本文主要是介绍论文笔记——MAST:A Memory-Augmented Self-Supervised Tracker,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文题目:A Memory-Augmented Self-Supervised Tracker
论文地址:https://arxiv.org/abs/2002.07793
这篇文章是今年牛津VGG组发表在ECCV20的文章,主要是用self-supervised的方法,处理Video Objects Segmentation的task。既然是自监督学习,那么训练阶段无需任何的annotation,只是通过学习到一种representation来实现frame之间像素级的关联;在测试阶段也只需要给出第一个frame的mask,后续frame的mask通过第0帧给定的mask进行预测。

本文的三大贡献如下:
(1)重新评估了过去的一些自监督方法,并给出了最优的选择;
(2)设计了一种存储结构—— memory bank,用来存放一些short-term以及long-term的帧信息,可以处理一些occluded instance;
(3)在video segmentation上面提出了一种新的metric——generalizability。

上图展示了一些无监督和有监督方法,在DAVIS-2017上的表现。可以发现过去的self-supervised方法普遍和supervised方法之间存在不小的gap,而本文的MAST已经达到甚至超越了一些有监督模型的performance,可以说比较强大。
Background
介绍了该论文的背景,自监督tracking的目标就是学习到一种feature representation,用来进行帧之间像素级的联系。主要是如何利用上一帧 I t − 1 I_{t-1} It−1来重构当前帧图像 I t I_{t} It,此时这个t-1帧称为reference frame,需要我们找到这两个frame之间的关联性。
那么怎么做呢?首先我们可以在第t帧,定义一个三元组 ( Q t , K t , V t ) ({Q_{t},K_{t}},V_{t}) (Qt,Kt,Vt),分别对应query,key,value。其中Q表示 I t I_{t} It经过Encoder后得到的feature map(该Encoder是一个Siamese CNN,下同),K表示之前的frame经过Encoder得到的feature map,V在训练阶段表示K对应帧的原图像,测试阶段表示mask。
于是通过这个三元组就可以重构出当前frame的图像 I t I_{t} It:

首先看公式(2),< · , · >表示两个向量的点积, Q t i Q_{t}^{i} Qti表示当前帧 I t I_{t} It的feature map在像素 i i i上的特征, Q t j Q_{t}^{j} Qtj表示上一帧 I t − 1 I_{t-1} It−1的feature map在像素 j j j上的特征。因此 A t i j A_{t}^{ij} Atij表示当前帧的特征图在 i i i处的特征,与上一帧的特征图在 j j j处的特征之间的相似度,由于是点积运算,所以该值越大则表明越相似。
得到关联矩阵A以后,就可以利用公式(1),通过矩阵A和上一帧的原图像V,重构当前帧的图像 I ^ t i \hat{I}_{t}^{i} I^ti。关联矩阵A相当于给上一帧原图像的每个pixel,分配一个权值,特征相似度高的地方权值较大,最终重构的像素是通过加权求和得到的。因此像素重构的过程相当于一种attention机制。
此外在自监督中还有一个概念比较重要,叫做information bottleneck。有些输入信息对特征表示的学习有用,而有一些输入则对instance的特征表达作用有限。举个例子,人脸有鼻子眼睛嘴巴,还有黄颜色的皮肤,前面的器官更能体现出脸的特征,而黄颜色哪里都有,不仅仅是人脸最本质的特征。因此需要我们保留合理的信息,来学习到最精简最具泛化性的特征。这是在self-supervised里面重要的一环。
Improved Reconstruction Objective

作者发现RGB三通道之间有很强的联系,即便dropout掉某一个通道,另外两通道也可以大致给出这个通道的值。因此作者采用了Lab色彩空间,这样可以迫使模型学习到更加robust的特征,而非简单地依赖于色彩信息。
重构采用了采用了regression的思想,并采用了huber loss:

