本文主要是介绍Synthesizing the preferred inputs for neurons in neural networks via deep generator networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
该算法(1)生成质量上最先进的合成图像,看起来几乎是真实的;(2)以可解释的方式揭示每个神经元学习的特征;(3)对新的数据集有很好的概括性,对不同的网络结构也有一定的概括性,而不需要重新学习先验;(4)可以被视为一种高质量的生成方法(在这种情况下,通过生成新颖、创造性、有趣、可识别的图像)。
1 Introduction and RelatedWork
受这类神经科学研究的启发,我们有兴趣通过为DNNs的每一个神经元寻找首选的输入来揭示DNNs的内部工作机制。正如神经科学家所做的那样,人们可以简单地向神经网络展示一大组图像,并记录一组高度激活神经元的图像[2]。然而,这种方法与synthesizing preferred stimuli相比有其缺点:1)它需要一个与训练网络所用的图像相似的分布,而这可能并不为人所知(例如,当探测一个训练过的网络时,不知道哪些数据被用来训练它);2) 即使在这样一个数据集中,许多激活神经元的信息图像也可能不存在,因为图像空间是巨大的[3];;3)对于真实的图像,神经元学习到的特征是不清楚的:例如,如果一个神经元被草地上的割草机的图片激活,它是否“关心”草地是不清楚的,但是如果一个合成的图像高度激活了割草机神经元包含草地(如图1所示),我们可以更确信神经元已经学会了关注这种环境。
合成首选刺激被称为激活最大化[4–8,3,9]。它从一个随机图像开始,通过反向传播迭代计算如何改变图像中每个像素的颜色以增加神经元的激活。以前的研究表明,这样做产生的图像会产生不切实际的、无法理解的图像[5,3],因为所有可能的图像集都是如此庞大,以至于有可能产生刺激神经元的“愚弄”图像,但与神经元学会检测的自然图像并不相似。相反,我们必须约束优化,只生成与自然图像相似的合成图像[6]。这一尝试是通过将自然图像先验知识纳入目标函数来实现的,这已被证明能显著提高所生成图像的可识别性[7,6,9]。许多手工设计的自然图像先验已经被实验证明可以改善图像质量,例如:高斯模糊[7]、a-范数[5,7,8]、总变差[6,9]、抖动[10,6,9]、数据驱动的面片先验[8]、中心偏移正则化[9]和从平均图像初始化[9]。在本文中,我们建议使用一种卓越的、学习过的自然图像先验[11],类似于图像的生成模型,而不是手工设计这种先验。这种先验使我们能够合成高度可被人类解释的首选刺激,从而对网络的内部功能有更多的了解。虽然没有办法严格衡量人类的可解释性,这个问题也使得定量评估生成模型几乎是不可能的[12],但我们不应该仅仅因为人类必须主观地评价它们而停止改善定性结果的科学工作。
学习自然图像的生成模型一直是机器学习的一个长期目标[13]。存在许多类型的神经网络模型,包括概率[13]、自动编码器[13]、随机[14]和递归网络[13]。然而,它们通常只限于相对低维的图像和狭义的数据集。
最近,Dosovitskiy和Brox[11]通过将自动编码方式与GAN的对抗性训练相结合,训练了能够从高度压缩的特征表示生成图像的网络。我们利用这些图像生成器网络作为先验产生合成的首选图像。这些生成器网络接近但不是真实的生成模型,因为它们在训练时没有像变分自动编码器[14]或GANs[17]那样对隐藏分布施加任何先验,也没有像去噪自动编码器[18]那样添加噪声。因此,在数据空间上既没有自然采样过程,也没有隐式密度函数。

