到文件夹路径里,回车打开,注意现在粘贴到浏览器是打不开的。
| Bash |

我们常用的就是hg19和hg38,以hg38为例:
双击进入文件夹,右击鼠标会发现复制到文件夹,随便选个文件夹,就可以下载到本地电脑了!
3. 认识fastq文件
fastq文件是我们从公司拿到的测序后的原始文件,就是一条条的DNA序列而已。

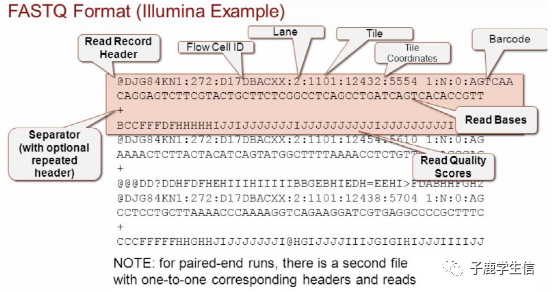
| fastq文件由四个基本部分组成: 序列ID行,以“@”开头,后面跟着一个唯一的序列标识符。例如:@SEQ_ID 序列,即实际的DNA或RNA序列数据。例如:ACGTGACTAGCTAGCTAGCTAGCTAGCTAG 第三行以“+”开头,表示序列的描述。有时也可以包含与序列相关的信息,但这并不是必需的。 第四行是与描述信息行对应的质量行,它包含与序列相同数量的ASCII字符,用于表示每个碱基的质量得分。对于Illumina测序仪生成的Fastq文件,质量得分通常由Phred符号表示。 |
4. GATK比对序列
4.1 设置路径
首先我们可以设置好软件和参考基因组的路径,然后后面使用$引用路径,这样每个命令就不用写长长的一串了!
注意“=”左右不要有空格,不然报错!
| R |
4.2 序列比对(Map to Reference)
| 背景知识: BWA 是一种能够将差异度较小的序列比对到一个较大的参考基因组上的软件包。它由三个不同的算法: BWA-backtrack: 是用来比对 Illumina 的序列的,reads 长度最长能到 100bp。 BWA-SW: 用于比对 long-read,支持的长度为 70bp-1Mbp;同时支持剪接性比对。 BWA-MEM: 推荐使用的算法,支持较长的read长度,同时支持剪接性比对(split alignments),但是BWA-MEM是更新的算法,也更快,更准确,且 BWA-MEM 对于 70bp-100bp 的 Illumina 数据来说,效果也更好些。
对于上述三种算法,首先需要使用索引命令构建参考基因组的索引,用于后面的比对。所以,使用BWA整个比对过程主要分为两步,第一步建索引,第二步使用BWA MEM进行比对。 bwa的使用需要两种输入文件: Reference genome data(fasta格式 .fa, .fasta, .fna) Short reads data (fastaq格式 .fastaq, .fq)
|
4.2.1 安装bwa
最好使用conda或者mamba安装
| Bash |
成功激活环境的标志是在命令行前面可以看到WGS这个环境的名字。
其他软件安装方式参考bwa。
4.2.2 参考基因组索引
首先,需要使用bwa index命令对参考基因组进行索引,这个是一次性的工作,索引完成后每个项目的分析都可以用了,数据非常大,这里我就不提供了,实在自己搞不定,找我我传一份:
| Plaintext |

从fastq文件开始处理,得到变异的VCF文件的流程大概是:
-
比对到参考基因组
-
Markduplicate
-
BQSR
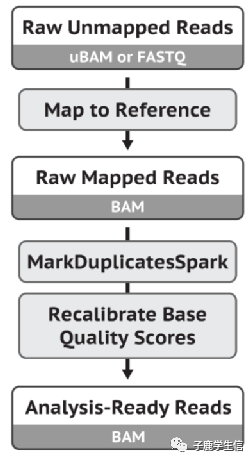
4.2.3 mappting
| 背景知识: BWA-MEM 算法原理 该算法先使用 MEM(maximal exact matches) 进行 seeding alignments,再使用 SW(affine-gap Smith-Waterman) 算法进行 seeds 的延伸。BWA–MEM 算法执行局部比对和剪接性。可能会出现 query 序列的多个不同的部位出现各自的最优匹配,导致 reads 有多个最佳匹配位点。有些软件如 Picard’s markDuplicates 跟 mem 的这种剪接性比对不兼容,在这种情况下,可以使用 –M 选项来将 shorter split hits 标记为次优。 |
| R |
4.2.3.1 使用bwa mem命令进行比对:
| Bash |
其中,"> alignment.sam"将比对结果输出到一个sam格式的文件中。
在这个命令中,bwa mem会使用BWT算法在参考基因组上进行比对,将比对结果输出到sam格式的文件中。
| 背景知识: SAM(Sequence Alignment/Map)格式是一种文本文件格式,用于存储测序仪原始测序数据和对参考基因组的比对结果。BAM是SAM的二进制表示,即SAM文件被压缩成binary格式。 主要区别如下:
总之,BAM格式是SAM格式的二进制表示方式,可以提高文件的处理效率,支持索引等高效定位功能,同时也包括了SAM格式的所有信息,使得它在实际二代测序分析中更加高效、实用。 |
所以我们后面分析都是用bam格式来做的,因为是二进制,所以也无法查看的。
不过我们可以看sam文件的格式:
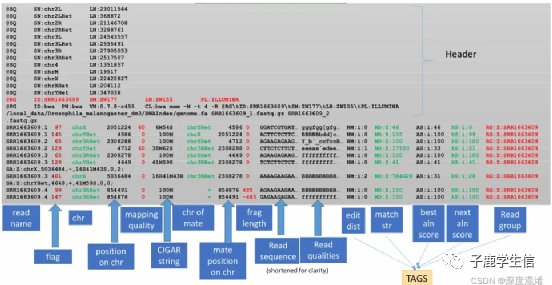
可以看到,原始的fastq文件只有序列信息,这里有位置信息了!
