本文主要是介绍论文解读: 2023-Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Title: Investigating the Factual Knowledge Boundary of Large Language Modelswith Retrieval Augmentation
URL: https://arxiv.org/abs/2307.11019
Code: https://github.com/RUCAIBox/LLM-Knowledge-Boundary/tree/main
知识密集型任务需要大量的事实知识,并且经常依赖外部信息的帮助。最近,大型语言模型(LLM)(例如ChatGPT)在解决包括知识密集型任务在内的各种具有世界知识的任务方面表现出了令人印象深刻的能力。然而,仍然不清楚LLM能够多好地感知它们的事实知识边界,特别是当合并检索增强时它们如何表现。
在这项研究中,我们提出了对LLM的实际知识边界以及检索增强如何影响开放域上的LLM的初步分析。特别地,我们关注三个主要的研究问题,并通过检验LLMs的QA性能、先验判断和后验判断对它们进行分析。我们证明了LLM对他们回答问题的能力和他们回答的准确性有坚定的信心。此外,检索增强被证明是一种有效的方法,可以增强LLMs对知识边界的意识,从而提高他们的判断能力。此外,我们还发现LLM在制定答案时倾向于依赖提供的检索结果,而这些结果的质量显著影响其可靠性。
1. Motivation
- LLM能在多大程度上感知其事实认知边界?
- 检索增强对LLM有什么影响?
- 具有不同特征的支持文档如何影响LLM?
2. Contribution
- LLM对事实知识边界的感知是不准确的,他们往往表现出过度自信的倾向。
- LLM不能充分利用它们所拥有的知识优势,而检索增强可以为LLM提供有益的知识补充。无论是先验判断还是后验判断,检索增强可用于增强LLM感知其事实认知边界的能力。