图2:为了给目标神经元h(例如 "蜡烛 "类输出神经元)合成一个首选输入,我们优化深度图像生成器网络(DGN)的隐藏代码输入(红条),以产生一个高度激活h的图像。被可视化的目标DNN可以是一个不同的网络(具有不同的结构,或在不同的数据上训练)。梯度信息(蓝色虚线)从目标DNN中包含h的层(这里是fc8层)一直流经图像回到DGN的输入代码层。请注意,被可视化的DGN和目标DNN都有固定的参数,而优化只改变了DGN的输入代码(红色)。
我们用作先验的图像生成器DNN被训练成接收一个code(例如标量向量)并输出一个合成图像,该图像看起来尽可能接近ImageNet数据集[19]中的真实图像。为了在给定的DNN中产生我们想要可视化的神经元的首选输入,我们在图像生成器DNN的输入代码空间中进行优化,以便它输出激活感兴趣神经元的图像(图2)。我们的方法将搜索限制在只能由先验绘制的图像集上,这为现实的可视化提供了强大的偏向。由于我们的算法使用深度生成器网络来执行激活最大化,我们称之为DGN-AM。
2 Methods
Networks that we visualize. 我们在各种不同的网络上演示了我们的可视化方法。为了重现性,我们使用Caffe或Caffe Model Zoo[20]中免费提供的预训练模型。CaffeNet [20], GoogleNet [21], 和ResNet [22]。它们代表了在130万张图片的2012年ImageNet数据集上训练的不同convnet架构[23, 19]。我们默认的DNN是CaffeNet[20],它是常见的AlexNet架构[24]的一个小变体,具有类似的性能[20]。8层CaffeNet的最后三个全连接层被称为fc6、fc7和fc8(图2)。fc8是最后一层(pre softmax),有1000个输出,每个ImageNet类别一个。
Image generator network. 我们用Φ表示我们想要可视化的DNN,而不是像以前的工作那样,直接优化一个图像,使其高度激活Φ中的一个神经元h,并选择性地满足嵌入成本函数中的手工设计的先验因素[5, 7, 9, 6],这里我们在图像生成器网络G的输入代码中进行优化,使G输出一个高度激活h的图像。
对于G,我们使用[11]公开的网络,这些网络已经用GANs[17]的原理进行训练,从CaffeNet[20]中的隐藏层特征表示中重建图像。G的训练方式与原始GAN配置有重要区别[17]。这里我们只能简单地总结一下培训过程;详情请参见[11]。训练过程包括四个卷积网络: 1)一个要反转的固定编码器网络E,2)一个生成器网络G,3)一个固定的 "比较器 "网络C和4)一个鉴别器D。G被训练来反转一个由网络E提取的特征表示,并且必须满足三个目标。1)对于一个特征向量yi = E(xi),合成的图像G(yi)必须接近于原始图像xi 2)输出图像C(G(yi))的特征必须与真实图像C(xi)的特征接近;3)D应该无法将G(yi)与真实图像区分开来。D的目标是区分合成图像G(yi)和真实图像xi,如同原始的GAN[17]。
在本文中,编码器E是CaffeNet在不同层的截断(t truncated at different layers)。我们用 E l E_l El表示在第l层截断的CaffeNet,用 G l G_l Gl表示为反转 E l E_l El而训练的网络。比较器 C is CaffeNet up to layer pool5。D是一个有5个卷积层和2个全连接层的卷积网络。G是一个upconvolutional (又称a deconvolutional)架构[15],有9个向上卷积层和3个全连接层。详细的架构在[11]中提供。
Synthesizing the preferred images for a neuron. 直观地说,我们在图像生成器模型G的输入代码空间中寻找一个代码y,使G(y)是一个图像,在我们想要可视化的DNNΦ中产生目标神经元h的高激活(即优化最大化Φh(G(y)))。回顾一下, G l G_l Gl是一个生成器网络,它被训练为从CaffeNet的第l层特征重建图像。从形式上看,包括一个正则化项,我们可以将激活最大化问题表述为:找到一个代码 y l ^ \hat {y^l} yl^,从而使