Multi-frame tracker
为什么要引入memory bank呢?在前面的重构中,如果出现occluded或一些棘手的情况,可能会导致出现一些偏差,而随着时间的推移,这个偏差会滚雪球一般越来越大。因此采用了这个short-term和long-term的memory结构,以解决错误累积的问题。

上图为MAST的基本结构,可以看出Query此时还是当前帧经过Encoder后的特征图,而Key变成了memory中存放的之前帧对应的特征图。如果要直接计算关联矩阵A,代价显然是非常大的。因此作者提出了一个two-step的attention机制。(1)粗糙地对memory中之前的帧计算ROI,该ROI与query pixel之间有着较好的match,因此可以减小关联矩阵计算的尺寸;(2)在得到ROI的基础上,计算关联矩阵A,进行重构。
整个MAST的算法思路如下:

那么ROI应该如何求解呢?首先看一个示意图:

由于memory中存在long-term的frame,因此同一个instance可能位置上差别很大,需要在较大的范围内寻找。因此引入了dilation结构,在不改变ROI大小的情况下,提高其感受野。
对于第t帧 I t I_{t} It 像素 i i i,如果要计算 I t − N I_{t-N} It−N 的ROI,首先也要计算相似度矩阵 H H H:
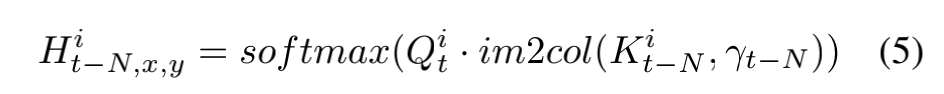
γ \gamma γ表示dilated rate,计算公式为 γ t − N = ⌈ ( t − N ) / 15 ⌉ \gamma_{t-N}=\lceil(t-N)/15\rceil γt−N=⌈(t−N)/15⌉,im2col表示将特征图K按照dilated rate转化成特定的矩阵表示,softmax是统一到0-1的概率值,得到一个概率矩阵。
在得到了矩阵H以后,就可以通过一个soft-argmax操作,估计ROI的中心坐标 P x , y i P_{x,y}^{i} Px,yi:
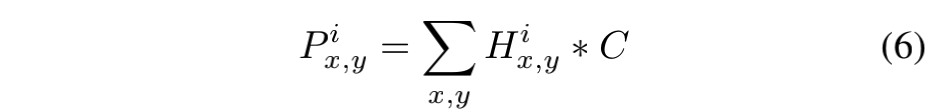
C C C在这里表示对应于dilated window的坐标。通过上述公式,最终可以得到ROI的center,再通过Bilinear sampler(可以参考STN这篇论文)操作就可以得到ROI了。
实验中的memory bank的size为5,分别保存第0,5(作为long-term),t-5,t-3,t-1帧(作为short-term)。预处理阶段将所有的图像resize到 256 ∗ 256 ∗ 3 256*256*3 256∗256∗3,并以0.5的概率随机drop掉一个色彩通道。
Generalizability metrics的计算公式如下:
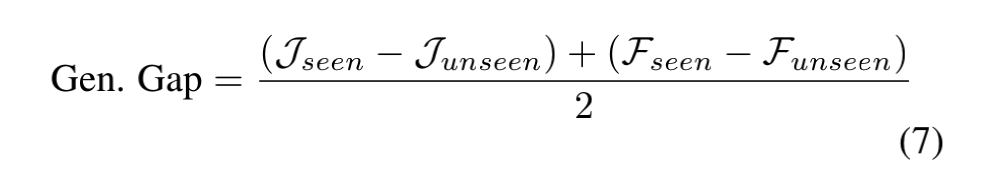
前面的符号表示 region similarity(输出分割与真实掩膜的iou),后面的符号表示contour accuracy(边缘点准确率和召回率的F-score)。可以看出这个metric意在减小已知类别和未知类别之间差距过大的情况。
实验结果:



这篇关于论文笔记——MAST:A Memory-Augmented Self-Supervised Tracker的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







