本文主要是介绍linux下载sra数据库,从NCBI当中SRA数据库中下载高通量测序数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用别人的数据,发自己的文章
由于大多数杂志在文章发表前要求公开数据,所以随着测序文章的爆发,NCBI的SRA数据库当中积累了海量的测序数据。我们可以利用这些数据重新做数据挖掘,发表新的文章。
官方下载方法不太稳
要利用数据,首先得下载得到数据,虽然SRA数据库提供的SRA Toolkit 工具包里的prefetch可以下载,但是用这个方法下载数据需要经过复杂的设置,而且经常莫名奇妙的下不了,总的来说体验很差。
其实老朋友迅雷也是可以下载的
下面通过一个例子介绍如何用迅雷下载SRA数据:
例如,我们要下载SRP108428(阅读文献可以找到公开数据的project号)下的所有数据,打开NCBI网址:https://www.ncbi.nlm.nih.gov/Traces/study/?acc=SRP108428(此处为project号),点击"Accession List"键,下载得到SRR List 储存在sra.txt文件中。
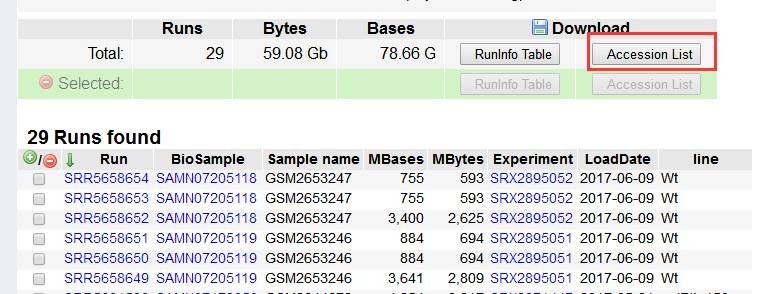
打开sra.txt文件:
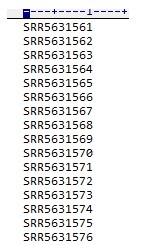
那么我们就可过下载地址规律生成所有样品的ftp的下载地址:
ftp://ftp-trace.ncbi.nih.gov/sra/sra-instant/reads/ByRun/sra/SRR/SRR563/SRR5631562/SRR5631562.sra
注:头部都一样(黑色字),后面地址分别为SRR,SRR+前三个数、SRR号、SSR号.sra
得到如下结果:

最后,将链接粘贴到迅雷下载即可, 是不是很方便?
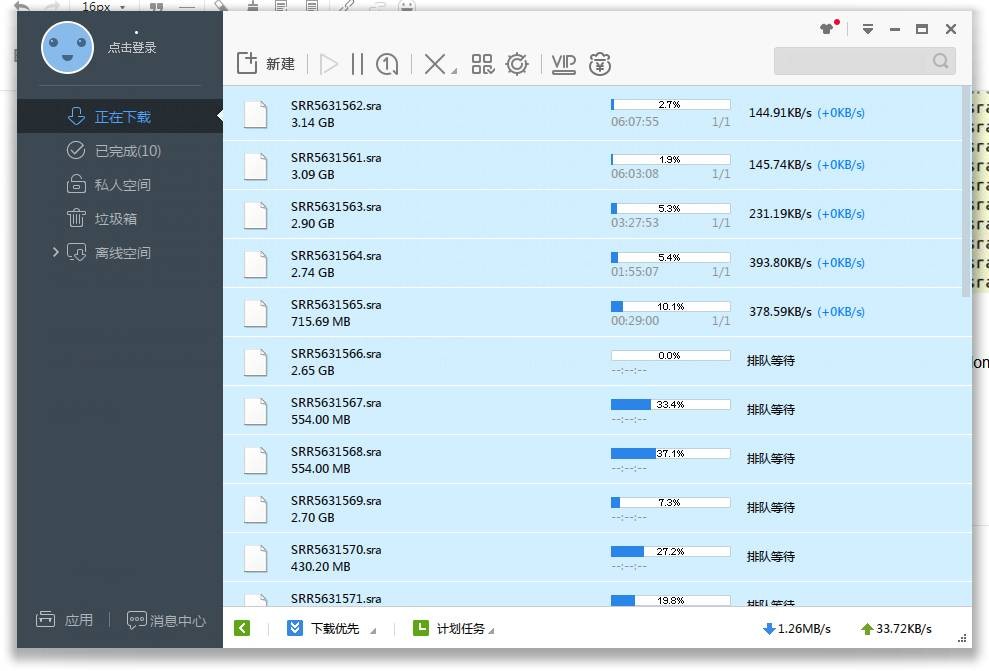
Tips:
如果下载上百个样品,手动粘贴就太累了。在Linux下可以实现一键自动产生下载链接,输入文件为sra.txt, 给出命令:
catSRR_Acc_List.txt|while read a ;do t1=${a:0:3};t2=${a:0:6};echo "ftp://ftp-trace.ncbi.nih.gov/sra/sra-instant/reads/ByRun/sra/$t1/$t2/$a/$a.sra";done
linux学习参照:《linux系统使用》
更多生物信息课程:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程、基因家族文献思路解读
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
这篇关于linux下载sra数据库,从NCBI当中SRA数据库中下载高通量测序数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