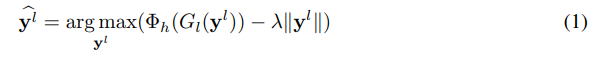
根据经验,我们发现L2正则化(λ=0.005)效果最好。我们还通过 E l E_l El运行验证集图像来计算代码集 { y i l } \{y^l_i\} {yil}中每个神经元的激活范围。然后,我们将 y l ^ \hat {y^l} yl^中的每个神经元夹在[0, 3σ]的激活范围内,其中σ是平均激活周围的一个标准差(由于ReLU非线性存在于我们优化代码的层中,所以激活的下限为0)。
这种剪裁作为代码空间的原始先验,大大改善了图像质量。在未来的工作中,我们计划通过GAN或其他生成模型来学习这个先验。因为激活最大化的真正目标是为每个神经元生成可解释的首选刺激,我们在由L2权重λ、迭代次数和学习率组成的超参数空间中进行随机搜索。我们选择了能产生最高质量图像的超参数设置。我们注意到,我们发现一个神经元的激活和其可视化的可识别性之间没有关联。我们的代码和参数可在http://EvolvingAI.org/synthesizing。
3 Results
3.1 Comparison between priors trained to invert features from different layers
由于生成器模型 G l G_l Gl可以被训练成反转E的任意层l的特征表示,我们对l={3,5,6,7}进行了采样,以探索对这种选择的影响,并定性地确定哪种产生最佳图像。在这里,用于可视化Φ的DNN与编码器E(CaffeNet)相同,但它们可以是不同的(如下图所示)。 G l G_l Gl网络来自于[11]。对于每个 G l G_l Gl网络,我们从随机抽样中选择了超参数设置,以获得最佳的定性结果。
优化卷积层(l=3,5)的编码通常会产生高度重复的片段,而优化全连接层的编码则会产生更为连贯的整体结构(图3)。有趣的是,以前的研究表明,训练G来反转较低层的代码(较小的l)会产生远比较高层的代码更好的重建结果[25,6]。这是可以解释的,因为这些低级代码来自自然图像,并且比更抽象的高级代码包含更多关于图像细节的信息。然而,为了使激活最大化,我们正在从头开始合成一个完整的层代码。我们假设这个过程对于l较小的 G l G_l Gl priors更为糟糕,因为低水平编码中的每个特征都有一个小的局部感受野。因此,优化必须在不知道全局结构的情况下独立地调整整个图像的特征。
因为全连接的图层有来自图像所有区域的信息,它们代表了物体的数量、位置、大小等信息,因此所有的像素都可以朝着这个特定的结构进行优化。一个正交的、非相互排斥的假设是,卷积层的代码空间更加高维,使其更难优化。
我们发现,在fc6代码空间中进行优化会产生最佳的可视化效果(图1和S13)。因此,我们使用这个G6 DGN作为本文其余部分的实验的默认先验。此外,我们的图像与以前所有方法的可视化图像相比,定性地看是最真实的(图S17)。我们的结果显示,即使在最后一个输出层,DNN也能捕捉到大量的精细细节和整体结构。
这一发现与之前的一个假设相反,即用监督学习训练的DNN经常忽略物体的全局结构,而只学习每一类的辨别特征(如颜色或纹理)[3]。
为了测试我们的方法是否记住了训练集的图像,我们从训练集中为每个合成图像样本检索了最接近的图像。具体来说,对于输出神经元Y(如口红)的每张合成图像,我们在同一类别的Y中找到一个在像素空间中具有最低欧氏距离的图像,就像以前的工作[17]一样,但也在编码器DNN的8个代码空间中的每一个。虽然这比在整个数据集中找到一个最近的邻居要困难得多,但我们没有发现任何证据表明我们的方法能够记住训练集图像(图S22)。我们认为,在深层表征空间中评估相似度比仅在像素空间中评估相似度更能反映图像的语义方面,是一种信息量更大的方法。