- 当提供高质量的支持文件时,LLM表现出更好的性能和信心,并倾向于依靠提供的支持文件来产生响应。依赖程度和LLMs的信任取决于支持文件和问题之间的相关性。
3. Method
传统的开放领域问答采用检索器-阅读器管道方法,首先给定问题和语料库,然后检索器在语料库中检索与问题相关的文件,然后机器阅读理解模型根据检索到的文件回答问题。
LLM时代,以端到端的方式解决开放域问答,直接给定问题,设计提示,引导模型输出答案,不需要外部知识库。
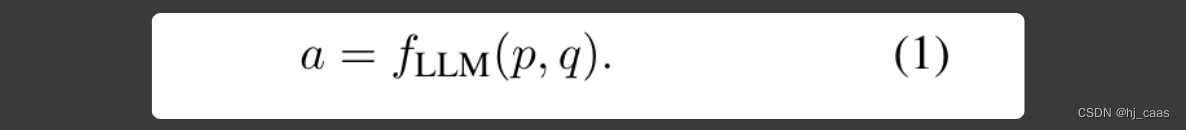
当需要外部知识库时,流程跟传统开放域问答类似,需要设计提示,引导模型从外部文档中寻找答案。
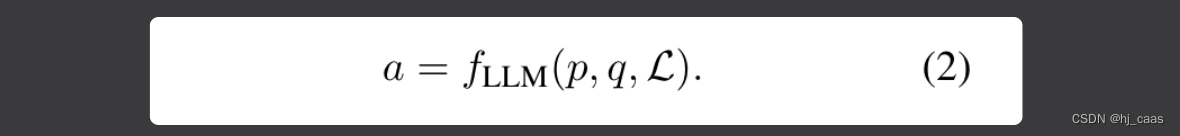
论文设计了两种提示,QA提示和判断提示,LLM根据给定的指令产生判断和答案。
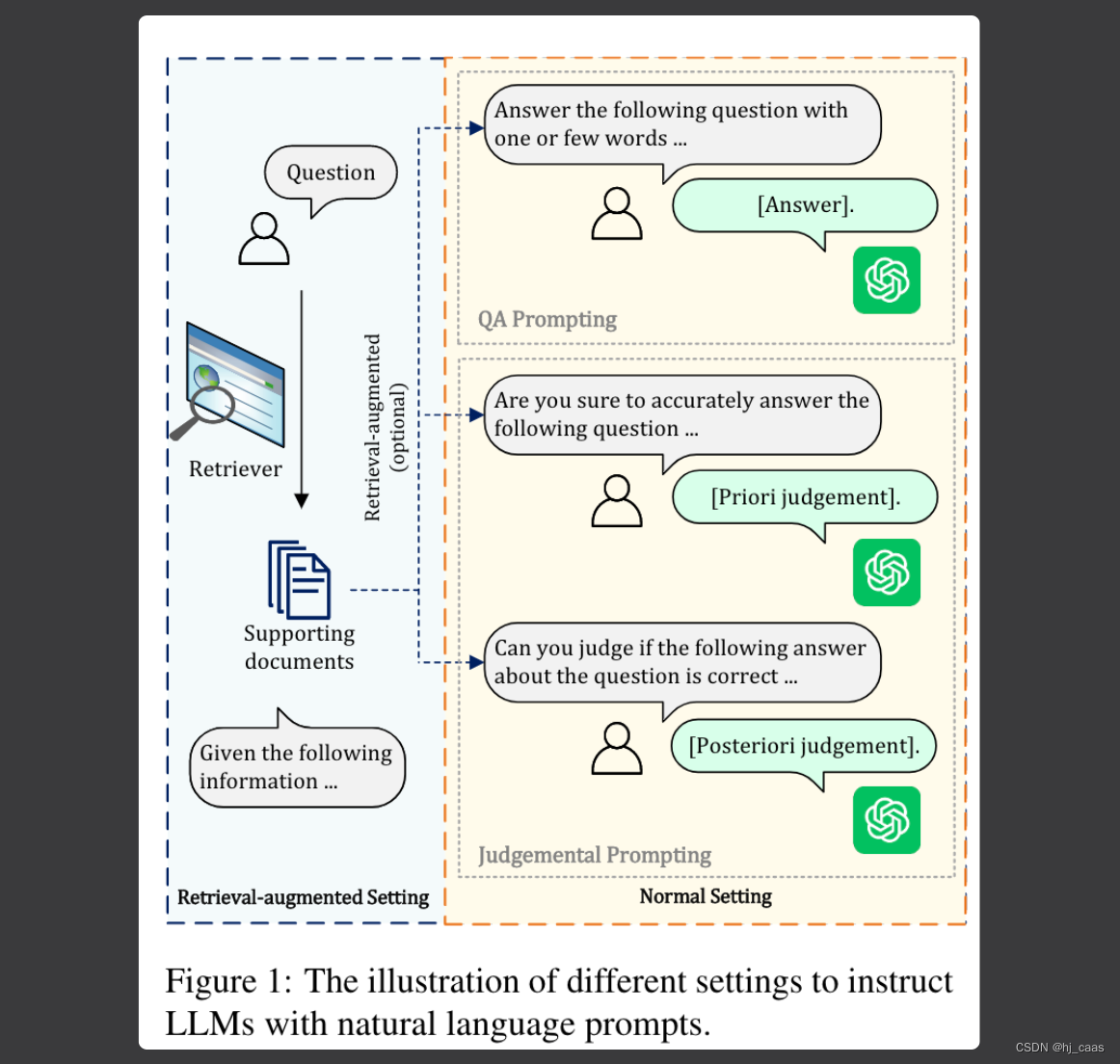 QA提示是引导LLM顺从地回答问题,以评估他们的QA能力。论文提出两种方法重塑指令评估LLM QA的能力。① Normal setting
QA提示是引导LLM顺从地回答问题,以评估他们的QA能力。论文提出两种方法重塑指令评估LLM QA的能力。① Normal setting
LLM用自己的知识提供答案,如公式(1)。
例如:“Answer the following question based on your inter-nal knowledge with one or few words.···”
② Retrieval-augmented setting
LLM使用自己的知识和检索到支持文件来回答问题,如公式(2)。
例如:“Given the following information:···Answer the following question based on the given information or your internal knowledge with one or few words without the source.···”