4.2.3.2 使用samtools软件将sam格式文件转换为bam格式文件:
| Bash |
4.2.3.3 samtools软件对bam文件进行排序和索引:
| Bash |
排序后的bam文件和其对应的bai索引文件将用于后续的下游分析。
| 背景知识: 使用samtools软件对bam文件进行排序和索引的目的: 提高查询速度:bam文件是按照读取顺序存储的,而不是按照参考基因组的顺序存储的。如果需要从bam文件中查询一段特定的参考基因组区域,就需要对bam文件进行排序和索引,以便快速定位包含目标区域的序列段。 简化后续分析:在很多分析过程中,需要对bam文件进行简化,例如去重、过滤、统计等操作。如果bam文件已经经过排序和索引,就可以更加方便、高效地进行这些操作。 便于可视化:一些可视化分析工具需要对bam文件进行索引,以便快速定位并显示每条序列在参考基因组上的比对结果。 |
4.2.4 MarkDuplicates
| 背景知识: Mark Duplicates是什么? 是指在WES二代测序数据分析过程中,对PCR扩增文库和高通量测序(HTS)过程中引入的PCR重复进行标记和去除的步骤。在HTS数据处理过程中,PCR扩增会导致同一DNA片段的多个拷贝被其它拷贝所覆盖,从而产生PCR重复。由于数据误差和测序深度等原因,PCR扩增文库引入的PCR重复数量可能非常高,从而对数据分析结果产生较大影响。针对这一问题,Mark Duplicates工具就被开发出来了。
Mark Duplicates通过计算同一DNA片段的序列相似度,将原始HTS数据中的PCR重复序列片段标记为重复项,并对这些重复项进行去除,只保留一份非重复的数据。去除PCR重复可以最大限度地提高测序数据的质量,减少测序偏好引入的误差,提高变异检测和重排程序的准确性。
总之,WES二代测序数据分析中的Mark Duplicates步骤可以理解为“标记和去重”,去除PCR扩增文库引入的PCR重复,保留一个最能代表该片段的序列样本,提高数据分析的质量和可靠性。
picard MarkDuplicates参数选择: VALIDATION_STRINGENCY参数用于控制MarkDuplicates的严格性,其具体取值有以下几种: SILENT:不验证输入数据的有效性,忽略所有错误和警告。 LENIENT:在大多数情况下可以接受的缺陷和警告下工作,减少错误提示。 STRICT:严格验证输入数据,应用严格的规则检查输入和输出文件的格式和内容。 VERY_STRICT:与STRICT模式相同,但忽略一些明显不会影响处理结果的问题。 如果数据质量较好,建议选择STRICT或VERY_STRICT模式,可以提高数据处理的质量和准确性。如果数据存在一些问题或者不确定性因素,则可以选择LENIENT模式,允许一些警告和缺陷。而SILENT模式通常只在非常特殊的情况下使用,例如在高通量数据处理管道中,当需要快速处理数据并忽略所有偏差和错误时。 |
| Bash |
4.2.5 Base (Quality Score) Recalibration
| 背景知识: BQSR是什么? Base Quality Score Recalibration(BQSR)是二代测序数据分析中非常重要的一环。它通过建立测序数据质量模型,对每个碱基的质量评分进行校正,从而提高测序数据的准确性和可靠性。其作用是通过机器学习技术,检测和纠正测序器输出的质量分数(称为碱基质量分数)中的系统性误差。
在二代测序中,每次测序错误率在约1-2%左右,因此会出现很多数据误差和突变。为了准确地检测出变异和SNP,我们需要尽量降低这些误差的影响。BQSR就是为了解决这一问题而提出的方法,它会先从测序数据中抽取出一部分作为“训练集”,然后根据训练集的数据量,建立出碱基质量模型,并使用该模型对所有碱基的质量评分进行校正,提高碱基质量和减少误差。
BQSR一般分为两个步骤:首先,使用训练集的数据建立出质量评分模型(即,估计碱基误差率),并生成一个较为准确的精度统计模型;然后,根据这个统计模型,计算每个碱基的错误率,进而对其质量评分进行校正。
所以,BQSR的作用是提高二代测序数据的准确性和可靠性,减少误差和突变,降低假阳性率。通过建立碱基质量模型,使用训练集数据进行校正,可以在一定程度上减少碱基误差,提高突变和SNP检测的准确性。 |
-
BaseRecalibrator工具
| 背景知识: BaseRecalibrator是什么? GATK4的BaseRecalibrator用于校正测序中的碱基质量分数,以提高测序数据的准确性。其中,碱基质量分数是测序时候为每个碱基分配的置信度分数,数值越高表示该碱基比对的越准确。