3.2 Does the learned prior trained on ImageNet generalize to other datasets?
我们测试是否相同的DNN先验(G6)训练反转ImageNet图像的特征表示,使可视化DNN训练在不同的数据集。具体来说,我们的目标是从Caffe Model Zoo下载的两个DNN的输出神经元[20]:(1)一个AlexNet DNN,在250万图像MIT Places数据集上训练,以50.1%的准确率对205种类型的地点进行分类[26](2) 由[27]创建的CaffeNet和[2]中的网络的混合架构,通过分别处理视频的每一帧来对视频中的动作进行分类。该数据集由13320个视频组成,分为101个人类动作类。
 图3:在MIT Places数据集上训练的AlexNet DNN输出单元的Preferred stimuli[26],表明事先训练的ImageNet很好地推广到由场景图像组成的数据集。对于DNN 1来说,在ImageNet图像上训练的先验对完全不同的MIT Places数据集有很好的概括性(图3)。这一结果表明,在ImageNet上训练的先验可以推广到其他自然图像数据集,至少如果要可视化的DNN结构Φ与编码器网络E的结构相同,而生成器模型G是由该网络训练的,以反转特征表示。
图3:在MIT Places数据集上训练的AlexNet DNN输出单元的Preferred stimuli[26],表明事先训练的ImageNet很好地推广到由场景图像组成的数据集。对于DNN 1来说,在ImageNet图像上训练的先验对完全不同的MIT Places数据集有很好的概括性(图3)。这一结果表明,在ImageNet上训练的先验可以推广到其他自然图像数据集,至少如果要可视化的DNN结构Φ与编码器网络E的结构相同,而生成器模型G是由该网络训练的,以反转特征表示。
对于dnn2:先验的推广产生了良好的结果;然而,这些图像在质量上不如dnn1清晰(图4)。我们有两个正交的假设来解释为什么会发生这种情况:1)Φ ([27]中的DNN是E(CaffeNet)的一个重大修改版本;2) 这两种类型的图像差别太大:主要是以对象为中心的ImageNet数据集和UCF-101数据集,后者侧重于人类执行动作。第3.3节回到了第一个 关于Φ和E之间的相似性如何影响图像质量的第一个假设

图4:AlexNet架构经过大量修改后的输出单元的首选图像,该架构被训练用于将视频分类为101类人类活动[27]。在这里,我们优化每个神经元的单个首选图像,因为DNN只对单个帧进行分类(整个视频分类是通过平均所有视频帧的分数来完成的)。
总的来说,用CaffeNet编码器训练的先验很好地概括了在不同数据集上训练的同一CaffeNet架构的其他DNN的可视化。
3.3 Does the learned prior generalize to visualizing different architectures?
我们已经证明了当DNN被可视化时Φ 与编码器E相同,生成的可视化效果非常逼真且可识别(第。3.1). 可视化不同的网络体系结构 Φ ^ \hat Φ Φ^, 一个人可以训练一个新的 G ^ \hat G G^ 倒置 Φ ^ \hat Φ Φ^特征表示。然而,为我们想要可视化的每个DNN训练一个新的gdgn在计算上是昂贵的。在这里,我们测试在CaffeNet(G6)上训练的相同DGN是否可以用于可视化两个在体系结构上与CaffeNet不同但在相同ImageNet数据集上训练的最新dnn。两者都是从Caffe Model Zoo下载的,准确率得分相近:(a)GoogLeNet是一个22层的网络,前5名的准确率为88.9%[21](b) ResNet是一种新型的非常深层的体系结构,具有skip connections[22]。我们设想了一个50层的ResNet,其top 5位的准确率为93.3%[22].
当Φ=E时,DGN-AM能产生最好的图像质量,当Φ结构与E的距离越大,可视化质量就越差(图5,顶行;GoogleLeNet的结构比ResNet更接近CaffeNet)。

