本文主要是介绍多卡训练系列1:sampler option is mutually exclusive with shuffle,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于Pytorch多卡训练中遇到的问题解决
具体问题报错:
Dataloader BUG ValueError: sampler option is mutually exclusive with shuffle
问题截图

问题产生的代码
from torch.utils.data.dataloader import DataLoader
dataset_train = Dataset(opt.images_dir)
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset_train)
dataloader = DataLoader(dataset=dataset_train,batch_size=opt.batch_size,shuffle = True,num_workers=opt.workers,pin_memory=True,drop_last=True,sampler=train_sampler)
问题产生的原因:
在设置sampler为torch.utils.data.distributed.DistributedSampler类之后,依然设置Dataloader的shuffle属性为True
在下面的源码解释中可以看出,如果sampler不为默认的None的时候,不用设置shuffle属性了
源码解释:
pytorch的Dataloader源码 参考链接
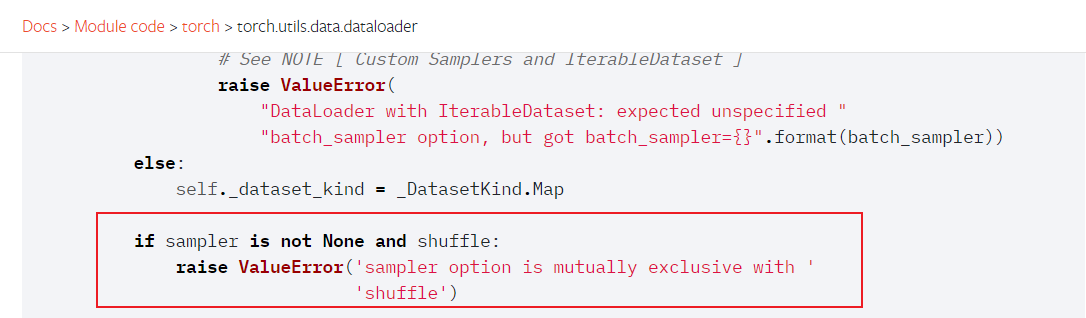
if sampler is not None and shuffle:raise ValueError('sampler option is mutually exclusive with shuffle')
源码补充
当sampler为None的时候会根据shuffle属性设置不一样的采样器(代码想要达到的功能就是在sampler
设置为默认值的时候根据shuffle属性初始化sampler,在sampler不为None的时候,就直接已经初始化完毕了,有了具体的采样器属性,是否随机等属性是根据你定义的sampler里面定义的(正如这里的RandomSampler一样))

参考文献
python - ValueError: sampler option is mutually exclusive with shuffle pytorch - Stack Overflow
torch.utils.data.dataloader — PyTorch 1.8.1 documentation
这篇关于多卡训练系列1:sampler option is mutually exclusive with shuffle的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