在二代测序中,由于测序过程中存在许多因素会影响碱基的质量,如测序深度、局部GC含量和捕获效率等,这些因素都会导致碱基质量分数产生一定的误差。而这些误差在后续的数据分析过程中可能会影响结果的准确性,因此需要进行校正。
BaseRecalibrator工具会分析测序数据中的碱基质量分数以及一些其他统计数据,如碱基覆盖度、局部GC含量等等。然后会基于这些统计数据,构建一个模型,该模型能够准确估计测序数据中的系统误差,并为数据中的每个碱基分配一个新的质量分数,以校正碱基质量分数中的误差。
用一句话来说,GATK4的BaseRecalibrator工具的作用就是通过量化分析测序数据中的系统误差,对碱基质量分数进行校正,以提高测序数据的准确性。这能够减少在后续数据分析阶段中可能存在的误差、提高SNP和Indel检测的灵敏度和精确性。 |
| Bash |
-
ApplyBQSR工具
| 背景知识: ApplyBQSR的作用: ApplyBQSR的作用是应用之前BaseRecalibrator工具创建的质量分数校正表,将校正后的碱基质量分数应用于测序数据中,从而提高测序数据的准确性。
具体来说,测序中的碱基质量分数可能会受到多种因素的影响,例如测序仪器的误差、文库制备和PCR扩增的偏差等。这些因素会导致碱基质量分数存在一定的误差,从而影响后续的数据分析和变异检测等任务的精度和召回率。
而在使用BaseRecalibrator工具创建基于多个统计量构建的质量分数校正表后,ApplyBQSR则可以在数据分析流程中将其应用到测序数据中。具体来说,ApplyBQSR将根据质量分数校正表中的信息,对每个碱基质量分数进行重新计算,以便更准确地反应测序中的碱基质量。这样就可以更好地排除碱基质量分数误差对数据分析结果的影响,提高数据分析结果的准确性。
总而言之,ApplyBQSR的作用就是在测序数据分析中,使用BaseRecalibrator工具创建的质量分数校正表,对测序数据中的碱基质量分数进行重新计算,以提高测序数据的准确性。 |
| Bash |
经过BQSR的文件就可以找变异了 !可以用GATK的HaplotypeCaller来找变异(SNP和Indel)。
4.2.6 HaplotypeCaller
| HaplotypeCaller的作用: GATK的HaplotypeCaller是用于从测序数据中检测单个或多个样本的变异(SNP和Indel)的工具。
HaplotypeCaller通过对变异区域进行从头拼装生成单倍体核苷酸序列,同时检测SNPs和indels。在程序遇到变异的区域时,丢弃原有的映射信息并在该区域中重新拼装reads。这个算法可以让HaplotypeCaller检测到传统方法难以检测的区域(例如含有不同类型的变异的区域)时更加准确。
HaplotypeCaller按单样本运行生成中间GVCF文件,然后可以在GenotypeGVCFs中联合多个样本进行基因分型。
|
生成中间文件gvcf:
| Bash |
WGS和WES数据分析的差异:
| 上面的这个HaplotypeCaller代码是针对WGS的。WES有少许不同,原因是WES使用探针捕获外显子区域,因此我们要给GATK指定检查区域,这样运行速度更快,更准确! |
如果是WES数据,修改代码如下:
| Bash |
这个intervals的bed文件也可以转换成bait 和 target interval 文件。区别是:
bed文件:
![]()
intervals文件:

代码如下:
| Bash |
我还没发现这两个文件在使用时的区别,发现了我再回来补充!
当然,上面的脚本可以写在一个文件里,命名成一个名字,然后直接提交在服务器后台运行。
写在后面:
我希望能建立一个活跃的、有爱的生信学习社群,这个社群包含了大部分生信学习基础知识,以及多个高分文章拆解教程。希望在未来的某一天,每个月都能发起训练营带着大家一起实践。
目前我已经完成了全网最详细的生信R语言基础教程、GEO数据挖掘、遗传学数据分析等基础教程。后面会继续写单细胞测序、临床预测模型构建、多组学数据分析等内容。这些基础内容全面向社群成员开放,相当于你有了一个随身生信图书馆!
如果想加入生信社群,或者需要学习更详细的遗传学数据处理教程,请丝信我,或者直接加我:Drzhou688,备注CSDN。
这篇关于一文理解全外显子家系和病例-对照参考基因组比对和变异检测全流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