图5:当被可视化的DNNΦ与编码器E(这里是CaffeNet)相同时,DGN-AM能产生最好的图像质量,如最上面一行,当Φ与E不同时,DGN-AM就会下降。
3.4 Does the learned prior generalize to visualizing hidden neurons?
Visualizing the hidden neurons in an ImageNet DNN. 以前的可视化技术已经表明,低层神经元可以检测到小而简单的模式,如角和纹理[2,9,7],中层神经元可以检测到单个物体,如人脸和椅子[9,2,28,7],但是在完全连接的层中,隐藏神经元的可视化是陌生的,很难解释[9]。由于DGN被训练来反转真实的、全尺寸的ImageNet图像的特征表示,一种可能性是,这种先验知识可能不能推广到为这些隐藏的神经元生成首选图像,因为它们通常更小,主题不同,或者与真实物体不相似。
为了找出答案,我们为所有层的隐藏神经元合成了首选图像,并与来自[9]的多元特征可视化方法产生的图像进行比较,该方法利用手工设计的 total variation and mean image initialization的先验。被可视化的DNN与[9]中相同(CaffeNet架构,权重来自[7])。
侧面比较(图S14)显示,两种方法在神经元已经学会检测的特征上往往是一致的。然而,总的来说,尽管不需要用真实图像的平均值作为优化的种子,但DGN-AM能产生更真实的颜色和纹理,从而提高我们学习每个隐藏神经元所学到的特征的能力。
人类和其他动物的面部除外,DGN-AM不能很好地显示这些面部(图S14,第6层第3单元;第五层第一单元;第6单元在第4层)。
Visualizing the hidden neurons in a Deep Scene DNN. 最近,Zhou等人[28]发现,当我们训练DNN对场景进行分类时,目标检测器会自动出现在DNN的中间层。为了确定一个隐藏的神经元在给定的图像中关心什么,他们在图像上密密麻麻地滑动一块遮挡的斑块,并记录激活何时下降。然后聚集激活变化以分割出导致高神经激活的确切区域(图6,每个图像中的高亮区域)。
为了确定这些分割的语义,然后向人类展示一个特定神经元的分割图像集合,并要求他们标注哪些类型的图像特征会激活该神经元[28]。在这里,我们将我们的方法与他们在AlexNet DNN上的方法进行比较,AlexNet DNN被训练为对麻省理工学院Places数据集的205个场景类别进行分类(在第3.2节中描述)。
在ImageNet上学习到的先验可用于可视化在MIT Places数据集上训练的DNN的隐藏神经元(图S15)。有趣的是,我们的可视化产生了与[28]中的方法类似的结果,该方法需要向每个神经元展示一个大型的、外部的图像数据集,以发现每个神经元已经学会了检测什么特征(图6)总的来说,DGN-AM不仅可以很好地推广到不同的数据集,而且产生的可视化效果在质量上属于人类提供的每个神经元对什么类型的图像特征做出反应的类别[28]。

图6:AlexNet DNN第5层隐藏神经元的可视化示例,训练用于分类[28]中的场景类别。对于每个单元:我们将[28](左)中的方法生成的两个可视化效果与我们的方法生成的两个可视化效果(右)进行比较。左边的两张图片是真实的图像,每一张都突出显示了一个高度激活神经元的区域,人类在突出显示的区域提供了描述共同主题的文本标签。我们的合成图像可以得出相同的结论,即隐藏的神经元学习到了什么样的特征。
3.5 Do the synthesized images teach us what the neurons prefer or what the prior prefers?
Visualizing neurons trained on unseen, modified images. 我们已经证明,DGN-AM可以通过利用DGN强大的、学习过的、自然的图像先验(图1),生成具有真实色彩和连贯全局结构的首选图像刺激。全局结构、自然颜色和锐利的纹理(例如,图1中的鸣禽)在多大程度上反映了“brambling” 神经元与先前神经元相比所学习到的特征?为了研究这一点,我们训练了3种不同的dnn:一种是针对全局结构较少的图像,一种是针对非真实颜色的图像,另一种是针对模糊图像。我们测试具有相同先验知识的DGN-AM是否产生反映这些修改的、不切实际的特征的可视化。
