本文主要是介绍用spark获取前一行数据,DF.withColumn(colName,lag(colName,offset).over(Window.partitionBy().orderBy(desc()))),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据:
1,11,111
2,22,222
3,33,333
1,22,333
1,22,444代码:
package com.emg.etp.analysis.preproces.nullphotoimport com.emg.etp.analysis.preproces.nullphoto.pojo.EcarData
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.execution.SparkStrategies
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._import scala.collection.mutable.ListBuffer/*** @Auther: sss* @Date: 2020/7/21 16:20* @Description:*/
object Tests {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("etpProcess").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(Array[Class[_]](EcarData.getClass))val spark = SparkSession.builder().config(conf).getOrCreate()val sc: SparkContext = spark.sparkContextimport spark.implicits._val rdd = sc.textFile("C:\\Users\\sss\\Desktop\\qqq\\aa.txt")val win = Window.partitionBy("id1").orderBy(desc("id3"))val rdd2 = rdd.map(line => {val data = line.split(",", -1)(data(0), data(1), data(2))})val data = rdd2.toDF("id1", "id2", "id3").withColumn("aa", lag("id3", 1).over(win))data.show()val df_difftime = data.withColumn("diff", when(isnull(col("id3") - col("aa")), 0).otherwise((col("id3") - col("aa"))))df_difftime.show()}
}
结果:
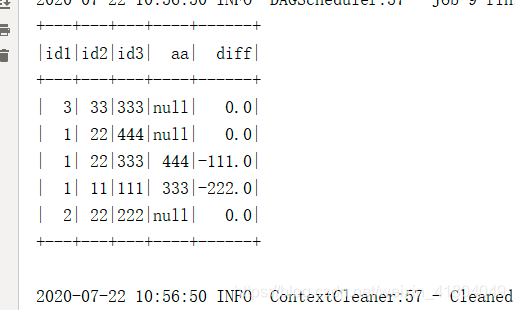
这篇关于用spark获取前一行数据,DF.withColumn(colName,lag(colName,offset).over(Window.partitionBy().orderBy(desc())))的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





