partitionby专题

Spark算子:RDD键值转换操作(1)–partitionBy、mapValues、flatMapValues
partitionBy def partitionBy(partitioner: Partitioner): RDD[(K, V)] 该函数根据partitioner函数生成新的ShuffleRDD,将原RDD重新分区。 scala> var rdd1 = sc.makeRDD(Array((1,"A"),(2,"B"),(3,"C"),(4,"D")),2)rd
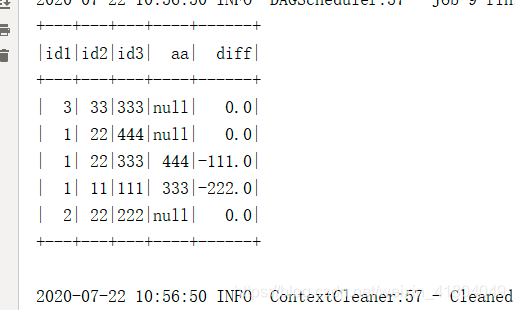
用spark获取前一行数据,DF.withColumn(colName,lag(colName,offset).over(Window.partitionBy().orderBy(desc())))
数据: 1,11,1112,22,2223,33,3331,22,3331,22,444 代码: package com.emg.etp.analysis.preproces.nullphotoimport com.emg.etp.analysis.preproces.nullphoto.pojo.EcarDataimport org.apache.spark.{SparkConf