具体来说,我们按照CaffeNet的架构训练3个不同的DNN来区分2000个类别。前1000个类包含常规的ImageNet图像,后1000个类包含经过修改的ImageNet图像。我们进行了3种类型的修改。1)我们把每张图片切成四分之一,然后按随机顺序重新缝合(图S19);2)我们把普通的RGB图片转换成BRG图片(图S20);3)我们用半径为3的高斯模糊法对图片进行模糊处理(图S21)。
我们在每个DNN中观察两组输出神经元(分别在1000个常规和1000个修改上训练的神经元)。S19、S20和S21)。在常规图像上训练的神经元的视觉效果通常表现为连贯的整体结构、逼真的颜色和锐度。相比之下,在修改后的图像上训练的神经元的可视化确实显示了切割的对象(图S19)、BRG颜色空间中的图像(图S20)和具有洗除细节的对象(图S21)。结果表明,DGN-AM的视觉化确实能很好地反映神经元从数据中学习到的特征,而且这些特征并不完全由先验知识产生。
Why do visualizations of some neurons not show canonical images? 虽然许多DGN-AM可视化显示的是全局结构(例如,单个居中台灯,图1);其他一些没有(例如,纹理斑点而不是4条腿的狗,图S18)或其他不规范(例如,校车偏离图像一侧,图S7)。
S5描述了我们的实验,研究这是否是我们的方法的缺点,或者这些非规范的可视化是否反映了神经元的某些特性。结果表明,DGN-AM可以准确地可视化一类图像,如果该图像集的图像大部分是规范的,而某些神经元的可视化缺乏全局结构或不规范的原因是神经元已经学会检测的图像集往往是多样的(多模态),而不是规范的姿态。需要对多方面的特征可视化算法进行更多的研究,这些算法分别对激活神经元的每种类型的图像进行可视化[9]。
3.6 Other applications of our proposed method
DGN-AM也可用于其他各种重要任务。我们简要介绍了我们对这些任务的实验,并请读者在补充部分了解更多信息。
1合成首选图像的一个优点是,我们可以观察特征在训练过程中如何演变,从而更好地了解深度学习过程中发生的情况。这样做还可以测试所学习的先验知识(经过训练,可以从训练有素的编码器中反转特征)是否泛化为欠拟合和过拟合网络的可视化。结果表明,可视化质量在一定程度上反映了DNN的验证精度,而学习到的先验知识对于训练有素的编码器DNN来说并不会overly specialized。更多细节见S6节。
3. 我们的方法可以扩展到通过合成同时激活两个神经元的图像来产生创造性的原创艺术(S8节)。
4 Discussion and Conclusion
我们已经表明,激活最大化–合成神经网络中神经元的首选输入–通过深度生成器网络形式的学习先验是一种富有成效的方法。DGNAM产生了迄今为止最逼真的、可解释的首选图像,使其在质量上成为激活最大化的最新技术。它从零开始合成的视觉效果提高了我们理解神经元已经学会检测哪些特征的能力。这些图像不仅能很好地反映神经元学习到的特征,而且在视觉上也很有趣。我们探索了DGN-AM可以帮助我们理解经过训练的DNN的各种方法。在未来的工作中,DGN-AM或其学习到的先验知识可以极大地提高我们从图像的文本描述合成图像的能力(例如,通过合成激活某个标题的图像)或创建更真实的“深梦”[10]图像。
此外,本文中使用的先验知识不能很好地推广到不同体系结构的dnn中,这促使我们研究如何训练这样一个通用的先验知识。成功地这样做可以在不同类型的dnn中发生的信息转换之间进行信息比较分析。
S5 Why do visualizations of some neurons not show canonical images?