判断提示是LLM利用已有的知识或外部检索的文件来进行判断过程。
① 先验判断
LLM判断是否可以为问题提供答案。
例如:“Areyou sure to accurately answer the following ques-tion based on your internal knowledge, if yes, youshould give a short answer with one or few words,if no, you should answer ‘Unknown’.···“
② 后验判断
LLM需要评估其提供答案的正确性。
例如:“Can you judge if the following answer about thequestion is correct based on your internal knowl-edge, if yes, you should answer True or False, if no,you should answer ‘Unknown’.···”
评估方法
- EM分数
评估LLM预测的答案与问题的正确答案精确匹配的问题百分比 - F1分数
测量预测的答案和正确答案之间的重叠。 - Give-up rate
表示LLMs放弃回答的问题的百分比,它评估了LLMs在生成答案时的信心水平。 - Right/G
表示LLM放弃回答但实际上可以正确回答的概率。 - Right/¬G
表示LLM没有放弃回答并能够正确回答的问题。 - Eval-Right
LLM评估其答案正确的问题比例。 - Eval-Acc
LLM对答案的评估(正确或错误)与事实一致的问题的百分比。
外部检索方法:
- 密集检索
RocketQAv2+Faiss - 稀疏检索
BM25 - ChatGPT检索
从记忆的知识中检索知识并生成相关的文档
4. Result Analysis
根据表2显示,LLM往往对自己的能力充满信心,而不愿意放弃答案。LLM对自己的事实认知不准确。
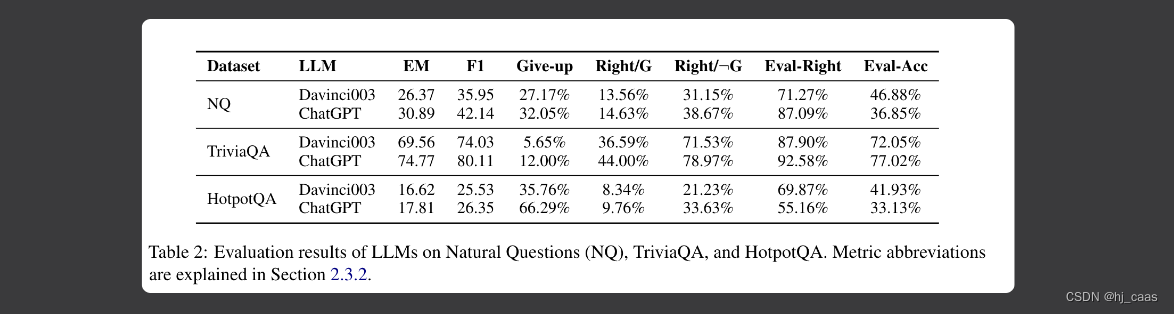