虽然许多神经元的可视化看起来很好,显示了一个类别的典型图像(例如,有灯罩和底座的台灯,图1);但其他许多神经元却不是这样(例如,狗的可视化经常显示出纹理的斑点,而不是一只狗用4条腿站立,图S18)。我们研究这是否是我们方法的一个缺陷,或者这些非经典的可视化实际上反映了神经元的某些属性。
在这个实验中,我们的目的是将一个DNN训练成成对的类,其中一个包含规范图像,而另一个不包含,并观察可视化是否反映了这些类。具体来说,我们选取了5个类{Ci},我们发现它们的可视化没有显示规范图像:


图S8:当观察所有输出神经元的可视化时,我们发现许多成对的图像看起来非常相似,有时人类的眼睛无法区分,例如羚羊对黑斑羚,狒狒对猕猴。我们研究了这种现象是否反映了训练集的图像,或者是我们方法的缺陷。这里我们展示了4对相似的类别。对于每一对:最上面一行显示了激活神经元最多的前4张训练集图像,最下面一行显示了由我们的方法产生的合成图像。每张图片下面都提供了一个激活分数。结果显示,首选图片密切反映了神经元被训练为分类的训练集图片。对于某些情况,从真实图像和合成图像中都可以注意到两个类别之间的差异:牛蛙与树蛙相比,往往有更深的、粗糙的皮肤;黑斑羚的角更长,皮肤比Hartebeest更黄。对于其他情况,在真实图像和合成图像中几乎是无法区分的。印度象和非洲象。我们还试图通过优化softmax概率输出层而不是激活层(即fc8层)来产生更具区别性的特征的可视化,以确保类似类的可视化是不同的。初步结果表明,我们确实获得了不同的模式(例如印度象和非洲象之间);然而,未来的工作仍然需要充分解释它们(数据未显示)。

(a) 可视化的前15名输出神经元有最高的类精度得分。

图S12:优化同时激活两个神经元的图像的可视化。上面:激活单个神经元的视觉效果。下面:激活“蜡烛”神经元和上面显示的相应神经元的可视化。换言之,这种方法可以是为图像生成领域生成艺术图像的一种新方法,也可以用于为神经元发现新类型的首选图像,从而为其所做的事情提供更多的信息(这里是∼30张激活同一个“蜡烛”神经元的图像)。


图S13:使用不同的先验G运行优化框架的结果比较,每个先验G都训练为从编码器网络E的不同层反转。训练从编码器的完全连接层(c,d)反转特征的先验比训练从卷积层(a,b)反转特征的先验产生更好的一致全局结构。这些网络可从[11]下载。一个假设是,在较低的卷积层中的每个神经元在输入图像上都有一个较小的感受野大小,并且只学习检测低水平的特征[9,2]。因此,与在完全连接层优化相比,在卷积层优化代码会导致重复片段,而在完全连接层,神经元已经学会更多地关注全局结构[9]。另一个正交假设是,卷积层的码空间的维数要高得多,因此很难找到产生逼真图像的码。


图S14:来自CaffeNet DNN[20]所有八层的神经元特征检测器实例的可视化。这些图像反映了不同层的感受野的真实大小。对于每个神经元,我们展示了4种不同的可视化:最上面的2张图片来自以前的工作,利用了手工设计的先验,称为 “mean image initialization”[9]。下面两张图片来自我们的方法。这种并排比较表明,这两种方法通常在神经元已经学会检测的特征上是一致的。总的来说,我们的方法产生了更逼真的颜色和纹理。然而,比较也表明我们的方法不能很好地显示动物的脸(第6层的第3和第4单元;第五层第一单元;第6单元在第4层)。最好看电子,彩色,变焦。


图S17:将所有先前的激活最大化结果与本文(i)中提出的方法进行比较。为了进行公平的比较,这些分类并不是为了展示我们最好的图片而精心挑选的,而是根据之前论文中提供的图片来选择的[5,7–9,6]。总的来说,虽然这是一种主观判断,读者可以自己决定,但我们相信,我们通过图像生成器网络合成首选图像的方法可以产生具有更自然颜色和更真实全局结构的可识别图像。


图S22:为了测试我们的方法是否记忆训练集图像,我们从训练集中为每个样本合成图像检索最近的图像。具体而言,对于输出神经元Y(例如唇膏)的每个合成图像(最左边的列),我们在同一类Y的所有图像中,在像素空间中的最低欧几里得距离(第二个最左边)中找到图像,如在先前的作品[17 ]中所做的,但也在编码器DNN的8个代码空间中的每一个(层CONV1到FC8)中。合成图像是对DGN先验输入fc6码进行优化的结果。虽然在同一类中与最近邻进行比较比在整个数据集中与最近邻进行比较要困难得多,但我们没有发现证据表明我们的方法能够记住训练集图像。我们相信,在深度表示的代码空间中评估相似度,可以更好地捕捉图像的语义方面,与仅在像素空间中评估相比,是一种更具信息量的方法。
这篇关于Synthesizing the preferred inputs for neurons in neural networks via deep generator networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!