表3显示,LLM不能充分利用已有的知识。检索增强可以作为LLM的有益知识补充。大多数情况下结合密集和稀疏检索的结果作为支持文档将会实现最佳性能。
论文提出ChatGPT比Davinci003理解长文本提示的能力弱。使用ChatGPT生成支持文档的效果表现较好,作者认为这是一种思维链的过程,先用基础知识生成相关文档,然后提炼答案。我认为有可能基础知识是错误的,导致生成的答案也是编造的。
注意,如果从外部知识库中检索到大量的相关文档作为模型的上下文提示,可能会引入大量的噪音,故需要控制检索的数量。
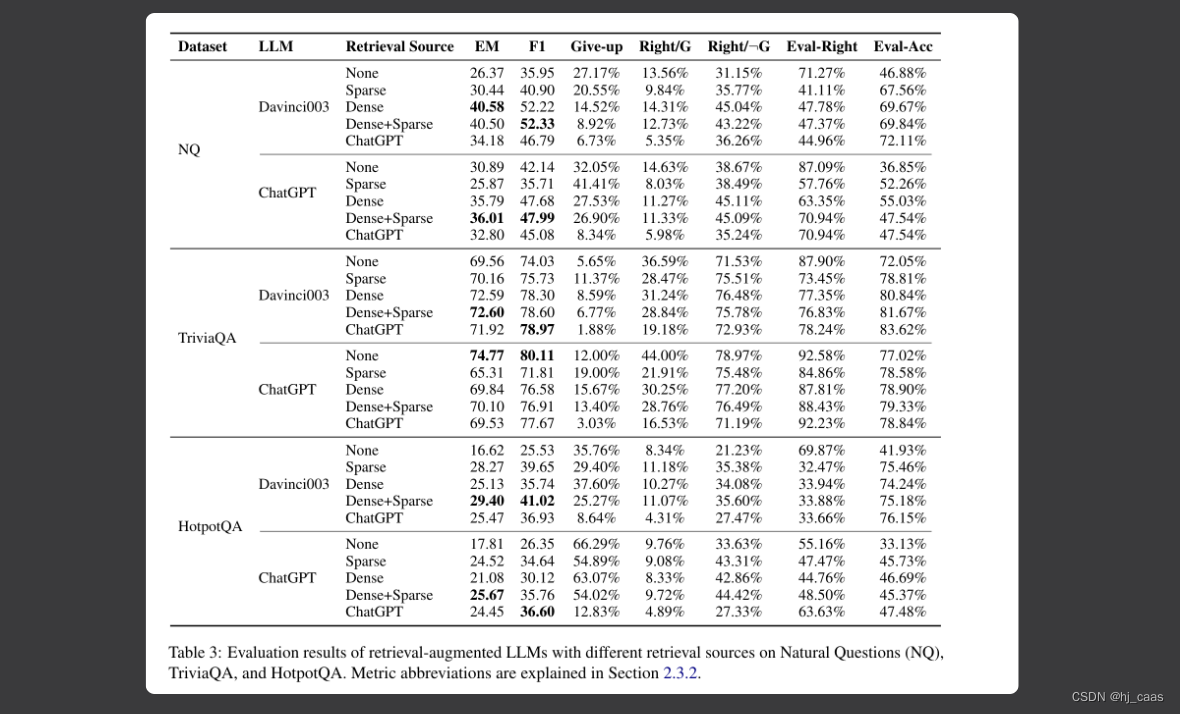
表3显示检索增强LLM感知事实知识范围的能力。
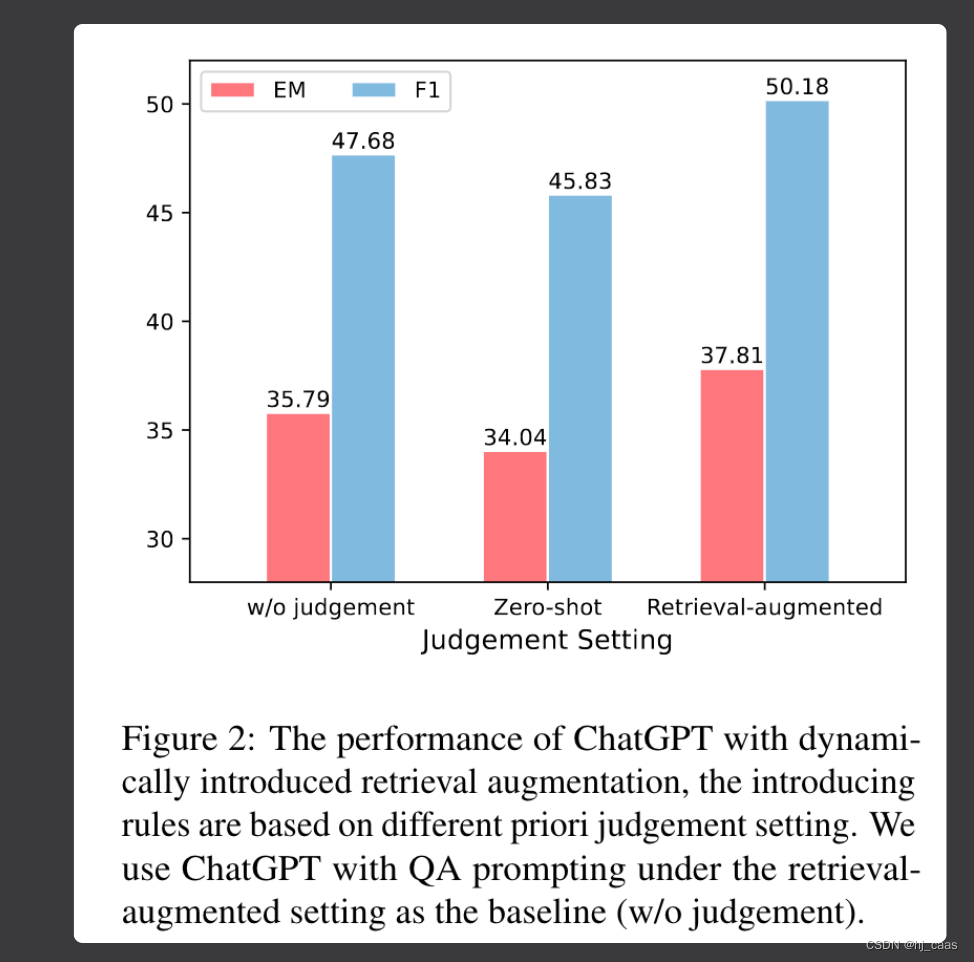
图2显示,LLM使用先验判断动态地引入支持文档是有益的。
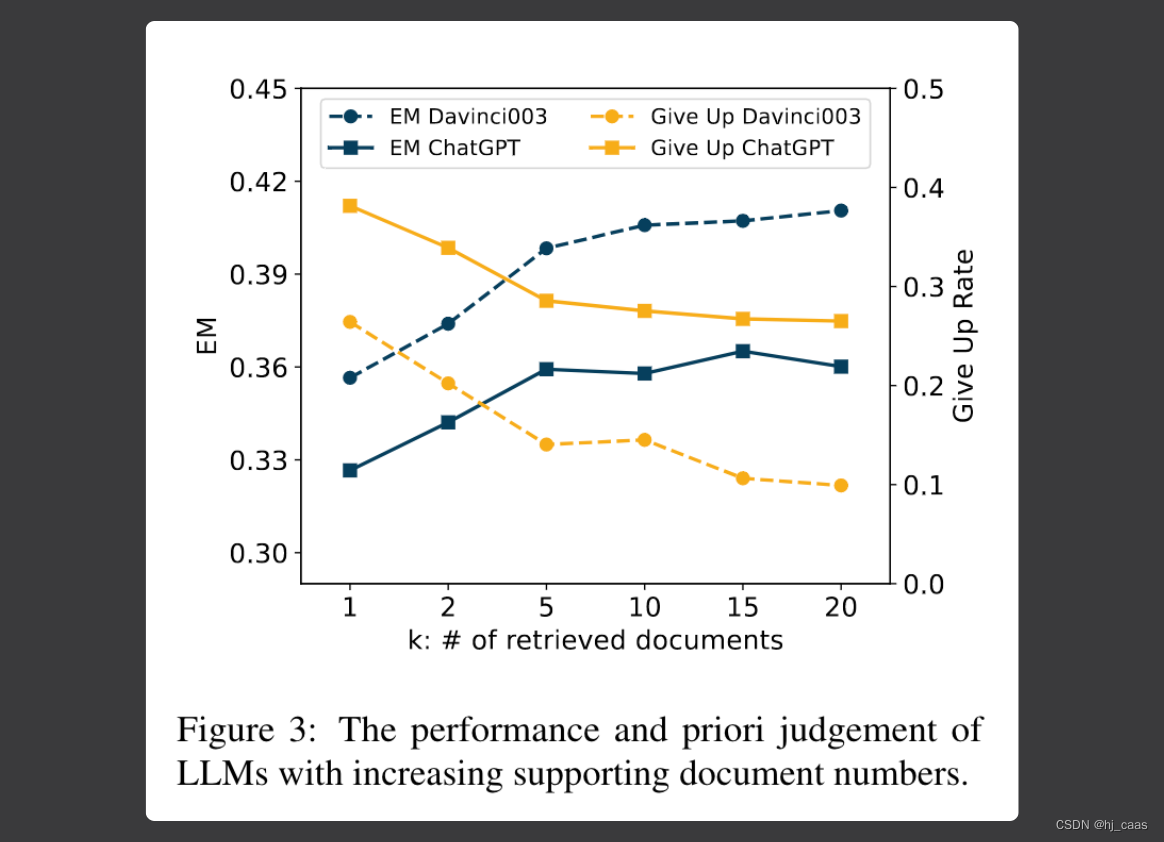
图3显示不同数量的外部相关文档对LLM性能的影响。
论文指出LLM对支持文档的排序不敏感,有论文指出提示文本内容的位置对模型影响很大。参考《2023-Lost in the Middle: How Language Models Use Long Contexts》
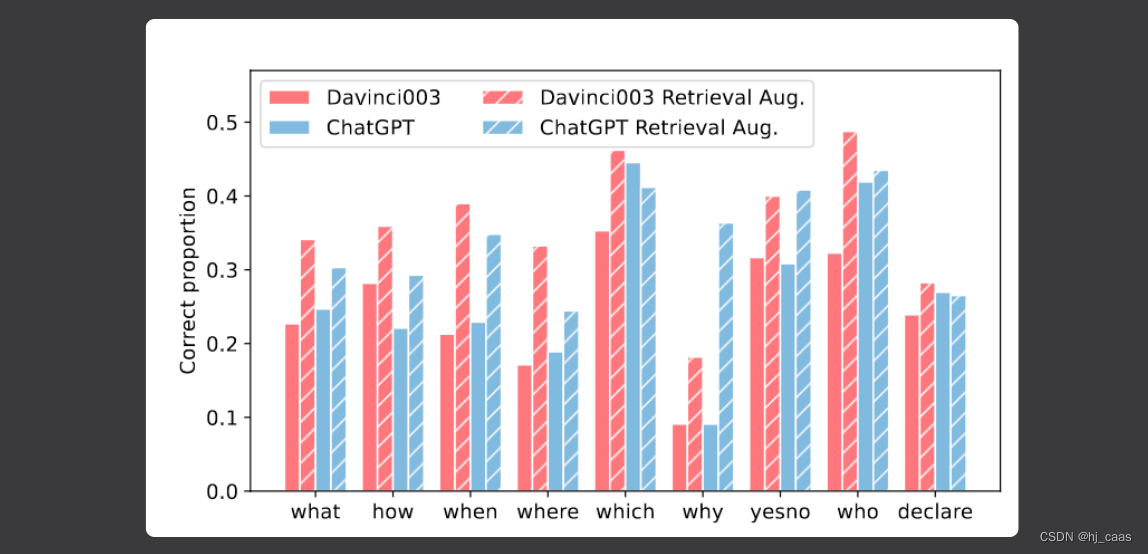
图4显示,检索增强将会改变LLM对不同查询类别的偏好。Davinci003提高了所有类别问题的准确率,平衡了各个类别在检索增强下的能力。
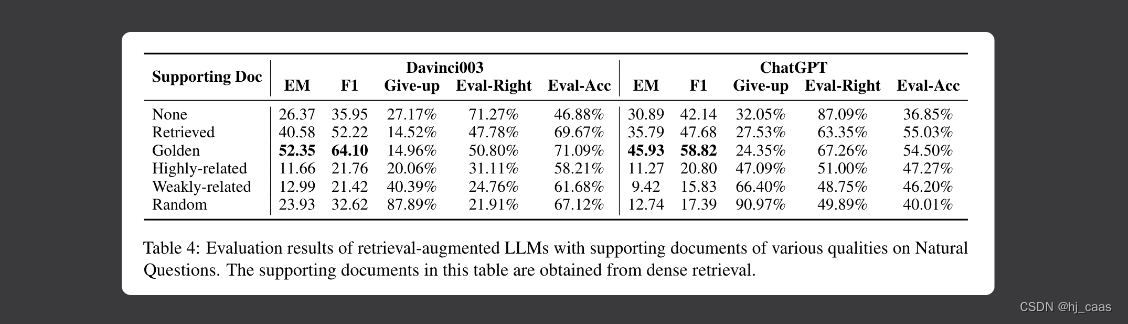
表四显示,LLM在高质量支持文档的支持下表现出更高的可信度。随着支持文档质量的提高,LLM的评估正确率增加,表明LLM在感知其事实知识边界方面表现出更高的准确性。同时表明LLM在生成答案时更关注支持文档。
5. Conclusion
(1) LLM对自己回答问题的能力和答案的质量表现出盲目的自信,表明他们不能准确地感知他们的事实知识边界。
(2) LLM不能充分地利用他们所拥有的知识,而检索增强的引入有效地增强了他们感知事实知识边界的能力,从而提高了判断能力。
(3) LLM在回答问题时倾向于严重依赖给定的检索结果,并且支持文档的特征显著地影响了他们的依赖。
(4) LLM动态使用检索增强将会提高模型问答的性能。
6. Code
这篇论文的代码实现比较简单,重点在于提示的设计。
prompt_dict = {'qa': {'none': 'Answer the following question based on your internal knowledge with one or few words.\nQuestion: {question}{paras}{prediction}','ra': 'Given the following information: \n{paras}\nAnswer the following question based on the given information or your internal knowledge with one or few words without the source.\nQuestion: {question}{prediction}','tail': '\nAnswer: ',},'prior': {'none': 'Are you sure to accurately answer the following question based on your internal knowledge, if yes, you should give a short answer with one or few words, if no, you should answer \"Unknown\"\nQuestion: {question}{paras}{prediction}','ra': 'Given the following information: \n{paras}\nCan you answer the following question based on the given information or your internal knowledge, if yes, you should give a short answer with one or few words, if no, you should answer \"Unknown\".\nQuestion: {question}{prediction}','tail': '\nAnswer: ',},'post': {'none': 'Can you judge if the following answer about the question is correct based on your internal knowledge, if yes, you should answer True or False, if no, you should answer \"Unknown\".\nQuestion: {question}{paras}\nAnswer: {prediction}','ra': 'Given the following information: \n{paras}\nCan you judge the if the following answer about the question is correct based on the given information or your internal knowledge, if yes, you should answer True or False, if no, you should answer \"Unknown\".\nQuestion: {question}\nAnswer: {prediction}','tail': '\nJudgement is: ',},'generate': {'none': 'I want you to act as a Wikipedia page. I will give you a question, and you will provide related passages in the format of a Wikipedia page which contains 10 paragraphs split by \"\n\n\". Your summary should be informative and factual, covering the key phrases that could answer the following question.\nQuestion: {question}{paras}{prediction}','ra': '','tail': '',}
}def get_prompt(sample, args):paras = ""prompt = prompt_dict[args.type]['none']if args.ra != 'none':ra_dict = args.rai = 0doc = []for k, v in ra_dict.items():v = min(v, len(sample[k]))for j in range(v):doc.append(("Passage-%d" % i) + sample[k][j])i += 1paras = '\n'.join(doc)prompt = prompt_dict[args.type]['ra']tail = prompt_dict[args.type][tail] if not args.usechat else ""prediction = sample['Prediction'] if args.type == 'post' else ""prompt = prompt.format(question=sample['question'], paras=paras, prediction=prediction)return prompt这篇关于论文解读: 2023-Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








